


 233
233 0
0本播客源自Anthropic官方文章《Demystifying evals for AI agents》:随着 AI 代理能力的提升,其评估难度也随之增加。代理的多轮交互、自主性以及在环境中修改状态的能力,使得传统的单轮评估方法失效。本简报旨在提炼 Anthropic 关于 AI 代理评估的核心见解,核心结论包括:
- 评估的价值在于复利效应: 早期建立评估虽有成本,但能避免在生产环境中陷入“被动修复”循环,加速模型升级,并作为产品与研究团队间的关键沟通渠道。
- 结构化组件: 有效的评估由任务、试验、评分器(代码、模型或人工)、迹线(Transcript)和最终结果(Outcome)组成。
- 分类评估策略: 针对编码、对话、研究和计算机操作等不同类型的代理,需结合确定性评分与基于模型的启发式评分。
- 从零到一的路径: 建议从 20-50 个真实故障案例开始,强调任务的无歧义性、环境的隔离性以及对迹线的定期人工审查。
- 多维度衡量: 结合自动化评估、生产监控和人工研究,形成类似于安全工程中“瑞士奶酪模型”的多层防御体系。
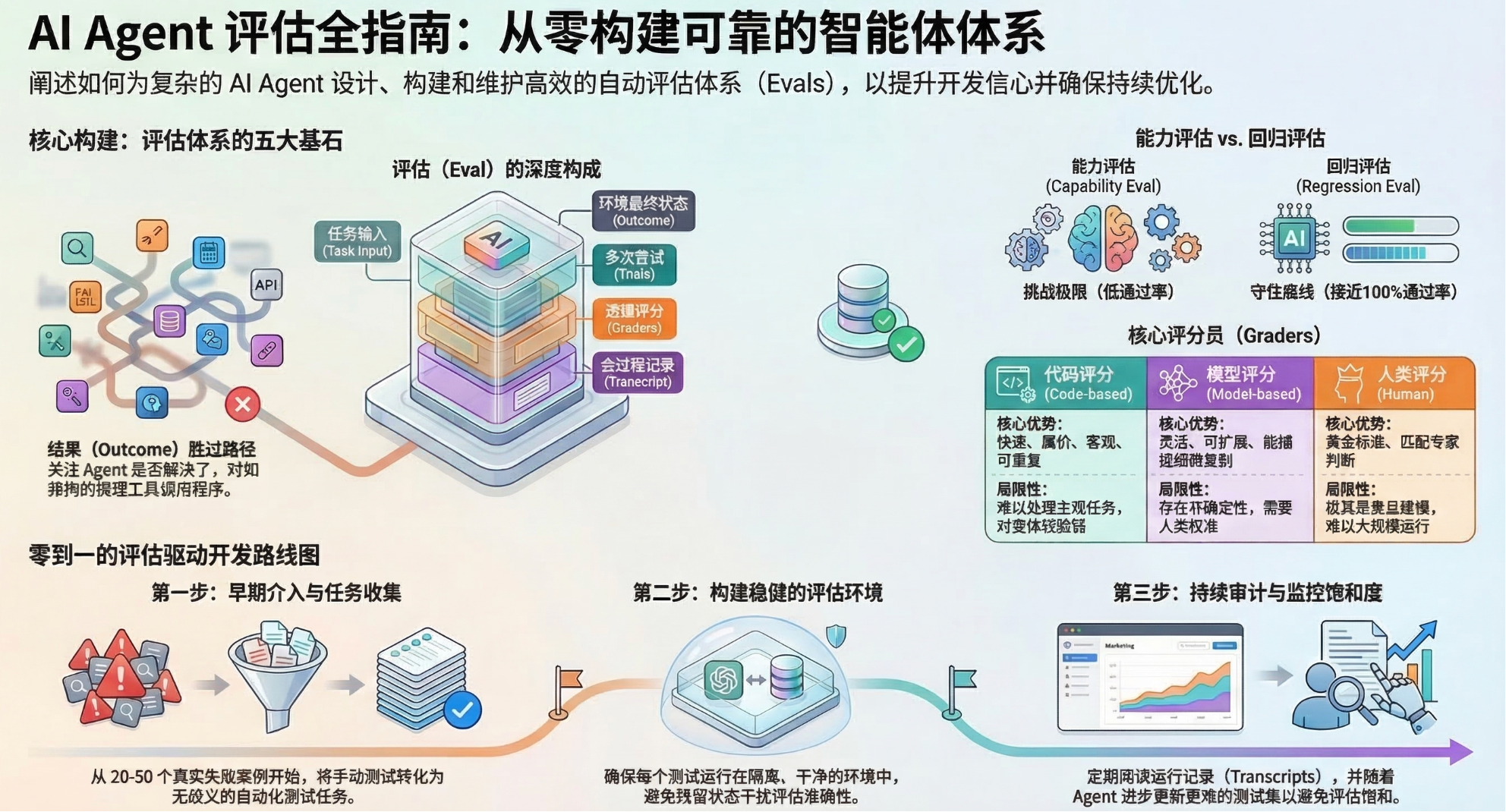
1. 评估的核心结构与术语
在代理(Agent)的语境下,评估不再仅仅是简单的“输入-输出”对,而是一个复杂的系统:

2. 为什么必须建立评估体系?
团队在初期可能依赖直觉和手动测试,但随着规模扩大,缺乏评估会导致以下瓶颈:
- 盲目开发: 无法区分真实的性能衰退与随机噪声,导致修复一个漏洞时产生更多新问题。
- 反应式调试: 只能被动等待用户反馈,无法在上线前自动测试数百个场景。
- 模型迁移迟缓: 拥有评估的团队能在几天内完成新模型的适配和提示词优化,而缺乏评估的团队则需数周的手动测试。
