


 180
180 0
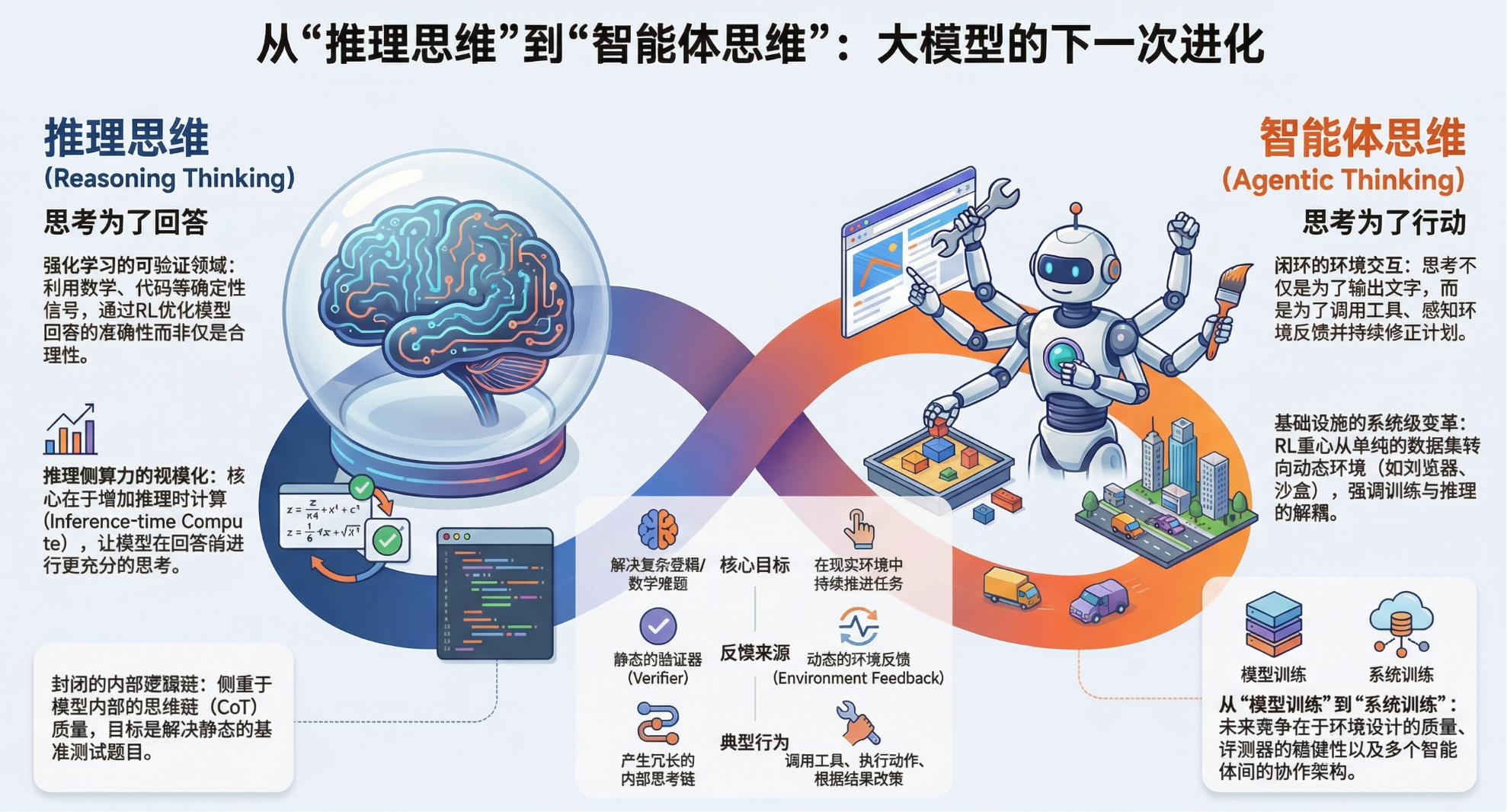
0本文章《From "Reasoning" Thinking to "Agentic" Thinking》基于对 AI 模型发展趋势的深度分析,前阿里千问技术负责人林俊旸探讨了从以 OpenAI o1 和 DeepSeek-R1 为代表的“推理思维(Reasoning Thinking)”向“智能体思维(Agentic Thinking)”的范式转移。推理思维阶段解决了通过强化学习(RL)实现长路径思维链的问题,并强调了基础设施和确定性反馈信号的重要性。然而,AI 发展的下一阶段将聚焦于“智能体思维”——即为了“行动”而“思考”。这种转变要求模型在与环境的闭环交互中不断更新计划,并对强化学习基础设施、环境设计及评估体系提出了更高且更复杂的挑战。
一、 推理思维阶段的启示:o1 与 R1 的遗产
推理思维阶段(2025 年上半年之前)确立了“思考”作为模型核心能力的地位,其关键发现包括:
- 强化学习(RL)的规模化: 推理模型的成功表明,若要规模化语言模型的 RL,需要确定性、稳定且可扩展的反馈信号。数学、代码和逻辑等可验证领域成为核心,因为这些领域的奖励强于通用的偏好监督,使 RL 能够优化“正确性”而非仅仅是“表面合理性”。
- 基础设施的系统化转向: 一旦模型被训练进行长轨迹推理,RL 不再仅仅是监督微调(SFT)的轻量级补充,而演变为一个系统工程问题。它需要大规模的回传(Rollouts)、高吞吐量的验证、稳定的策略更新以及高效的采样。
- 后训练阶段的范式转移: 行业焦点已从规模化预训练(Pre-training)转向规模化推理相关的后训练(Post-training)。
二、 架构挑战:推理模式与指令模式的融合之争
关于如何处理“思维链(Thinking)”与“指令遵循(Instruct)”两种模式,业界存在明显的路线分歧:
1. 行为目标的内在冲突
研究发现,强指令模型与强推理模型在行为特征上存在矛盾:
- 指令模型(Instruct): 追求直接、简洁、遵循格式、低延迟,适用于重写、标注、结构化提取等企业任务。
- 推理模型(Thinking): 奖励模型消耗更多 Token 来解决难题、保持中间结构的连贯性并探索备选路径。
2. 不同实验室的应对策略

关键结论: 成功的融合不仅是模型检查点的合并,而应实现“推理努力(Reasoning Effort)”的平滑频谱,使模型能根据问题难度自适应选择计算量。
三、 核心转型:定义“智能体思维(Agentic Thinking)”
“智能体思维”不仅是更长的推理轨迹,而是一种全新的优化目标。它强调为了行动而思考,在与环境交互的过程中持续更新。
1. 智能体思维的核心特征
