


 3
3 0
0当全球数十亿用户访问 Google 搜索、Gmail、YouTube 时,他们的请求是如何被精准、快速、无感地分发到成千上万台后端服务器的?答案不是昂贵的硬件负载均衡器,而是一款运行在普通 Linux 服务器上的软件系统——Maglev。
本期内容将深入拆解 Google 自 2008 年起自研的分布式负载均衡系统。你将看到,Maglev 如何通过内核旁路技术单机处理千万级数据包,如何用独创的一致性哈希算法实现比传统方案更均匀的流量分布,以及如何利用 ECMP 和连接跟踪在动态扩缩容时保证用户连接不中断。更重要的是,这套系统展示了软件定义基础设施的威力:用商用硬件+精妙算法,取代昂贵、封闭、难以扩展的硬件设备。对于任何关注大规模网络架构、云原生基础设施的工程师而言,Maglev 的设计思想都堪称经典。
参考论文:Maglev: A Fast and Reliable Software Network Load Balancer
Maglev 是一项早在 2008 年就已成熟并投入使用的技术,但 Google 直到 2016 年 才通过 NSDI 会议正式发表论文,向公众披露其设计细节和多年来的运维经验。这种“先在大规模生产中验证,多年后再发表论文”的做法在大型科技公司中非常常见。



以下为主要内容的图文介绍:



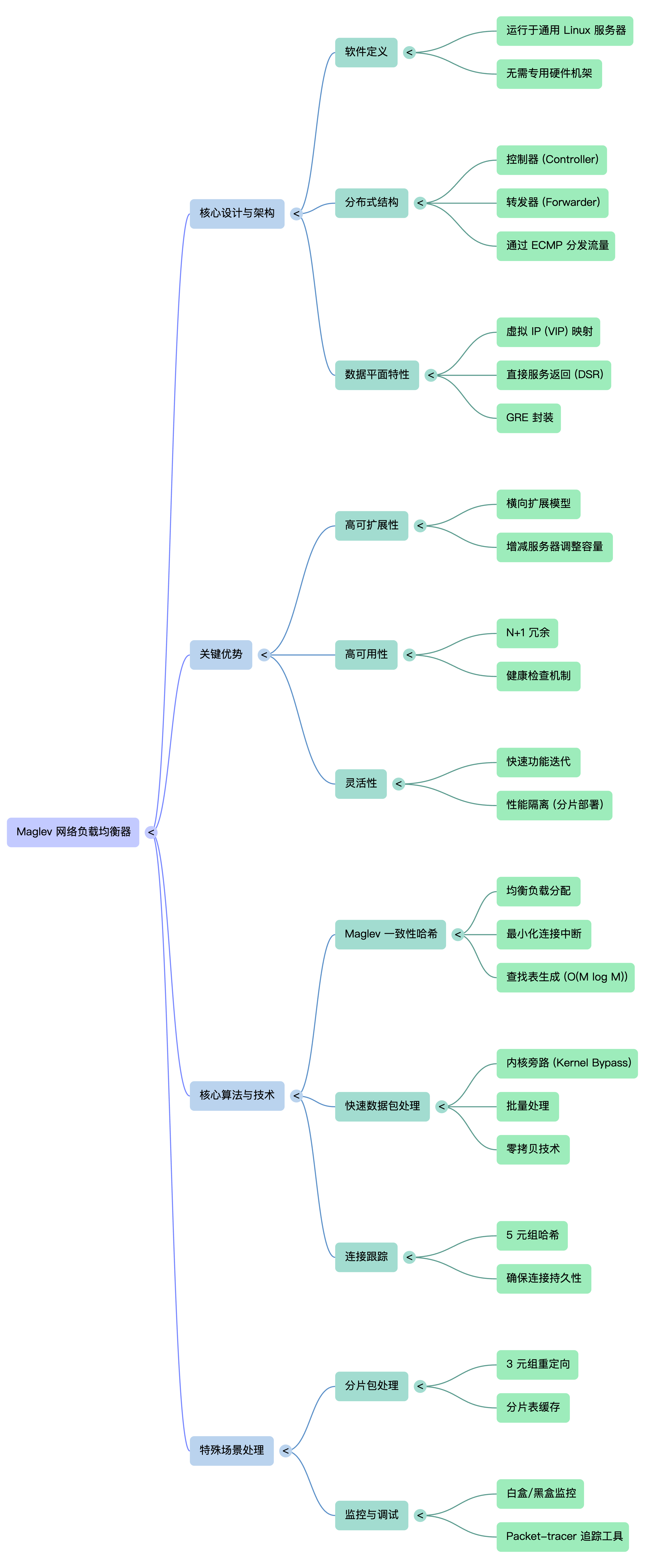
⚙️ 第一章:为什么 Google 要自己造“轮子”?
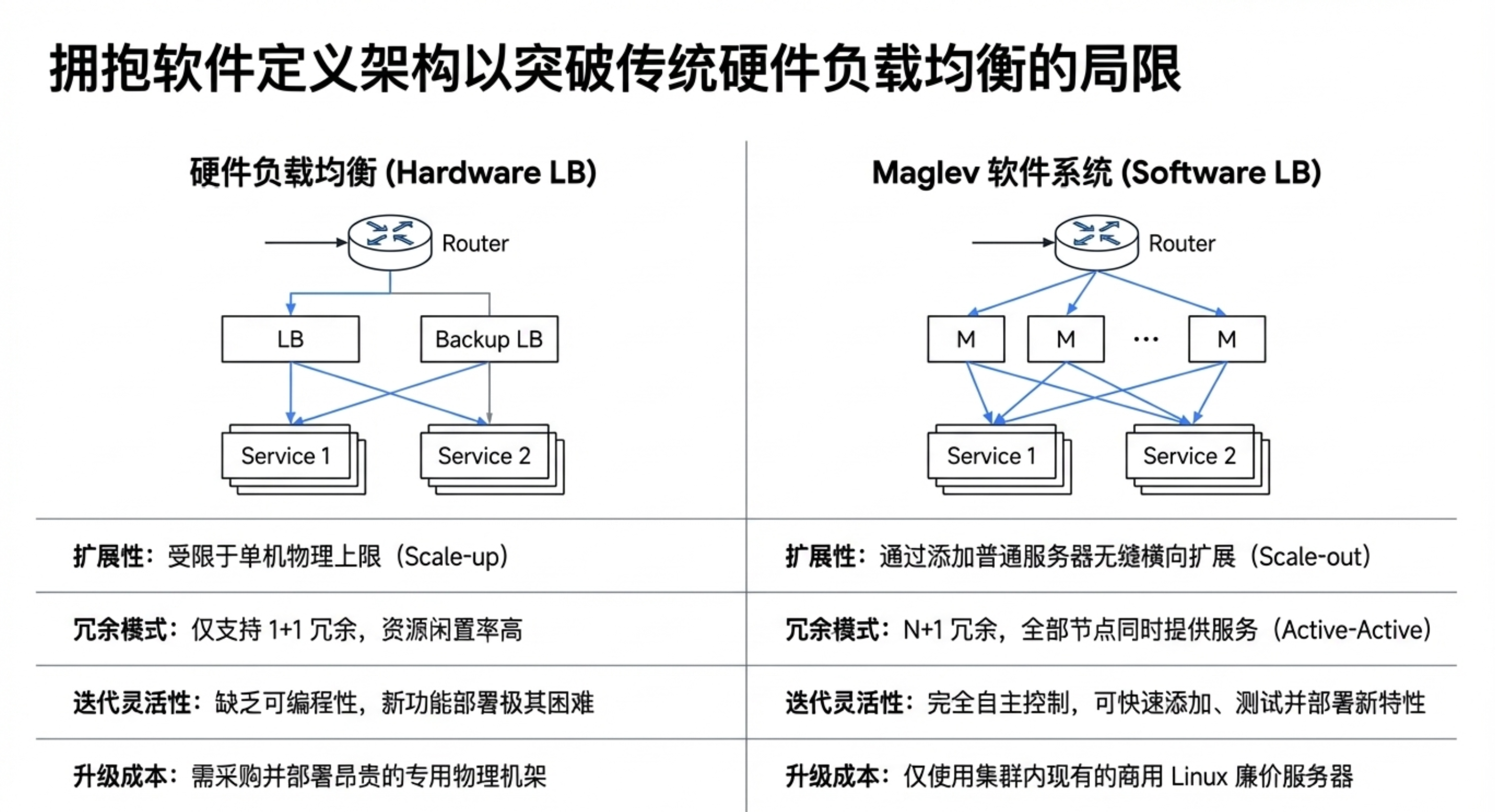
在 Maglev 之前,Google 曾依赖传统的硬件负载均衡器,但很快撞上了天花板:
- 容量瓶颈:硬件设备处理能力固定,流量增长只能“换更大的盒子”,无法水平扩展。
- 可用性差:通常采用1+1主备冗余,故障切换不灵活,资源利用率低。
- 成本高昂且封闭:专有硬件价格昂贵,功能迭代慢,无法快速响应内部需求。
Google 需要一套可水平扩展、高可用、软件定义的负载均衡系统,Maglev 应运而生。
