12
12 0
0情境工程(Context Engineering):把“聪明但孤立”的模型,变成能解决问题的智能助手
开场:为什么大模型在真实场景里“翻车”?
Hello,大家好,欢迎朋友们来到本源进化。你有没有这样的经历:看发布会上那些大语言模型演示得天花乱坠,感觉什么都能干。可真到了你自己想用它解决点实际问题,比如分析一下公司内部几百页的产品文档,或者让它告诉你昨天行业里发生了啥重要新闻,它就突然“翻车”了——要么是一问三不知,要么就是极其自信地编造一些“事实”,让你哭笑不得。
这到底是为什么呢? 明明看起来像一个很“抽象的大脑”,怎么一到用的时候就掉链子?
这个问题的核心其实不在于模型本身够不够“智能”,关键在于它们往往处于一种断开连接的状态。想象一个拥有惊人计算能力的大脑被关在密室里:
- 它没有连到你手头的具体资料;
- 它也不知道这个世界实时发生了什么变化;
- 甚至你上一分钟跟它说了什么,它下一分钟就可能忘了。
这种与世隔绝的状态,正是我们觉得 AI 应用效果“不行”的根本原因。背后还有一个关键限制:上下文窗口(context window)。这就像模型用来思考和处理当前任务的一块临时记忆。但这块“板子”大小有限——写满新内容时,旧的信息就会被挤掉。
这意味着重要的背景信息、之前的对话记录可能随时丢失。仅靠“如何更好地提问”(也就是优化 prompt/提示词)远远不够——这就像你只给密室里的大脑递一小张纸条,信息太有限。
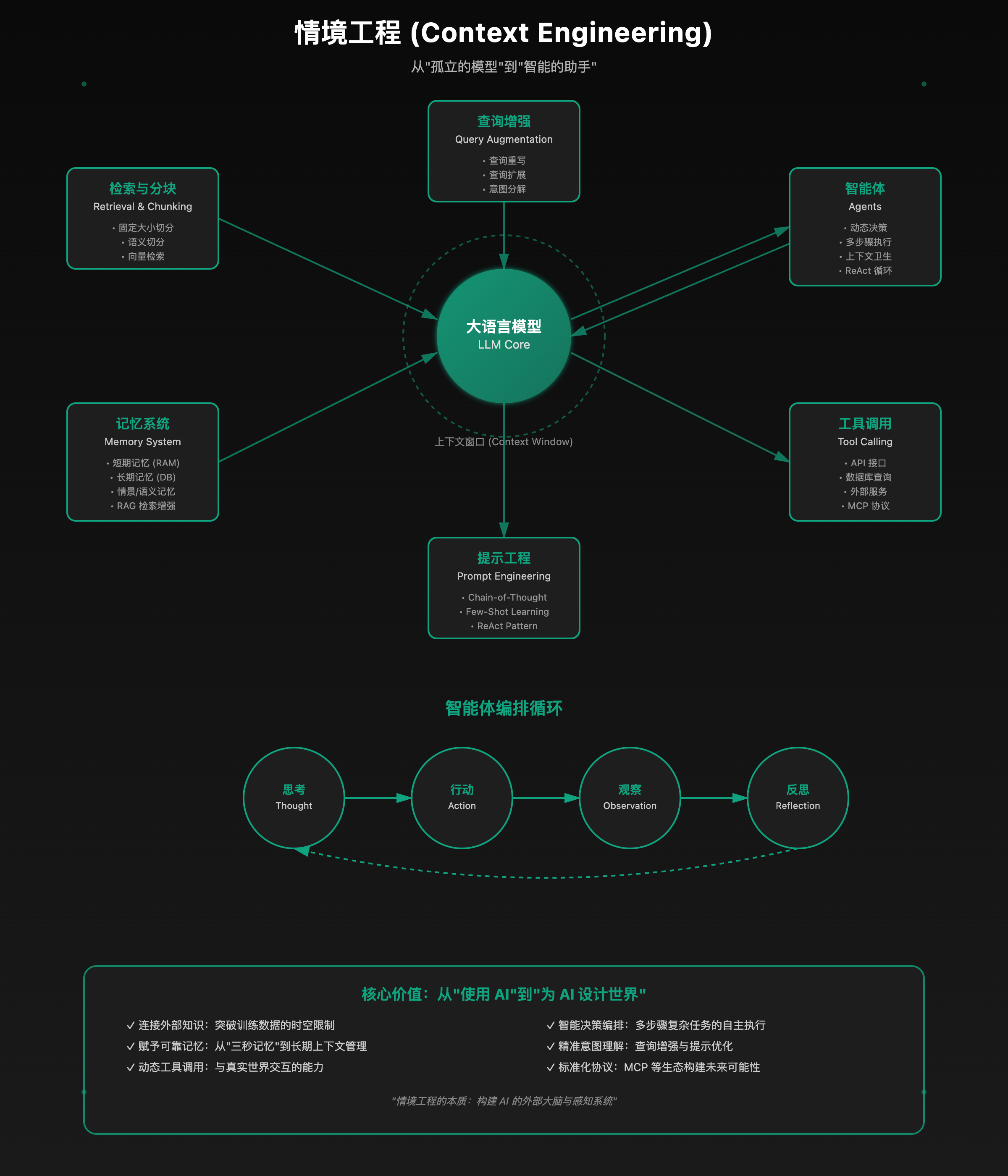
真正要让它发挥威力,咱们得给它搭一个完整的外部支持系统。这正是今天的核心概念:情境工程(Context Engineering)。注意,我们不是给模型“开颅手术”去改它的神经网络;情境工程的重点是设计一套架构/系统,在最恰当的时机把最恰当的信息喂给模型:要能连外部知识库、能调用实时工具、还能赋予模型可靠的记忆力。目标是让回答基于真实相关的依据,而不是仅依赖训练数据里那些可能已过时的“库存知识”。
今天我们就来拆解:如何把一个“很聪明但却孤立”的模型,打造成可靠的、能解决手头具体问题的智能助手。
这就像从给密室里的大脑递纸条,升级到给它装上电话、连上互联网、配上秘书和档案柜。这个比喻很形象。
模块一:检索(Retrieval)与分块(Chunking)
关键挑战:怎么让模型“看到”我们要它处理的信息?
你有一堆海量内部文档(例如十几年的技术报告、所有的客户服务记录),不可能一股脑全塞进那个小小的上下文窗口,肯定装不下。
当用户问一个具体问题,答案可能就藏在几百页文档的某一段里——如何让模型精准找到它?
这就需要检索技术(Retrieval):从庞大的外部信息海洋中,捞出与当前问题最相关的那几片信息“碎片”。
分块(Chunking)的工程权衡