- 成本与收益的错位: 评估的成本在前期显现,但其收益(如降低令牌使用、减少延迟、提高一致性)会随生命周期不断累积。
3. 评分器类型对比分析
有效的评估设计通常结合以下三种评分方式:

4. 针对不同类型代理的专业评估
- 4.1 编码代理 (Coding Agents)
核心方法: 依赖确定性评分。代码是否运行?测试是否通过?
最佳实践: 除了最终结果,还应使用基于启发式的规则或模型评分器检查代码质量和工具调用行为。
- 4.2 对话代理 (Conversational Agents)
核心挑战: 交互质量本身就是评估的一部分。
方法: 通常需要第二个 LLM 模拟用户行为(甚至是对抗性用户)。
衡量维度: 任务是否解决(状态检查)、交互轮数(效率)、语气是否得体(模型红利)。
- 4.3 研究代理 (Research Agents)
核心挑战: 质量是相对的,且“事实”会随参考内容变化。
评估指标: 落地性检查( claims 是否有来源支持)、覆盖度检查(是否包含关键事实)、来源质量检查。
- 4.4 计算机操作代理 (Computer Use Agents)
方法: 在沙盒环境中运行,检查 GUI 后的后端状态(如订单是否真的下达)。
优化策略: 平衡 DOM 提取(执行快但令牌多)与截图(执行慢但令牌省)的使用,并评估代理是否选择了最合适的工具。
5. 处理非确定性:pass@k 与 pass^k
由于代理行为在不同运行中存在差异,单一的成功率无法概括性能:
- pass@k: 在 k 次尝试中至少获得一次正确解的概率。适用于“只要有一个方案可行即可”的场景。
- pass^k: 所有 k 次尝试均成功的概率。衡量代理的一致性,对于要求极高可靠性的面向客户应用至关重要。
6. 从零到一:建立可靠评估的路线图
第一阶段:积累与规范
