8
8 0
0这份材料介绍了Variational JEPA (VJEPA) 及其扩展版本 Bayesian JEPA (BJEPA),这是一种用于自监督学习和世界建模的概率框架。与传统的生成模型不同,该架构放弃了对原始观测值(如像素)的重构,转而通过预测潜在表示来捕捉环境动态,从而有效过滤掉不相关的噪声和高熵干扰。VJEPA 利用变分目标函数对未来状态的预测不确定性进行显式建模,并从理论上证明了其潜在表示足以支持最优控制。BJEPA 则进一步引入了专家乘积(Product of Experts)机制,将学习到的动力学特征与任务先验(如目标或物理约束)结合,实现了无需重新训练的零样本任务迁移。这种方法为在复杂、嘈杂的环境中进行具备不确定性感知能力的规划与控制提供了一个高效且稳健的基础架构。
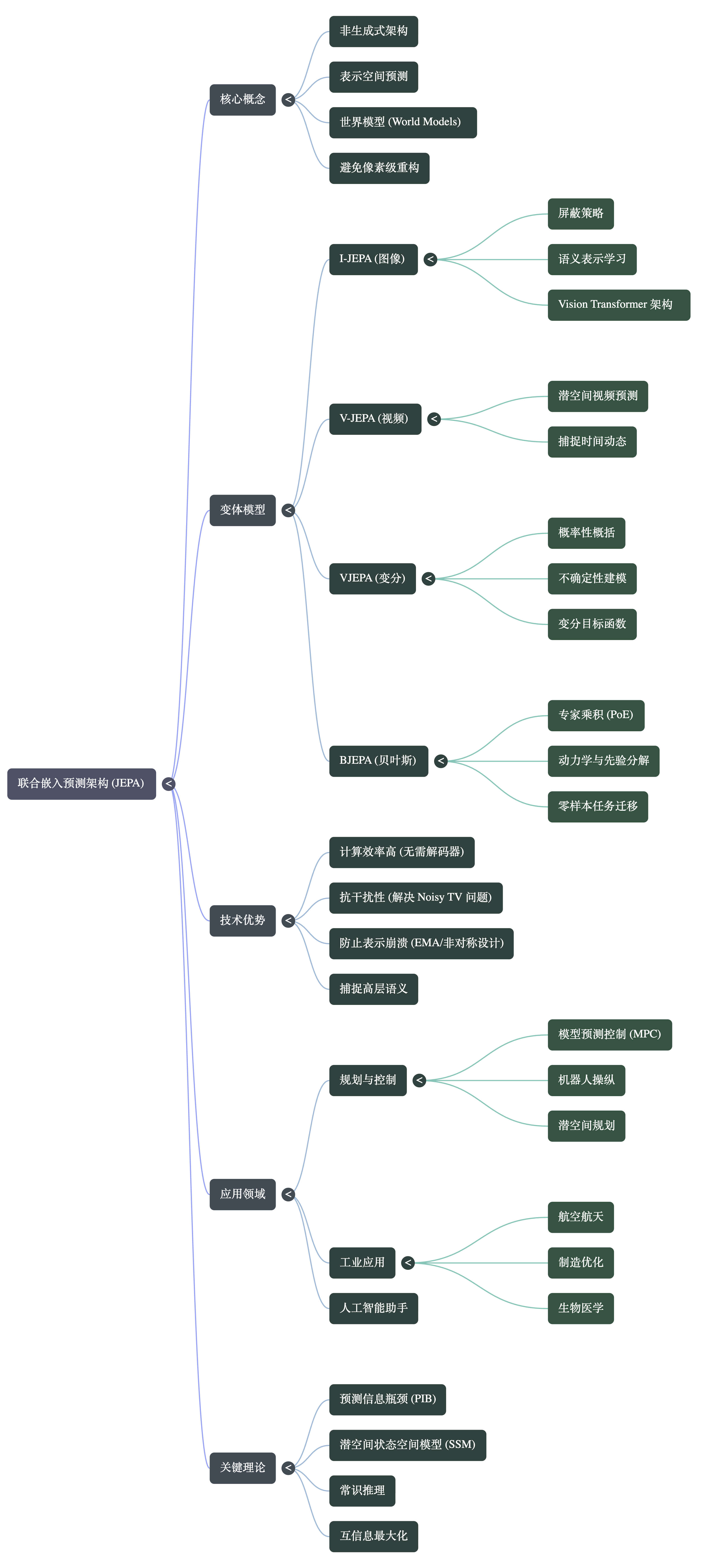
JEPA(联合嵌入预测架构)通过在抽象的表征空间中进行预测,而非生成原始的、高维的感官数据(如像素),来学习世界模型。它采用双编码器架构:一个上下文编码器将可见的上下文信息映射为潜在表征,另一个目标编码器将缺失的部分或未来状态(目标)映射为潜在表征。随后,预测器网络尝试基于上下文表征(通常会结合一个用于处理不确定性的潜在变量)来预测目标表征,整个损失函数的计算完全在嵌入空间中进行,从而绕过了向像素解码的步骤。
这种抛弃像素重建的设计解决了传统生成式世界模型的核心痛点:
- 规避不可预测的“滋扰变量”(Nuisance Variables)和高熵噪声: 在现实世界中,预测未来的每一个原始像素(例如风中摇曳的树叶、地毯的细微纹理或水面的涟漪)不仅计算量呈指数级增长,而且大部分细节对于理解物理世界和执行任务而言是毫无意义的。
- 充当预测信息瓶颈(Predictive Information Bottleneck): 试图重建像素的生成式模型往往会被迫分配算力去拟合嘈杂的细节(这被称为“嘈杂电视”问题),而JEPA的预测机制允许编码器主动过滤掉不可预测且无关的视觉噪音。通过消除不必要的像素级细节,JEPA将学习的重点引导至捕捉因果关系、空间结构和物理动力学等本质的“常识”上。
在不依赖像素作为约束的情况下,JEPA需要克服“表征坍塌”(Representation Collapse)的风险(即模型可能会通过输出恒定值来让预测误差降为零)。为了解决这一问题,JEPA采用了非对称的架构设计——例如,通过上下文编码器参数的指数移动平均(EMA)来缓慢更新目标编码器的参数。同时,它通常结合VICReg等自监督正则化损失函数,通过最大化潜在特征的信息量、方差和去相关性,来强制表征空间保持丰富的结构。
在学习世界模型并用于实际规划时,JEPA架构展现出强大的扩展性:
- 分层多尺度推理(H-JEPA): 通过将多个JEPA模块进行堆叠,系统可以实现类似人类大脑的多尺度处理。底层JEPA处理短期的、包含更多底层细节的预测,而高层JEPA则基于底层输出的抽象特征,忽略附带细节,进行更长远的时间跨度和概念层面的预测规划。
- 潜在空间中的模拟与控制: 像 VJEPA 或 BJEPA 这样的变体引入了概率建模来明确表达对未来的不确定性。这使得人工智能代理能够直接在潜在表征空间中“想象”未来并进行模型预测控制(MPC),无需耗费算力渲染出未来的画面,从而实现了极高效的复杂任务规划。
VJEPA 与 BJEPA 在处理不确定性时有何不同?