第一步、也是非常关键的一步:把大部头文档有策略地拆分为更小、易理解与处理的单元。怎么拆、拆多大,里面的学问很大,它会直接影响后续检索的准确性与最终答案的质量。
- 切得太细(比如逐句作为一个块)
好处:更容易精确匹配关键词;
坏处:语境缺失,模型难以理解真正意思。
打比方:你问路,人家只说“向左转”,但没说在哪儿转——信息就不够用了。 - 切得太粗(一个块包含好几个段落)
好处:上下文看似完整;
坏处:一个大块可能混杂多个主题,导致其向量表征变得模糊、区分度差,反而降低检索精准度。
比喻:把苹果、香蕉、橙子打成“混合果酱”,味道混了,就很难精准识别“苹果”的特征。
结论:分块的艺术在于找到那个**“甜蜜点”**——既足够小(保证信息纯度和检索精度),又足够大(提供必要上下文)。
常见分块策略
- 固定大小切分(fixed-size chunking):如每 500 个字符切一块,并设置重叠,避免把句子从中间切断。
- 结构感知切分(document/recursive chunking):利用文档的自然结构(标题/段落/列表)来切。
- 语义切分(semantic chunking):分析句子之间的语义关联,把同一子主题的句子聚合,话题明显转换时再切;得到的块内部逻辑更清晰。
预处理 vs. 后处理
- 预处理(pre-chunking):把所有文档一次性切好并向量化入库;优点响应快,缺点灵活性差。
- 后处理(post-chunking):先大致定位到相关文档,再针对问题动态分块;优点更灵活、可按问题优化,缺点响应时延略增。
每一步都有取舍。
模块二:记忆(Memory)——摆脱“三秒记忆”
我尤其喜欢 Andrej Karpathy 的比喻:上下文窗口像 RAM,模型像 CPU(模型很宝贵、容量有限)。记忆系统的本质,就是为模型扩展这块有限的工作内存。
记忆类型
- 短期记忆:本轮对话的内容,尽量直接放在上下文中,保证对话连贯(像我们的大脑“工作记忆”)。
- 长期记忆:更早的对话记录、用户偏好、关键事实和知识,存放在外部数据库(常用向量数据库)。
当需要“回忆”往事时,通过检索增强生成(RAG, Retrieval-Augmented Generation)把相关内容捞回来,再放入当前上下文。
进一步细分:
情景记忆(episodic memory):记录具体事件与对话过程;
语义记忆(semantic memory):存储一般性事实、概念和知识。
记忆管理四原则
- 选择性存储:只存对未来交互有价值的信息,避免噪音污染记忆库。
- 高效检索:需要的时候能又快又准地找回来。
- 定期维护:定期回顾、修剪、提炼,删除过时/重复/错误信息,避免错误被反复提取。
- 按任务定制:不同场景需要不同记忆架构(如闲聊问答 vs. 长期项目跟踪)。
结论:记忆系统设计,直接关系到 AI 应用能否长期稳定、可靠、智能。
