

 31
31 0
0本课聚焦提升优化效率的进阶算法。核心介绍了动量法,通过累积历史梯度平滑搜索轨迹并加速收敛。详细阐述了 Adam 优化器,结合一阶和二阶矩估计实现参数级自适应学习率。最后强调了超参数搜索在模型拟合中的“艺术”属性。
第11课完整讲义:zhuanlan.zhihu.com
00:00 开篇语
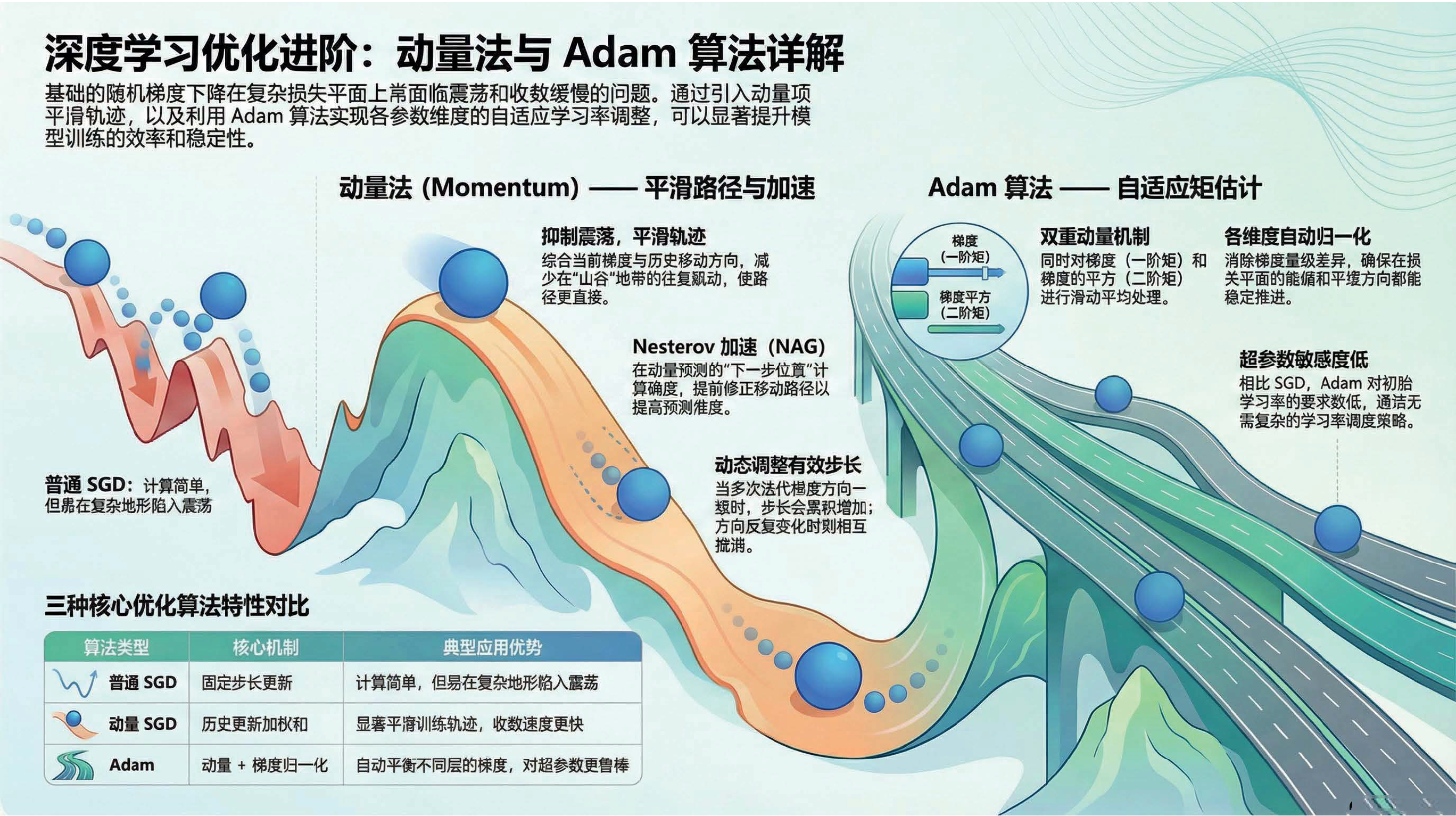

