


 4
4 0
0从 RAG 到 Agent Memory:AI 如何从只读走向读写与“会记住你”的对话
开场:换个角度理解“AI 的记忆”
Hello,大家好,欢迎来到「本源进化」。最近你可能经常听到:AI 有短期/长期记忆,甚至还分什么程序性、情景性、语义性记忆。听着有点复杂?今天我们换个角度,不纠结定义,从你更熟悉的技术路径讲起——RAG(Retrieval-Augmented Generation,检索增强生成)。
沿着这条线,我们看看 AI 如何从“只会帮你找资料的小助手”,一步步进化到更会即兴、更能学习、还能记住你的伙伴。准备好了吗?出发。
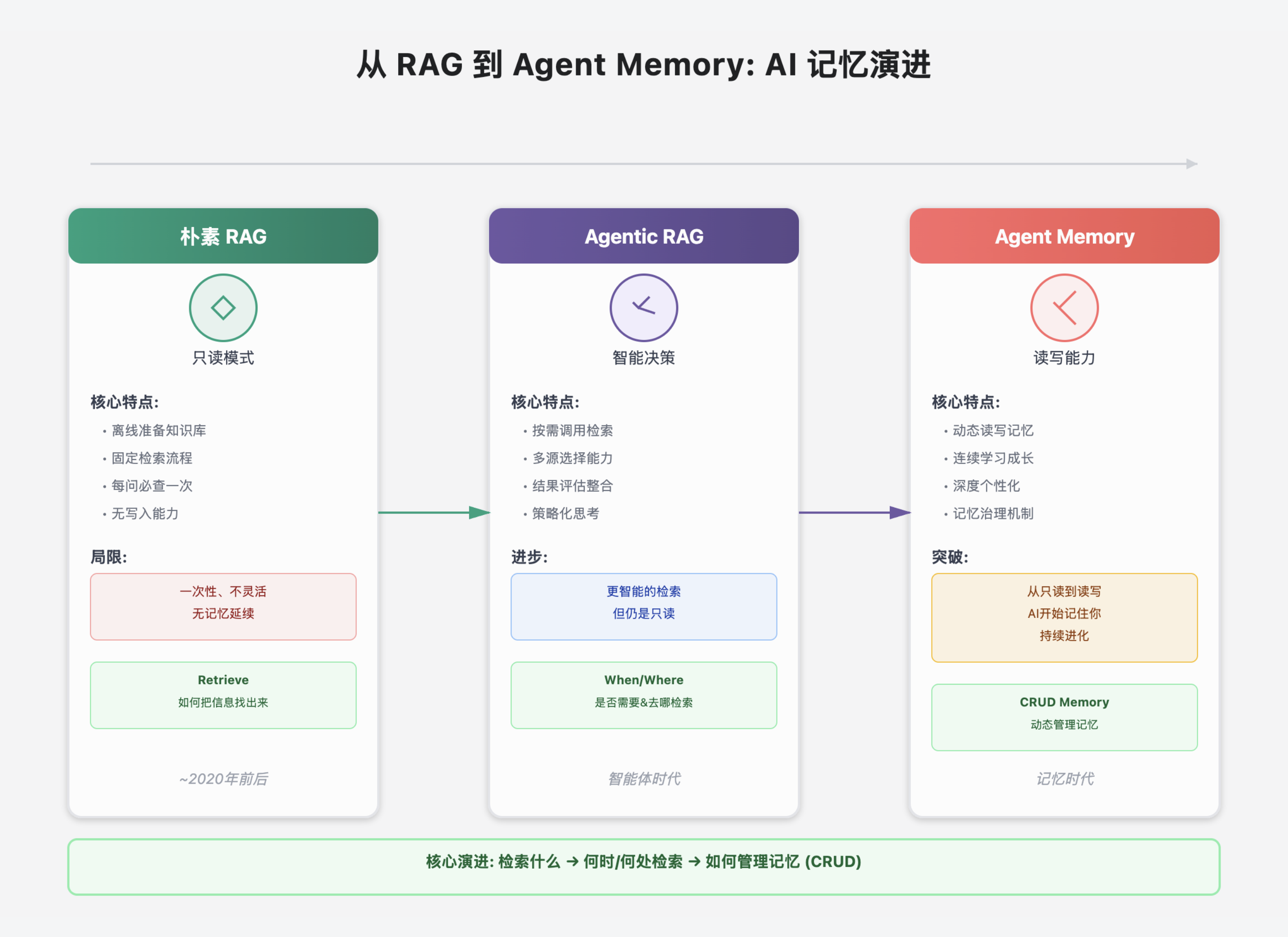
一、朴素 RAG:一次性、只读的“找资料 + 参考”
最早的语言模型像一个学得不错但记性一般的学生:只记得“训练时写进参数里的知识”(参数化知识)。问到新信息或教材外的具体事,它就容易不知道。
于是大约在 2020 年前后,大家提出了 RAG:
- 离线准备(Offline):把最新报告、公司文件、个人笔记等处理建库,常用向量数据库按“语义相近”存取。
- 在线检索(Online):用户提问 → 先去外部知识库检索相关片段 → 把“问题 + 检索到的片段”一起交给大模型参考作答。
价值:显著降低幻觉,在实时信息/垂直知识问答场景里效果明显。
核心局限:
- 一次性只读:基本每问必查;通常只查一次,不评估“是否靠谱/是否足够”;且只面向预设的单一知识库,不灵活。
- 后果:遇到多步推理/跨源核验问题,或检索命中不准,答案质量仍不稳定。
直观比喻:像给模型递一张小抄。它不能挑、不能换、看完就忘;下一次还是得从头来。
二、Agentic RAG:让“检索”成为按需调用的工具
下一步,登场的是 Agentic RAG(能动式/自主式 RAG)。升级点在于:
检索不再是“写死、默认执行”的固定环节,而是一个可选工具,由更聪明的 Agent(智能体)来决定是否需要、何时调用、调用哪一种。
关键改进:
- 有了基本决策:先判断“凭参数化知识能否回答”,再决定要不要查。
- 多源选择:可选内部知识库、公网搜索、特定数据库/API等;来源更灵活。
- 结果评估与整合:拿到命中文档后,会评估相关性/可信度,再决定如何融入回答。
流程更像“研究助理”:
思考 →(若需要)调用检索工具 → 评估/整合 → 生成答案。
相比朴素 RAG,它更策略化、更贴近人类解题思路。
但仍有一个硬限制:对外部知识库,本质依然只读。
也就是说,Agent 会“读”并“用”外部信息,但无法在对话过程中把新信息写回知识库;学到的东西下回未必还能用(除非人工更新)。
三、Agent Memory:从“只读”到“读写”,AI 开始记住你
真正的跃迁发生在 Agent Memory(智能体记忆):写能力被引入流程。
具备记忆的 Agent 不仅能读取(检索外部知识),还可以在互动中动态地“写入/更新/删除”自己的外部记忆库——把有价值的信息长期沉淀。
直接带来的变化:
- 从“孤立对话”到“连续成长”:每次互动不再是“从零开始”,Agent 会继承以往经验。
- 更深的个性化:记住你的偏好/习惯/计划(如“喜欢简洁回答”“下周去北京出差”),在后续对话中主动适配。
