

 13
13 0
0Episode release: 2025-05-24
内容来源:Devin by Cognition (YouTube)
📌 本期亮点
Cognition 联合创始人 Russell Kaplan 近日在LangChain社区的 LangChain Interrupt技术大会中作了一场标题为“Devin by Cognition: When AI Becomes Your Best Developer ”的分享,阐述了 Devin 2.x 面向大型、多编程语言、历史代码仓的整体设计哲学与落地经验。本期播客帮你10分钟读懂Russell的分享精华。
🚩 大型代码仓(large code repo)关键挑战与解决方案

1️⃣ 挑战一:代码量级庞大、上下文窗口有限
痛点:百万行以上代码,单纯 LLM 上下文处理困难
解决方案:语义切分 + 向量索引,动态精准加载代码片段
Deep Mode 支持跨文件、跨语言深度语义检索
2️⃣ 挑战二:隐式知识沉淀不足,开发上手难
痛点:隐性架构知识、决策散落于 PR 评论与注释中
解决方案:自动生成 DeepWiki:架构图、调用关系、Markdown 文档
搜索与规划工具实时共享 Wiki 信息,快速辅助新人上手
3️⃣ 挑战三:任务链长且复杂,AI易“走神”
痛点:重构与迁移任务常涉及数十步,容易遗漏或失败
解决方案:生成“可回滚”的多步计划 (Interactive Planner)
失败时自动回滚、自修复,自适应调整 Prompt 再尝试
4️⃣ 挑战四:单实例串行任务执行效率低
痛点:串行执行任务耗时长、效率低
解决方案:Parallel Devins 并行实例,每实例独立环境并发执行
Web端 IDE 支持实时旁路干预、状态追踪
5️⃣ 挑战五:黑箱与信任缺失问题
痛点:开发团队对AI透明度与可控性存在顾虑
解决方案:Machine Snapshot 实时捕获环境、代码和执行状态
提供置信度评分,低于阈值自动暂停,等待人工确认