VJEPA (Variational JEPA) 和 BJEPA (Bayesian JEPA) 在处理不确定性时的核心区别在于不确定性建模的结构化方式以及模块化程度。
VJEPA(变分联合嵌入预测架构)处理不确定性的方式:
- 显式分布预测:VJEPA 放弃了传统 JEPA 的单一确定性点预测,转而直接在表示空间中学习未来潜在状态的条件预测分布(例如具有学习到的均值和协方差的高斯分布)。
- 单一的概率预测模型:它通过概率模型 $p_\phi(Z_T | Z_C, \xi_T)$ 来表示未来的不确定性,这意味着它可以根据当前的上下文预测出多个可能的未来模态。
- 蒙特卡洛采样传播:在推理或规划时,VJEPA 可以在预测分布中提取多个样本来显式地表示并传播未来的不确定性,从而评估不同的合理未来轨迹。
BJEPA(贝叶斯联合嵌入预测架构)处理不确定性的方式:
- 基于“专家乘积”的贝叶斯分解:BJEPA 在 VJEPA 的基础上进行了扩展,它将预测信念显式分解为两个独立的模块:一个代表系统动力学的“似然专家”,另一个代表约束条件的“先验专家”。
- 分离“物理可能性”与“任务约束”:在评估未来的不确定性时,似然专家 $p_{like}(Z_T|Z_C)$ 根据历史上下文预测世界自然演化的可能性(即物理上可能发生什么);而先验专家 $p_{prior}(Z_T|\eta)$ 则注入辅助信息,如目标区域、安全约束或物理流形(即任务期望或要求发生什么)。
- 后验融合的推理机制:BJEPA 通过计算这两个分布的乘积并进行归一化(逻辑“与”操作),将最终的预测限制在物理可行性与任务依从性相交的流形空间内。这种分离不确定性的方法使得模型能够在不重新训练底层物理动力学模型的情况下,实现新任务约束的零样本转移 (Zero-Shot Transfer)。
总结来说,VJEPA 将不确定性封装在一个基于历史的单一概率分布中,而 BJEPA 则将不确定性处理转化为一个贝叶斯融合过程,通过模块化地结合环境的固有不确定性(动力学)和外部的目标约束(先验),实现了更灵活、可控的规划和预测。
探讨“嘈杂电视”实验如何证明模型对干扰的鲁棒性
“嘈杂电视”(Noisy TV)实验是一个旨在压力测试模型“对干扰变量的不变性”(nuisance invariance)的分析实验。在这个思想实验中,如果人工智能被设定为通过寻找新奇事物或预测误差来获得奖励,它往往会沉迷于无法控制、不可预测的局部噪声(就像盯着电视上的雪花噪点),从而无法在实际任务中取得实质性进展。
该实验通过对比不同模型在极端噪声环境下的表现,深刻地证明了联合嵌入预测架构(JEPA/VJEPA/BJEPA)相较于传统生成式模型对干扰具有更强的鲁棒性。具体证明过程和原理解析如下:
1. 实验设计:用高方差噪声淹没真实信号
实验构建了一个线性高斯系统,其中系统的观察维度($D_x=20$)远大于真实的底层信号维度($D_s=4$)。系统生成的观察数据由两部分组成:
- 真实信号:低方差且稳定演化的核心信息。
- 干扰噪声(嘈杂电视):高方差的随机游走变量,并且可以通过缩放因子 $\sigma$ 不断被放大。在最高的噪声级别($\sigma=8.0$)下,干扰项的方差可达真实信号的约64倍,真实信号被完全淹没在噪声中(信噪比降至 -2.2 dB)。
2. 实验结果对比:生成式模型的灾难 vs. VJEPA的坚挺
