0
0 0
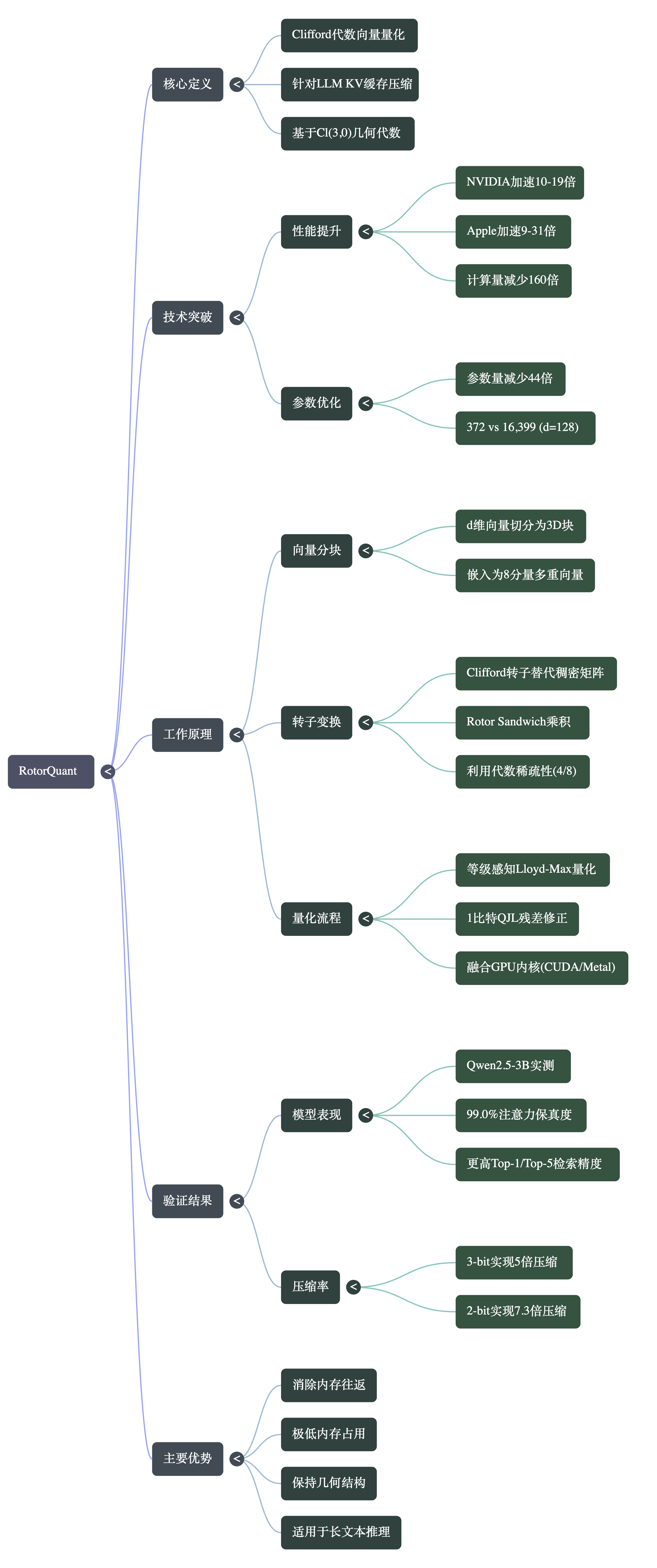
0RotorQuant 是一种针对大语言模型 KV 缓存压缩的新型向量量化技术,旨在优化模型在处理长文本时的内存瓶颈。该方法通过引入 Clifford 代数中的旋转因子,替代了传统 TurboQuant 中高成本的密集矩阵旋转。这种几何代数方法将高维向量拆分为多个三维小组进行局部旋转,极大地利用了代数稀疏性。实验表明,该技术在保持高精度注意力忠实度的同时,参数量减少了 44 倍。此外,通过定制化的 CUDA 和 Metal 融合算子,其处理速度在 NVIDIA 和苹果芯片上分别实现了高达 19 倍和 31 倍的提升。这一突破为现代 AI 推理提供了一种参数更少、计算更快的几何优化方案。
简述 RotorQuant 如何通过几何代数提升 LLM 推理效率。
RotorQuant 通过将几何代数(具体为 $Cl(3,0)$ 空间的 Clifford 旋量/Rotors)引入大语言模型(LLM)的 KV Cache 压缩中,极大地提升了推理效率。其核心优化机制如下:
1. 向量分块与局部旋转替代全局矩阵乘法现有的 TurboQuant 方法通过一个巨大的 $d \times d$ 密集正交矩阵来旋转和解相关(Decorrelate)整个向量,这不仅参数量巨大,且计算成本极高(在向量维度 $d=128$ 时,每个向量需要约 16,384 次乘加运算)。RotorQuant 摒弃了这种“大锤”式的全局处理,将高维向量切分为多个 3 维的分组,并为每个 3 维组独立分配一个廉价的 Clifford 旋量来进行局部旋转。
2. 利用代数稀疏性大幅削减参数与计算量在 $Cl(3,0)$ 几何代数中,一个旋量仅具有 4 个非零分量(1 个标量和 3 个二重向量)。RotorQuant 利用极其稀疏的“三明治积”($v' = R v \tilde{R}$)来实现完美的三维空间旋转。这种高度的代数稀疏性使计算量暴降;同时,在 $d=128$ 时,所需参数量从原方法的 16,399 个减少到了仅 372 个,实现了 44 倍的参数缩减。
3. 全流水线 GPU 算子融合 (Fused Kernels)RotorQuant 将整个数据处理流程(向量嵌入 $\rightarrow$ 旋量三明治积 $\rightarrow$ 区分多重向量秩的量化 $\rightarrow$ 逆三明治积 $\rightarrow$ 提取)全部融合到了一个单一的 GPU 算子中(支持 NVIDIA CUDA 和 Apple Metal)。这种设计避免了中间张量在显存层级之间的来回读写,确保所有计算都能在寄存器中高效完成,消除了显存带宽瓶颈。
4. 结合残差校正保持模型保真度虽然局部 3 维旋转在合成测试中的均方误差(MSE)略高,但 RotorQuant 结合了 QJL(1-bit 量化残差校正)技术,能够完美弥补这一差距。在真实的 LLM 模型(如 Qwen2.5-3B)推理验证中,它不仅匹配了原始方法的注意力保真度(余弦相似度 0.990),甚至在长上下文检索中表现更好,因为几何代数更好地保留了真实注意力的方向性结构。