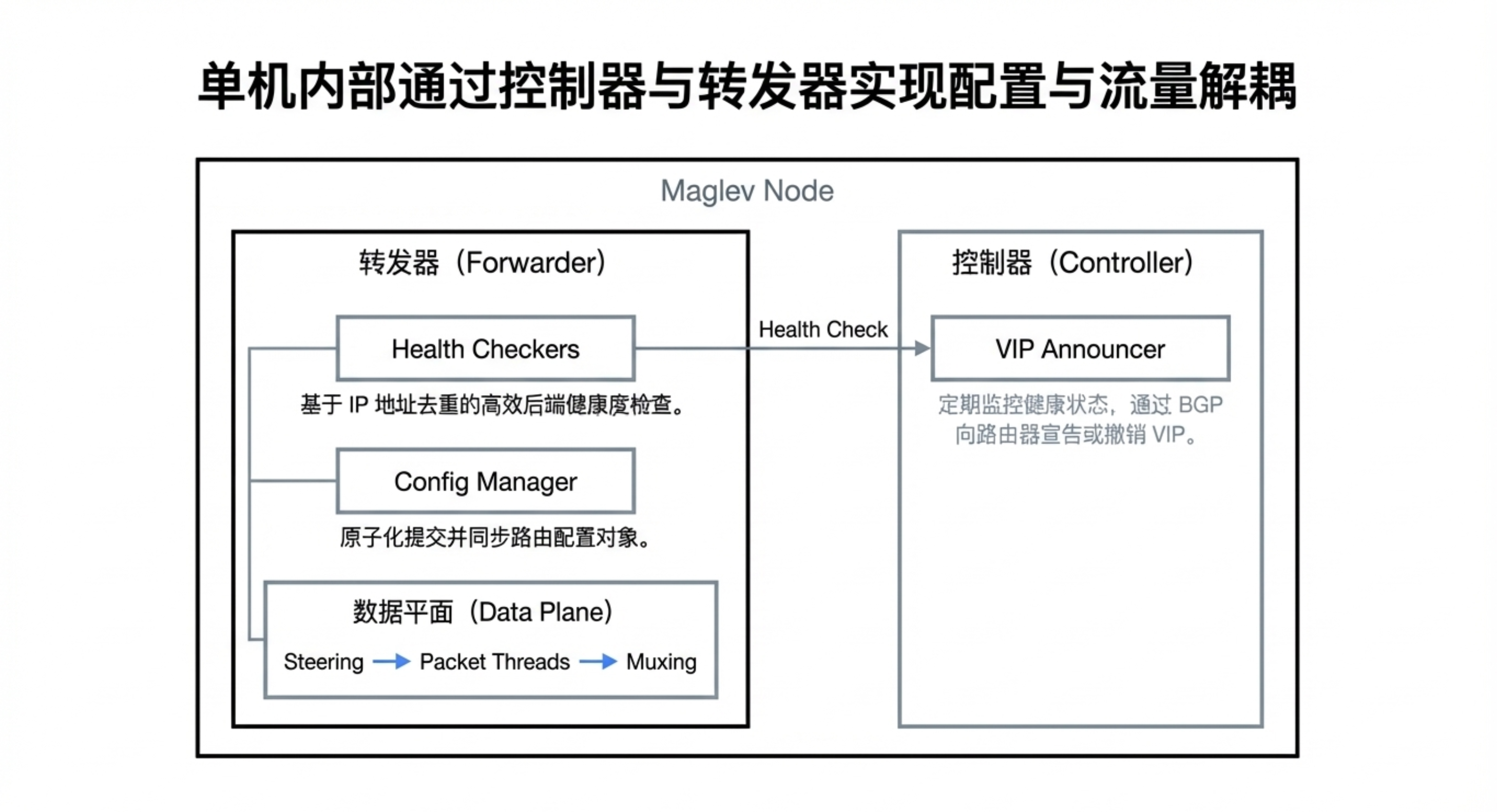
🧱 第二章:核心架构——控制器与转发器
Maglev 由两个主要组件构成:
- 控制器:定期检查转发器健康状况,通过 BGP 协议向路由器宣告或撤回虚拟 IP(VIP),控制流量入口。
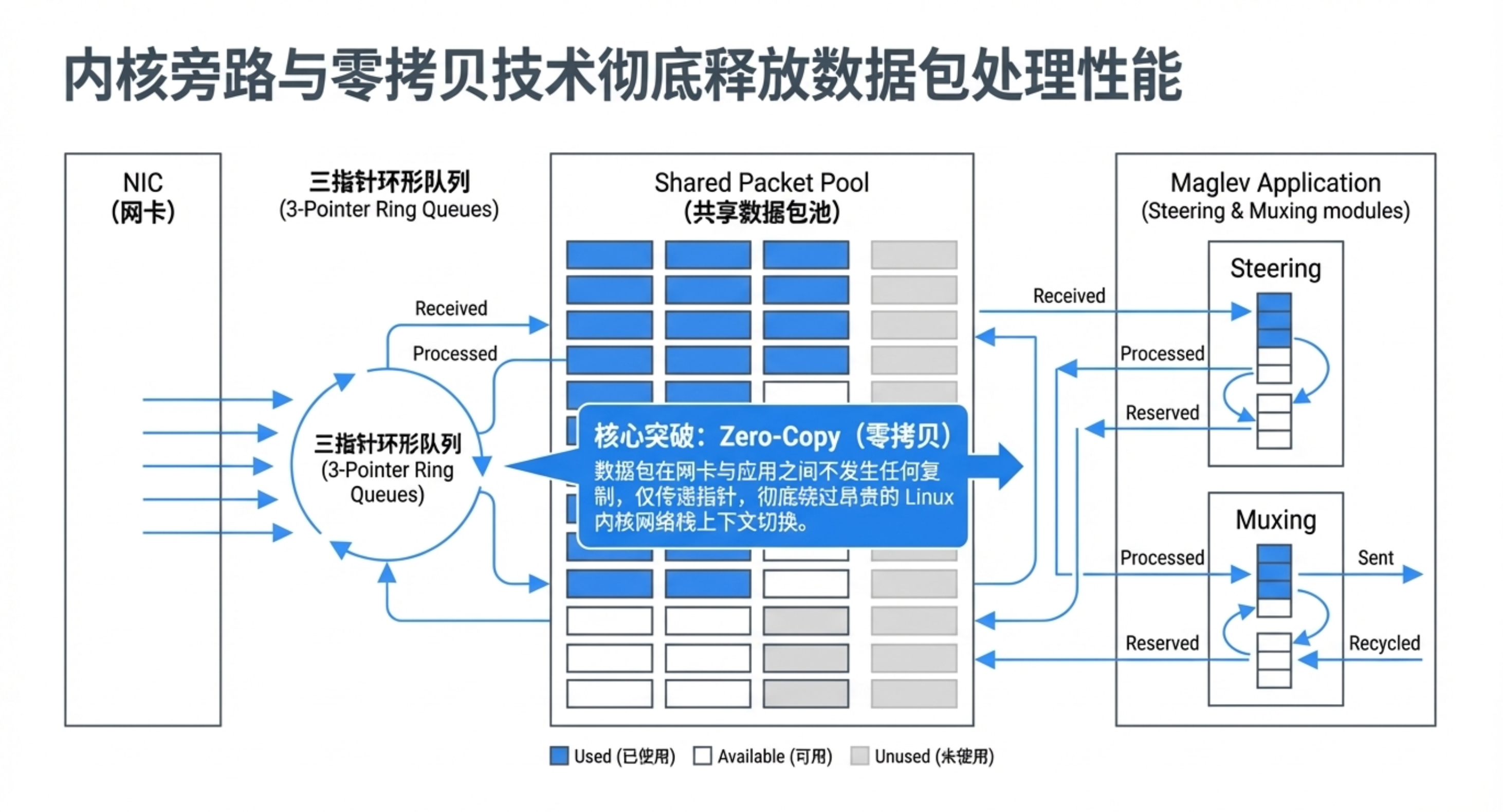
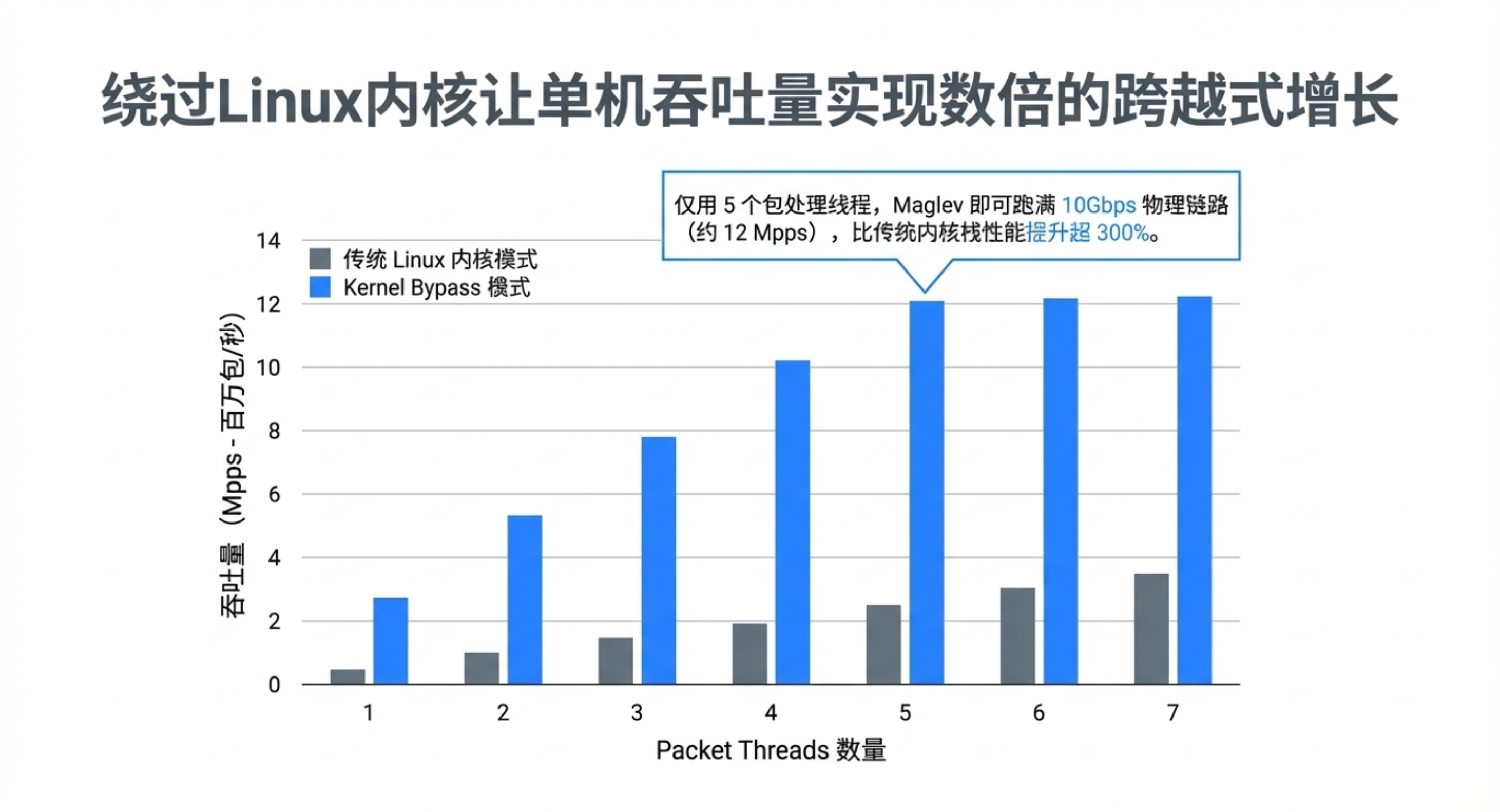
- 转发器:运行在每台普通 Linux 服务器上的数据平面,负责实际处理数据包。关键技术:采用内核旁路(Kernel Bypass),直接在用户空间与网卡交互,绕过 Linux 内核网络栈,极大提升吞吐量。
