

 469
469 0
0本文档《Harness design for long-running application development》总结了 Anthropic 实验室团队在提升 Claude 执行长时程、自主性应用开发任务方面的研究成果。核心结论表明,**架构设计(Harness Design)**是突破 Agent 性能瓶颈的关键。通过引入受生成对抗网络(GAN)启发的“生成者-评估者”多 Agent 架构,并制定具象化的评估准则,可以将主观的设计质量和复杂的软件工程转化为可量化、可迭代的流程。随着模型能力(如从 Claude 4.5 演进至 4.6)的提升,架构设计虽可简化,但其作为突破模型原生能力边界的手段依然不可或缺。
1. 初始实施的局限性与失效模式
在早期尝试中,即便使用提示词工程改进,Claude 在处理复杂前端设计和长时程编码任务时仍会遇到性能瓶颈。研究识别出两种主要的失效模式:
- 连贯性丢失与“上下文焦虑” (Context Anxiety):随着上下文窗口填满,模型在长任务中容易失去逻辑连贯性。
当模型意识到接近其上下文限制时,会表现出“上下文焦虑”,即过早地收尾工作。
解决方案: 采用“上下文重置”(Context Resets),清除窗口并结合结构化交付物(Artifacts)将状态传递给新启动的 Agent。这比简单的压缩(Compaction)更有效,因为重置能提供“干净的白板”。 - 自我评估缺陷 (Self-evaluation Bias):模型在评估自身产出时往往过于自信,倾向于给出积极评价,尤其是在主观的设计任务中。
即便任务结果可验证,Agent 也常因判断力不足而阻碍性能。
解决方案: 将“执行者”与“评估者”分离,并对独立评估者进行针对性的“怀疑论”调优。
2. 前端设计:将主观质量转化为可评级准则
为了让 Claude 产生高质量的视觉设计,研究人员开发了一套评估框架,将主观审美拆解为四个具体维度:

架构运作流程:
- 生成者 (Generator): 基于提示词创建 HTML/CSS/JS。
- 评估者 (Evaluator): 使用 Playwright MCP 交互式地操作页面,进行截图、分析并根据准则打分并撰写详细批评。
- 循环迭代: 运行 5 到 15 次迭代。生成者根据反馈决定优化当前方向或进行审美上的大转型(Pivot)。
- 成果: 在一个案例中,模型在第 10 次迭代时打破了常规,将传统博物馆网页重构为具有 CSS 透视感的 3D 空间交互体验。
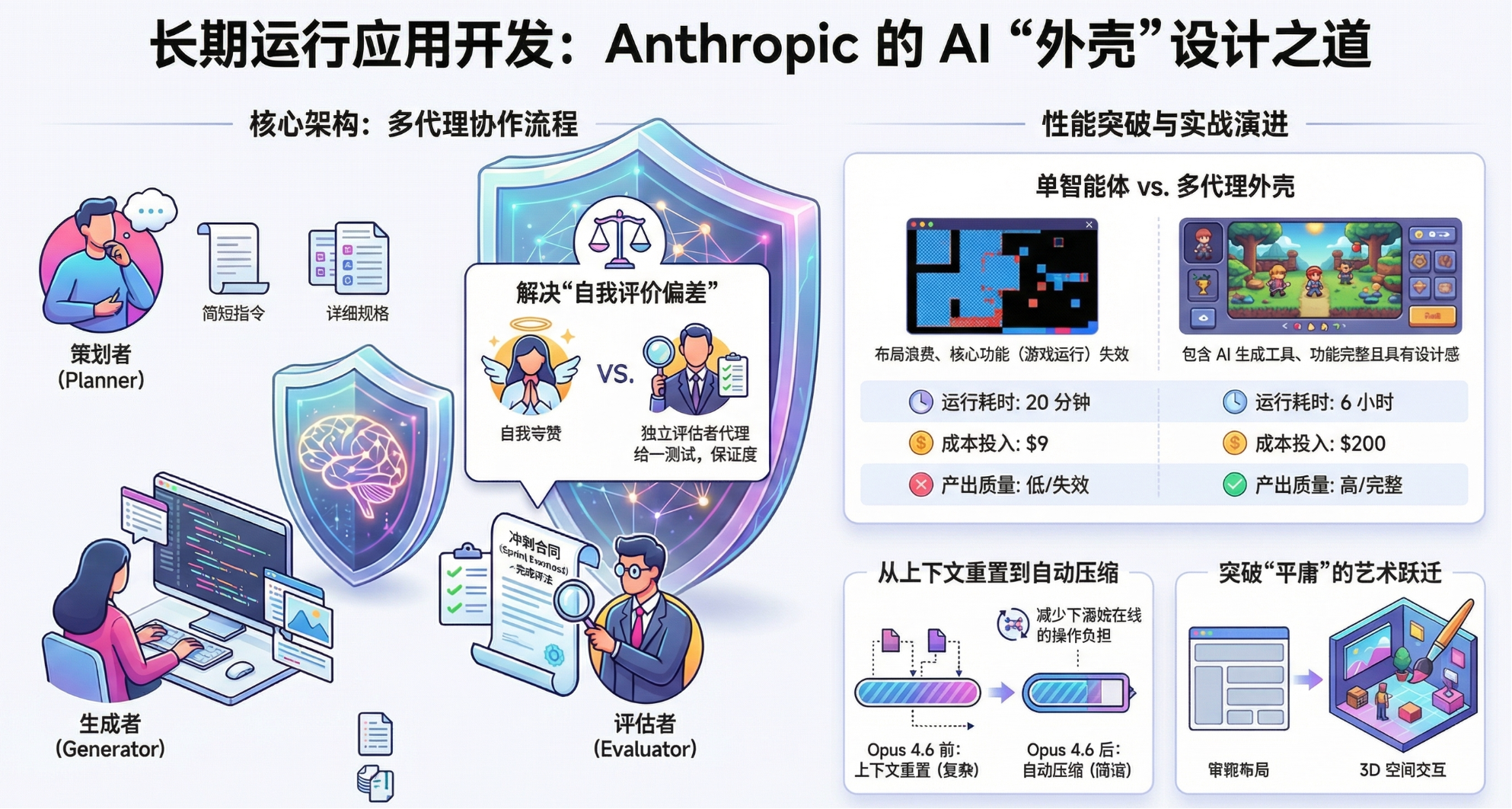
3. 全栈编码:三 Agent 协作架构
针对长时程、自主性的全栈开发,Anthropic 构建了一个由三个角色组成的系统:
- 规划者 (Planner): 将简单的 1-4 句提示词扩展为完整的产品规格书。侧重于产品背景和高层技术设计,避免过度规定底层细节,以防止错误级联。
