

 8
8 0
0
面对复杂任务,我们是该派一个“全能型” AI 单打独斗,还是组织一群“专家型” AI 协同作战?这个看似简单的问题,长期以来只依赖直觉和试错。如今,第一篇试图为 AI 智能体系统建立“扩展科学”的研究给出了量化答案。本期内容将带你深入这项对 180 种配置进行受控实验的论文。你将了解到决定协作成败的核心并非任务本身的复杂程度,而是其可分解性;你会发现一个惊人的 “基准悖论”:当单代理能力超过某个阈值(约45%)后,增加协作反而会拖后腿;你也会看到,错误的传播如何因架构设计而被放大或遏制。对于任何正在构建 AI 智能体应用、或试图优化团队协作模式的开发者和研究者而言,这份研究提供的不是鸡汤,而是可量化的选择标准。
这篇论文标志着我们对 AI 智能体的理解,正从“艺术”走向“科学”。它用数据戳破了“人多力量大”的朴素直觉,揭示了协作效能的真实边界。在通往更强大智能系统的道路上,最重要的或许不是无休止地增加代理数量,而是学会为正确的任务,选择正确的协作方式。

参考论文:Towards a Science of Scaling Agent Systems
以下为主要内容的图文介绍:


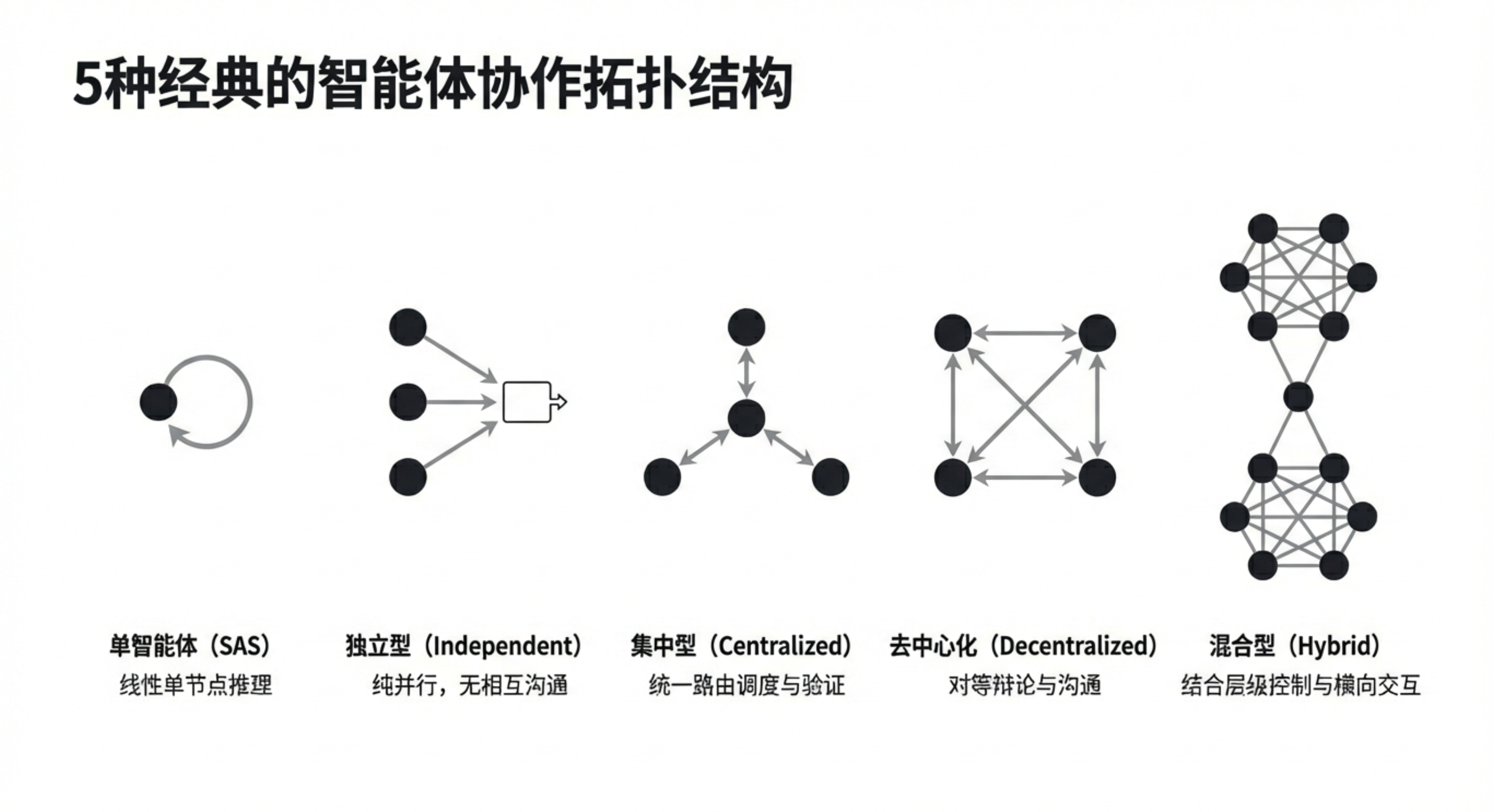


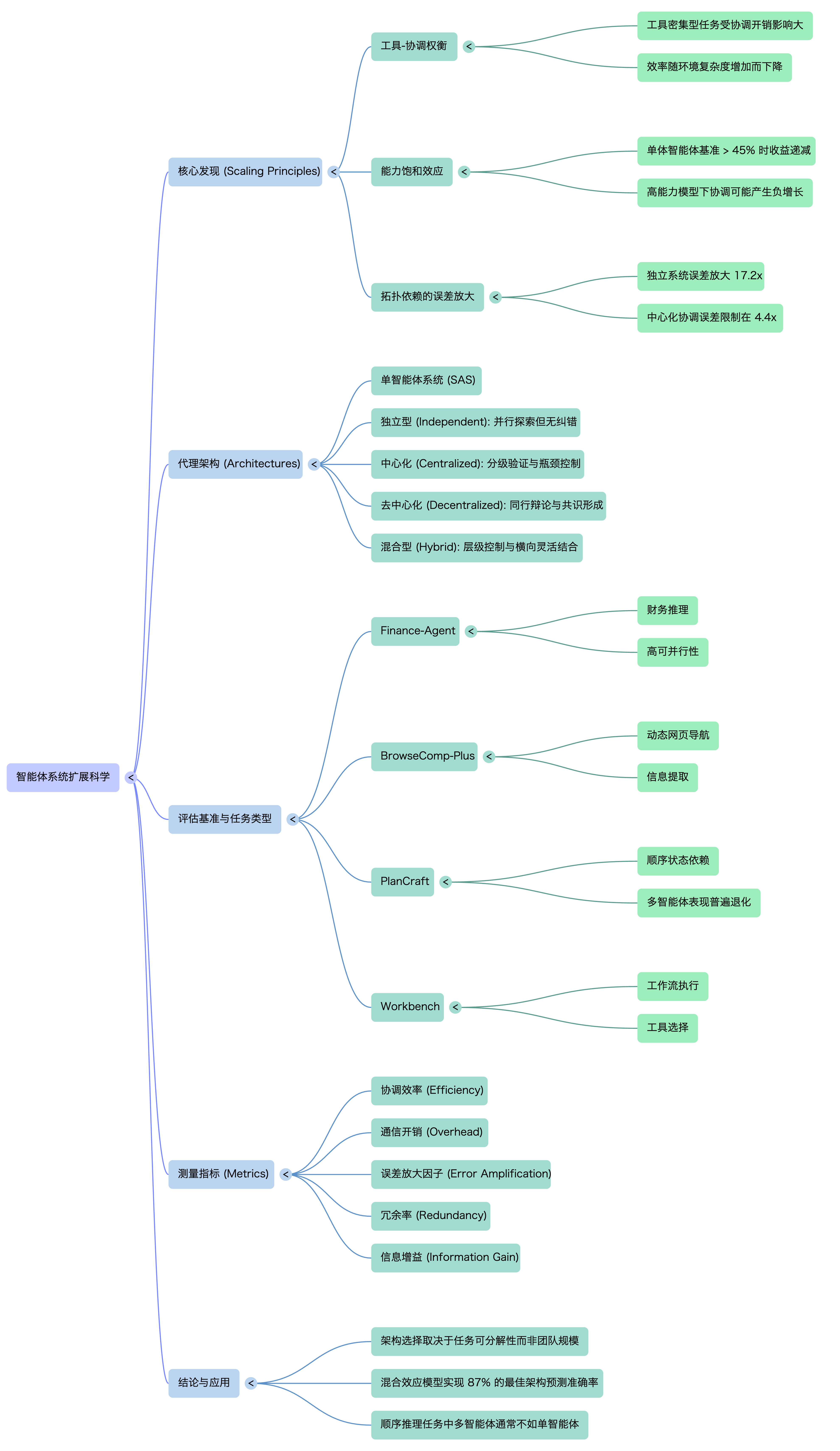
🧠 核心洞察:三大扩展原则,揭开协作的真相
论文通过大量对比实验,识别出主导智能体系统性能的三大关键效应:
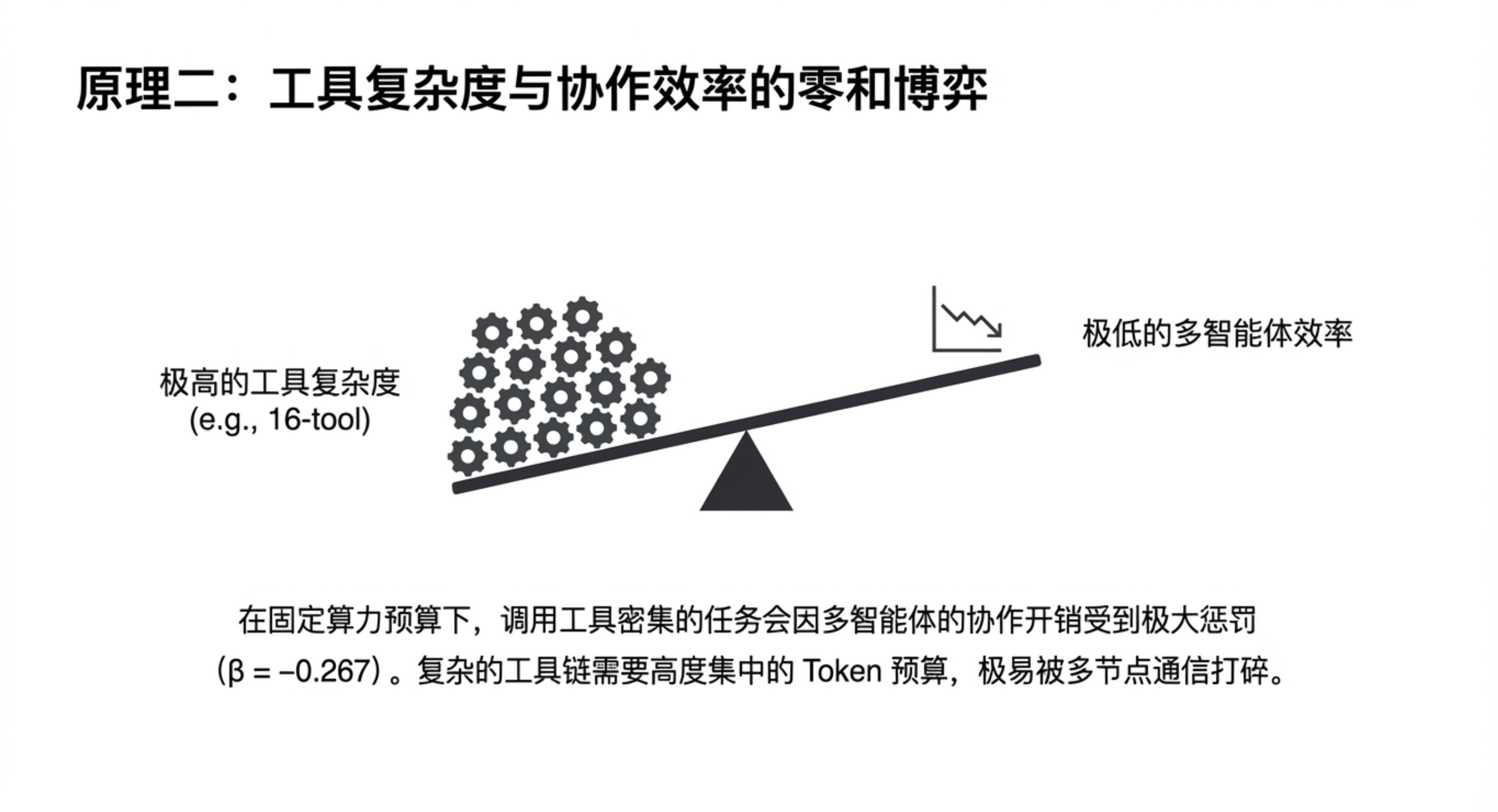
- 工具-协作权衡:在固定的计算预算下,工具密集型任务(如复杂的软件工程)会不成比例地受到多代理协作开销的影响。工具越丰富,协作的“税”就越重,有时更简单的架构反而更高效。
