


 9
9 0
0
你是否想过,让 ChatGPT 回答“珠穆朗玛峰有多高”这类事实性问题时,它内部竟在进行一场昂贵的深度计算“推理”?传统 Transformer 模型缺乏真正的“记忆”机制,被迫用宝贵的神经网络层来“回忆”静态知识,效率低下。
本期节目,我们将深入解读一项名为 Engram 的突破性研究。它为 LLM 引入了“条件内存”这一全新维度,通过类似哈希表的 O(1) 常数级查找,让模型瞬间获取事实、搭配等静态知识,从而将计算资源彻底解放给真正的逻辑推理。我们将揭秘它如何与 MoE(混合专家 Mixture of Experts)模型协同工作,找到计算与存储的“黄金比例”,并探讨这项技术如何从系统层面,让我们能用主机内存廉价地扩展千亿参数,彻底打破 GPU 显存的束缚。
Abstract: While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup. To address this, we explore conditional memory as a complementary sparsity axis, instantiated via Engram, a module that modernizes classic N-gram embeddings for O(1) lookup.
“Engram”一词源自神经科学,意为“记忆痕迹”,它是一个可扩展、可查找的记忆模块,用于语言模型在推理过程中过去可能已经见过的模式或片段。
为了方便理解,我们可以打一个比方: 如果把标准的 Transformer 比作一个必须通过现场计算和推导来解决所有问题的天才,那么 Engram 就像是给这位天才配了一本极其详尽且能瞬间翻阅的百科全书。有了这本书,天才不再需要浪费大脑精力去记忆和推算那些固定的常识(静态知识),从而可以将全部的专注力用来处理书中没有的复杂逻辑和全局推理(动态计算)。