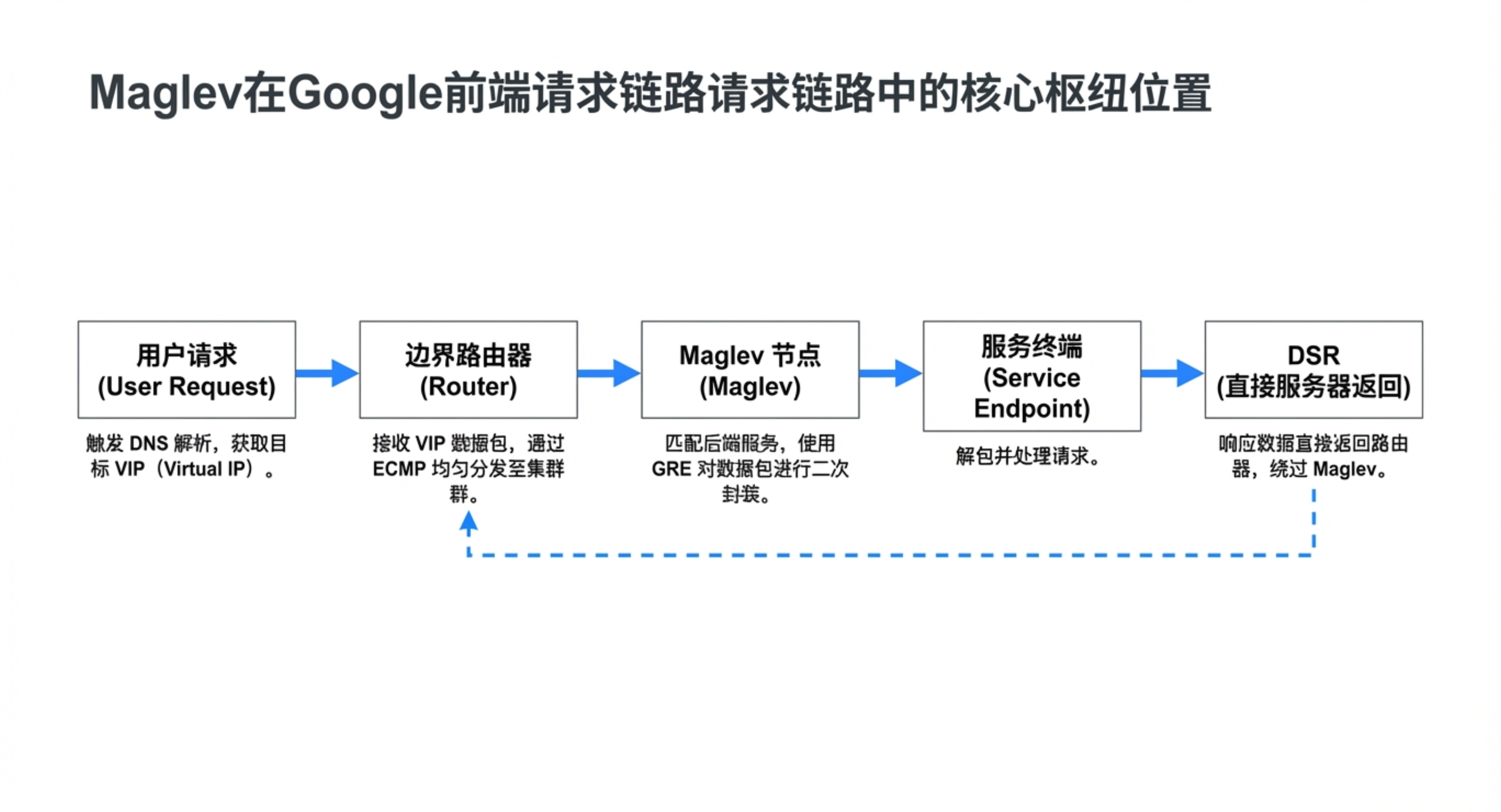
🔄 第三章:流量分发——ECMP + Maglev哈希 + 连接跟踪
- 入口分散:上游路由器通过等价多路径(ECMP)将流量均匀散列到集群中的所有Maglev转发器,实现水平扩展。
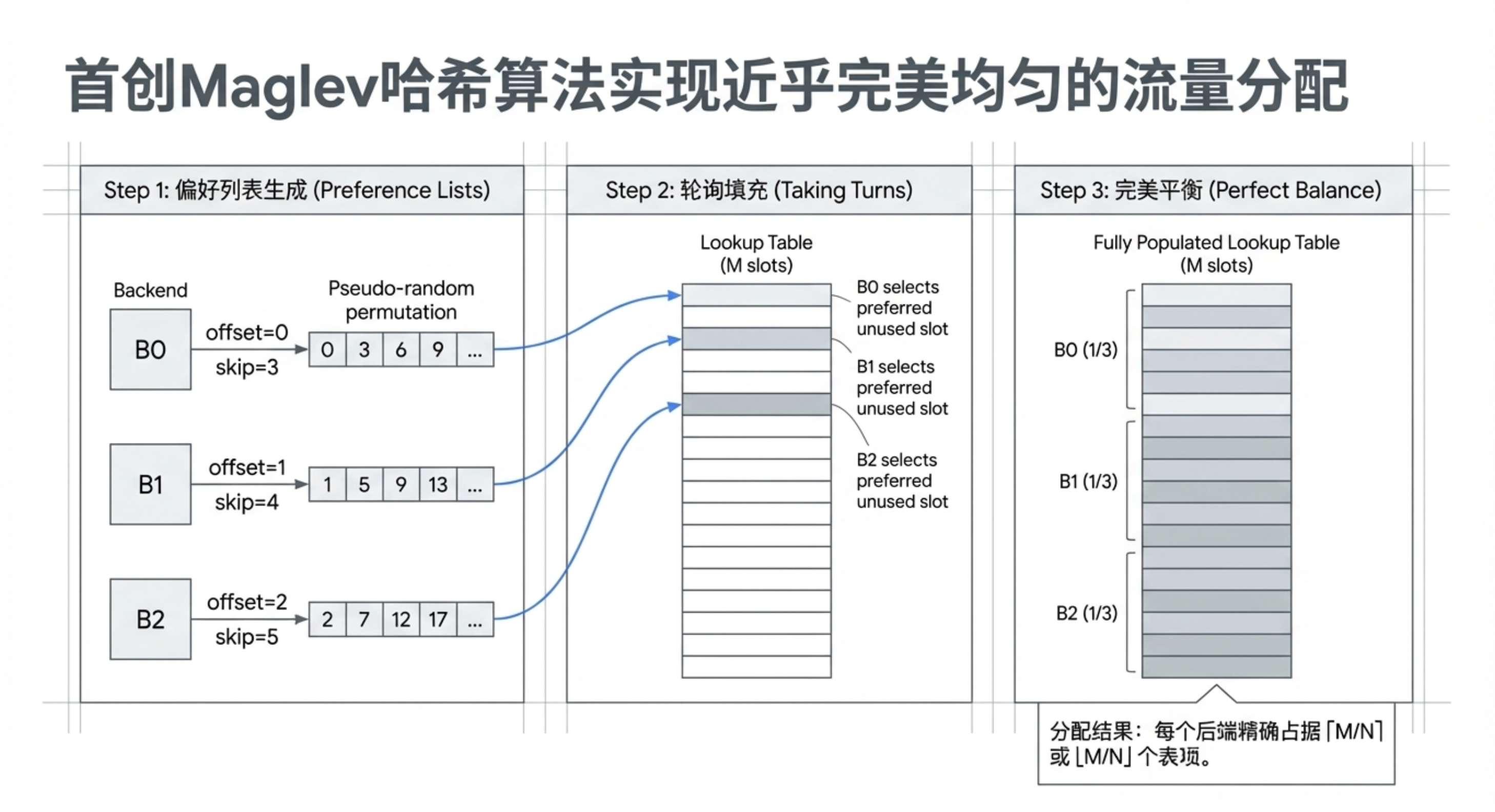
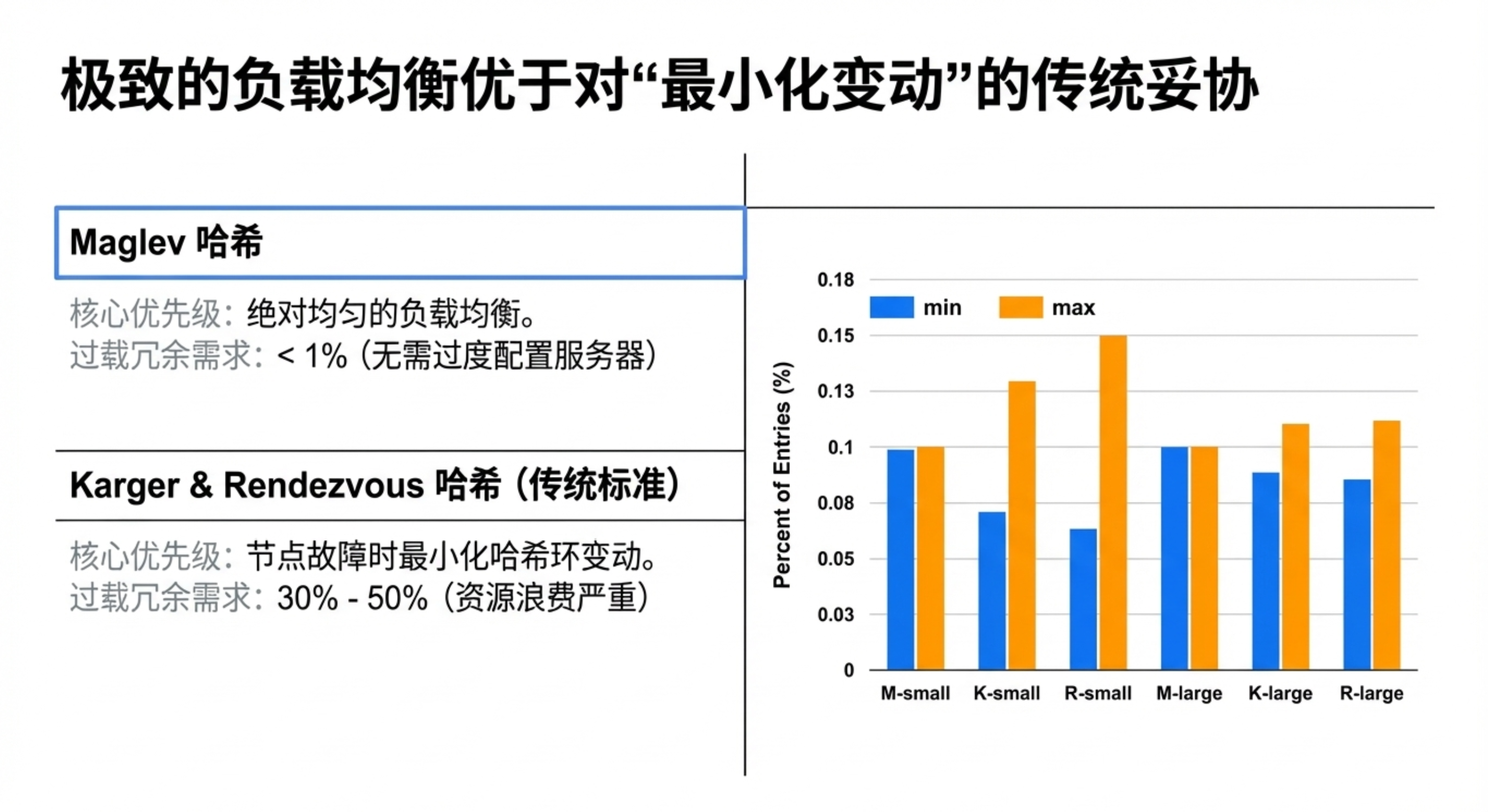
- Maglev 一致性哈希:这是论文的核心贡献。与传统一致性哈希(如 Karger 哈希)不同,Maglev 哈希优先保证负载的极致均匀性。