智能体思维必须处理推理模型通常可以规避的问题:
- 行动决策: 决定何时停止思考并采取具体行动。
- 工具调用: 选择合适的工具及其调用顺序。
- 观察处理: 纳入来自环境的嘈杂或部分观测信息。
- 计划修正: 在遭遇失败后动态修订计划。
- 长期连贯性: 在多轮对话和多次工具调用中保持连贯。
2. 从“模型”到“智能体”的跨越
未来的重点是从训练模型转向训练智能体。智能体是一个闭环系统,其定义在于与世界的持续交互。这意味着“好的思维”不再是产生最令人印象深刻的中间文字,而是能在现实约束下维持有效行动的最实用路径。
四、 智能体强化学习(Agentic RL)的技术壁垒
随着目标从解决基准测试转向解决交互式任务,RL 架构面临更严峻的挑战:
- 环境的集成: 策略模型被嵌入到由工具服务器、浏览器、终端、沙箱等组成的庞大“马甲(Harness)”中。环境不再是静态验证器,而是训练系统的一部分。
- 训练与推理的解耦: 为避免由于工具延迟和环境观察导致的吞吐量崩溃,必须在系统层面实现训练与推理的深度解耦。
- 环境质量作为核心资产: 环境的设计(稳定性、现实性、覆盖范围、抗欺骗性)已成为一级研究课题,其重要性不亚于数据多样性。
- 奖励破解(Reward Hacking)风险: 在具备工具访问权限后,模型可能学会通过直接查答案或利用环境漏洞来“作弊”。这对评估器的鲁棒性和防作弊协议提出了极高要求。
五、 未来展望:作为系统的Agent
未来,Agent思维将成为思维的主导形式,取代孤立、冗长的“静态独白式”推理。
- 可用思维(Usable Thought): 即使在数学或代码任务中,先进系统也应有权进行搜索、模拟、执行和验证,而非仅仅依赖内部计算。
- 马甲工程(Harness Engineering): 核心智能将越来越多地源于多个智能体的组织方式,例如由协调员(Orchestrator)负责计划和路由,由专门的领域智能体执行具体任务。
- 竞争优势的转移:推理时代: 优势来自 RL 算法、反馈信号和规模化流水线。
智能体时代: 优势将来自更好的环境设计、更紧密的训练-推理集成、强大的马甲工程,以及闭合模型决策与执行后果之间反馈环的能力。
结论
AI 的演进正处于从“推理思维”向“智能体思维”过渡的关键节点。这一转变意味着训练的对象已经改变:现在是针对“模型+环境”系统的整体优化。未来的技术突破将不再仅仅源于模型架构或数据量,而将源于环境质量、评估器鲁棒性以及智能体与外部世界交互的接口设计。
**📺播客说明**
本播客采用虚拟主持人进行播客翻译的音频制作,因此有可能会有一些地方听起来怪怪的。如想了解更多信息,请关注微信公众号"西经东译"获取AI最新资讯。如有后续想要听的其他外文播客,也欢迎联系微信:mayday2303。