总结借助 Clifford 旋量的高效稀疏表示以及底层算子融合,RotorQuant 在实现 5 倍或更高 KV Cache 压缩率的同时,推理速度在 NVIDIA GPU 上提升了 10 至 19 倍,在 Apple 芯片上提升了 9 至 31 倍,成功打破了 LLM 长上下文生成时的显存与计算瓶颈。
比较 RotorQuant 与 TurboQuant 在参数量和速度上的差异。
RotorQuant 在参数量和推理速度上均显著优于 TurboQuant,具体差异如下:
参数量差异
- 大幅减少的参数需求:在典型的注意力头维度 $d=128$ 时,RotorQuant 仅需 372 个参数,比 TurboQuant 减少了 44倍。
- 核心原理:TurboQuant 依赖一个全局的 $d \times d$ 密集随机正交旋转矩阵,在 $d=128$ 时需要 16,384(或 16,399)个参数,其参数复杂度为 $O(d^2)$。而 RotorQuant 采用了更精细的几何操作,将向量划分为多个 3 维小块,并使用独立的 Clifford 旋量(Rotor)对每个小块进行局部旋转。由于在 $Cl(3,0)$ 代数中,每个旋量仅包含 4 个非零分量(即每个小块只需 4 个参数),从而实现了参数量的锐减。
- 高维扩展性:随着向量维度增加,RotorQuant 的参数优势愈发明显。例如在 $d=4096$ 时,TurboQuant 的参数量高达约 1670 万,而 RotorQuant 仅需 5,478 个参数(减少了约 3063倍)。
速度差异
- 显著的整体提速:由于底层的深度优化,RotorQuant 在 NVIDIA GPU (CUDA) 上比 TurboQuant 快 10-19倍,在 Apple Silicon (Metal) 上快 9-31倍。
- 计算操作数(FMAs)骤降:处理 $d=128$ 的单个向量时,TurboQuant 的矩阵乘法需要执行 16,384 次乘加运算(FMAs)。RotorQuant 利用旋量的代数稀疏性(8 个多重向量分量中有 4 个为零),通过三明治积(Sandwich Product)完成等效旋转,每处理一个向量仅需约 100 次 FMAs,运算量减少了 160 倍。
- 融合算子(Fused Kernel)消除访存瓶颈:TurboQuant 依赖传统的矩阵乘法库(如 cuBLAS 或 Accelerate)进行计算。而 RotorQuant 将完整的处理流水线(嵌入 → 旋量三明治积 → 离散量化 → 逆三明治积 → 提取)全部整合在一个独立的 GPU 算子(Kernel)中。这种设计使得所有的计算都在线程寄存器内完成,避免了中间数据在各级缓存和内存间的来回搬运,极大提升了吞吐量。
RotorQuant 在真实模型 Qwen2.5 中的精度表现如何?
