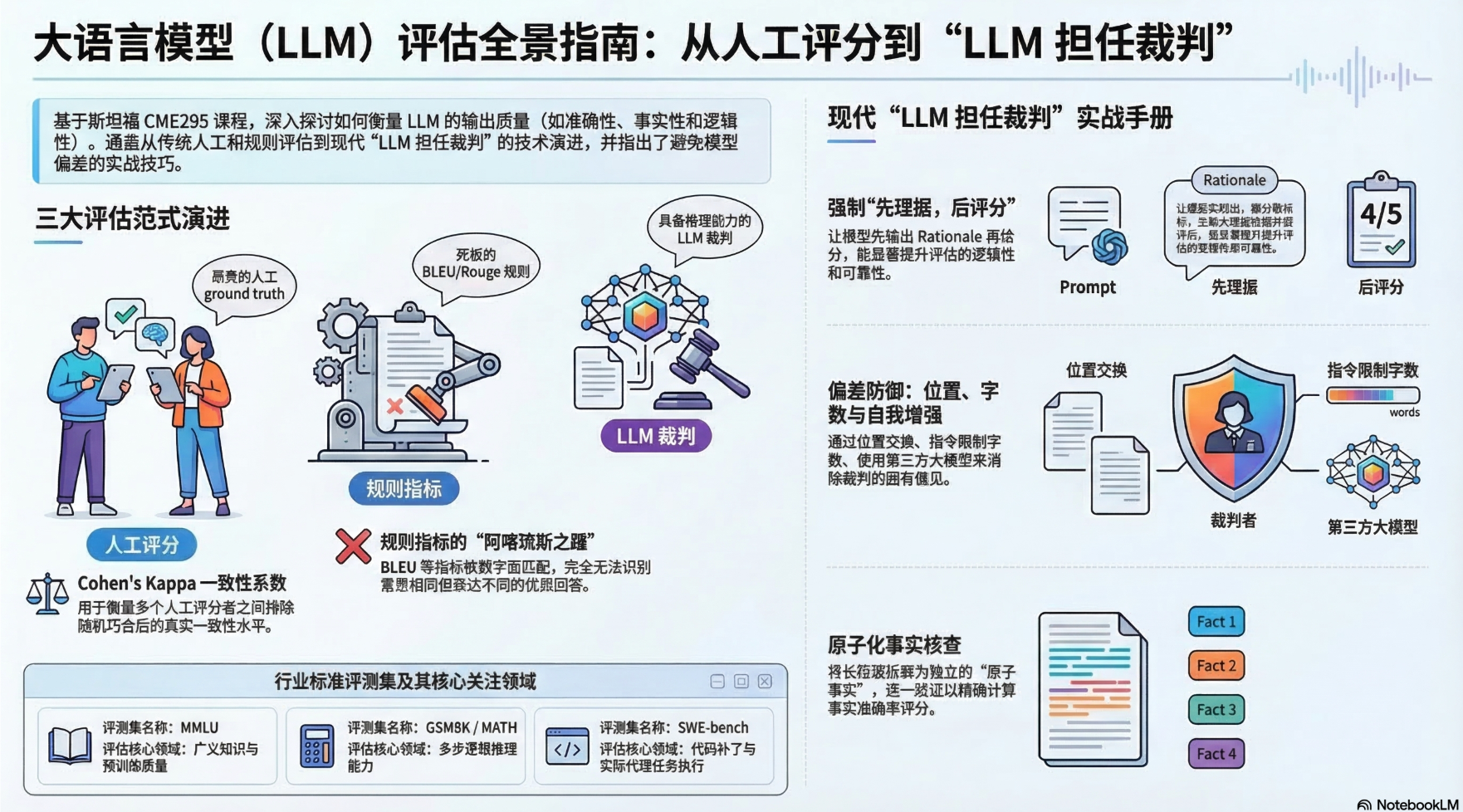
这份源自斯坦福CME295课程的访谈录深度解析了大型语言模型(LLM)评估体系的演进历程与核心挑战。文中探讨了从高成本的人工评测标准到基于规则的自动化指标(如BLEU和METEOR),再到现代主流的以模型作为评判者(LLM-as-a-judge)的范式转型。作者强调了在复杂工作流中识别位置偏差与幻觉的重要性,并详细分类了知识、推理及工具调用等维度的公共基准测试。全文旨在揭示评估不仅是追求客观评分,更需通过校准与结构化输出来确保模型表现与人类真实意图的高度一致。


 6
6 0
0