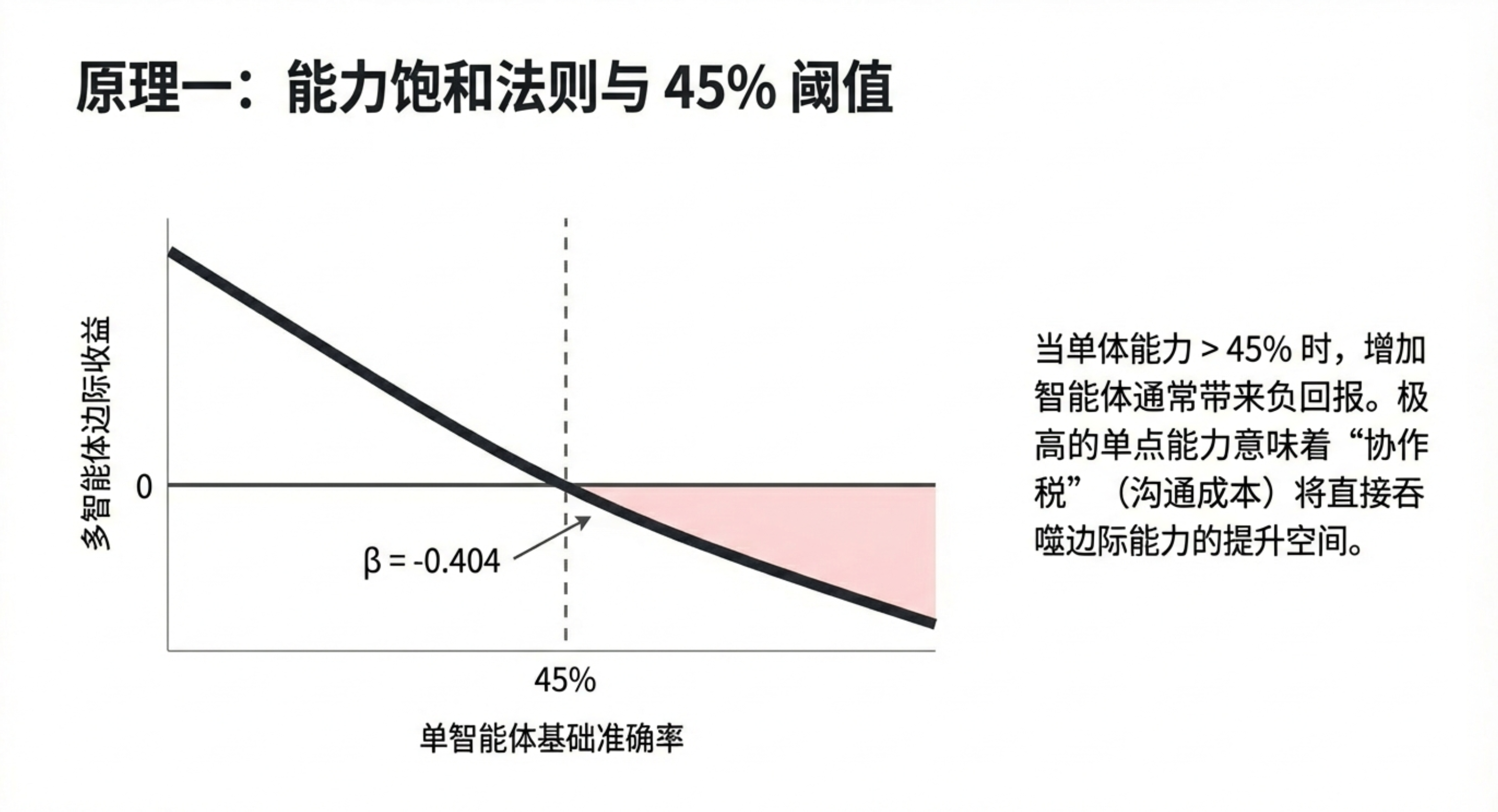
- 能力饱和点:存在一个反直觉的 “基准悖论”。一旦单代理系统的性能超过约45%的经验阈值,增加代理协作带来的回报就会急剧递减,甚至变成负值。一个足够强的个体,可能比一群平庸的协作体更可靠。
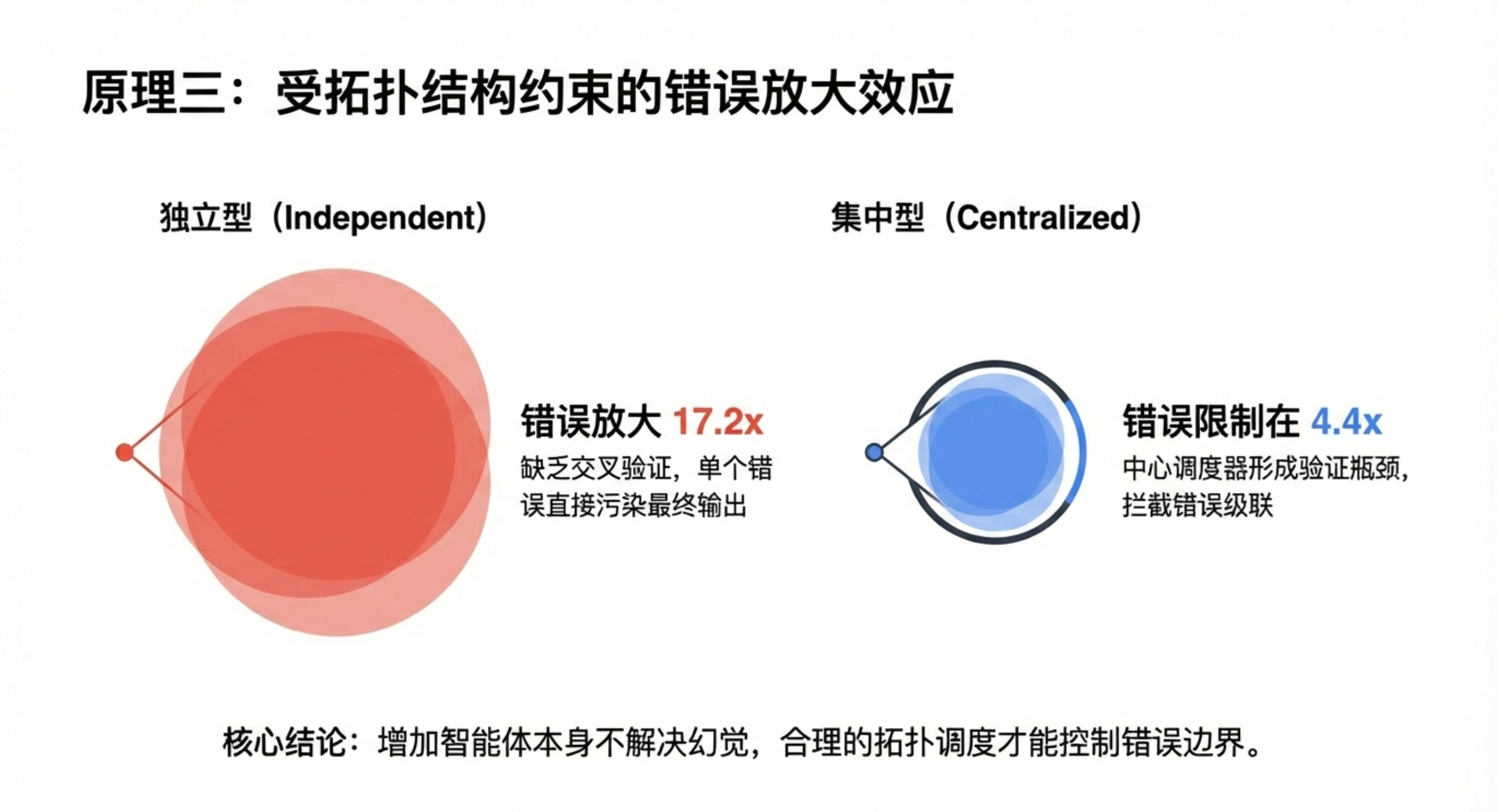
- 拓扑相关的错误放大:错误的传播方式高度依赖架构。独立代理因缺乏检查机制,会将错误一路放大;而中心化协作通过设置验证瓶颈,能将错误放大控制在4.4倍以内。
