


 5
5 0
0🧭 本期导引
我们将解读腾讯AI团队最新发布的论文 MobileGUI‑RL,提出了一个在真实在线环境中训练 GUI 智能体的端到端强化学习框架。它不再依赖离线轨迹,而是真正从环境中学习,实现更强泛化与灵活性。
🚩 解决的核心问题
- 离线训练过拟合严重:传统依赖预收集轨迹,无法适应界面差异,很脆弱 交互策略弱:监督或离线 RL 对长序列任务的稀疏奖励处理不好,泛化能力差
- 成本高且不可扩展:标注成本大,难以覆盖交互多样性 。
🧩 MobileGUI‑RL 的三大创新
- 在线训练环境:并行运行多个 Android 模拟器,异步生成轨迹与训练,实现真实交互 。
- 自动生成任务课程(Curriculum):通过模糊自探索生成任务,再经文本模型筛选,构建任务学习曲线 。
- MobGRPO 强化算法:
– 基于 GRPO 优化,引入轨迹级优势估计;
– 多组件奖励设计:成功、效率、早退惩罚等,使奖励更密集、有梯度
🔄 全流程架构概览
- 环境搭建:大量 Android 模拟器并行交互。
- 任务自探索:随机游走 GUIs + GPT-4o 逆推任务指令。
- 任务筛选:文本世界模型模拟交互,保证任务可解。
- 在线 RL 训练(MobGRPO):收集轨迹,奖励设计,优化策略。
- 模型评估迭代:每轮更新后继续生成任务与训练,形成闭环。
📊 核心实验数据
使用 MobileGUI‑7B 与 32B 两版模型,在三大在线基准上获得强劲提升:
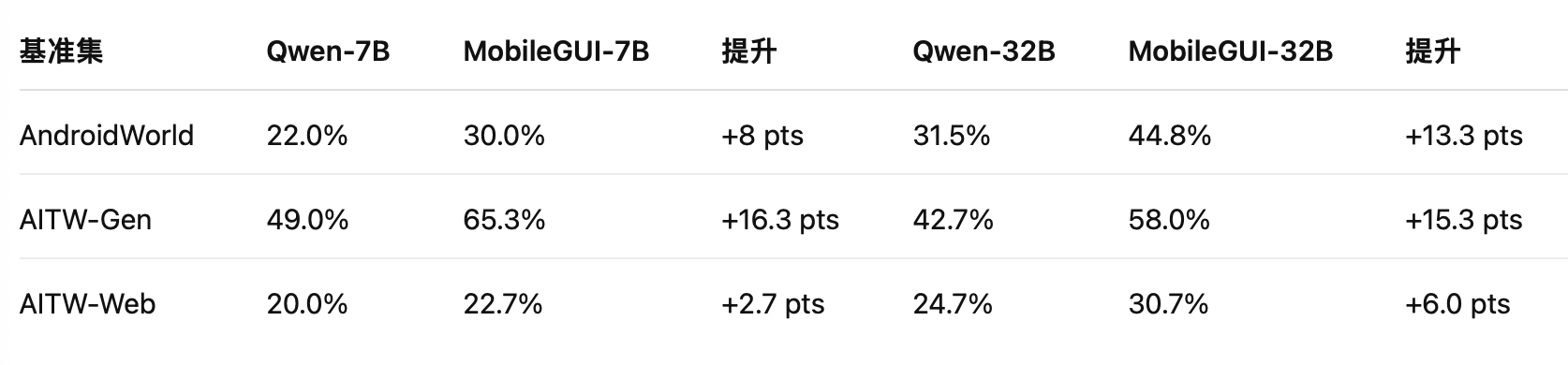
🔎 特别亮眼的是 MobileGUI‑32B 在 AndroidWorld 上击败 GPT‑4o,与 Qwen‑72B 腾挪,展现实用价值 。
🧪 消融实验:组件有效性验证
移除关键组件后的性能显著下降(以 AndroidWorld 为例):
- 无任务筛选:32B 从 44.8% 降至 41.0%
- 无课程学习:32B 降至 34.0%
- 无效率奖励:32B 降至 35.5%
三大模块均有 3‑10pts 的贡献,强化了设计必要性 。
🌟 总结与洞察
MobileGUI‑RL 展现了将 Vision‑LLM 与强化学习结合、转向端到端在线训练的可行路径,显著改善了 GUI 智能体在真实环境中的性能与泛化能力。
其架构亮点在于:环境真实 + 自动课程 + 稠密奖励 的协同作用,实现了“经验驱动 vs 静态轨迹”的范式转换。
🚀 总结
- ✓ 方法上:突破了离线训练瓶颈,为 GUI Agent 打开实用大门。
- ✓ 架构上:兼顾可扩展性、样本效率与策略泛化,适配移动生态复杂度。
- ✓ 未来方向:将目标朝向视觉 world model、分级任务、个性化学习迈进,是下一步关键走向。
📚 参考资料
- 论文全文:MobileGUI‑RL (arXiv:2507.05720)
- 在线阅读页面:arXiv 详细说明