6️⃣ 挑战六:企业ROI和安全审计问题
痛点:企业对AI解决方案的投入回报和安全顾虑大
解决方案:Nubank实践案例:效率提升约8-12倍,成本降低20倍
提供VPC隔离、企业私有部署和审计日志服务
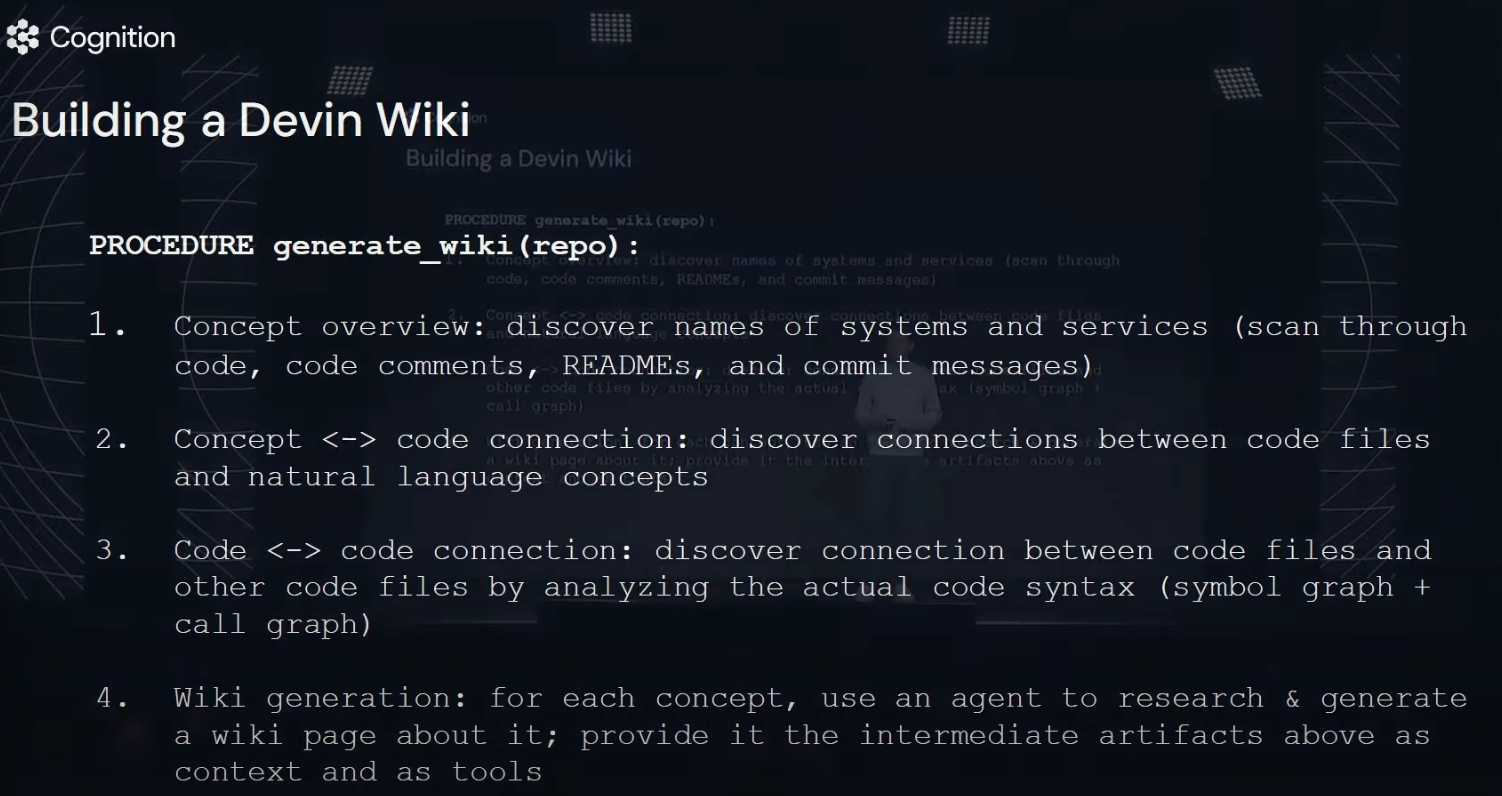
Devin Wiki & Devin Search 如何为模型提供上下文
构建Devin Wiki的过程:
扫描代码仓库,提取语法树(AST)、依赖关系、注释、提交历史与PR讨论。
使用语义切分将代码文档化,构建自动生成的 Markdown 架构图、API文档和调用链图。
Wiki支持实时自动更新,以确保信息持续最新。Devin Search如何提供上下文?
将构建的Devin Wiki与仓库中的代码片段统一索引,建立高效向量数据库。
当用户向Devin提问时,Devin Search从语义索引快速检索相关代码片段和Wiki内容。