论文特别指出:Engram 提供了一个新的稀疏性轴,与 MoE 的条件计算不同,它通过条件查找提供静态记忆容量。下面图表中从目标、计算方式、优化方向和作用位置四个维度解释了 Engram 和 MoE 的区别。
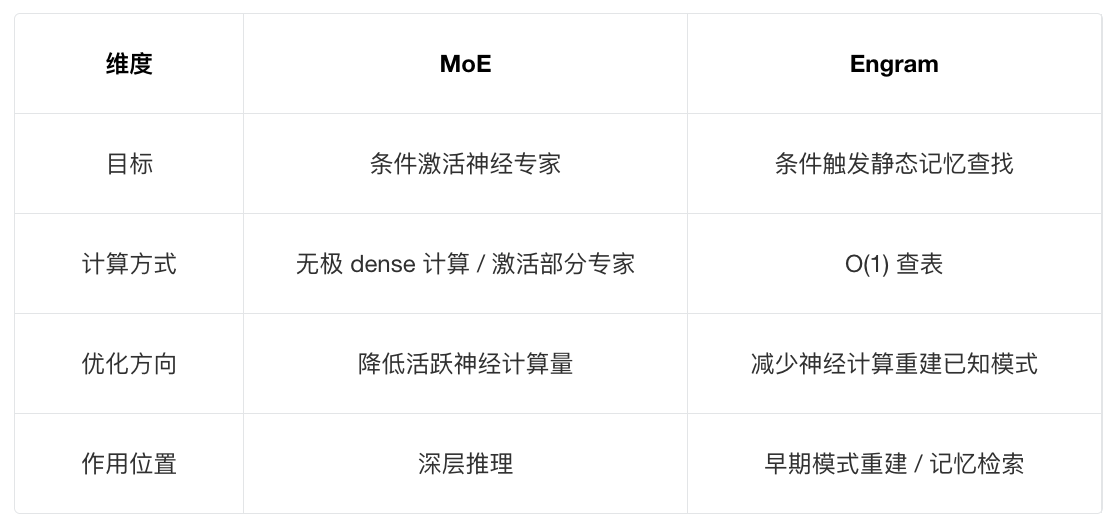
最后,DeepSeek 将 Engram 与 MoE 结合,形成了一个双系统:
- Engram 模块: 负责海量知识点的“存储与快速检索”。
- MoE 专家: 摆脱了沉重的记忆负担,全身心投入到“逻辑推理与合成”中。
这种分工极大地优化了参数效率。在 27B 的实验模型中,Engram 模块可以占用大量的参数用于记忆,但在实际推理时,它只消耗极少的计算量(FLOPs)。
参考:
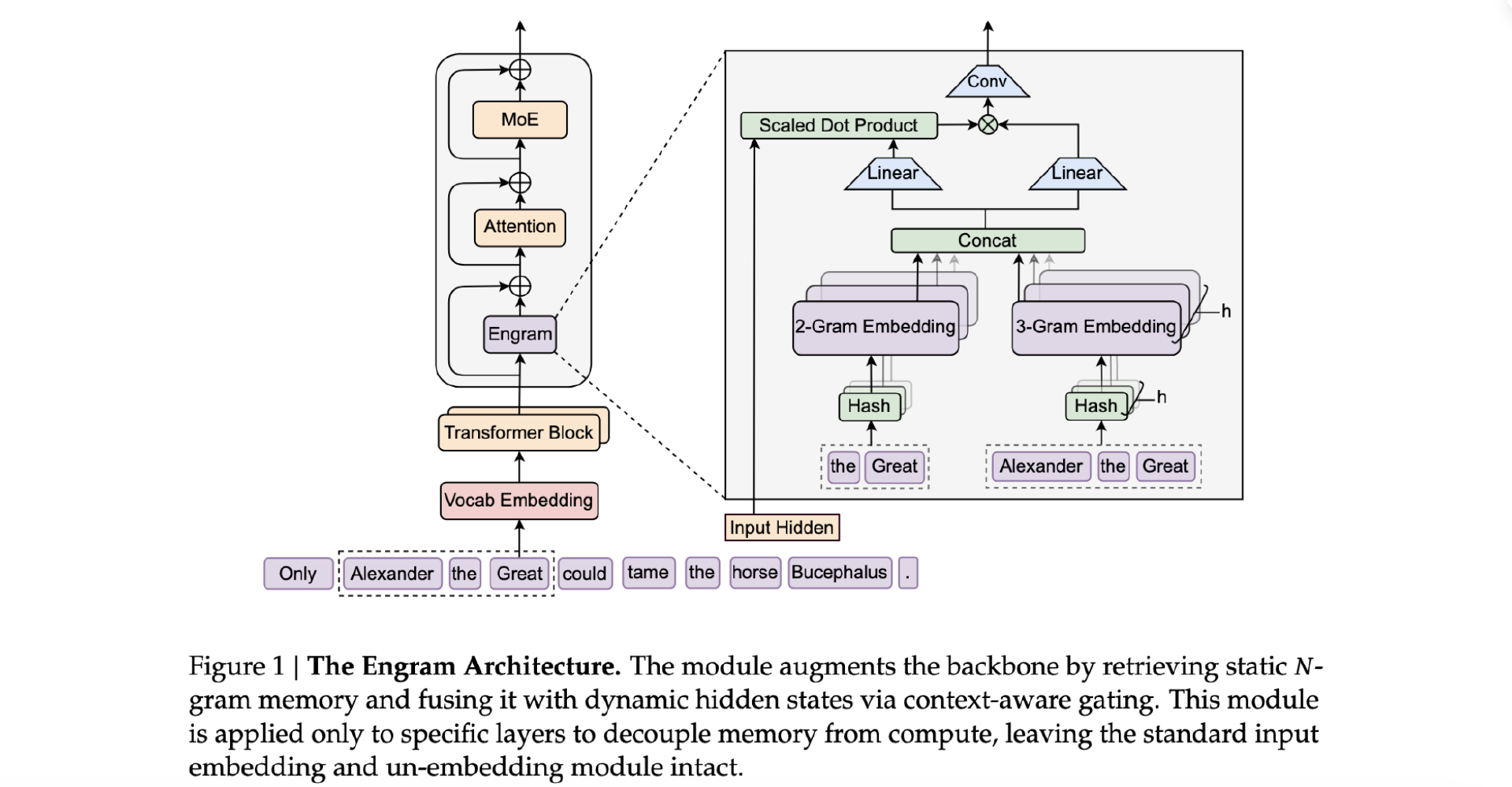
查和算分离的 Engram 新方法的整体架构:
🧠 核心问题:Transformer 的“记忆失能”
语言包含两个层面:一是需要组合与推理的动态逻辑,二是诸如事实、实体、固定搭配等静态知识。当前的 Transformer 模型存在一个根本缺陷:它没有原生的知识检索机制。当被问到“法国的首都是哪里?”时,它无法像查询数据库一样快速调取答案,而是必须启动昂贵的神经网络计算,在早期层中费力地“重建”这个知识。这就像用一颗顶尖的围棋大脑,去反复背诵乘法口诀表——巨大的资源错配。
⚙️ Engram 的解决方案:常数级的知识“闪电查找”
Engram 模块的核心思想直击要害:为静态知识建立一个专有的、高速的查找表。
- 现代化 N-gram 嵌入:Engram 将局部上下文(如前几个词)作为“键”(Key),通过高效的哈希函数,在 O(1) 的时间复杂度内,从一个巨大的内存表中检索出对应的“值”(Value)——即静态知识嵌入向量。
- 上下文感知门控:为防止哈希冲突或一词多义,Engram 引入了一个巧妙的门控机制。它会用模型当前的隐藏状态作为“查询”,来调节检索到的记忆,确保取出的知识与当前语境完美匹配。