- 生成者 (Generator): 采用“冲刺”(Sprint)模式,每次实现一个功能。拥有 Git 版本控制权限,并在交付 QA 前进行初步自我评估。
- 评估者 (Evaluator): 充当 QA 角色。使用 Playwright 模拟用户行为,测试 UI、API 终点和数据库状态。
关键机制——冲刺合同 (Sprint Contract): 在编写代码前,生成者与评估者就“完成”的定义达成一致。生成者提出实现方案和验证方法,评估者审核。这种“协商”机制确保了开发过程忠实于规格书,同时避免了过早过度规范。
4. 性能演进:从 Claude 4.5 到 4.6
随着模型原生能力的提升,架构设计的复杂性得到了有效精简:
- 4.5 时代的复杂架构
挑战: 强烈的上下文焦虑,需要频繁的上下文重置。
方案: 必须使用冲刺分解(Sprint decomposition)来保持连贯性。
案例对比(2D 复古游戏制作器):Solo 模式: 20分钟完成,成本 $9。结果布局粗糙,工作流僵硬,游戏逻辑断裂。
架构模式: 6小时完成,成本 $200。结果功能丰富(含 AI 生成关卡工具),虽然物理引擎有瑕疵,但核心逻辑完全可用且经过了 27 项细粒度测试。
- 4.6 时代的简化架构
进步: Claude 4.6 改进了长上下文检索、代码审查和调试能力。
调整:删除了上下文重置,转而使用 SDK 的自动压缩。
取消了强制性的冲刺分解,模型可以连贯运行数小时。
评估者转为在任务末尾进行单次质量检查(除非任务处于模型能力边缘)。
数字音乐工作站 (DAW) 案例:时长: 约 4 小时;成本: $124.70。
结果: 生成了一个包含编排视图、混音器和自主 AI 编曲 Agent 的功能性 DAW。尽管在处理音频捕获等深度硬件交互上仍有 stub(占位)代码,但已具备核心生产力雏形。
5. 核心洞察与未来结论
- 架构设计的价值并非恒定: 评估者的必要性取决于任务难度与模型原生能力边界的相对位置。当任务超出模型可靠处理范围时,架构提供的“护栏”价值极高。
- 自动化测试是短板: Claude 原生并不是一个优秀的 QA Agent。它容易表现得过于宽容或测试过于表面。必须通过“读取日志 -> 识别判断偏差 -> 更新提示词”的循环来不断调优评估者。
- 工程化原则:从最简单的架构开始,仅在需要时增加复杂度。
随着模型升级,应主动剥离不再承重的架构组件。
通过拆解任务和应用专门 Agent,可以释放出模型单次生成无法达到的潜能。
总结而言,Anthropic 的经验表明:AI 工程师的价值在于不断寻找模型能力与新型架构组合之间的平衡点,以实现从“生成简单片段”到“自主构建复杂系统”的跨越。
**📺播客说明**
本播客采用虚拟主持人进行播客翻译的音频制作,因此有可能会有一些地方听起来怪怪的。如想了解更多信息,请关注微信公众号"西经东译"获取AI最新资讯。如有后续想要听的其他外文播客,也欢迎联系微信:mayday2303。