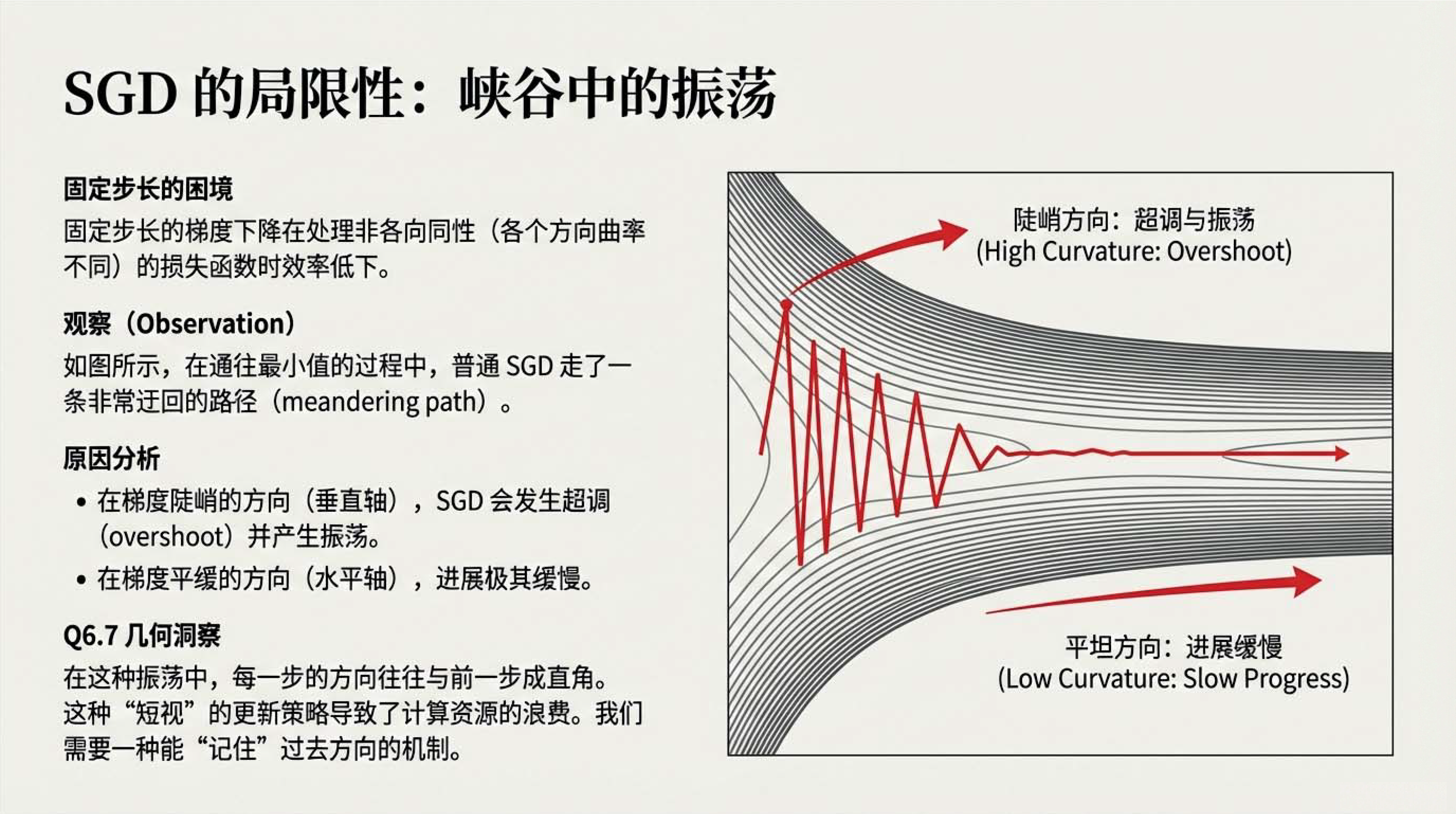
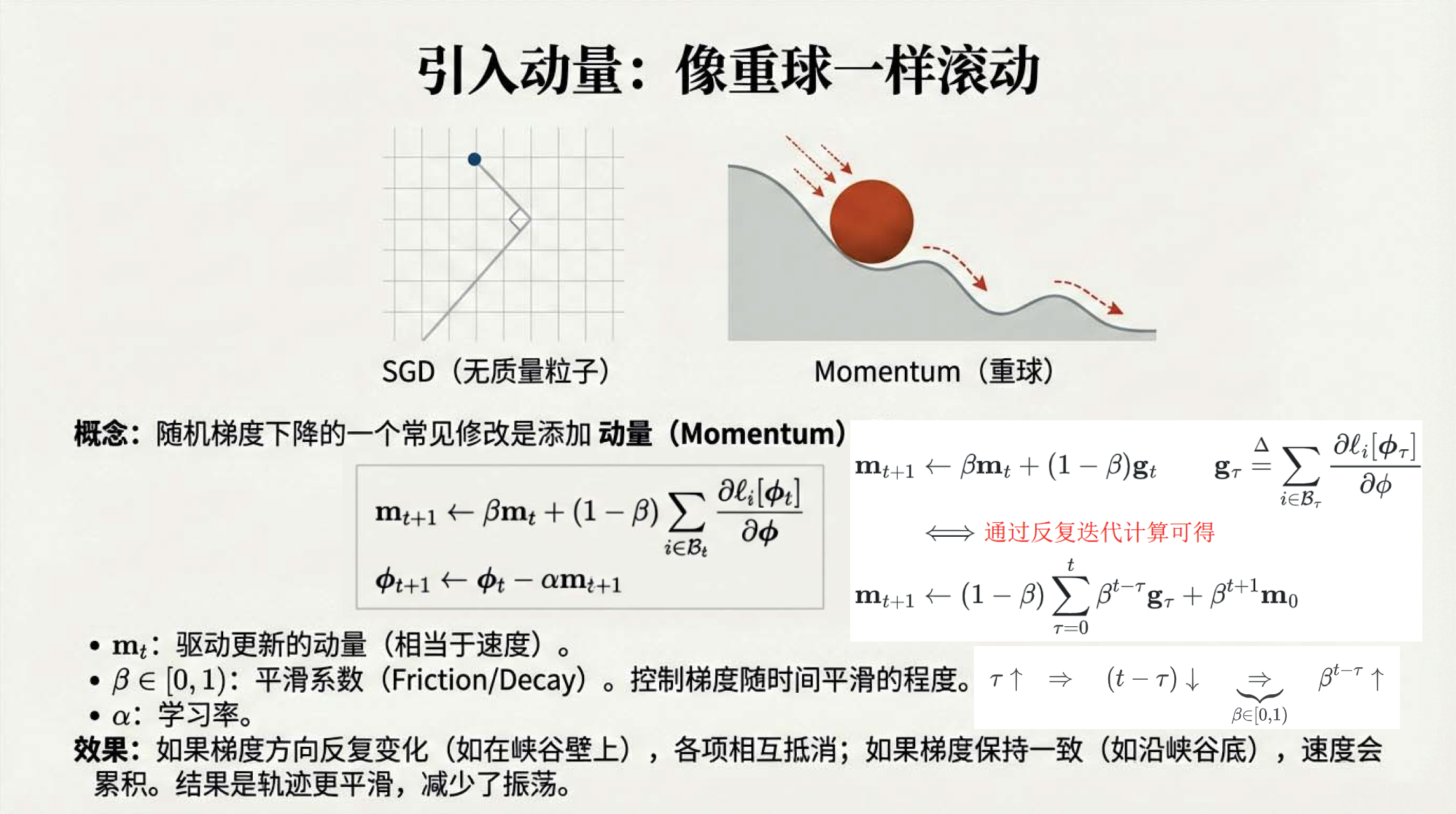
01:22 动量就是指数加权平均