- 系统级优化:由于查找地址完全由输入决定(确定性),系统可以在计算开始前,异步预取所需的内存块。实验证明,即使将一个1000亿参数的 Engram 内存表放在相对廉价的主机内存(而非 GPU 显存)中,推理延迟也仅增加不到3%。这为廉价地扩展模型参数打开了新天地。
⚖️ 关键发现:计算与存储的“黄金分割”
研究提出了一个深刻问题:在固定的参数预算下,应该在负责计算的 MoE 专家和负责存储的 Engram 内存之间如何分配?
实验揭示了清晰的 “U型缩放法则”:
- 纯 MoE 模型(100%计算)缺乏专用内存,处理静态知识效率低。
- 纯内存模型(100%存储)则丧失了推理所必需的复杂计算能力。
- 最优平衡点出现在将20%-25%的稀疏参数分配给 Engram 内存时。在这个比例下,模型在知识、推理、代码和数学等各项任务上达到性能巅峰。这证明,存储与计算是互补而非互斥的。
🚀 性能飞跃:更深的“推理深度”与更强的长文本能力
集成 Engram 的模型展现出了全方位的提升:
- 全面超越基准:在参数量和计算量严格对等的情况下,Engram-27B模型在知识、推理、代码、数学等多个基准上全面超越了纯 MoE 的基准模型。
- 解锁长上下文潜力:Engram 接管了局部依赖关系的处理,解放了注意力机制,让它能更专注于长距离的全局关联。在长文本检索任务中,准确率从84.2%飙升至97.0%。
- 实现“逻辑深:在参数量和计算量严格对等的情况下,Engram-27B 模型在知识、推理、代码、数学等多个基准上全面超越了纯 MoE 的基准模型。“变深”了。
💎 范式意义:算法与系统的协同革命
Engram 不仅仅是一个高效的插件。它代表了一种算法设计与系统架构的深度协同。
它首次在神经网络中清晰地划分了“存储”与“计算”的界限,并证明通过廉价的确定性查找来补充昂贵的神经计算,是构建下一代超大规模、超高效率稀疏模型的可行路径。这项技术有望让我们跳出“堆叠 GPU 和参数”的粗暴增长模式,转向更精巧、更可持续的智能架构设计。