通过为每个后端生成偏好表并轮询填充,最终每个后端分配的哈希槽位差异小于1%,极大避免了热点。
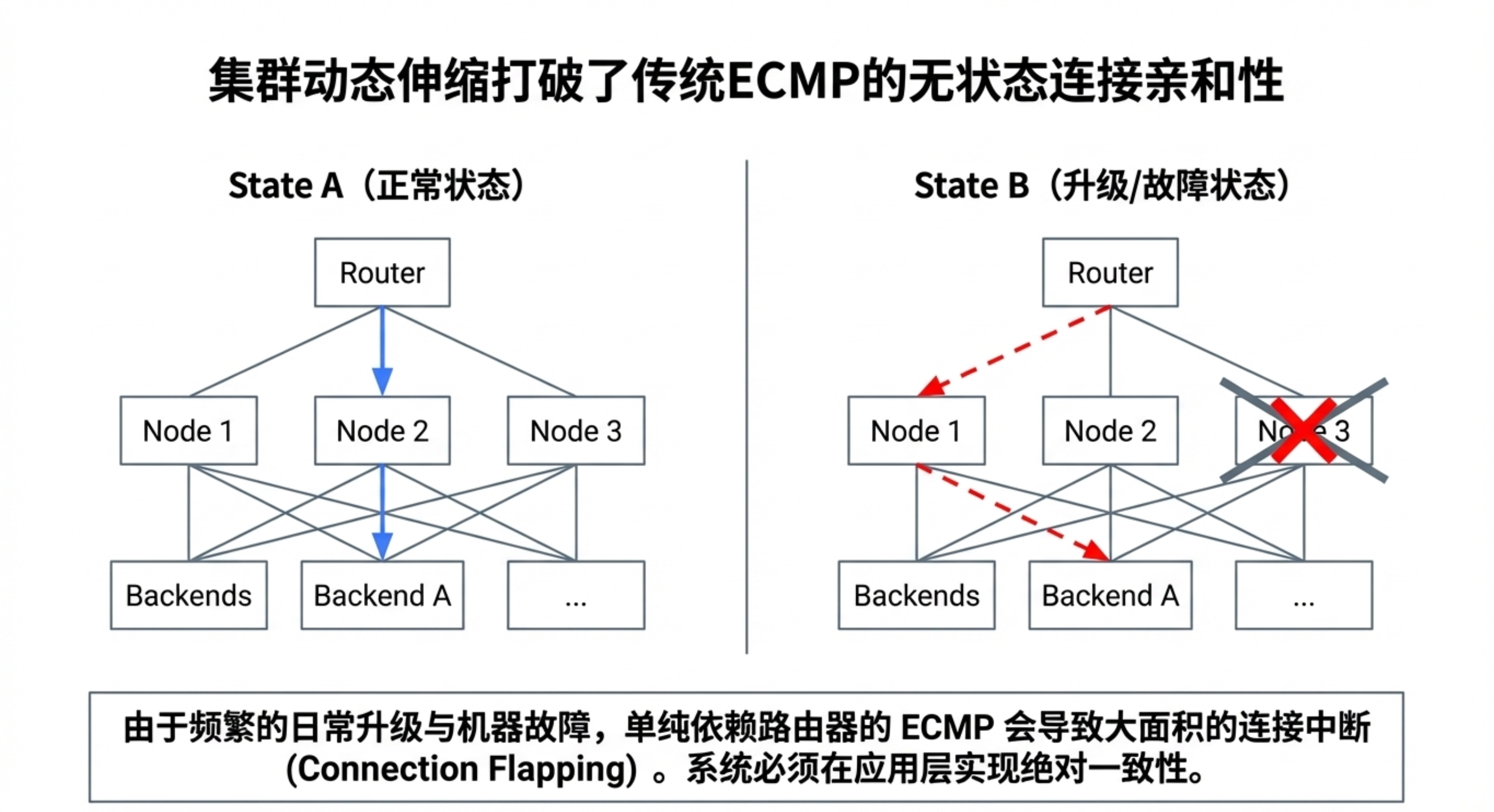
- 连接跟踪:转发器内部维护一个连接表,记录每个五元组(源IP、源端口、目的IP、目的端口、协议)被分配的后端。当后端集合变化(如服务器宕机或扩容)时,属于同一 TCP 连接的数据包仍能被正确路由到同一后端,保证连接不中断。
🚀 第四章:性能表现——接近线速的软件转发
- 单机吞吐:在10Gbps网络下,Maglev 能以线速处理小数据包;使用40Gbps网卡时,吞吐量超过1500万包/秒。