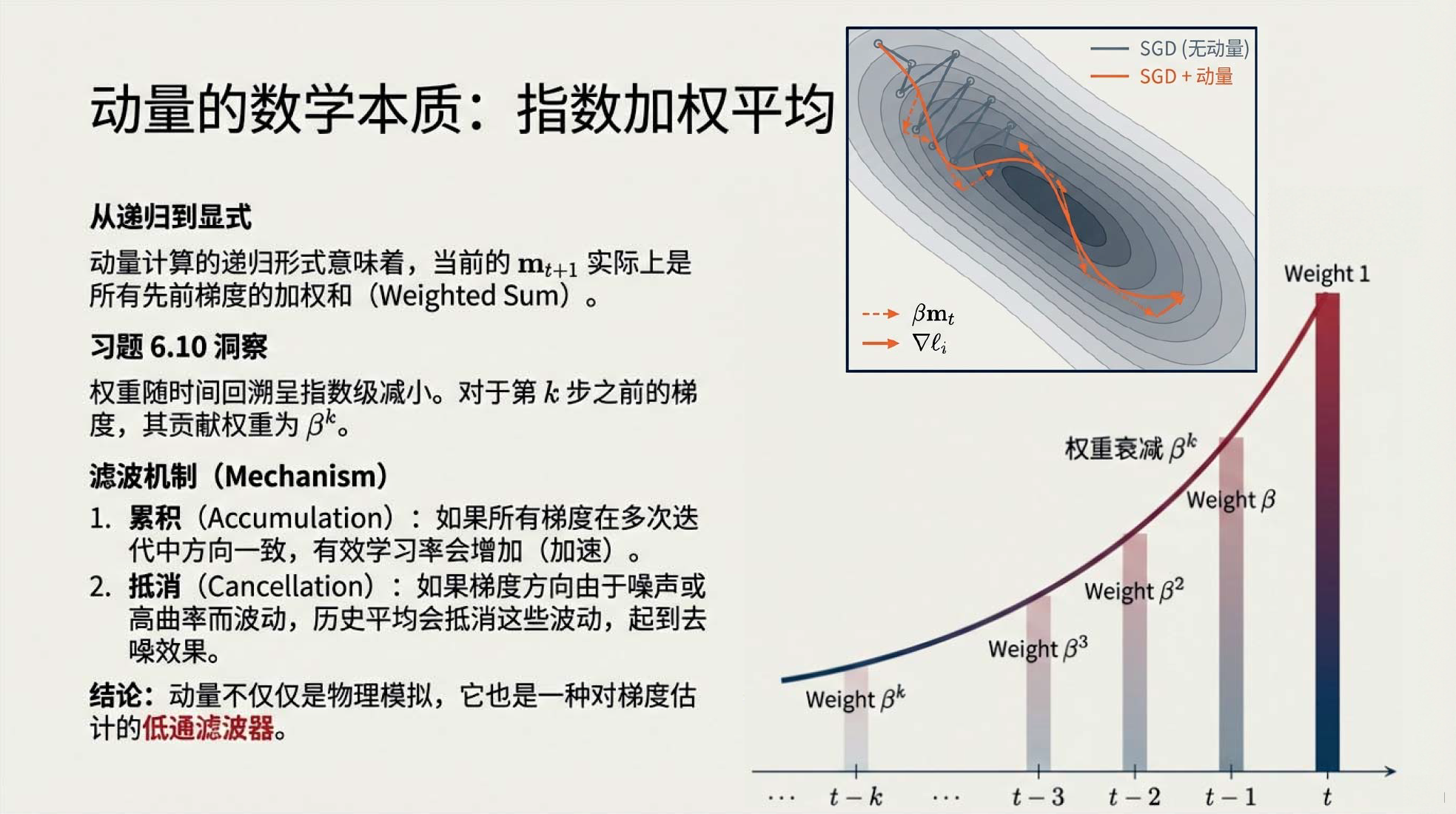
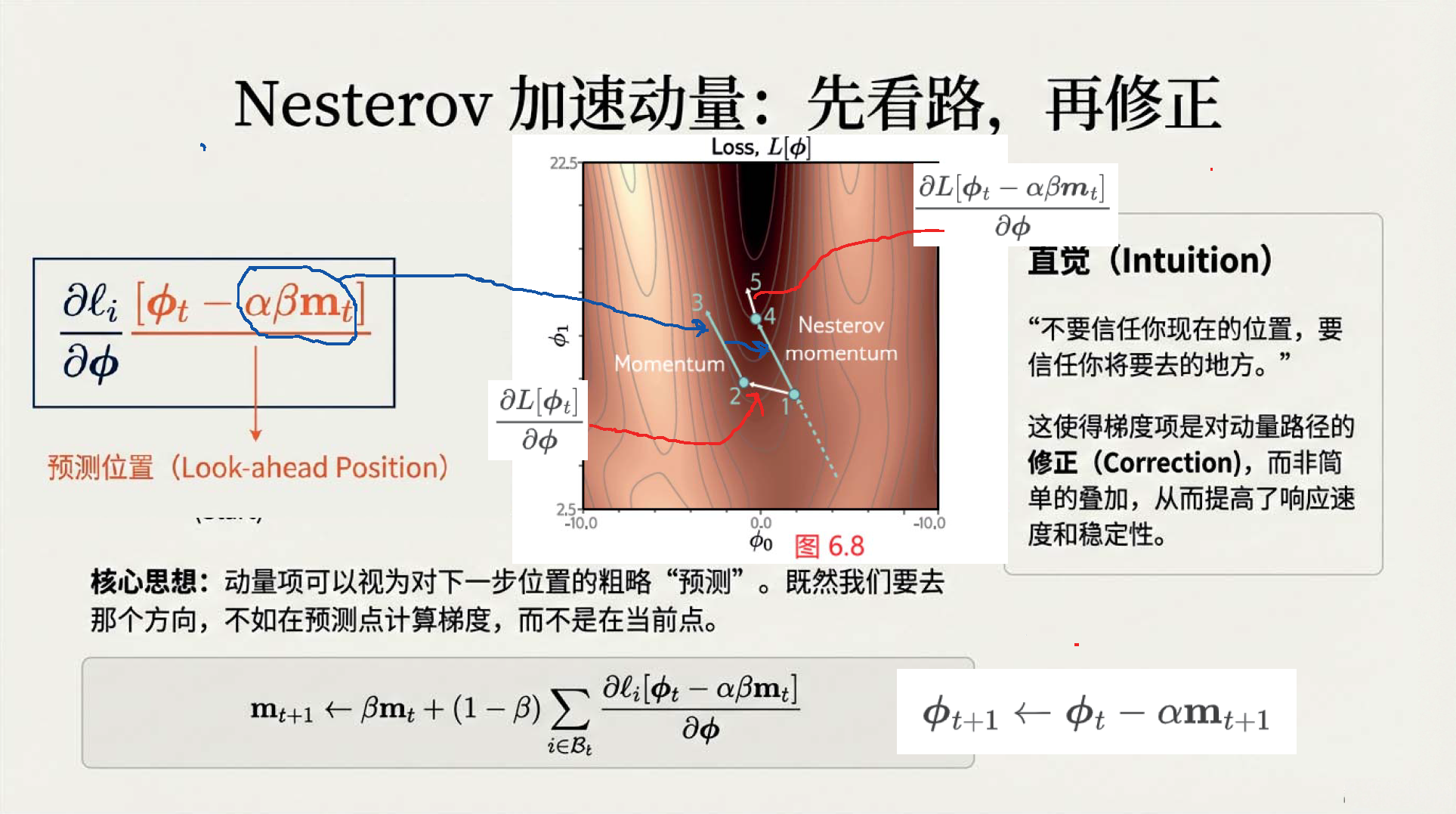
04:40 Nesterov 加速动量
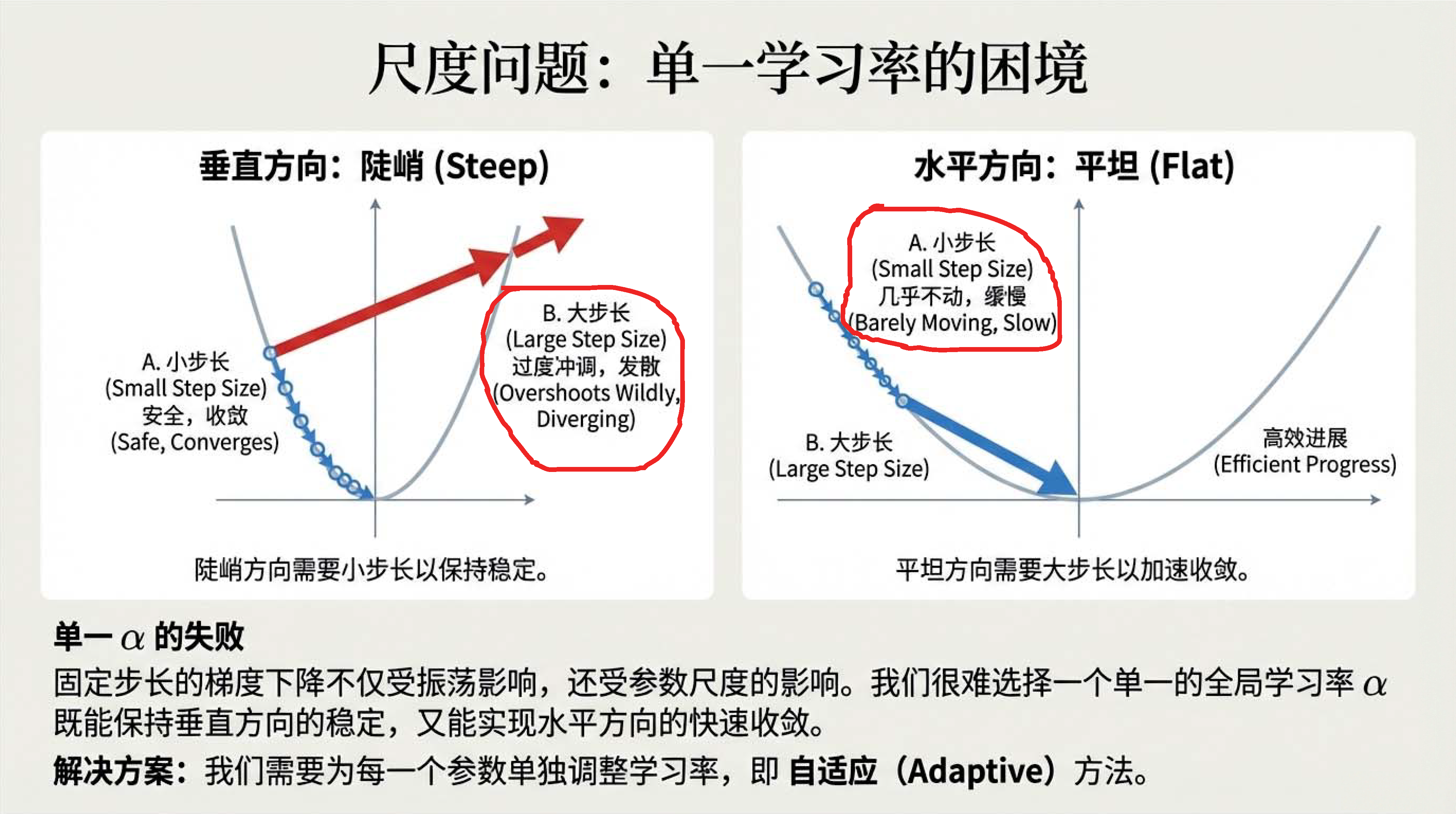
