

 2
2 0
0
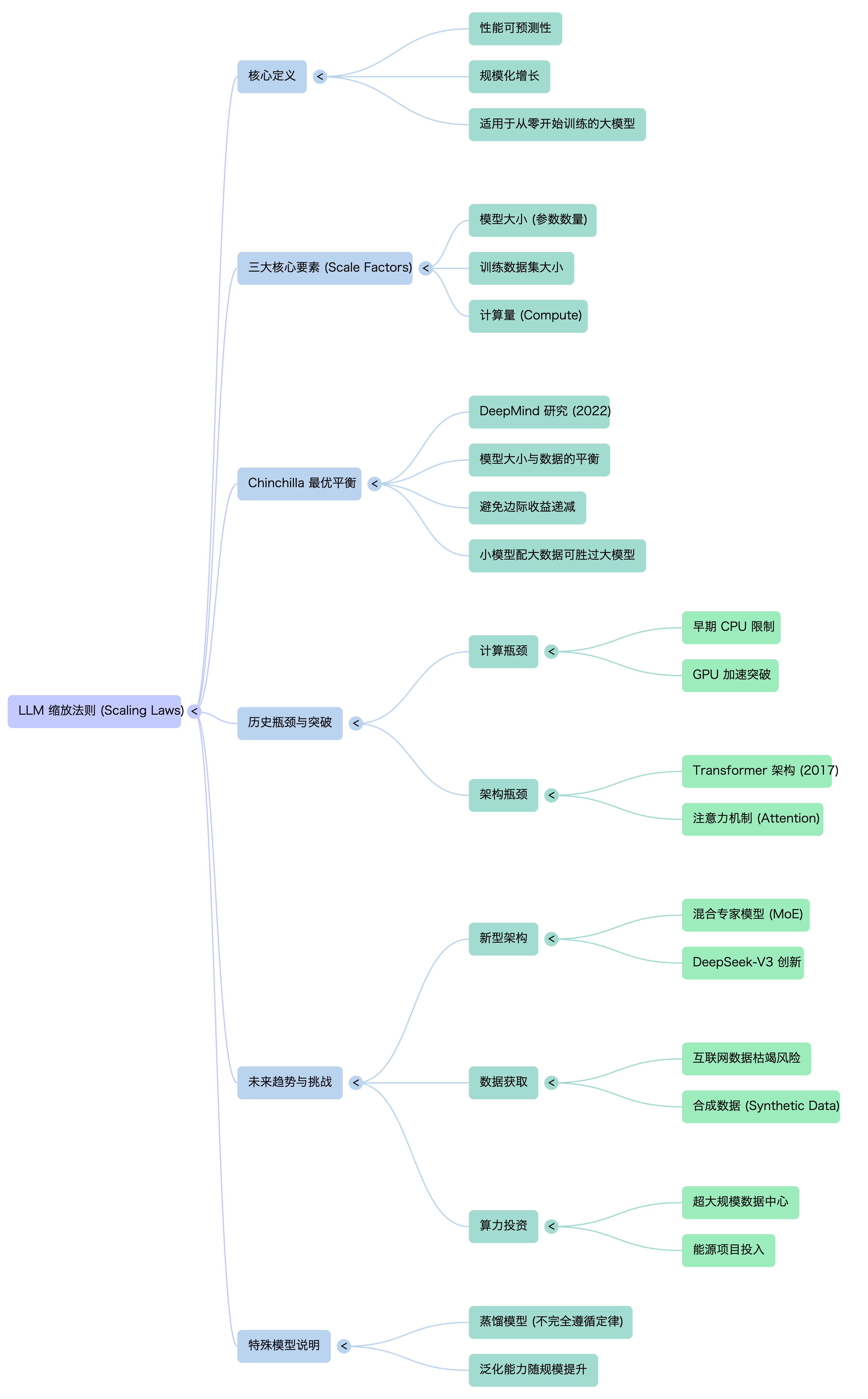
在 AI 领域,曾有一个简单粗暴的信条:堆算力、堆数据、堆参数,就能换来更智能的模型。但这条看似无限的“扩展定律”,其实暗藏着精妙的平衡艺术。本期内容将深入拆解大语言模型性能增长背后的核心法则。你将了解到,决定模型能力的三大支柱如何相互制衡,以及 DeepMind 的 “Chinchilla” 研究为何颠覆了“越大越好”的认知——原来,一个在巨量数据上充分训练的小模型,完全可以战胜资源错配的庞然大物。我们还将追溯从 GPU 到 Transformer 的技术革命如何一次次重写增长曲线,并展望在数据枯竭的阴影下,MoE 架构与合成数据如何引领下一场突破。
DeepMind's Chinchilla is a highly efficient, 70-billion-parameter large language model (LLM) introduced in 2022, revolutionary for proving that smaller models trained on significantly more data (tokens) outperform much larger, undertrained models like Gopher, leading to better performance with less computational cost for inference, making advanced AI more accessible.