- 及早开始: 20-50 个源自真实失败案例的任务即可起步。
- 消除歧义: 确保两个领域专家能对同一结果达成一致。如果专家无法独立完成该任务,说明任务定义有问题。
- 建立参考解: 为每个任务创建一个已知的正确输出,以证明任务是可解的并验证评分器配置。
第二阶段:设计与运行
- 环境隔离: 确保试验之间没有残留文件、缓存或资源竞争,防止关联性失败或“作弊”(如查看前次试验的 Git 历史)。
- 设计评分逻辑: 优先选择确定性评分;针对多步骤任务建立“部分给分”机制,体现成功程度的连续性。
- 防止评估绕过: 设计任务时应确保通过任务确实需要解决问题,而非寻找漏洞。
第三阶段:长期维护
- 审查迹线 (Read the Transcripts): 这是最关键的技能。失败是代理的问题还是评分器误报?阅读迹线能建立对系统的直觉。
- 监测评估饱和度: 当评估得分接近 100% 时,它就变成了回归测试套件,失去衡量进步的信号。此时需要引入更难的任务。
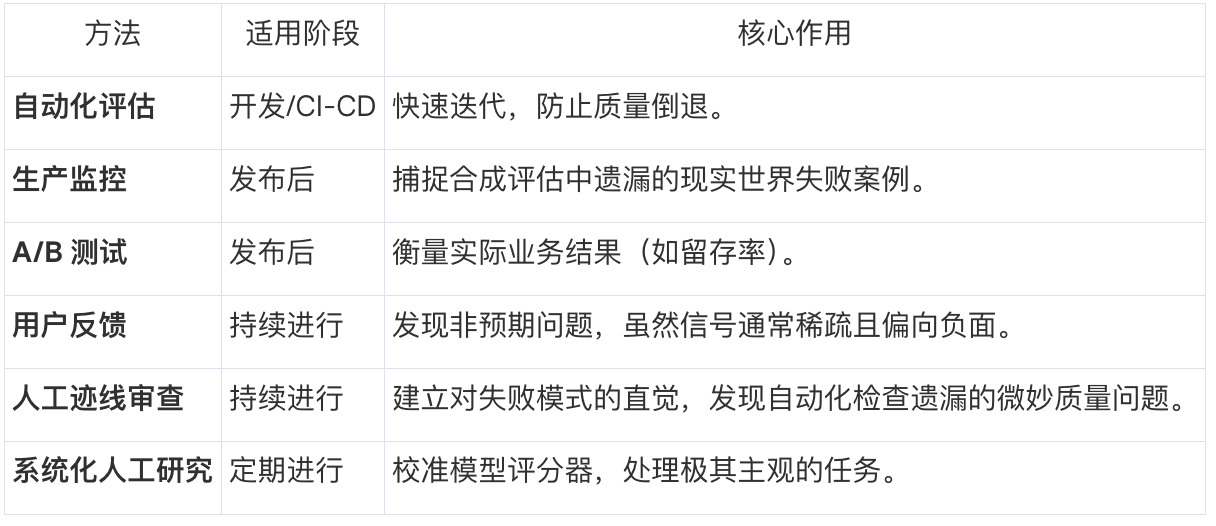
7. 全面理解性能的综合方法
自动化评估并非唯一手段,应将其与其他方法结合,构建“综合理解”:
8. 结论
评估不应被视为开发的负担,而应是核心组件。缺乏评估的团队会被动地在修复与回归之间循环,而建立评估的团队则能通过明确的目标(“Hill to climb”)加速进步。有效的评估体系应从简单的真实案例开始,通过不断迭代评分逻辑和审查迹线,最终演变为能够支撑复杂代理系统持续进化的基础设施。
**📺播客说明**
本播客采用虚拟主持人进行播客翻译的音频制作,因此有可能会有一些地方听起来怪怪的。如想了解更多信息,请关注微信公众号"西经东译"获取AI最新资讯。如有后续想要听的其他外文播客,也欢迎联系微信:mayday2303。