06:26 单一学习率的困境
07:35 归一化梯度

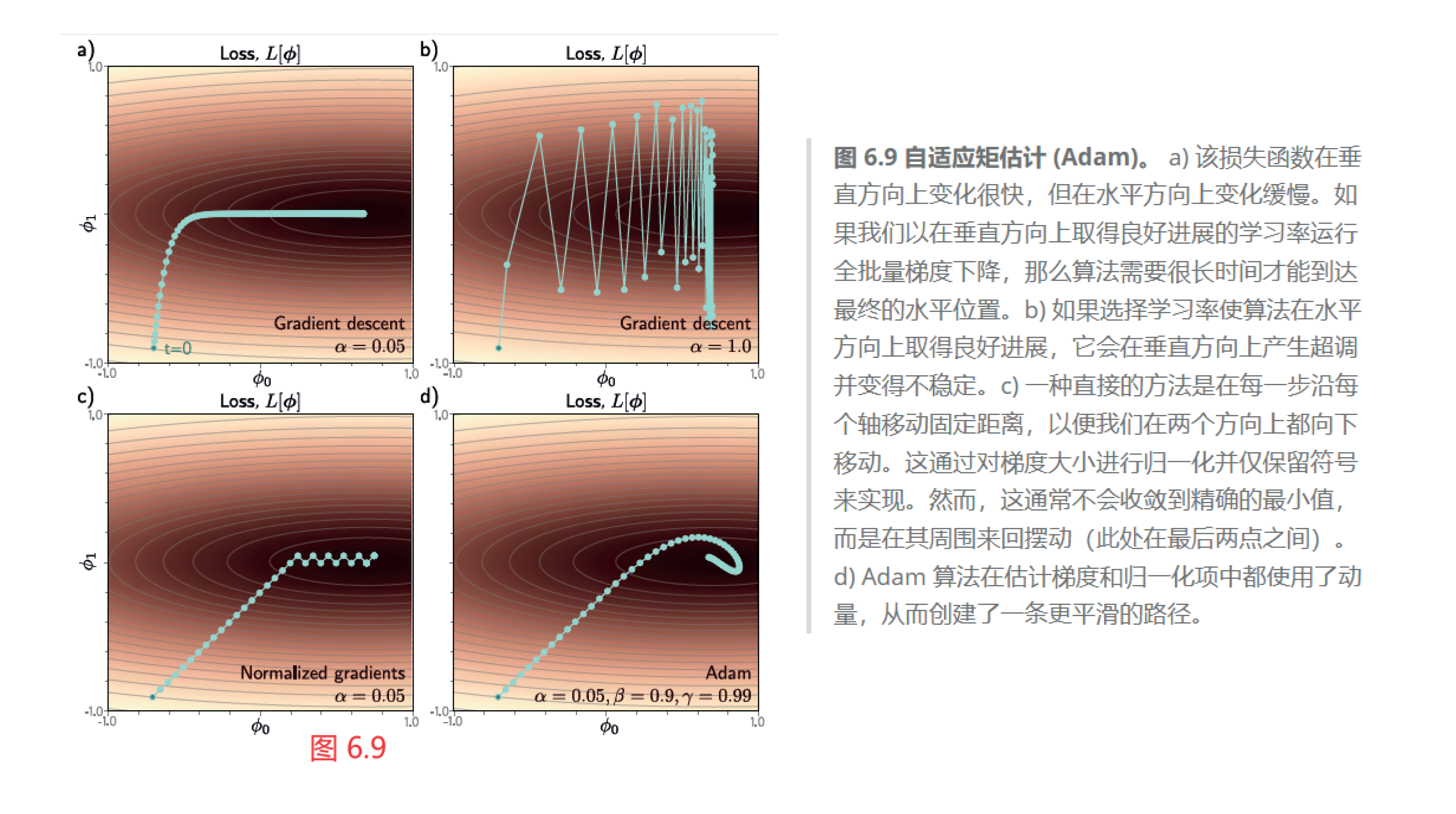
11:13 Adam 自适应矩估计