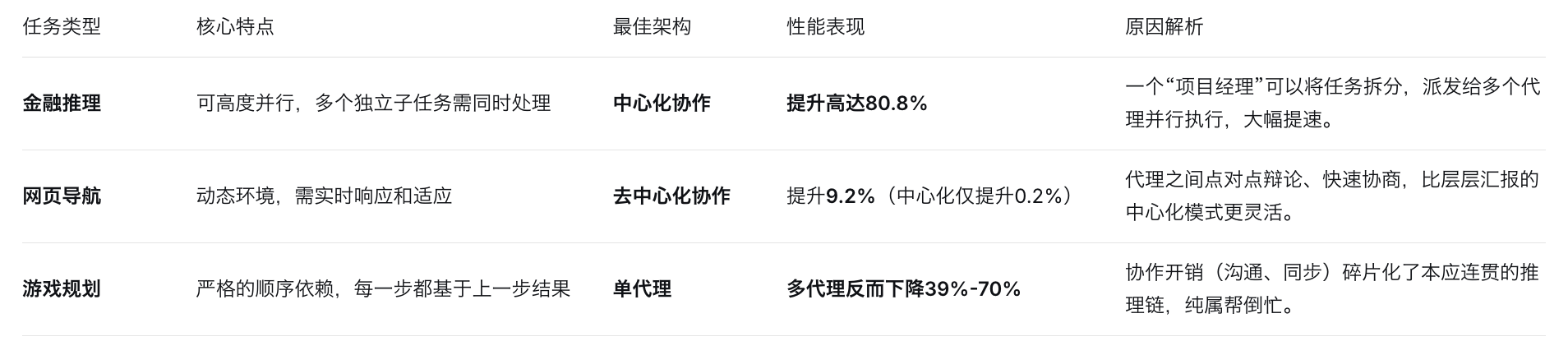
🔄 任务决定架构——不是所有任务都适合“开会”
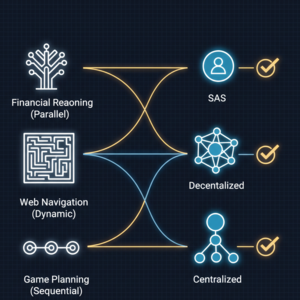
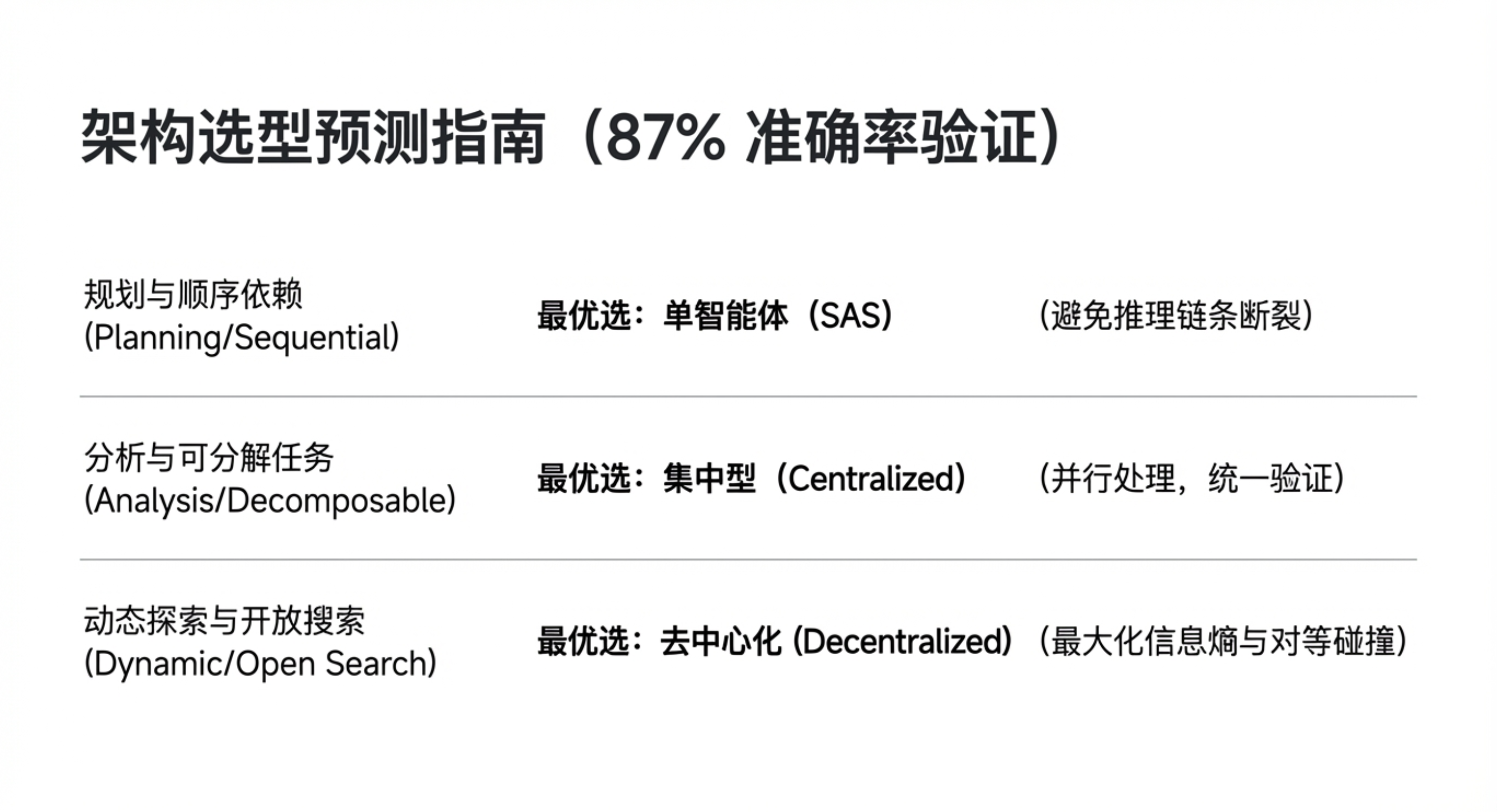
协作的收益,几乎完全取决于任务的可分解性。论文通过三类典型任务,揭示了这种匹配关系:
📊 量化指标——45%的阈值与4.4倍的误差
研究不仅停留在定性描述,更提供了可供参考的量化指标:
- 45%:协作的“盈亏平衡点”:当单代理的能力低于45%时,协作能显著提升表现;一旦超过这个阈值,增加代理带来的收益锐减。这为是否引入多代理提供了清晰的决策依据。
- 4.4倍:中心化架构的错误控制力:相比独立代理(错误无限放大),中心化协作通过引入验证节点,能将错误传播控制在4.4倍以内。这对于安全关键型任务(如金融交易、医疗诊断)具有重要参考价值。
- 87%:预测准确率:基于这些指标建立的混合效应模型,在预测未见任务的最优架构时,准确率高达87%,证明了其规律的普适性。
💸 不可忽视的成本——协作的“算力税”
多代理并非免费的午餐,其计算成本随代理数量呈幂律增长(指数1.724)。
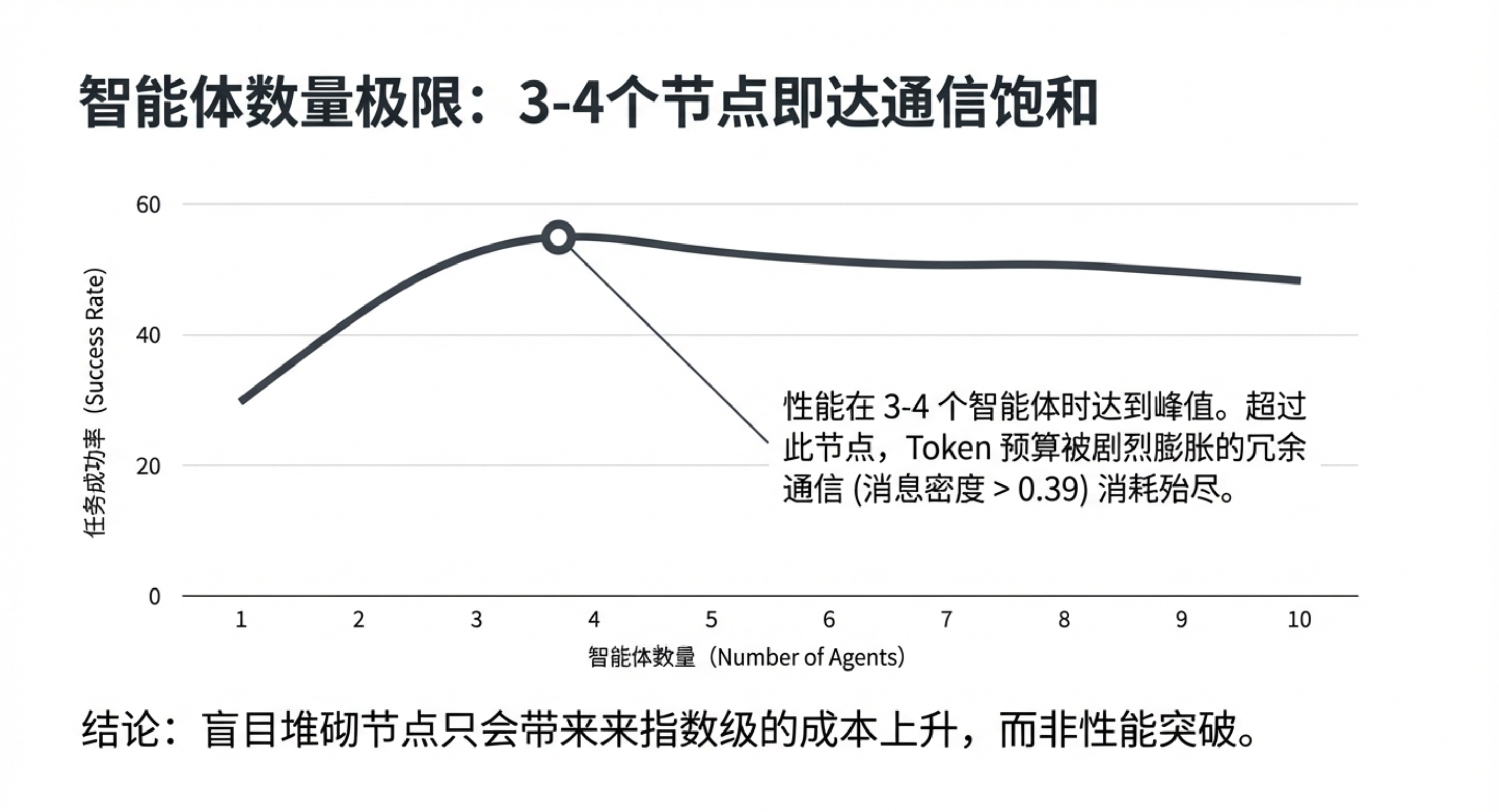
- 3-4个代理的“天花板”:在固定预算下,当代理数量超过3-4个后,通信成本将开始主导系统性能,单个代理的推理能力会被稀释得极其稀薄。
- “More agents is all you need”的迷思:论文明确指出,智能体系统的成功并不取决于代理数量,而是取决于协作架构与任务结构的精准对齐。盲目堆砌代理,只会让系统陷入过度协调的低效泥潭。
🎯 实践指南:如何为你的任务选择正确架构?
基于论文发现,我们可以提炼出以下选择原则:
- 先评估单代理能力:如果现有单代理在代表性任务上已能稳定达到45%以上的成功率,优先考虑优化它,而非引入复杂协作。
- 诊断任务的可分解性:任务能否被拆分为多个独立并行处理的子任务?如果能,中心化协作是首选。如果任务具有严格的顺序依赖性,请坚持使用单代理。
- 权衡环境动态性:在快速变化的环境中(如网页、游戏),去中心化架构的灵活优势可能超过其沟通开销。
- 计算协作的“成本账”:在引入超过3个代理前,务必评估通信开销是否会吞噬掉协作带来的收益。
