


 189
189 0
0随着生成式人工智能(AI)任务日益复杂、专业化且涉及多步操作,传统的 LLM-as-a-Judge(大模型作为裁判)范式正面临严峻挑战,包括固有的参数偏差、单次推理的浅层逻辑以及无法验证真实世界观察结果。为应对这些局限,AI 评测领域正经历向 Agent-as-a-Judge(智能体作为裁判)的范式演进。
Agent-as-a-Judge 核心在于利用智能体的规划(Planning)、工具增强验证(Tool-augmented Verification)、多智能体协作(Multi-agent Collaboration)和持久化记忆(Persistent Memory)能力,实现更稳健、可验证且细粒度的评测。本简报分析了该范式的发展阶段、核心方法论、应用领域及未来挑战。
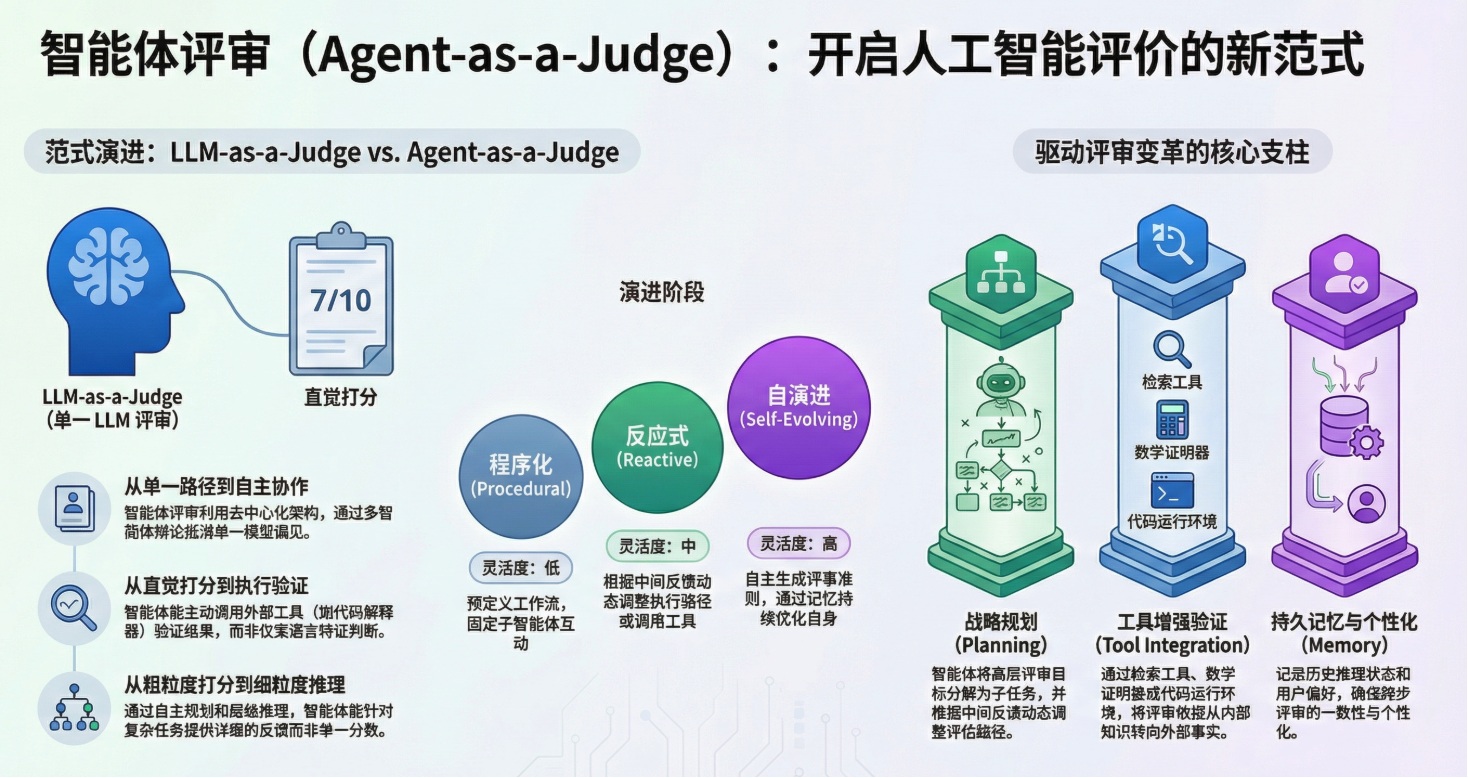
1. 范式演进:从 LLM-as-a-Judge 到 Agent-as-a-Judge
- 1.1 LLM-as-a-Judge 的局限性
参数偏差(Parametric Biases): 单次推理评估者易受位置偏差、长度偏差(倾向于更长的回复)及模型自我偏好影响,难以保持中立。
缺乏真实性验证(Lack of Verification): 作为被动的观察者,LLM 仅根据语言模式评估答案,无法与环境互动,在专业领域容易产生“幻觉纠错”。
认知负荷与粗粒度评分(Cognitive Overload): 在处理多维度评估准则时,单次推理难以全面兼顾,往往给出无法反映细微差别的模糊得分。
- 1.2 Agent-as-a-Judge 的进化维度
2. 智能体评测的三个发展阶段
根据自主性和适应程度,Agent-as-a-Judge 的发展可分为三个阶段:
- 1. 程序化阶段(Procedural): 将单次推理拆分为预定义的智能体工作流或固定子智能体之间的结构化讨论。决策规则预先设定,无法适应新场景。