模块三:智能体(Agents)与上下文卫生(Context Hygiene)
很多时候,光“能看、能记”还不够。要解决复杂问题,模型需要做判断:我现在该干嘛?信息够不够?要不要查最新数据?需不需要调用外部工具?这类需要动态决策、多步骤执行的任务,就需要“智能体(Agent)”登场。
把智能体想象为大脑皮层/总调度师:
- 不再只是固定的“检索-思考-回答”;
- 能按当前目标与环境反馈动态制定计划与决策;
- 会判断:去记忆库搜?去外部数据库查?调用哪个工具?如果走不通,能调整策略再试。
可以说,智能体既是上下文的构建者(决定要哪些信息),也是上下文的使用者(依赖这些信息做决策)。
智能体的上下文挑战
随着轮次增多、任务变复杂,智能体的上下文管理会很“棘手”:
- 上下文过载(overload):历史对话/工具结果塞满窗口,抓不住重点;
- 上下文干扰或混淆(distraction/confusion):噪音或模糊的工具描述误导决策;
- 上下文冲突(clash):短期/长期记忆与工具结果相互矛盾而“卡壳”;
- 上下文中毒(poisoning):错误或幻觉信息进入上下文并被反复依赖,任务跑偏。
因此,“上下文卫生(context hygiene)”至关重要:
要压缩历史、过滤噪音、检测并处理冲突、溯源与纠错,保持“清醒的工作记忆”。
模块四:工具(Tools)与函数/工具调用(Function/Tool Calling)
工具是把大语言模型与真实世界/数字世界连接起来的桥梁:
查天气、查数据库、控制软件、通过 API 订票,甚至操作硬件——都靠它。
早期有人尝试靠 Prompt 暗示指令,但不稳定。真正的突破是函数/工具调用能力:模型直接输出结构化指令(通常 JSON),例如:
工具名:查询航班;参数:{"from":"北京","to":"上海","date":"明天"}这种方式可靠、可控,降低沟通歧义。
智能体编排(Orchestration)循环
思考(Thought)→ 行动(Action:选工具+填参数)→ 观察(Observation:看结果)→ 反思(Reflection)
不断迭代,直到完成任务或判定无法完成。这与人类解决复杂问题的思维过程高度相似。
走向标准化:MCP(Model Context Protocol)
社区提出了 MCP(模型上下文协议),愿景是成为“AI 的 USB-C”。
让各类外部工具/API/数据库都按照统一协议对接模型,开发者把精力聚焦在智能体逻辑与编排策略,而不是为每个接入写一堆转接代码。这将极大加速更强大、更通用 AI 应用的诞生。
模块五:查询增强(Query Augmentation)
第一公里的理解很关键。用户自然语言往往随性、模糊、含歧义、甚至多意图。
例如:“帮我看看北京最近咋样,顺便推荐个吃饭的地方呗。”——它包含天气查询与餐馆推荐两种意图,还带口语化表达。若直接扔给检索系统或智能体,效果可能不理想。
