

 248
248 0
0本文章《 How we built our multi-agent research system》深入分析了 Anthropic 构建其 Research 功能背后的大型语言模型(LLM)多智能体架构。该系统旨在解决复杂、开放式的研究任务,通过“编排者-执行者”(Orchestrator-Worker)模式,实现了比单智能体系统更高的效率与准确性。
核心结论包括:
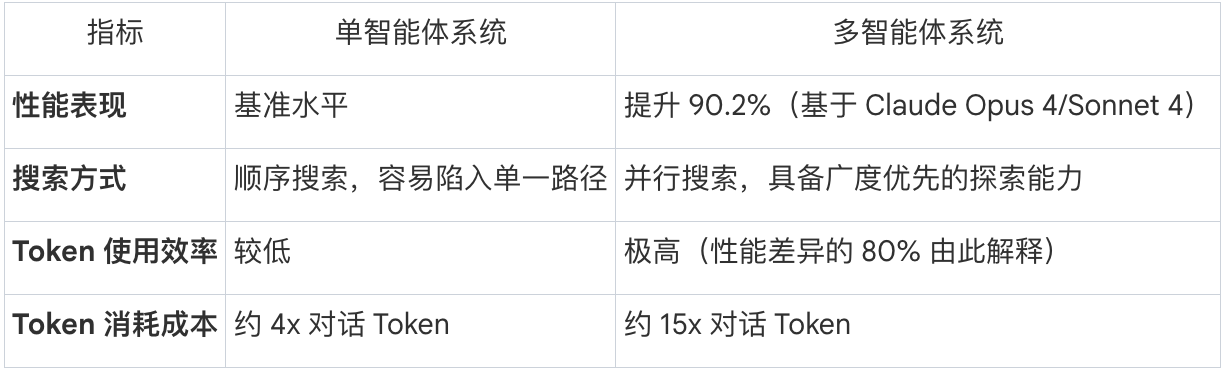
- 性能飞跃:在内部评估中,采用 Claude Opus 4 为主导、Claude Sonnet 4 为子智能体的系统在处理复杂查询时,性能优于单智能体 Claude Opus 4 达 90.2%。
- Token 驱动的扩展性:研究发现,80% 的性能差异源于 Token 使用量。多智能体系统通过分布式上下文窗口有效扩展了 Token 消耗,从而提升了推理能力。
- 成本权衡:多智能体系统的 Token 消耗量约为普通对话的 15 倍。其经济可行性取决于任务的高价值属性。
- 架构范式转移:从传统的静态检索(RAG)转向动态、多步、具有自我调节能力的自主搜索流程。
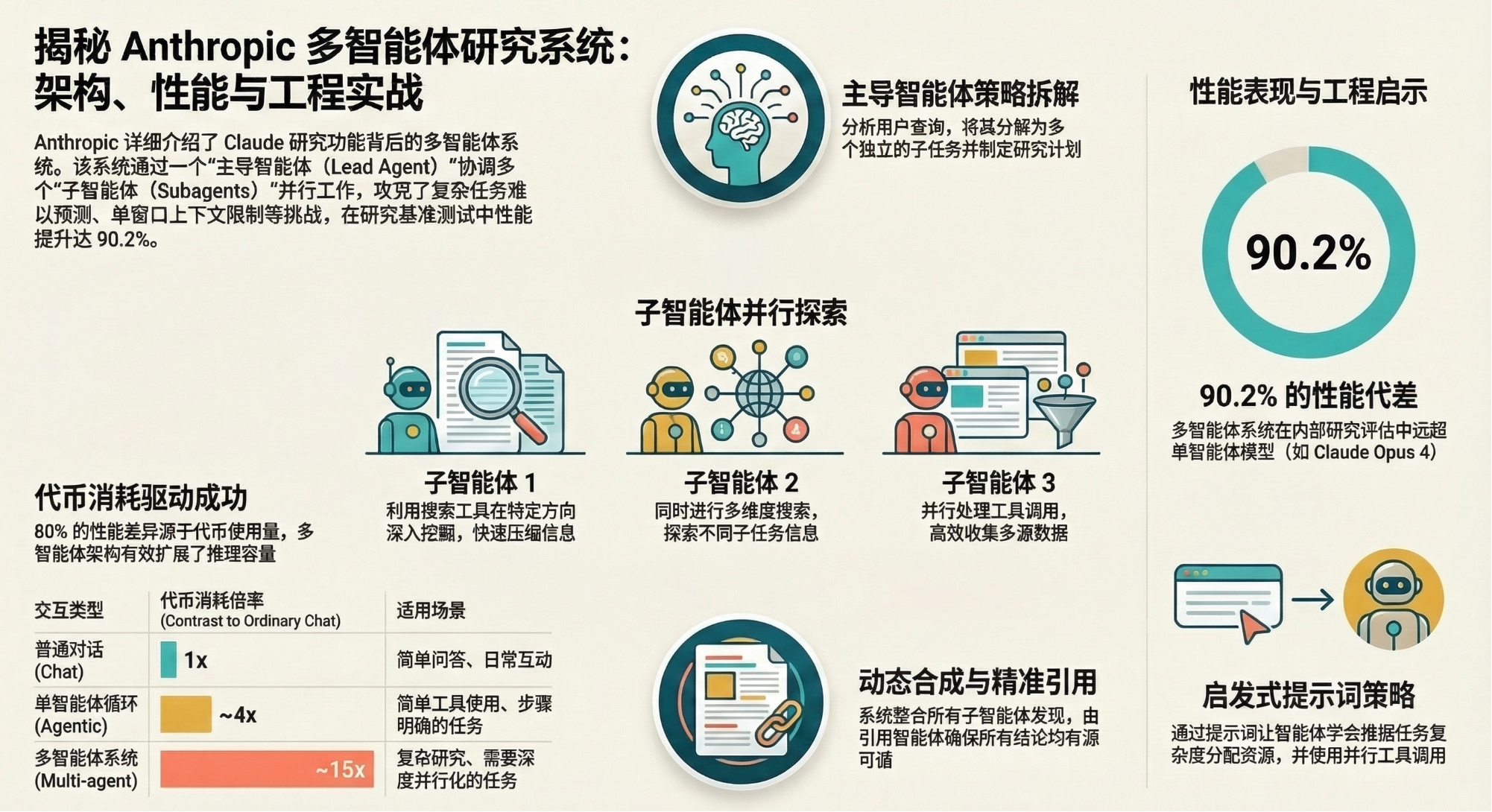
1. 核心架构与系统原理
该研究系统摒弃了预设路径的线性流程,采用了高度动态的并行协作架构。
- 1.1 编排者-执行者模式
系统采用层级化结构,将复杂任务拆解为可并行处理的子任务:
主导智能体(Lead Agent):负责分析用户查询、制定研究策略、创建子智能体并最终汇总结果。
子智能体(Subagents):作为智能过滤器,独立执行搜索任务、评估工具结果并返回精炼信息。
- 1.2 研究流程概览
系统通过以下循环流程确保研究的深度与广度:
规划与存储:主导智能体制定计划并存入外部存储,以防因上下文窗口(200,000 tokens)截断而丢失关键背景。