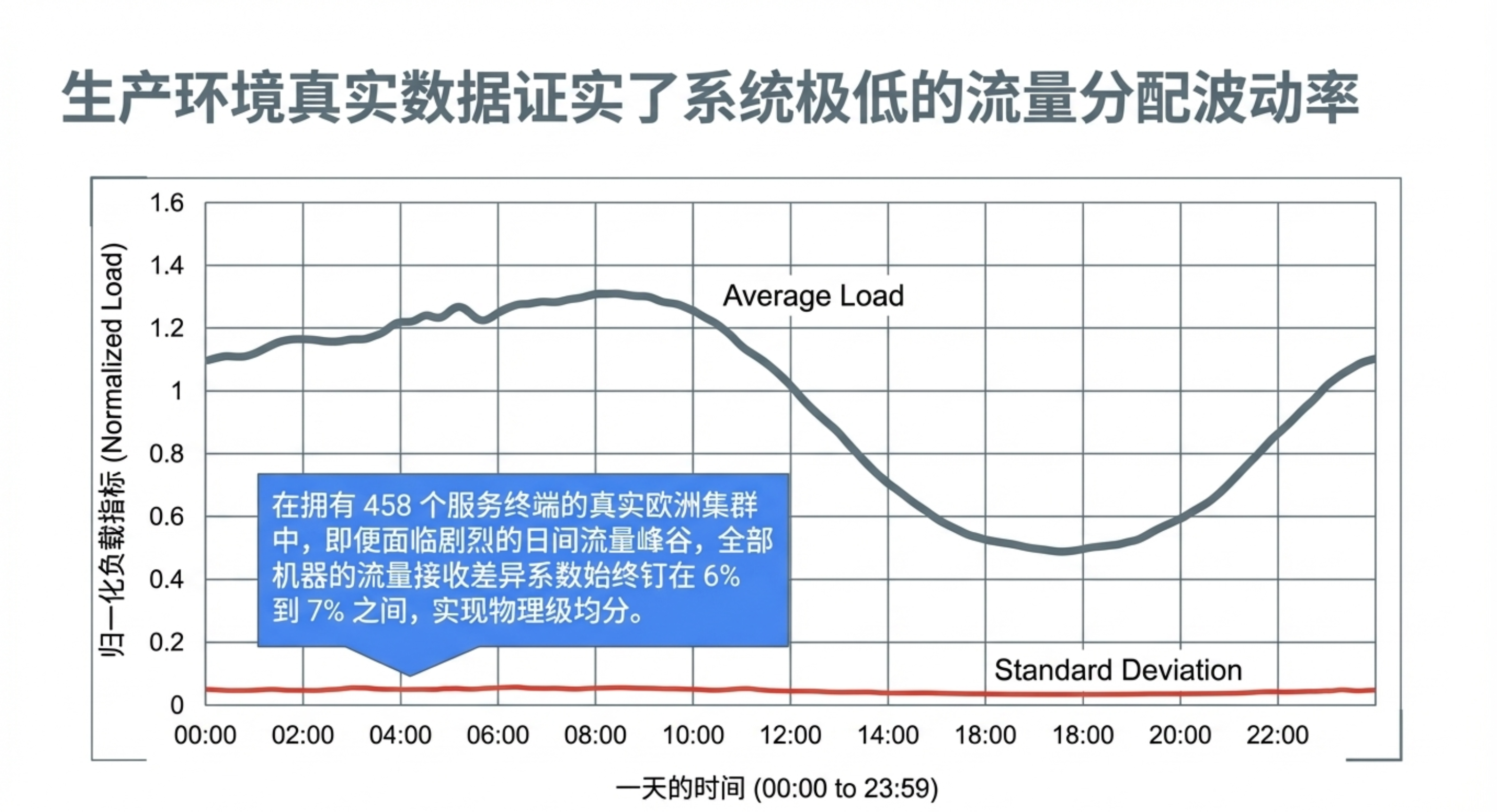
- 均衡效果:在生产集群中,各后端负载的变异系数(CV)通常仅为6%-7%,均衡性极佳。
- 极低延迟:正常负载下,每个数据包的转发处理时间仅约350纳秒。
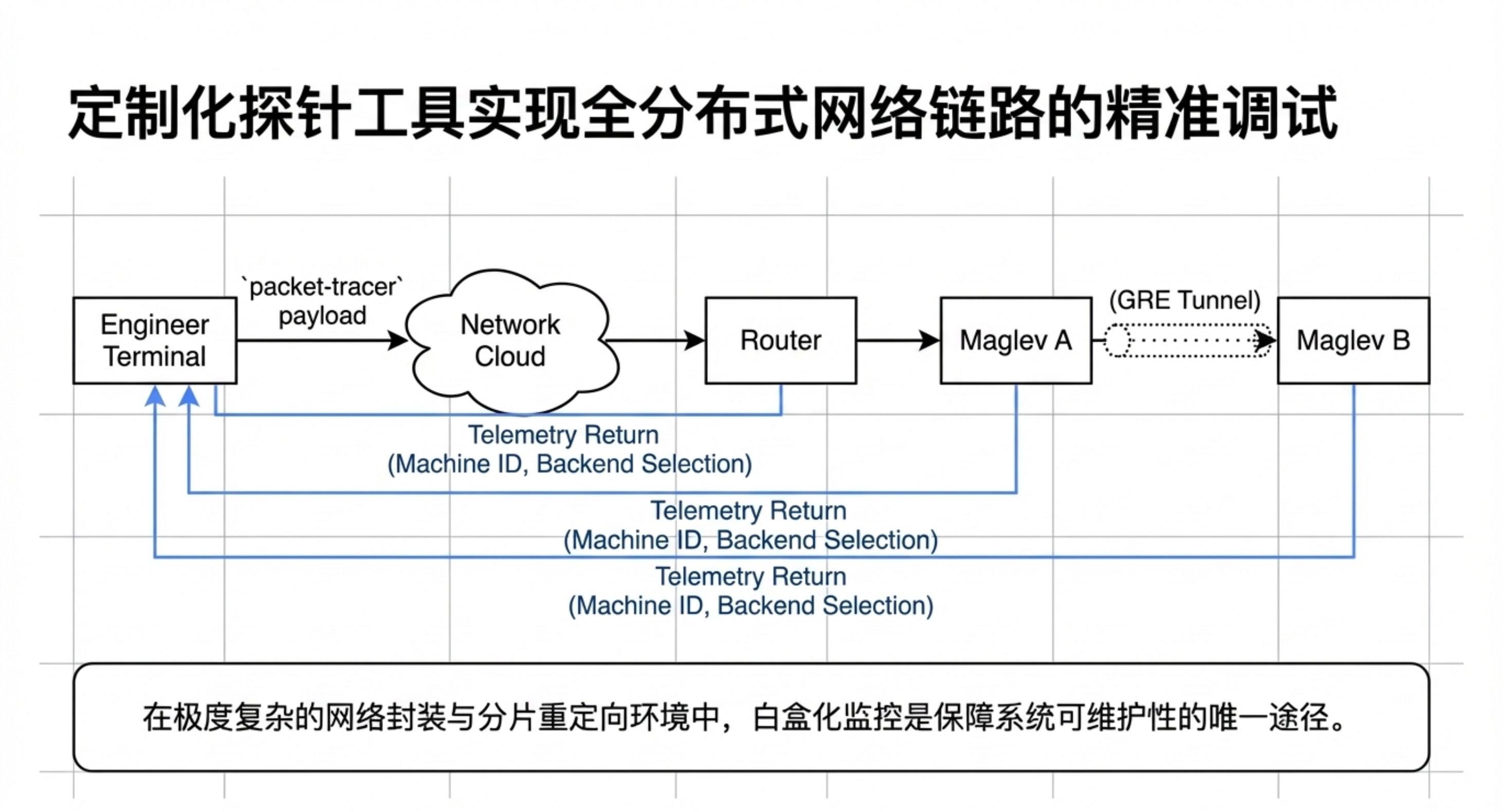
💡 第五章:运维经验与演进
- 从主备到 ECMP 集群:Maglev 最初采用主备模式,后演进为 ECMP 横向扩展,资源利用率大幅提升。
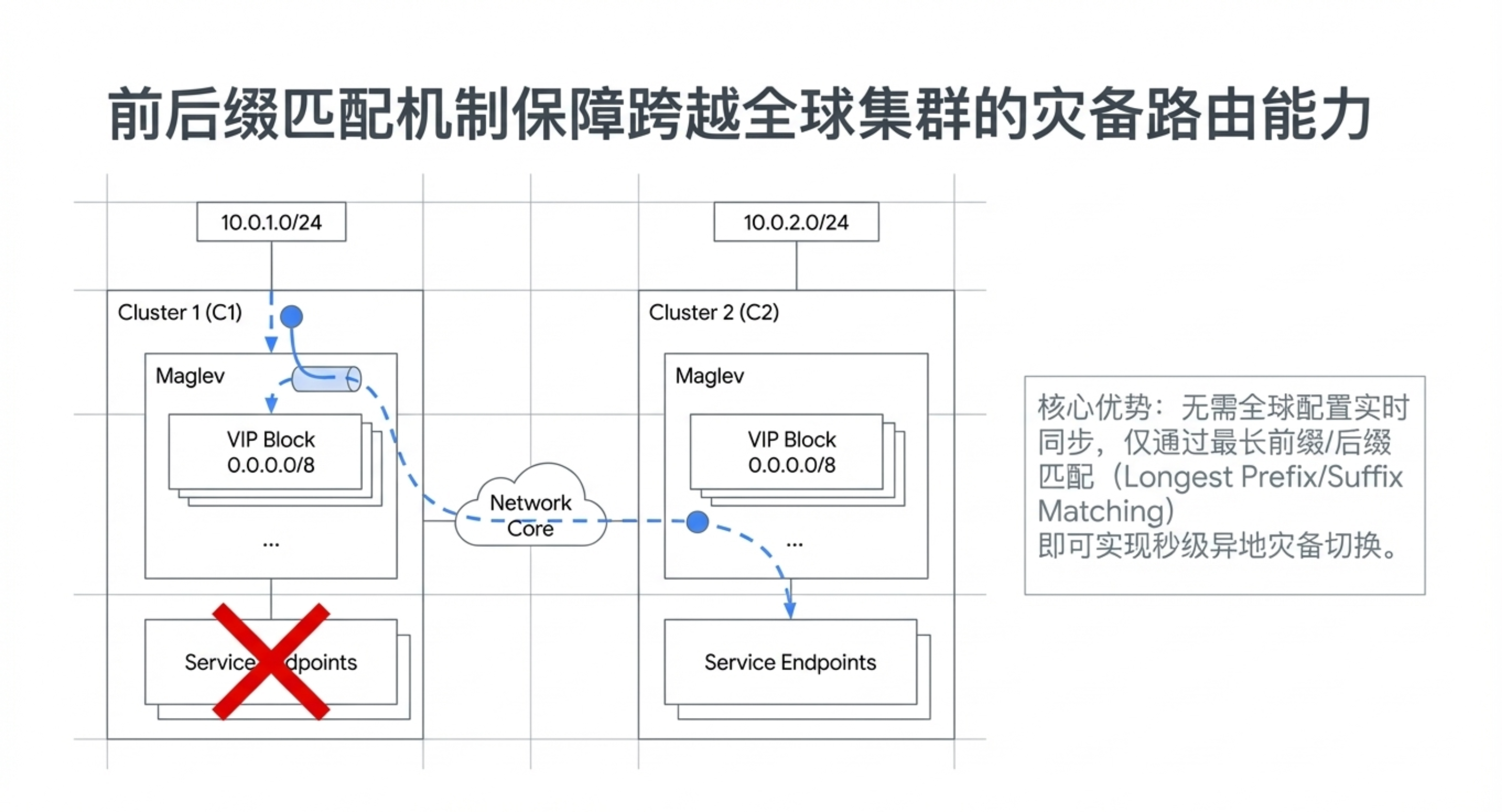