因此,在处理之前对原始查询进行预处理与增强尤为重要:精准捕捉真实意图,并把它转成后端模块(检索/智能体)更易理解与执行的结构化指令。
常用方法
- 查询重写(query rewriting):把口语化问题改写为清晰、结构化的形式,去掉与意图无关的闲聊噪音。
- 查询扩展(query expansion):基于原问题生成多个语义相近的变体,扩大召回(但注意别扩张过度导致失焦)。
- 查询分解(query decomposition):把复杂问题拆成可独立处理的子任务(如“北京天气”与“餐馆推荐”)。
- 查询智能体(query agents):既懂自然语言,也理解后端数据模式(schema),可动态生成SQL等精确查询;还能评估返回结果的相关性,不满意则自我调整策略重试。
模块六:提示工程(Prompt Engineering)与情境工程的关系
- 提示工程:关注与大模型对话的最终指令文本(prompt)——如何清晰表达意图、格式、风格,让模型更准确地按模板输出、减少误解。
- 情境工程:关注宏观系统层面——围绕模型构建其运行所需的外部信息环境与交互架构:检索、记忆、智能体、工具、查询增强等。
比喻:情境工程像是搭舞台与后台系统;提示工程像是指导台上演员(LLM)的语气/表情/台词。两者相辅相成、缺一不可。
事实上,情境工程里也包含提示工程元素——比如为工具写清晰准确的工具描述(tool description),直接影响智能体能否正确理解与选择工具。
常用提示技巧
- Chain-of-Thought(CoT,思维链):在提示里要求“一步步思考(Let’s think step by step)”,显著提升多步推理任务的准确度。
- Few-Shot Prompting:在指令里给出若干输入-输出范例,帮助模型对齐格式/风格/约束(模板化输出、风格迁移等场景尤为有效)。
- Tree-of-Thoughts(ToT):探索多条推理路径再择优。
- ReAct:把思考与工具行动紧密结合,边想边做。
总结:从“用 AI”到“为 AI 设计世界”
我们正在经历一个重要转变:从“作为用户去提问下指令”,到“作为架构师去设计与构建 AI 所居住与感知的信息世界”。
一个真正强大的、能解决复杂问题的 AI 应用,其核心竞争力未必只在“底座模型多大多聪明”,更在于围绕模型搭建的情境工程系统是否精良、高效、可靠、可复现。
思考题:当你不再满足于“使用 AI”,而是开始为它构建外部大脑与感知系统(检索、记忆、智能体、工具、查询增强、提示工程),这会如何改变你解决问题的方式与可达高度?
当 MCP 等标准化协议日益成熟与普及,我们又将看到哪些今天仍难以想象的全新 AI 能力与应用场景涌现?
——感谢收听本期《本源进化》,我们下期再见。