- 2. 反应式阶段(Reactive): 能够根据中间反馈动态选择执行路径、调用工具或子智能体。其灵活性局限于固定决策空间内的条件跳转。
- 3. 自进化阶段(Self-Evolving): 处于领域前沿,具有极高自主性,能即时合成评测准则,并根据经验更新记忆,实现评测系统的自我改进。
3. 核心方法论分析
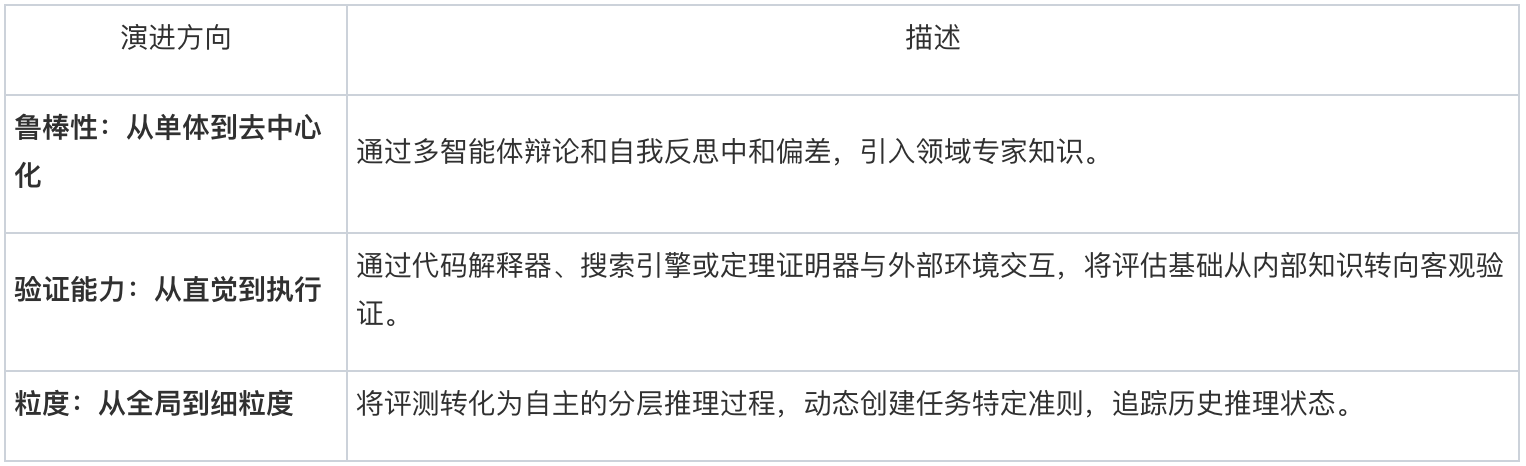
- 3.1 多智能体协作(Multi-Agent Collaboration)
集体共识(Collective Consensus): 采用水平辩论机制(如 ChatEval 的法庭辩论模式),通过不同角色的立场对抗来消除单模型偏见。任务分解(Task Decomposition): 采用“分而治之”策略。例如CAFES和GEMA-Score将评估分为证据收集、推理和评分等预定义阶段;HiMATE则利用树状结构处理不同粒度的错误。
- 3.2 规划与准则发现(Planning & Rubric Discovery)
工作流编排: 智能体根据中间反馈调整策略(如 Evaluation Agent),并能在获得充足证据后自主终止执行。动态准则制定: 这是自进化阶段的标志。EvalAgents通过网页搜索发现隐含准则;OnlineRubrics则在强化学习过程中不断演进准则以检测奖励作弊(Reward Hacking)。
- 3.3 工具集成(Tool Integration)
工具的使用将评测锚定在可观察和可验证的信号上:

- 3.4 记忆与个性化(Memory & Personalization)
中间状态追踪: 记录推理链条中的中间证明状态或执行痕迹,支持多步评估的连贯性。
个性化上下文: 存储用户偏好数据或构建长期的用户画像(如RLPA和SynthesizeMe),确保评测标准跨时间的一致性。
4. 应用领域纵览
- 4.1 通用领域
数学与代码: 从单一评分转向基于验证信号的判断。例如HERMES将逻辑推理锚定在形式化证明步骤上;Popper通过统计测试验证自由文本主张。
