


 6
6 0
0引言|把“追新”按下暂停键
大家好,欢迎来到本源进化。
今天我们聊一个常见却容易跑偏的话题:在铺天盖地的 AI 新闻里,怎样把应用真正做稳、做成、做出价值。
你可能刷到过那张火爆的对比图:左边是“大家以为的改进方式”——天天追最新模型、纠结框架、向量数据库;
右边是“真正有效的方式”——和用户深聊、把数据喂好、把流程打通、把系统做稳、把提示词练熟。扎心,但准。
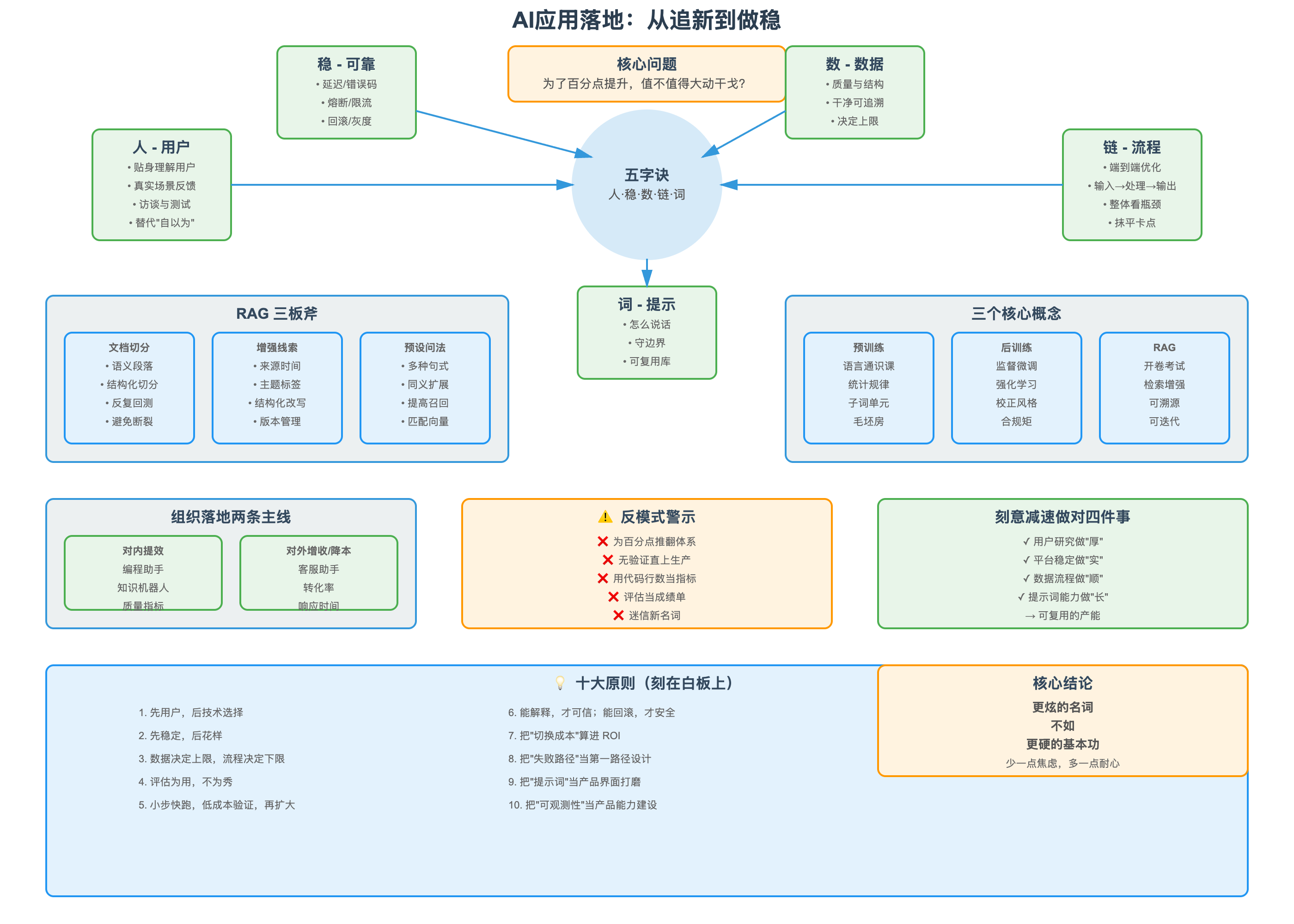
问题|为了一点点提升,值不值得大动干戈?
现实里的两难经常出现:一个新技术宣称有百分点级的性能提升——要不要马上切?
