

 3
3 0
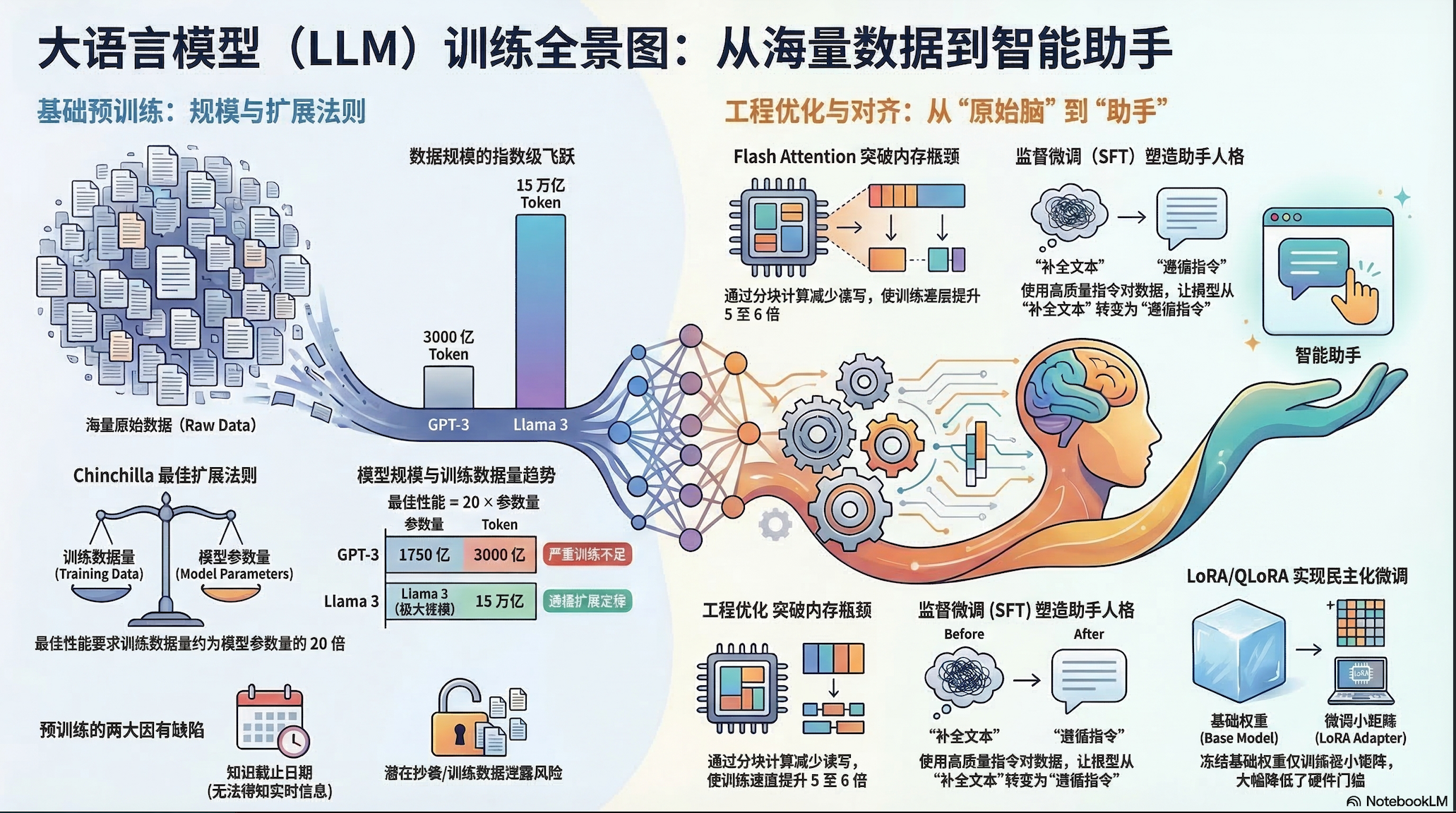
0该视频转录探讨了将原始数据转化为高效人工智能助手的复杂工程路径,重点围绕预训练、硬件优化与微型调优这三大核心阶段展开。首先,预训练是构建模型灵魂的基石,通过在数以万亿计的令牌上进行大规模计算,赋予模型基础的语言规律与知识储备。其次,为了突破硬件内存瓶颈,开发者利用并行计算、Flash Attention及混合精度训练等精妙的工程手段,极大地提升了海量参数处理的效率与速度。最后,通过指令微调(SFT)与低秩自适应(LoRA)等技术,模型从简单的文本预测者转变为对齐人类需求的实用助手。总体而言,现代大语言模型的成功不仅源于数据的堆砌,更是深度架构优化与高效工程化协作的结晶。