- 灵活的 VIP 匹配:支持基于前缀/后缀的 VIP 匹配,便于紧急情况下跨集群流量重定向。
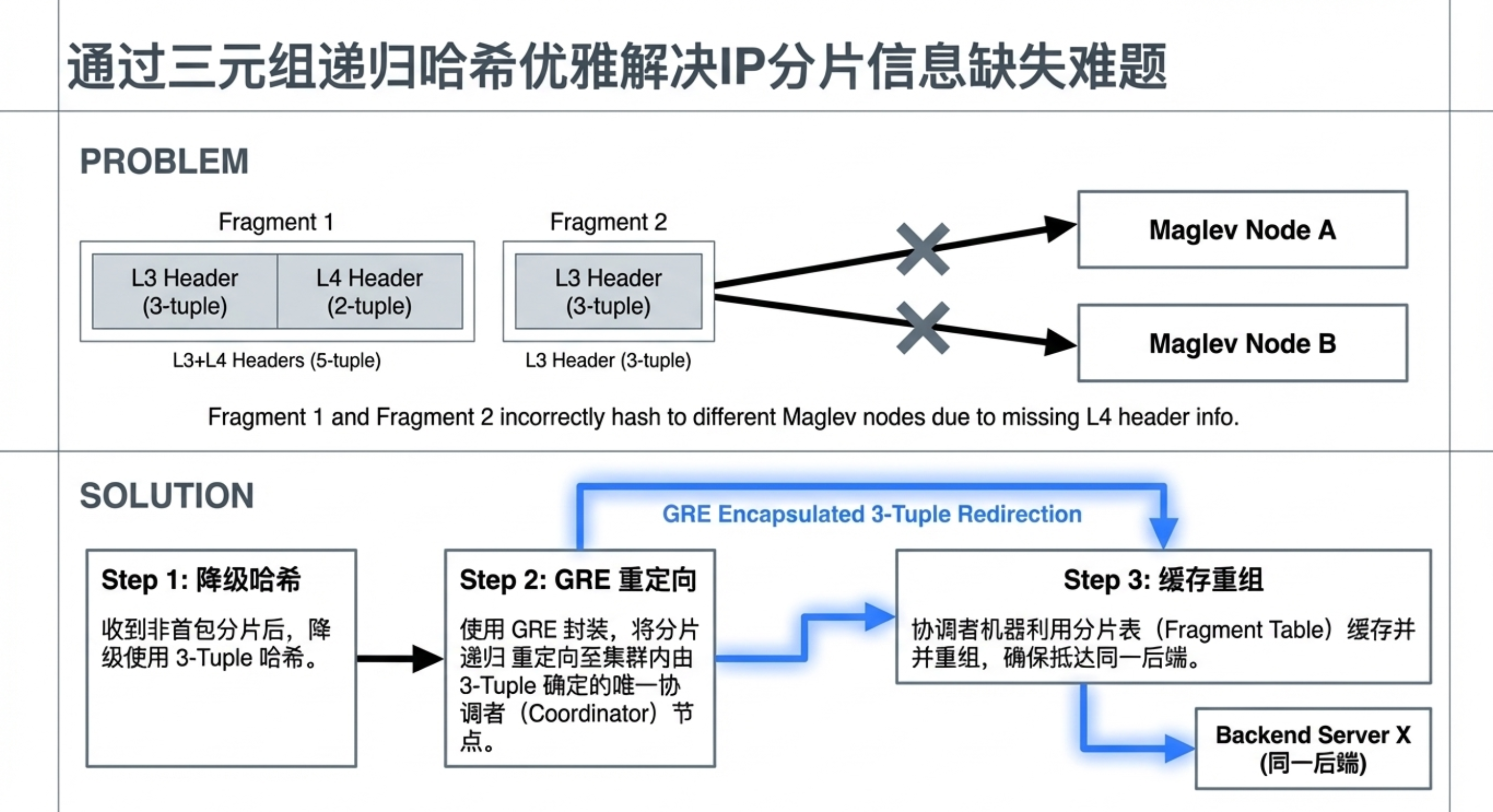
- IP 分片处理:针对分片包,通过二级重定向机制确保同一报文的所有分片由同一台转发器处理。
🧭 第六章:总结与启示
Maglev 证明了:用软件和商用硬件,完全可以构建出超越专用硬件的负载均衡系统。其设计思想——内核旁路、自定义一致性哈希、连接跟踪与 ECMP 的结合——已被广泛应用于现代云基础设施(如 AWS 的 NLB、Google 的 Andromeda 等)。对于任何构建大规模网络服务的人来说,Maglev 都是一份必读的“基础设施设计教科书”