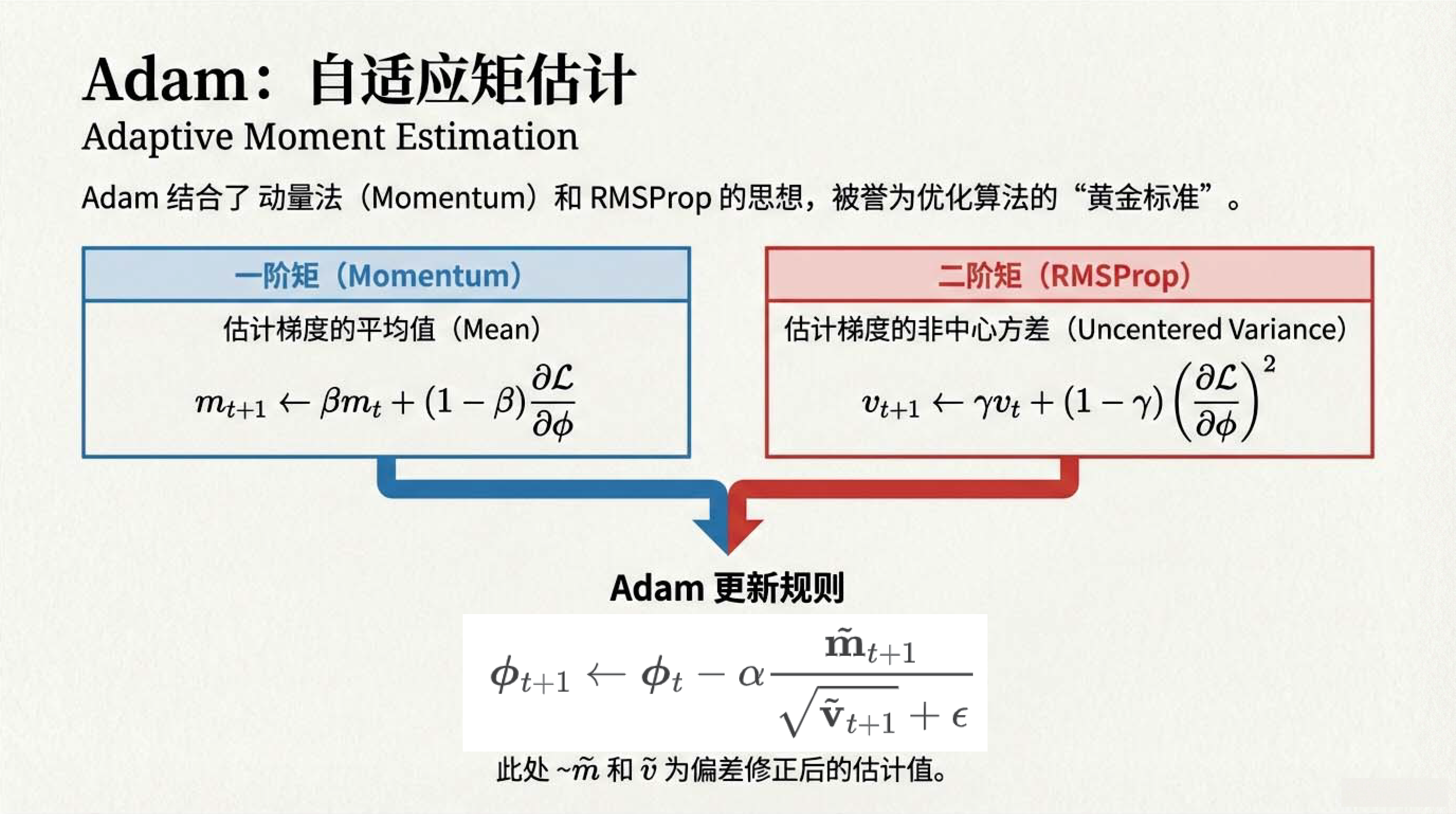


15:47 训练的艺术:超参数搜索

17:02 第6章总结

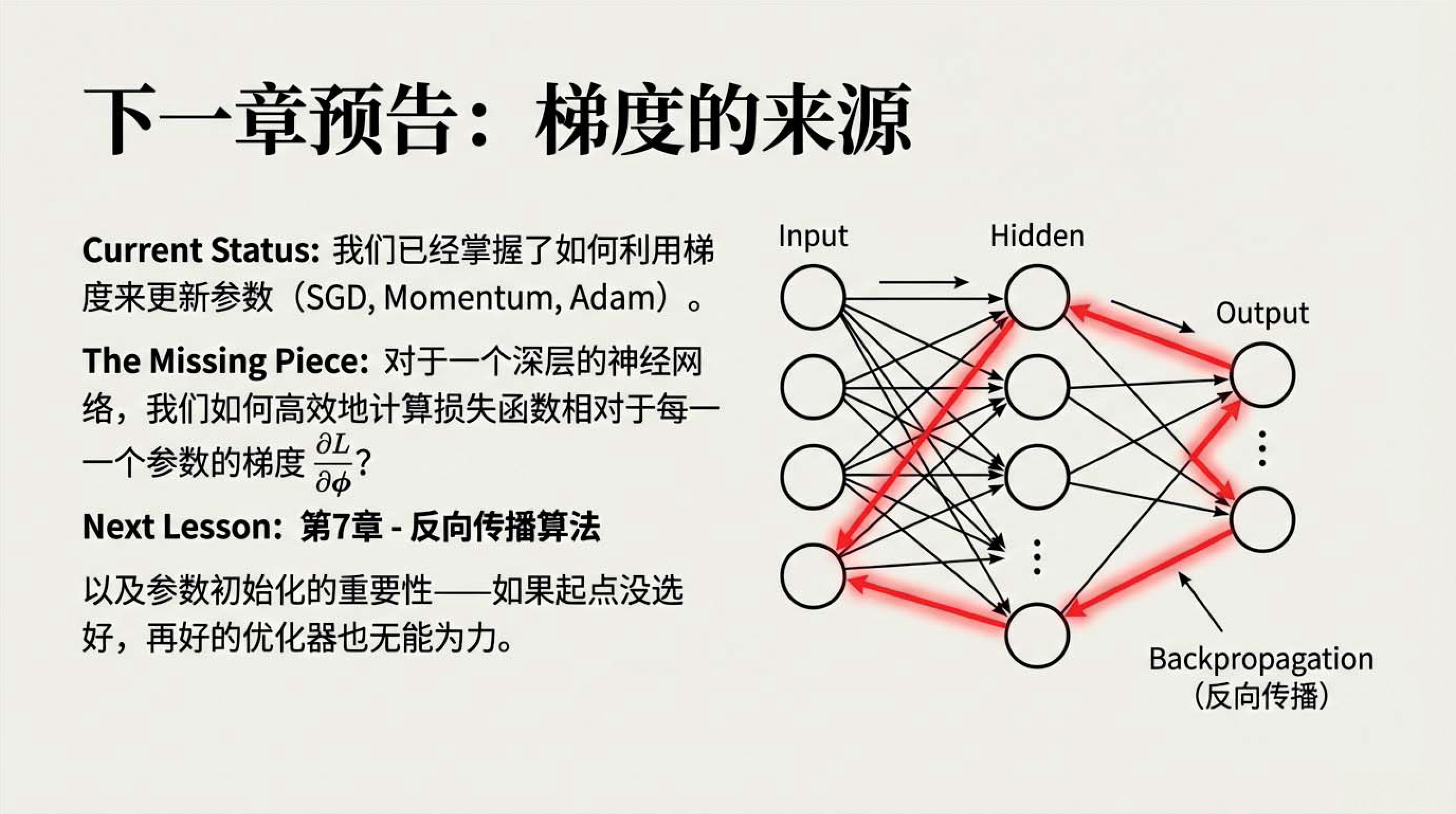