- 生成式模型(如 VAE 和 AR)陷入崩溃:随着噪声增加,这类模型提取真实信号的能力出现灾难性下降。在最高噪声级别下,VAE 对真实信号的恢复率($R^2$)骤降至约 0.50,而对噪声的恢复率却高达 0.62。这表明它们被“嘈杂电视”吸引,将计算资源用于追踪高方差的干扰项,从而忽略了真正的信号。
- 预测架构(VJEPA 等)的极强鲁棒性:无论噪声多大,VJEPA 及其变体都保持了对真实信号的高恢复率($R^2 > 0.84$)。在可视化中,它们成功充当了“潜在过滤器”(latent filters),滤除了高频的视觉噪声,紧紧追踪着底层的真实信号。
3. 核心原理:为什么 VJEPA 能够无视干扰?
实验揭示了模型底层目标函数的根本差异(即“PCA 与 CCA 的区别”):
- 像素级重建 迫使模型编码噪声(隐式 PCA):生成式模型(如 VAE)的训练目标是最大化像素级观察的对数似然,这要求它们在隐空间中隐式地执行非线性主成分分析(PCA)。为了最小化重建误差,模型必须优先考虑能够解释输入数据中最大方差的维度。当干扰噪声的方差大于真实信号时,模型在数学上就被迫去模拟这些噪声。
- 抽象空间预测 赋予模型“过滤”能力(隐式 CCA):VJEPA 完全放弃了像素级的重建,转而在抽象的潜在空间(latent space)中进行预测。它遵循**预测信息瓶颈(PIB)**原理,隐式地执行典型相关分析(CCA),其目标是最大化过去状态与未来状态之间的“预测互信息”。由于“嘈杂电视”中的随机噪点对于预测未来真正的状态变化毫无帮助,VJEPA 在计算预测损失之前,就能自然而然地将其视为冗余信息并予以丢弃。
总结:“嘈杂电视”实验通过数学和实证证明了,只要模型依赖于像素级的自动回归或重建目标,就不可避免地会被高熵的局部细节(如纹理、相机噪声或无关动态)所干扰。而 VJEPA 通过纯粹的潜在状态预测(latent-space prediction),在设计上就具备了对干扰变量的不变性,使其能够高效剥离出对规划和控制有用的因果动态。
如果预测分布是多模态的,MAP规划还会有效吗?
如果预测分布是多模态的(例如机器人在岔路口可以选择向左或向右),仅依赖 MAP(最大后验概率)或均值轨迹规划可能会失效,甚至导致不安全的决策。
主要原因和替代方案如下:
- 忽略不确定性和潜在的高代价风险:MAP 规划是一种将规划简化为确定性推出的近似方法,它在单峰分布且不确定性较弱的环境中非常有效且计算成本低。然而,当动态环境呈现多模态或非高斯分布时,仅承诺并优化单一的 MAP 或均值轨迹会使得系统忽略其他可能的发展路径,尤其是那些发生概率较低但可能带来高昂代价的结果。
- 可能产生物理上无效的状态:如果在多模态的分支未来中强行使用单峰假设(或均值预测),模型可能会将截然不同的模态进行平均,从而导致信念变得模糊或错误。举例来说,“向左走”和“向右走”两种模态的平均结果,可能会是一个物理上完全无效的“撞墙”状态。
- 基于采样的分布规划(Sampling-based planning)是必不可少的替代方案:在多模态动态、部分可观测或对风险敏感的场景中,保留完整的预测不确定性轮廓对于鲁棒控制至关重要。此时,不应依赖单一代表性轨迹,而应使用蒙特卡洛采样(Monte Carlo rollouts),从预测分布中提取多个样本来模拟并评估各种可能的未来轨迹。这种方法能够自然地支持鲁棒和风险敏感的规划,从而根据不同样本的聚合结果做出更安全的决策。