- 写入策略(示例):
存完整对话记录或自动摘要;
识别偏好/事实并写入记忆条目(如“偏好先给结论再给依据”)。
简言之,Agent 不仅会在需要时调用检索工具去读,也会在“发现新信息”时调用记忆工具去写。系统开始形成一个关于世界、也关于你的动态知识与经验体系。
四、超越线性:更像“人脑”的多类型记忆与治理
上面的“三段进化史”是理解框架。但在真实系统里,记忆远比线性模型复杂:
1)多类型记忆(职能分工)
- 程序性记忆:对操作/风格/习惯的掌握(如“这位用户偏爱正式语气、需要要点式输出”)。
- 情景性记忆:对具体事件/对话片段的记录(如“昨天下午 3 点问过 XX 价格”)。
- 语义性记忆:对客观事实/通用知识的沉淀(如“地球是球形”)。
- 原始日志:最原始的会话全文备份,作为必要时的回溯底座。
2)记忆治理(Memory Governance)
核心问题是:记什么、留多久、怎么找、怎么忘。
- 筛选与强化:哪些成为核心长期记忆,哪些只是短期缓存。
- 时效与过期:对过时/失准信息进行降权或清除。
- 遗忘机制:避免“记忆库膨胀”和“噪声侵占”,让系统保持稳定与可控。
- 污染防护:防止误解/攻击性输入被固化为“错误记忆”。
五、三阶段核心差异(速记版)
- 朴素 RAG
知识库:离线准备
检索:固定、基本每问必查、只查一次
写入:无(只读)
对话延续:弱(次次从头来) - Agentic RAG
知识库:离线为主
检索:按需调用、多源选择、带评估整合
写入:无(仍是只读)
对话延续:一般(策略更优,但不沉淀) - Agent Memory
知识库:在线可读/写/改/删
检索:按需 + 多源 + 评估整合
写入:有(动态记忆:偏好/事实/摘要/原始日志)
对话延续:强(连续学习与个性化)
六、机会与风险:潘多拉魔盒也需要“使用手册”
机会:
- 学习性:越用越懂你,任务完成度与效率持续提升。
- 个性化:对偏好/语境/历史的理解不断加深。
- 自治度:形成可自我更新的知识与经验库。
风险与挑战:
- 记忆污染:误解或错误信息被错误固化,后续持续带偏。
- 治理复杂度:何时写入、写入质量门槛、如何索引/裁剪/过期、何时遗忘。
- 边界与合规:隐私、权限、可解释性与安全需要制度化设计。
七、总结:从“检索什么”到“如何管理自己的记忆”
我们沿着 RAG 的脉络,看到了 AI 信息处理关注点的迁移:
- 朴素 RAG(Retrieve):重点在如何把信息找出来。
- Agentic RAG(When/Where to Retrieve):重点转向是否需要检索与去哪检索。
- Agent Memory(Create/Read/Update/Delete Memory):焦点落在信息如何被动态管理,即创建/读取/更新/删除自己的记忆。
当 读写记忆成为能力拐点,AI 不再只是“被动问答机”,而是在与你的每次互动中,主动构建并维护一份关于你与世界的“活的记忆”。
结尾的两道思考题
- 既然我们在赋予 AI 动态写入与管理记忆的能力,该如何设定规则与边界,确保被记住的内容准确、有益、符合人类价值?
- 对一个能不断学习的 AI 来说,遗忘扮演着怎样的角色?为什么“学会忘记不再相关甚至有害的信息”,可能和“学会记住”同样重要?
感谢你的阅读,我们下期继续一起深挖更有价值的洞见。