在真实模型 Qwen2.5(具体为 Qwen2.5-3B-Instruct)的测试中,RotorQuant 展现出了极高的精度表现。
具体精度表现可以归纳为以下几个方面:
- 极高的注意力保真度(余弦相似度):RotorQuant 能够保持约 99.0% 的余弦相似度。例如,在 2K 上下文和 3-bit 量化下,RotorQuant 的余弦相似度为 0.9903(对比 TurboQuant 为 0.9906);在 4K 上下文和 3-bit 量化下为 0.9870。
- 在长上下文中更优的检索准确率:在 4K 上下文长度下,RotorQuant 在 Top-1 和 Top-5 准确率上超越了 TurboQuant。在 4K 上下文、3-bit 量化时,RotorQuant 的 Top-5 准确率为 93.8%(显著高于 TurboQuant 的 87.5%)。
在 4K 上下文、4-bit 量化时,RotorQuant 的 Top-1 准确率为 81.2%(高于 TurboQuant 的 75.0%)。 - 完美的“大海捞针”测试(Needle-in-Haystack):无论是在 2-bit、3-bit 还是 4-bit 的量化位宽下,也无论上下文长度是 512、2048 还是 8192,RotorQuant 都实现了 9/9 的完美匹配,每次都能正确识别出最接近的向量。
深层原因与洞察:如果在纯合成数据上测试,RotorQuant 的均方误差(MSE)其实略高于 TurboQuant。然而,这种精度差距在真实模型中完全消失了,主要得益于两点:
- 真实数据的几何结构:真实的 KV Cache 向量并不是随机分布的,而是存在于由模型注意力模式塑造的低秩流形(low-rank manifolds)上。RotorQuant 采用的 Clifford 旋量去相关方法(Clifford rotor decorrelation)能够更好地保留真实注意力头的方向性结构。
- QJL 残差校正:通过结合 QJL(1-bit Quantized Johnson-Lindenstrauss)残差校正,RotorQuant 弥补了量化带来的误差,确保了内积估算的无偏性和高精度。
RotorQuant 相比 TurboQuant 为什么参数量更少?
RotorQuant 相比 TurboQuant 能够大幅减少参数量,核心原因在于它放弃了全局的密集矩阵,转而采用向量分块结合 Clifford 旋量(Rotors)的极其稀疏的代数表示。具体原因如下:
- TurboQuant 采用全局密集矩阵(参数量呈 $O(d^2)$ 增长):TurboQuant 通过一个巨大的 $d \times d$ 随机正交旋转矩阵来对整个向量空间进行全局旋转解相关。这种方式的参数量与向量维度 $d$ 的平方成正比。在典型的注意力头维度 $d=128$ 时,仅这一个矩阵就需要 $128 \times 128 = 16,384$ 个参数。
- RotorQuant 采用“向量分块 + 局部旋转”策略:RotorQuant 没有使用全局大矩阵,而是将高维的 $d$ 维向量切分为多个 3 维的小块(groups of 3 dimensions),并对每个 3 维块独立应用一个 Clifford 旋量进行局部旋转。
- Clifford 旋量极高的代数稀疏性:在 $Cl(3,0)$ 几何代数空间中,一个用于三维旋转的旋量(Rotor)非常紧凑,仅包含 4 个非零分量(1 个标量和 3 个二重向量)。这意味着,定义一个局部 3 维空间的完美旋转只需要约 4 个参数。
最终的参数对比结果:通过用局部稀疏的旋量替代全局密集的矩阵,RotorQuant 实现了参数断崖式的下降:
- 在 $d=128$ 时,TurboQuant 需要 16,399 个参数,而 RotorQuant 仅需 372 个参数,实现了 44 倍的缩减。
- 在高维扩展时优势更加巨大。
为什么 RotorQuant 在长上下文中表现更好?
RotorQuant 在长上下文中表现更好,核心原因在于其采用的几何代数方法更好地保留了真实注意力的方向性结构(directional structure)。
具体原因和数据表现如下:
1. 契合真实 KV Cache 的几何分布真实的 KV Cache 向量并不是随机分布的单位向量,而是存在于由大语言模型注意力模式塑造的低秩流形(low-rank manifolds)上。RotorQuant 采用的 Clifford 旋量去相关(decorrelation)方法,在进行旋转时不仅保留了向量的范数和内积,还能保留外积和多重向量的秩(grades)。这种能够保留完整代数结构的特性,使其在处理真实数据时具有天然优势。
2. QJL 残差校正抹平了合成误差如果仅在随机合成数据上测试,RotorQuant 的均方误差(MSE)其实略高于 TurboQuant 的全局矩阵旋转。
3. 长上下文中的卓越数据表现得益于上述原理,RotorQuant 在真实模型(如 Qwen2.5-3B-Instruct)的长上下文检索中实现了对原有方法的超越:
- 4K 上下文检索精度更高:在 4K 的上下文长度下,RotorQuant 实现了更高的 Top-1 和 Top-5 检索准确率。例如,在 3-bit 量化时,其 Top-5 准确率达到了 93.8%(对比 TurboQuant 为 87.5%);在 4-bit 量化时,其 Top-1 准确率为 81.2%(对比 TurboQuant 为 75.0%)。
- 完美的超长上下文匹配:在高达 8192(8K)长度的“大海捞针”(Needle-in-Haystack)测试中,无论是在 2-bit、3-bit 还是 4-bit 的量化位宽下,RotorQuant 都实现了 9/9 的完美精确匹配,每次都能准确无误地识别出最接近的向量。