在 Chinchilla(2022年)出现之前,OpenAI 的 GPT-3(1750亿参数)和 DeepMind 自家的 Gopher(2800亿参数)等模型引领了一股“军备竞赛”:大家都在追求更大的模型参数量,认为这是提升性能的关键。这些超大模型虽然很强,但训练成本极高(数百万美元),运行(推理)成本也非常昂贵,难以广泛应用。同时,它们在给定计算预算下可能并非最优解。
Chinchilla 团队通过严谨的实验,发现了一个关键规律:对于一个给定的计算预算(即用于训练的总浮点运算量),模型大小和训练数据量需要按比例平衡增长。
Chinchilla 的核心意义在于,它颠覆了当时“模型越大越好”的普遍认知,证明了“用更多的数据、更高效地训练一个较小的模型”是更优的发展路径。
Chinchilla 就像一位精干的学者:
- 以前的超大模型(Gopher/GPT-3):像一个拥有巨大图书馆(参数)但只匆匆读过几本书(数据)的“神童”,知识面广但不深,且反应迟钝(推理慢)。
- Chinchilla:像一个图书馆规模适中但精读并消化了海量书籍的顶尖专家。他知识更扎实、准确,反应更快,且培养(训练)和请教(使用)他的成本要低得多。
因此,Chinchilla 不仅是一个优秀的模型,更是一篇指引方向的“方法论”论文,它让整个领域意识到:在追求 AI 能力的道路上,规模和数据的平衡,才是通往高效与卓越的关键。
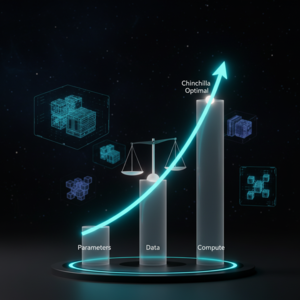
比喻理解: 我们可以把训练大语言模型比作烹饪一场盛大的宴会:参数量就像是厨师的技能等级,训练数据是食材的多样性,而计算量则是厨房设备的火力。扩展定律告诉我们,想要做出一桌绝顶美味(模型性能),你必须同时提升这三者。如果你只有顶级的厨师(高参数量)和强大的炉灶(高算力),却没有足够的食材(训练数据),那么最终的菜肴品质(性能)也会遭遇瓶颈。只有当这三者比例协调时,宴会的水平才会随着投入的增加而稳步提升。
原文地址:What are LLM Scaling Laws ?
Large Language Models (LLMs) don’t just improve randomly—there’s a science behind their growth. In this video, we explore LLM Scaling Laws, which describe how increasing model size, training data, and compute power impact performance. These laws help researchers predict and optimize AI advancements, ensuring models are trained efficiently without unnecessary costs. But how do these scaling rules hold up as models get bigger? And do they work the same way for small or distilled models?
📊 扩展定律:AI 能力的“可预测”增长曲线
- 核心洞察:大语言模型的性能并非随机跃升,而是随着规模扩大,呈现一种平滑、可预测的提升。这为 AI 研发提供了宝贵的“路线图”。
- 一个特例:通过知识蒸馏获得的“学生模型”,因其继承了大模型的“经验”,表现往往优于同等规模、从零训练的模型。
⚖️ 性能的三位一体:模型、数据与算力的平衡之舞
真正的提升来自于三个维度的协同扩展:
- 模型规模:神经网络的参数量,决定了其理论容量。
- 数据规模:训练所用的文本总量,决定了其知识广度与深度。
- 计算规模:训练过程消耗的浮点运算量,是这一切的燃料与成本。
🧠 Chinchilla 法则:纠正“盲目堆料”的认知偏差
DeepMind 的里程碑研究揭示了在固定计算预算下的最优配比原则:
- 收益递减定律:无脑增加参数或数据而忽略其他维度,将导致性能增长急剧放缓,造成巨大的资源浪费。
- 小模型的逆袭:关键在于“充分训练”。一个在极大数据集上训练到饱和的小模型,其性能可以轻松超越一个在有限数据上训练不足的大模型。
- 泛化能力的源泉:更大模型配合更多数据,能获得更强的小样本学习能力,使其快速适应新任务。
🚀 历史转折点:当增长撞上“墙”
扩展定律的曲线曾因瓶颈而趋于平缓,是技术创新一次次将其“重启”:
- 算力破壁:21世纪初,GPU 的广泛应用解决了大规模并行计算的瓶颈。
- 架构革命:2017年 Transformer 架构的提出,突破了序列建模的效率天花板,成为现代所有大模型的基石。
🔮 未来前沿:如何继续驱动增长引擎?
面对数据枯竭与算力需求的指数级增长,前沿探索集中在:
- 架构创新:如混合专家模型,它通过动态激活少量参数(专家)来处理不同任务,实现了参数量巨增而计算量可控的巧妙平衡。
- 合成数据:当高质量公开文本耗尽,由 AI 生成、再用于训练 AI 的合成数据,成为延续数据支柱的关键假设。
- 能源与硬件的终极博弈:科技巨头正投入千亿级资金建设数据中心与寻找新能源,因为扩展之战的下半场,将是资源与工程的终极考验。
