

 6
6 0
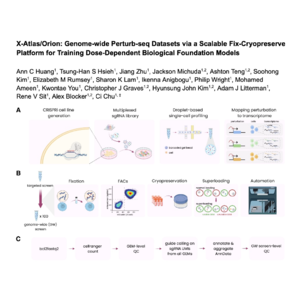
0这篇文章介绍了 FiCS Perturb-seq,这是一个工业化平台,用于以可扩展且一致的方式生成大规模的 Perturb-seq 数据集,从而克服了先前方法中存在的瓶颈。该平台通过结合可逆化学固定、低温保存和自动化等技术,实现了高灵敏度、低批次效应的基因组范围扰动数据生成。研究人员利用 FiCS Perturb-seq 平台创建了迄今为止最大的公开 Perturb-seq 资源,即包含八百万个细胞的 X-Atlas/Orion 数据集,该数据集覆盖了所有人类蛋白质编码基因。这些数据对于训练能够纳入基因剂量效应的先进生物学基础模型至关重要,从而有望加速生物学发现和治疗方法的发展。
References:
- Huang A C, Hsieh T H S, Zhu J, et al. X-Atlas/Orion: Genome-wide Perturb-seq Datasets via a Scalable Fix-Cryopreserve Platform for Training Dose-Dependent Biological Foundation Models[J]. bioRxiv, 2025: 2025.06. 11.659105.
