

 0
0 0
0说话人1: 哈喽~今天咱们来聊个挺有意思的话题,就是Windows和Linux这俩内核的复杂度。你平时用电脑的时候,有没有感觉过有的系统用着用着就卡,有的就一直很稳?我最近跟李坚毅博士聊了聊他的研究,发现这里头门道可多了。
说话人2: 可不是嘛,我之前一直以为就是优化得好不好的问题,没想到还有这么多讲究。那李博士是从哪些方面来分析的呀?
说话人1: 首先就得从基础理论说起,李坚毅博士整理了好几个经典的计算机理论来当分析框架。比如Lehman软件演化定律,就是说软件越迭代,代码越复杂,能不能把可变的部分和稳定的核心分开,直接决定了复杂度能不能控制。还有Yourdon-Constantine耦合内聚理论,这个说的是低耦合高内聚才能降低复杂度,模块之间别互相依赖太深,自己内部功能得集中。
说话人2: 听起来有点抽象,能不能举个例子?
说话人1: 那咱们就先说说Linux,它就是严格照着这些理论来的。Linux是开源宏内核,核心就讲究模块化,能用可加载内核模块,就是LKM机制,硬件驱动、文件系统这些都能动态加载卸载,不用动核心代码。核心功能模块比如进程调度、内存管理这些,都遵循Parnas信息隐藏理论,内部实现细节藏起来,只对外暴露标准接口,模块之间依赖特别低。
说话人2: 那Windows呢?它好像跟Linux不太一样。
说话人1: 没错,Windows是闭源宏内核,核心讲究易用性和向后兼容,把好多用户态的功能都集成到内核态了,比如图形渲染、权限管理,这么一来内核功能就特别冗余。而且为了让老软件还能跑,几十年前的代码都得保留着,根本没法彻底重构。还有那个注册表,所有模块和程序都依赖它,模块之间的耦合就特别重。李博士整理的资料里说,这就是Windows复杂度高的一个主要原因。
说话人2: 那他们用什么指标来量化这些复杂度呢?总不能光靠感觉吧。
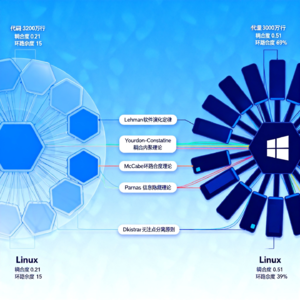
说话人1: 当然有量化指标了,李博士整理了三个核心指标,每个都有数学公式。第一个是代码量量化指标,内核总代码量等于核心模块代码量加外围适配模块代码量,还有个核心模块代码占比η,就是核心模块代码量除以总代码量。η越低,说明核心逻辑越精简,可变的适配部分和核心隔离得越好。
说话人2: 那具体数值是多少呀?
说话人1: 比如Linux 6.8版本,总代码量大概3200万行,核心模块代码量800万行,η就是800万除以3200万,等于0.25。Windows 11 22H2版本,总代码量5000万行,核心模块3000万行,η就是0.6,差了一倍还多。这就说明Linux把适配逻辑和核心逻辑彻底分开了,代码增长主要在外围,核心复杂度可控;而Windows核心逻辑冗余太多,复杂度主要在核心模块里。
说话人2: 哦,原来如此。那第二个指标呢?
说话人1: 第二个是模块耦合度系数C,公式是所有模块之间的关联度之和,除以模块数乘以模块数减一。关联度Rij就是两个模块之间的依赖程度,取值0到1。Linux核心模块有5个,每个模块之间关联度都低于0.3,比如进程调度和内存管理关联度最高也就0.28,算下来C大概是0.21,属于低耦合。Windows核心模块8个,图形渲染模块和其他模块关联度都超过0.6,算下来C是0.51,属于中高耦合,模块之间互相依赖特别深。
说话人2: 那耦合度高了有啥坏处?
说话人1: 耦合度高的话,改一个模块就得考虑其他好几个模块,容易牵一发动全身。比如Windows改内存管理模块,还得同步调整图形渲染、注册表这些模块,维护难度特别大。而Linux改网络协议栈模块,不用动其他核心模块,维护起来就简单多了。这就是李博士整理的资料里说的,耦合内聚理论对复杂度的影响。
说话人2: 那第三个指标呢?
说话人1: 第三个是逻辑层级复杂度,用McCabe环路复杂度V(G)来衡量,公式是边数E减节点数N加2倍连通分量数P。内核核心模块都是单连通分量,P就是1。比如Linux的CFS调度器模块,E是48,N是35,算下来V(G)是48减35加2,等于15,属于中等复杂度。而Windows的WoW64兼容层模块,E是126,N是89,算下来V(G)是126减89加2,等于39,属于极高复杂度。
说话人2: 为啥WoW64复杂度这么高?
说话人1: 因为WoW64要支持32位程序在64位系统上运行,得覆盖近30年的Windows版本,要处理不同版本的API调用、内存地址转换、权限适配这些,逻辑分支特别多,执行路径冗余,所以复杂度就高了。这也符合McCabe理论,逻辑复杂度随分支数量非线性增长。李博士整理的资料里还提到,Windows还有个注册表复杂度,配置项数量和内核启动时间呈线性正相关,配置项越多,启动越慢,模块之间隐性依赖也越多,进一步提升复杂度。
说话人2: 那这俩内核复杂度差异的本质原因是什么呀?
说话人1: 本质上就是设计定位和原理实现的不同。Linux定位是多场景适配的开源系统,面向专业用户和开发者,所以严格遵循经典理论,把复杂度转移到外围适配模块,核心保持精简。Windows定位是面向普通用户的商用系统,要易用、要兼容老软件,所以就得在理论上妥协,把好多功能集成到内核里,保留历史代码,导致核心复杂度高。李博士整理的资料里说,这不是技术优劣,而是不同需求下的选择。
说话人2: 这么说的话,Linux适合专业人士,Windows适合普通用户?
说话人1: 可以这么理解。Linux稳定、可扩展,能适配从嵌入式设备到超级计算机,但是对用户技术要求高;Windows易用,软件生态丰富,普通用户上手容易,但是复杂度高,维护起来难。李博士整理的资料里还提到,经典计算机科学理论是内核复杂度控制的核心支撑,Linux遵循得好,复杂度就可控,Windows妥协了理论,换来了用户体验和兼容性。
说话人2: 那未来这俩内核会怎么发展呀?
说话人1: 李博士整理的资料里也有展望。Linux可以结合虚拟化、容器化技术,优化外围适配复杂度;Windows可以通过模块化重构、兼容层分离,在保证兼容的前提下降低核心冗余和耦合度。还可以完善量化模型,加入更多适合现代内核的指标,比如虚拟化场景下的复杂度指标。
说话人2: 今天聊的这些还挺有意思的,原来操作系统内核还有这么多门道。
说话人1: 是啊,平时用电脑的时候感觉不出来,深入了解了才发现,每个系统背后都有一套完整的理论和设计思路。李坚毅博士整理的这些内容,把复杂的技术用数理化的方式呈现出来,让咱们能更清晰地看到差异和原因。
说话人2: 没错,感觉收获挺多的。
