6
6 0
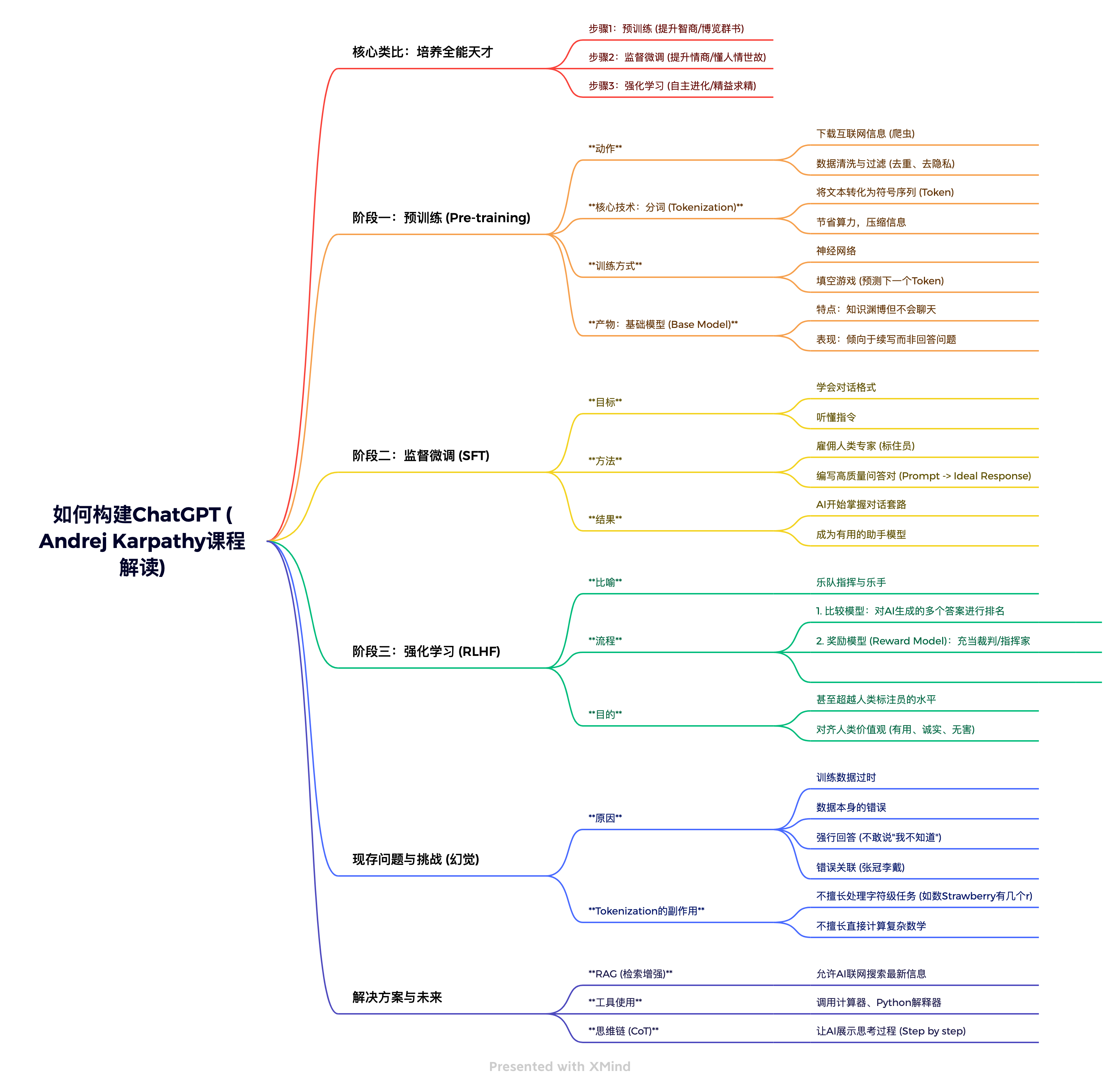
0这周呢,一起来学习的课程是Andrej Karpathy《如何构建chatgpt》,如果你也被像SFT、标注、分词、幻觉这样的名词搞得云里雾里,那么这期节目非常适合你去收听。本期我们将大家拆解构建大语言模型的三个阶段:训练、监督微调、强化学习,一起来了看看大语言模型是如何炼成的!
你将听到:
l Andrej Karpathy 是谁?为什么他的课值得听?
l 为什么说Token是AI的语言?
l 如何通过打分和奖励机制,让AI的回答更符合人类价值观?
l AI的幻觉与缺陷 —— 为什么ChatGPT有时候会一本正经地胡说八道?
相关名词:
l Large Language Model (LLM):一种通过在海量文本上训练,能够理解和生成自然语言的人工智能模型。
l Token (分词):将文本拆分后供模型处理的基本单位,可以是词、字或子词。
l SFT (监督微调):用高质量问答数据对预训练模型进行微调,使其学会遵循指令、输出有用格式。
l RLHF (基于人类反馈的强化学习):通过人类对模型输出的偏好反馈来训练和优化模型,使其回答更符合人类价值观(安全、有用)。
l Hallucination (幻觉):模型自信地生成看似合理但事实上错误或虚构的内容。
时间戳
01:45 培养AI就像培养天才:智商、情商与自主学习的三阶段类比。
02:30 阶段一:预训练 (Pre-training)。
08:50 基础模型 (Base Model) 的特点:高智商但不懂社交的“书呆子”。
09:40 阶段二:监督微调 (SFT)。
11:30 阶段三:神经网路训练与强化学习 (RLHF)。
15:00 AI的局限性与幻觉。
18:10 解决方案与未来展望。
本期思维导图