


 420
420 1
1Andrej Karpathy终于把「AI 时代知识管理」的原型说清楚了,原文《LLM Knowledge Bases》
核心不是 RAG,不是更聪明的搜索,而是让 LLM 成为知识库的唯一维护者——采集、编译、输出、linting、自我修复,全部自动化。
人只负责两件事:投喂原料,和提出好问题。 这中间的 gap,就是他说的 incredible new product。
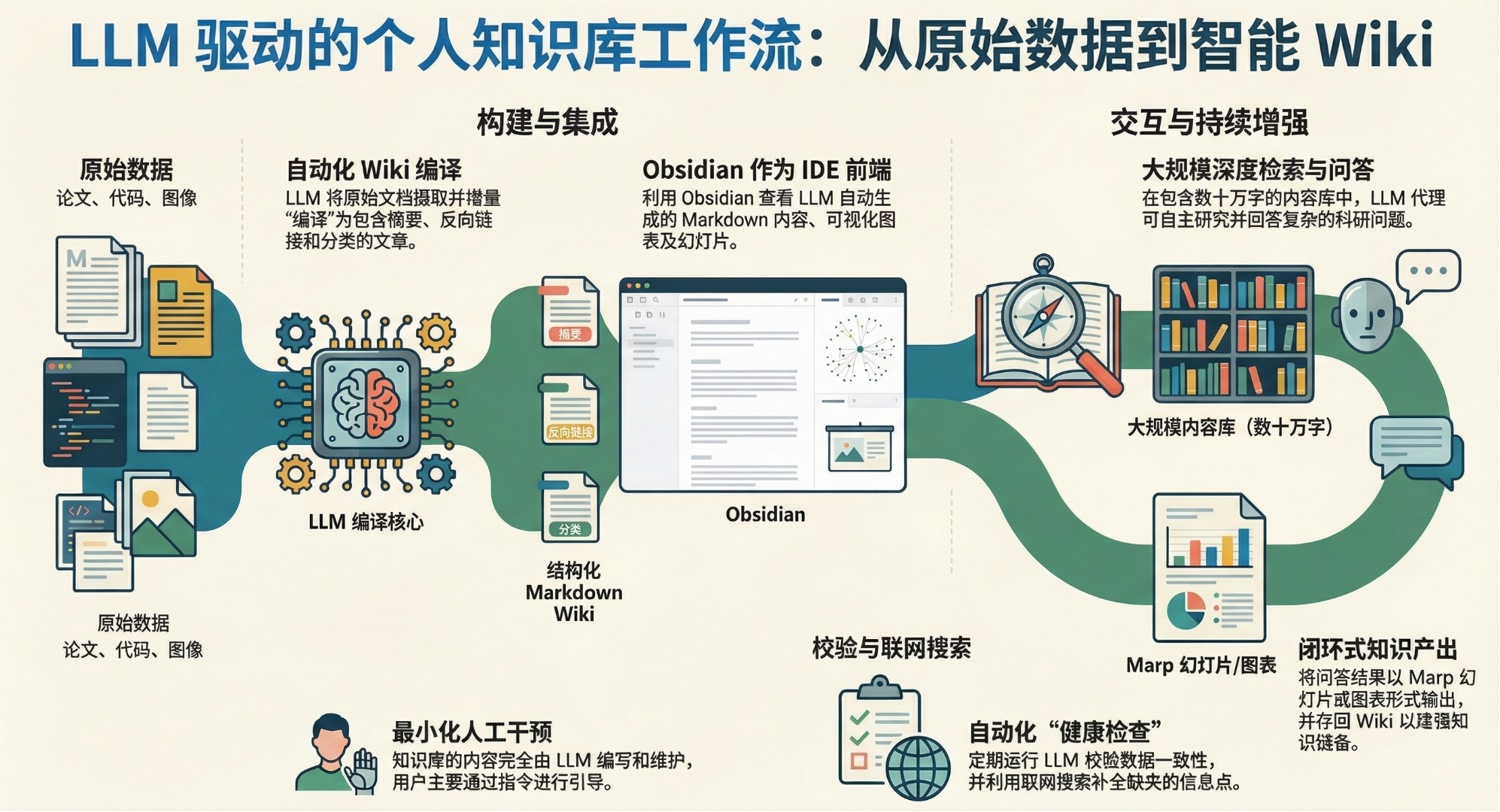
具体复现步骤:
- 第一步:建一个「垃圾场」 raw/
把你所有觉得有价值的东西无脑丢进去:网页、论文、截图、PDF、GitHub repo、播客转录。 不需要分类,不要提前建文件夹。
Andrej Karpathy现在用的是 Obsidian Web Clipper 一键剪藏,连图片一起下载到本地。
- 第二步:让 LLM 当图书管理员
给 LLM 的核心指令只有两句话: 「阅读 raw/ 里的所有文件,生成一个结构化的 wiki。要求:每份原始文件一篇摘要,提取概念并写成独立文章,然后互相做 backlink。」 放心丢过去,最新 LLM 的 wiki 结构能力比人类强。
- 第三步:把 Obsidian 当 IDE 用
不要拿 Obsidian 写笔记,拿它当前端看板。
raw/ 是原始数据,wiki/ 是 LLM 编译后的产物,output/ 是你的查询结果。 三个目录,天然的分层。
- 第四步:开始「对话式」研究
你的知识库大了之后,提问方式要变。
不要问「这篇文章说了什么」,要问:「帮我对比 A 和 B 的差异,所有结论必须引用 wiki 原文并标注来源。」
然后让 LLM 不直接回答你——让它生成一份 .md 报告,或者 Marp 幻灯片,或者 matplotlib 图表。
- 第五步:强制回流(最关键的一步)
任何一次查询的结果,都必须重新存回 wiki。
这样你的每次探索都会沉淀下来,知识库只会越查越厚。
- 第六步:定期让 LLM lint 你的 wiki
给 LLM 的指令:「通读整个 wiki,找出: 1. 互相矛盾的数据 2. 缺失的中间环节 3. 可以写新文章的概念关联」
这是 human 做不到、LLM 很擅长的维护工作。
**📺播客说明**
本播客采用虚拟主持人进行播客翻译的音频制作,因此有可能会有一些地方听起来怪怪的。如想了解更多信息,请关注微信公众号"西经东译"获取AI最新资讯。如有后续想要听的其他外文播客,也欢迎联系微信:mayday2303。