并行执行:生成多个子智能体,每个子智能体拥有独立的上下文窗口,通过 MCP(模型上下文协议)服务器使用外部工具。
内省与迭代:子智能体使用交替思维(Interleaved Thinking)评估结果,主导智能体根据反馈决定是否需要补充研究。
引用与输出:专门的引用智能体(CitationAgent)对所有主张进行溯源核实,确保事实准确。
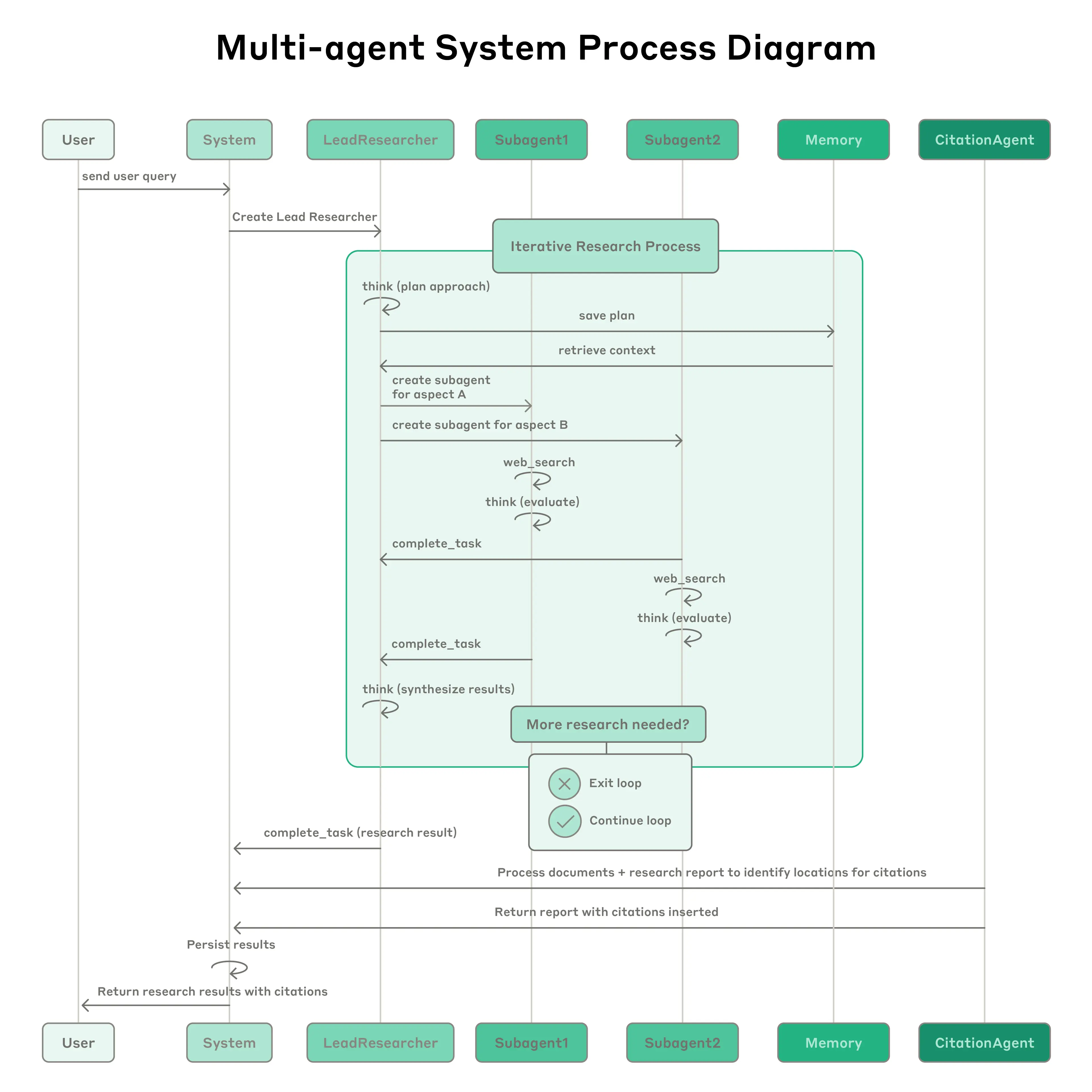
- 1.3 性能对比分析
2. 提示词工程(Prompt Engineering)的核心原则
由于多智能体系统具有极高的协调复杂度,Anthropic 总结了八项关键的提示词策略,以优化智能体行为:
- 模拟与内省:通过控制台模拟智能体步骤,识别“过度搜索”或“选择错误工具”等失效模式。
- 明确委派指令:为主导智能体提供精细的模板,确保为子智能体定义的任务具有明确的目标、输出格式及工具边界,避免重复劳动。
- 根据复杂度扩展投入:在提示词中嵌入“规模规则”。简单任务仅需 1 个智能体和少量工具调用;复杂任务则需 10 个以上智能体协同。
- 工具设计与启发式引导:为智能体提供工具选择的启发式方法(如:优先使用专业工具而非通用工具),并确保工具描述极其清晰。
- 自我改进机制:利用 Claude 4 诊断失效模式并重写提示词或工具描述。此举使后续智能体的任务完成时间缩短了 40%。
- 先广度后深度策略:引导智能体先进行简短、广泛的查询,评估格局后再逐步缩小范围。
- 强化思维过程:利用“扩展思维模式”作为草稿纸,显著提升指令遵循能力和推理效率。
- 并行化操作:主导智能体并行启动 3-5 个子智能体,且每个子智能体并行调用 3 个以上工具,使研究时间缩短高达 90%。
3. 评估与可靠性保障
评估多智能体系统具有挑战性,因为“过程”往往是非确定性的。
- 3.1 评估层级
小样本起步:初期通过约 20 个代表性查询进行测试。由于多智能体系统的改进效果通常很显著(如成功率从 30% 跃升至 80%),小样本即可提供有效反馈。