19:12 Notes 部分
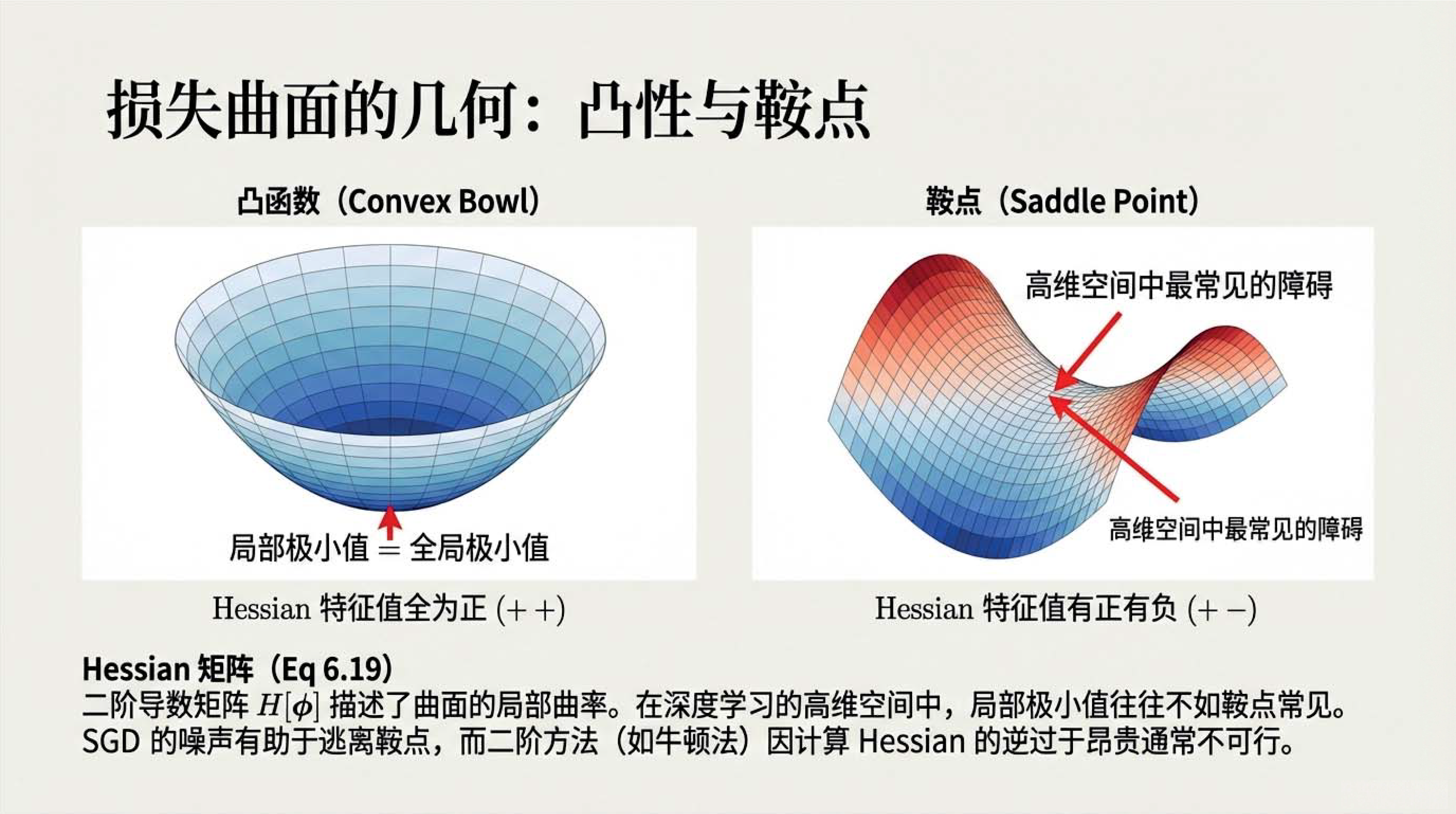

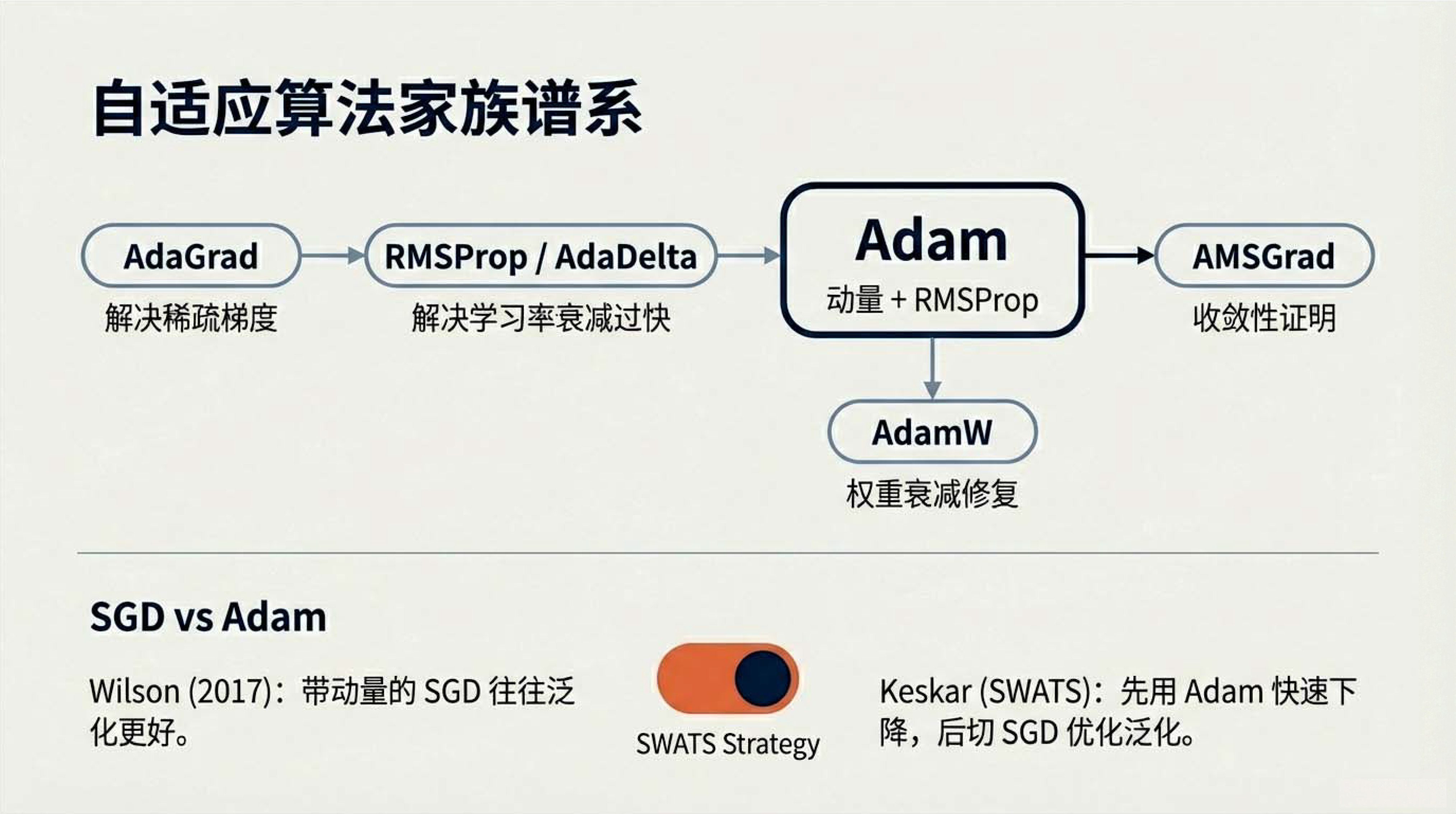