- 切换意味着迁移成本、回滚代价、不可预期风险;
- 新技术尚未大规模实战验证,你很可能成为“试错者”。
多数时候,不值得。这不是反对创新,而是强调以价值和时机为先:先问清用户价值、业务目标、ROI,再决定是否切换。
范式|人 · 稳 · 数 · 链 · 词(五字诀)
- 人:贴身理解用户与场景——看他们怎么用、何处卡顿、为何吐槽,用真实反馈替代“自以为”。
- 稳:把底座做“可用、可靠、可观测”——延迟、错误码、熔断、限流、回滚、灰度,这些都是体验的地基。
- 数:数据质量与结构并重——干净、成体系、可追溯,决定 AI 能力上限。
- 链:端到端看流程——从输入→处理→输出整体优化,而非只盯模型那一环。
- 词:提示词/交互——“怎么跟模型说话”,决定模型是否懂你、是否守边界。
结论:看起来不酷,却是最管用、最能复用的能力。
概念扫盲|预训练、后训练、RAG 一次讲清
预训练:一门“语言通识课”。
- 模型在海量文本上学习语言的统计规律,处理单位是子词单元(介于字母与整词之间),既懂词根也能泛化形态变化。
- 只做预训练的“基础模型”像毛坯房:知识多,不一定会“对话”。
后训练:把毛坯房变成“可居住”的空间。
- 监督微调:用高质量“问-答”范例继续训练,校正风格、格式与边界;必要时用蒸馏让小模型模仿强模型,以更低成本取得相近效果。
- 基于人类反馈的强化学习:模型先给多种回答,由“裁判”给偏好/好坏反馈并强化正确倾向;裁判可以是真人、更强模型,或可验证奖励(代码能否跑通、算式是否正确)。
目的:不是“变魔术”,而是让模型更合人心、合规矩。
检索增强生成(RAG):开卷考试。
- 先从你的资料库检索相关片段,再与问题一起送入模型,答案更贴场景、可溯源、可迭代。
- 真正决定成败的不是“哪家向量库”,而是数据准备与检索策略。
实验|RAG 的三板斧与常见细节
- 文档切分(Chunking)
太长:一块里混入多个主题,检索“命中却看不懂”。
太短:上下文断裂,模型“拼不回去”。
做法:按语义段落/标题层级切分;对代码/表格/FAQ 采用结构化切分;结合检索表现反复回测粒度。 - 增强线索(Contextual Signals)
给每个分块补充来源、时间、主题、标签、短摘要;
必要时对难读材料做结构化改写(如 Q&A、关键点清单、术语释义);
对动态内容加版本/生效日期,避免把过期规则检索出来。 - 预设问法(Query Expansion)
为每块内容提前生成多种提问句式(同义、口语、近义);
检索时同时匹配原问题与预设问法向量,常能显著提高召回与相关度。
再强调:RAG 成败常常取决于这些“看不见的细活”,这就是决定上限的地方。
组织|企业落地的两条主线
对内提效(编程助手、内部知识机器人)
- 价值感知主观、量化困难;与团队水平、工程文化、质量标准强相关。
- 顶尖工程师能放大价值,也可能因质量洁癖而抵触。关键是正确定义“好”的指标(可维护性、缺陷率、评审时长、故障恢复时间等),而非“代码行数”。
对外增收/降本(客服、销售助手、自动预订)
- 指标清晰、闭环可度量:转化率、首次响应时间、问题一次性解决率、单位成本等;
- 更容易拿到管理层支持,但也要重视合规、可解释与仲裁机制。
评估为用,不为秀
- 高风险场景(医疗、金融、法务):建立严密、持续的离线与在线评估,覆盖公平性、鲁棒性、安全边界。
- 低影响小工具:控制评估成本,盯住投入产出比;用抽样质检+关键指标即可。
- 评估的价值是发现问题与指引改进,而不是“给自己贴分数”。
反模式|这些习惯请尽量避免
- 为百分点级潜在提升,贸然推翻现有体系;
- 无验证直上生产,轻视迁移、回滚、容灾;
- 用**“代码行数”**充当提效指标;
- 把评估当成绩单,而非迭代清单;
- 过度迷信“新名词”,忽视数据与流程这两块硬功。
放慢|刻意减速,做对四件事
- 把用户研究做“厚”:访谈、可用性测试、任务回放,沉淀典型场景/反例/金句吐槽。
- 把平台稳定性做“实”:建立仪表盘、告警、追踪链路,让问题可见、可复盘、可回滚。
- 把数据与流程做“顺”:从输入—处理—输出梳理瓶颈;排队、重试、缓存、落盘,一步步抹平“卡点”。
- 把提示词能力做“长”:规范系统提示词、角色设定、边界条件、负样例;形成可复用的提示词库与A/B 评测流程。
扩展视角|团队与行业的变化
- 组织边界更模糊:工程、产品、设计深度融合成为常态;复合型人才更吃香。
- 自动化重塑角色:标准化工作更多由 AI 或初级工程师在指导下完成;资深工程师转向架构、规范与质量。
- 创新重心上移:从追“基础模型飞跃”转向应用层创新——更好的后训练、RAG 策略与场景设计。
- 推理时间更长:为更高质量的单次输出,用算力换思考,在关键场合追求“慢即是快”。
- 多模态机会巨大:语音/图像/视频融合带来新交互,但也引入延迟、打断、合规等新挑战。
总结|更炫的名词,不如更硬的基本功
要真正创造价值:
- 读懂 预训练、监督微调、基于人类反馈的强化学习、RAG 能做什么、不能做什么;
- 用评估做改进工具,而不是 KPI;
- 把资源投在人、稳、数、链、词上,稳扎稳打,少走弯路。
原则|十句话刻在白板上
- 先用户,后技术选择
- 先稳定,后花样
- 数据决定上限,流程决定下限
- 评估为用,不为秀
- 小步快跑,低成本验证,再扩大
- 能解释,才可信;能回滚,才安全
- 把“切换成本”算进 ROI
- 把“失败路径”当第一路径设计
- 把“提示词”当产品界面打磨
- 把“可观测性”当产品能力建设
思考题|从一个小痛点开始
回看你过去一周:有没有一个最别扭、最低效的小环节?挑出它,问自己:
- 我要的理想结果是什么?
- 现状的主要阻碍在哪里?
- 能否用 AI 做一个**“只为我好用”**的小改造(哪怕是自动化一个重复动作)?
- 明天就能开始的最小行动是什么?
从这里起步,你会更快地把“AI 焦虑”变成“可复用的产能”。
——今天就到这儿。愿我们少一点焦虑,多一点把事做稳的耐心。下次见。