LLM 担任评委(LLM-as-judge):通过预设红利(Rubric)评估事实准确性、引用精度、完整性、来源质量及工具效率。采用单一 LLM 调用给出 0-1 分及胜负判定是最具一致性的方法。
人工校验:用于捕获自动化评估可能遗漏的边缘案例,例如智能体偏好 SEO 优化网站而非权威学术来源的偏见。
- 3.2 生产环境的工程挑战
状态化与错误补偿:智能体任务运行时间长,系统必须具备断点续传能力(Checkpoints),并利用模型智能处理工具失效,而非简单重启。
全链路追踪(Tracing):通过监控决策模式和交互结构(而非对话内容)来诊断“找不到明显信息”等逻辑故障。
彩虹部署(Rainbow Deployments):由于智能体是长程运行的,更新代码时需采用逐渐切换流量的方式,确保旧版智能体在任务完成前不被中断。
4. 关键应用场景与未来展望
多智能体研究系统在以下领域显示出显著价值:
- 软件系统开发:跨专业领域的系统构建(占当前用例 10%)。
- 内容优化:专业与技术性内容的开发(8%)。
- 商业策略:业务增长与营收策略制定(8%)。
- 学术研究:辅助教育材料与学术资料开发(7%)。
- 信息核实:对人物、地点或组织进行验证(5%)。
5. 进阶实施技巧(附录)
- 终态评估:针对修改持续状态的任务,应关注最终环境是否达到预期目标,而非纠结于中间的每一步骤。
- 长程对话管理:当上下文接近上限时,引导智能体总结已完成的工作并存入外部存储,通过生成“干净上下文”的新智能体来实现任务接力。
- 文件系统输出:允许子智能体直接将结构化结果(如代码、报告)写入外部文件系统,主导智能体仅传递轻量级引用,以减少“传声筒游戏”中的信息损失和 Token 开销。
**📺播客说明**
本播客采用虚拟主持人进行播客翻译的音频制作,因此有可能会有一些地方听起来怪怪的。如想了解更多信息,请关注微信公众号"西经东译"获取AI最新资讯。如有后续想要听的其他外文播客,也欢迎联系微信:mayday2303。