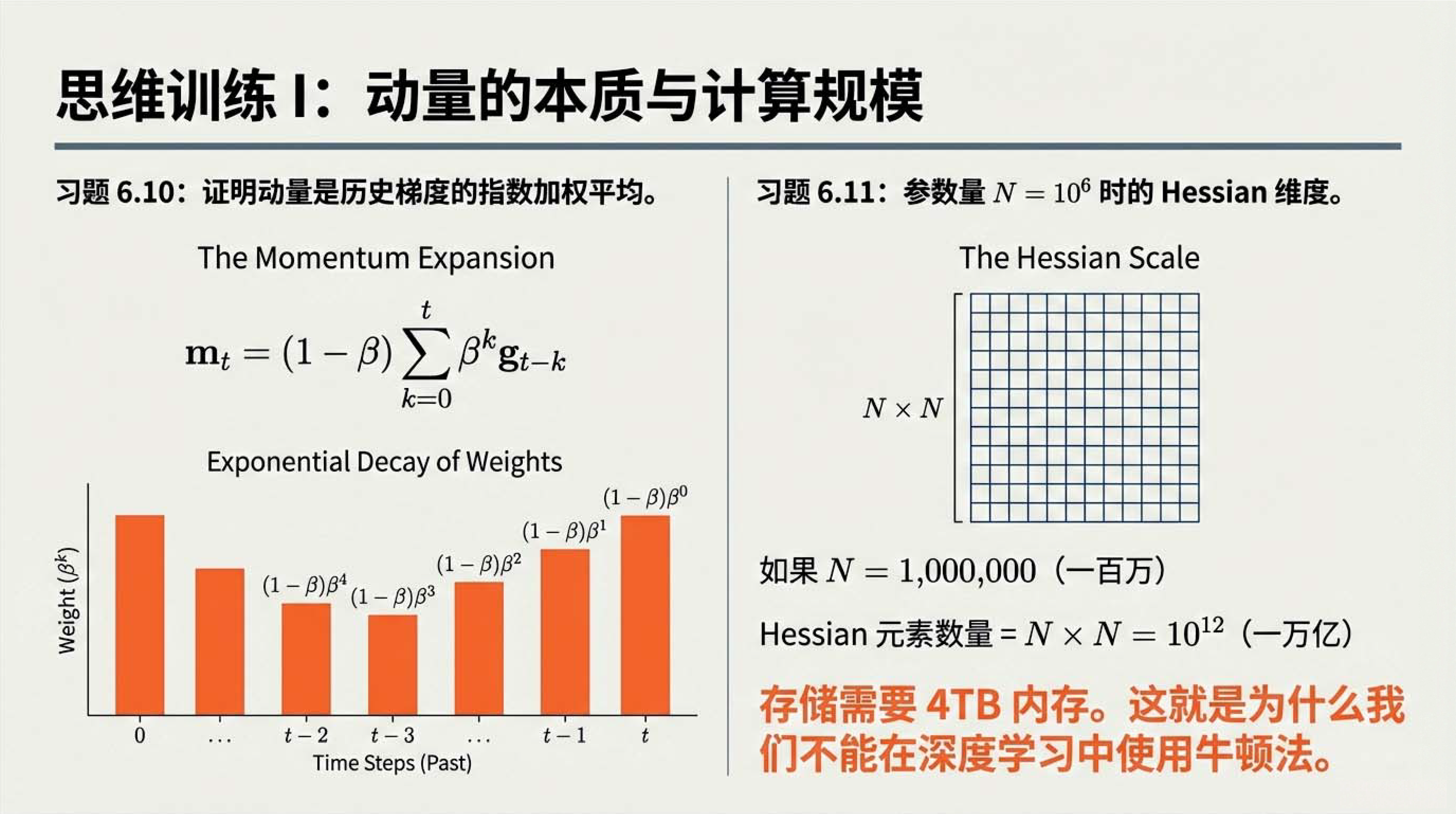
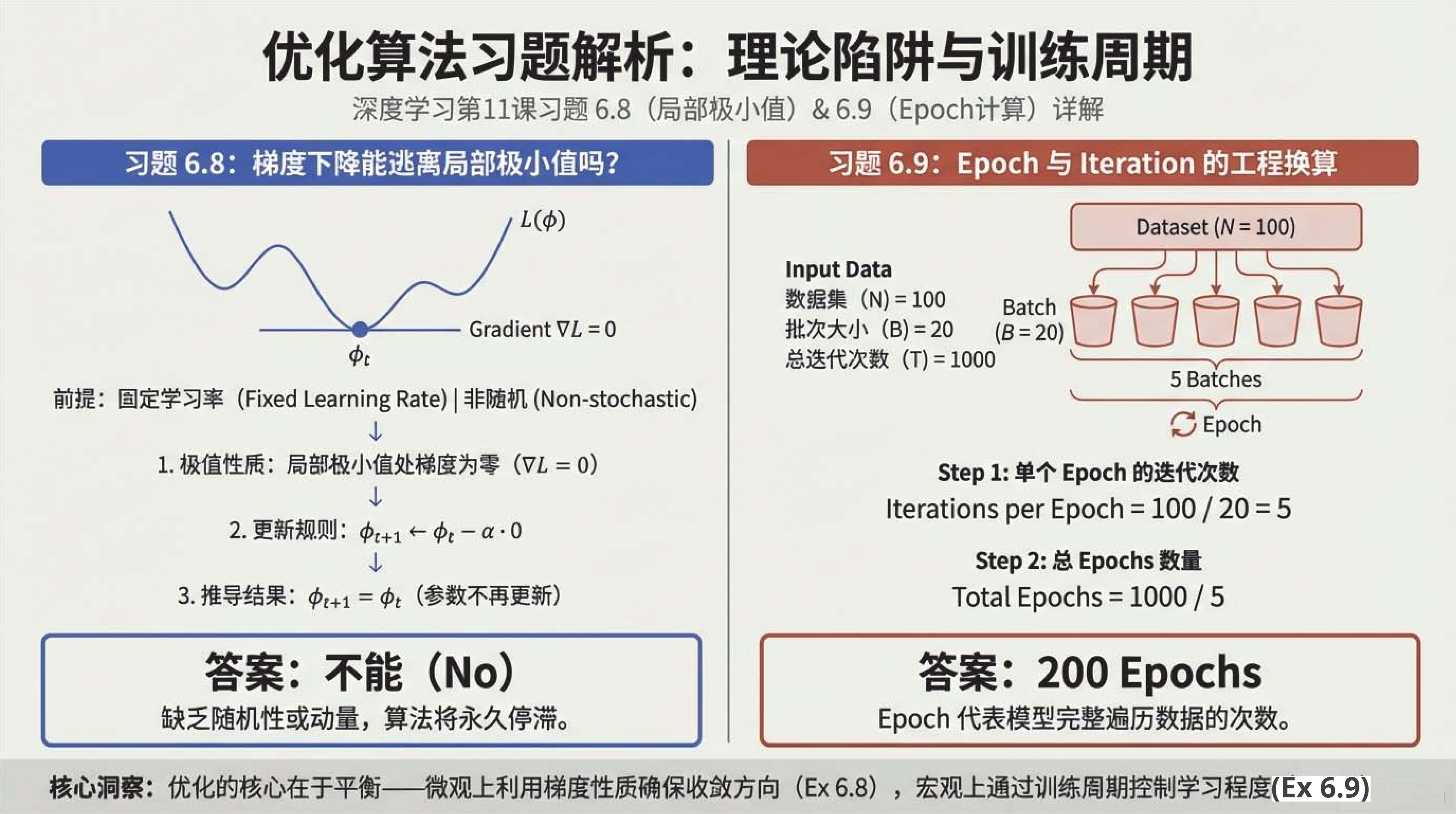
21:22 习题
23:10 结束语