事实核查: 将静态标签预测重构为证据搜集的交互式循环。FACT-AUDIT评估判决准确性与理由质量;NarrativeFactScore解决长文本的一致性问题。
多模态与视觉: 智能体协调专用工具探测图像生成的指令遵循度(如 CIGEval)或针对图文生成事实核查问题。- 4.2 专业领域
医疗: 采用多专家角色辩论(如MAJ-Eval)或模拟器评估医患对话(如Chat-Coach)。
法律: 模拟法庭辩论,通过原告、被告和法官的角色扮演提高判决的稳健性。
金融: 提取分析报告的逻辑树以评估研究深度,或通过审计代理轨迹检测部署风险。
教育: 模拟教学细微差别,通过多阶段工作流(准则构建、证据识别、交叉评审)实现人类水平的自动评分。
5. 挑战与未来展望
- 5.1 当前主要挑战
计算成本与延迟: 多步推理、工具调用和多智能体通信显著增加了推理开销。
安全与隐私: 工具集成扩大了攻击面(如提示注入);持久化记忆增加了敏感数据泄露或未经授权推断用户属性的风险。
幻觉强化: 若智能体裁判存在系统性偏见,其提供的奖励信号可能会在强化学习中强化被评测模型的错误行为。
- 5.2 未来研究方向
主动记忆管理: 智能体应自主决定何时注册新偏好、更新标准或修剪过时反馈。
情境感知准则生成: 根据任务难度动态缩放评估粒度,对复杂工作流进行细粒度拆解。
人机协作校准: 在处理主观性极强的场景时,通过主动咨询人类专家来完善评测标准。
基于训练的优化: 从推理侧工程转向训练侧优化,利用强化学习使智能体裁判内化复杂的规划和工具调用行为。
- 5.3 总结
Agent-as-a-Judge 不仅仅是评测工具的升级,更是向具备感知、推理和持续进化能力的自主评测实体的跨越。下一代智能体裁判将超越固定协议,实现真正的评估自动化。
📺相关链接与资源
[报告来源]《Agent-as-a-Judge》
本播客采用虚拟主持人进行播客翻译的音频制作,因此有可能会有一些地方听起来怪怪的。如想了解更多信息,请关注微信公众号"西经东译"获取AI最新资讯。如有后续想要听的其他外文播客,也欢迎联系微信:mayday2303。