将检索出的信息动态输入给Devin的LLM作为上下文,以确保回答精确和贴合实际需求。

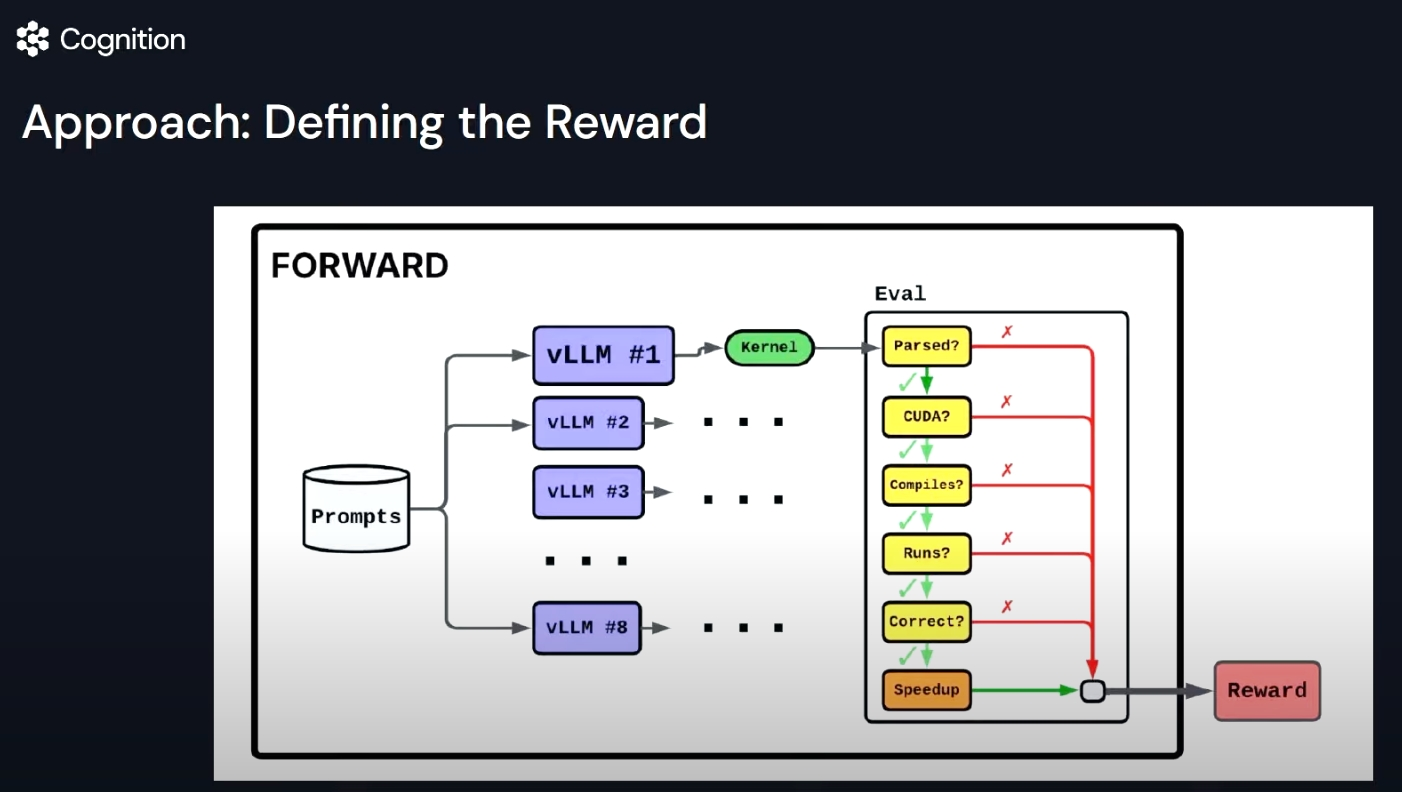
通过定义奖励(Reward Definition)对代码模型进行强化训练
强化学习(RL)的思路
Devin 采用基于强化学习的后训练(RL post-training),并明确定义奖励(Reward)函数,以驱动模型持续提升开发效率与准确性。具体做法
明确任务表现标准(如成功运行、测试通过、代码简洁、执行效率)。
根据任务完成的质量、时间成本、资源占用以及失败回滚次数定义奖励函数。
将实时计算的奖励信号反馈给模型,引导模型逐步优化策略。优势
使模型更关注于具体的开发目标。
在特定领域(例如特定代码库、业务场景)实现明显性能提升,超越未进行后训练的前沿模型。
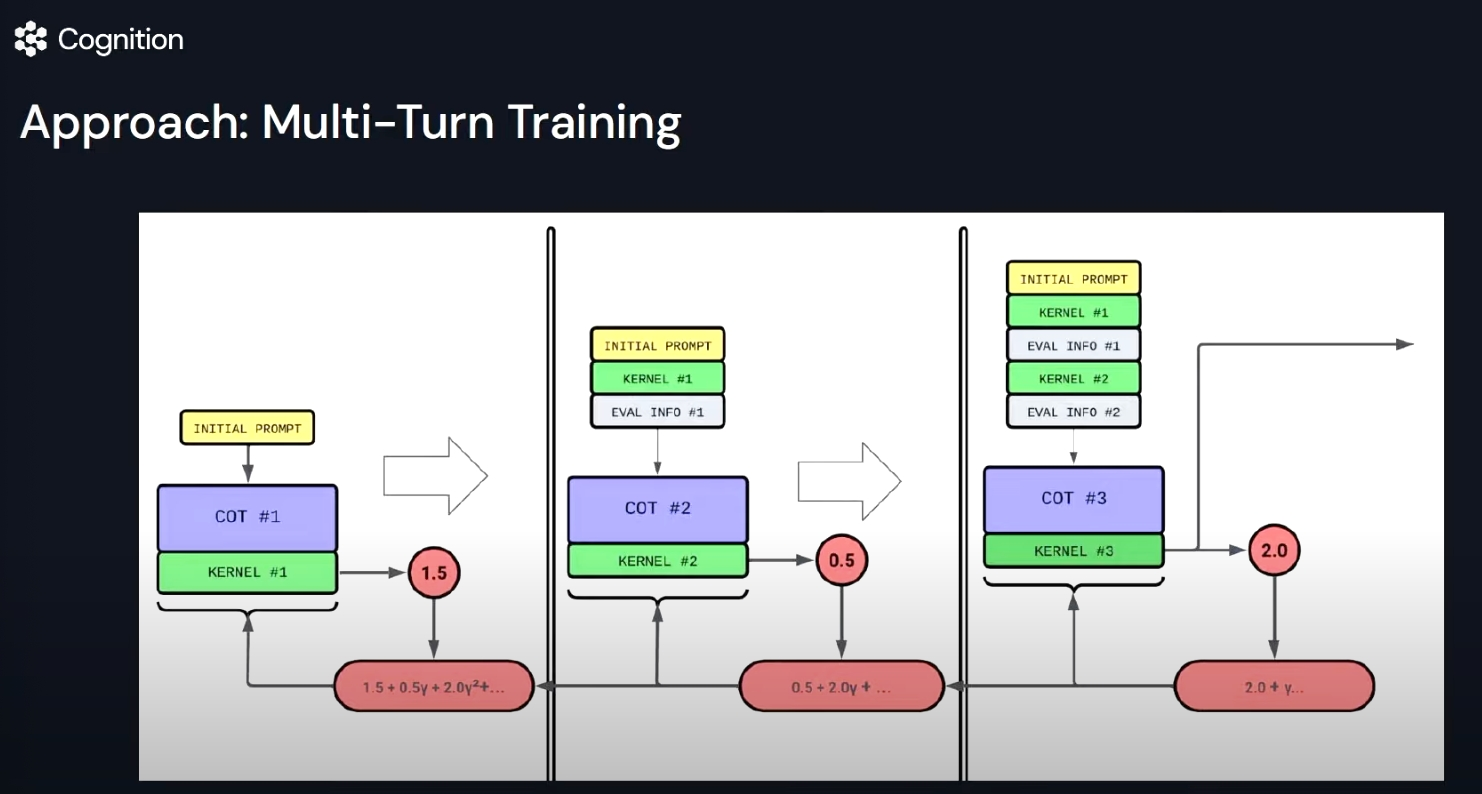
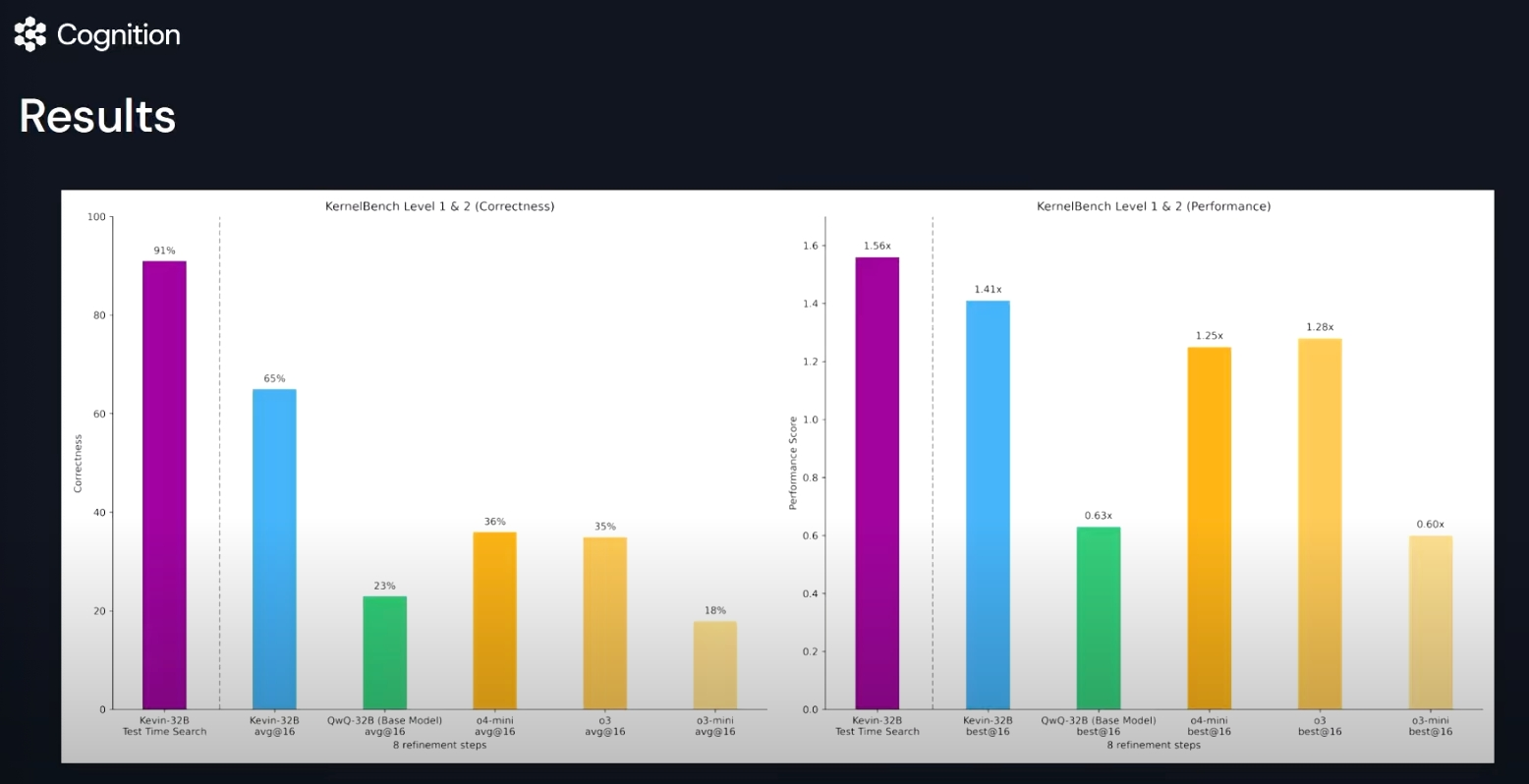
自定义RL优化模型:在窄域内定义明确的奖励信号,引导模型的持续精进,超过通用大模型。
聚焦特定领域价值:模型的精细化优化往往在企业级场景中效果更显著,更有实践价值。
计算为强化训练瓶颈:在进行RL后训练时,要注意计算资源的合理配置与高效利用,而不是一味追求数据量的增加。
🔗 延伸阅读与资源链接
📃 官方博客:Cognition Devin 2.0 Blog
📚 官方文档:Devin Docs
✍️ 技术深度解析:Agent-Native Development 技术详解 (Medium)
🛠️ 开源实践参考:LangChain SourceCode Loader示例
🚀 互动讨论
在你的具体业务或开发工作中,你认为用定制化后训练的AI模型能解决哪些目前痛点?欢迎在评论区与我们分享你的想法和经验。
🏷️ 关键词
#AI开发助手 #大型代码库 #Devin #DeepWiki #ParallelDevins #MachineSnapshot #软件工程自动化
