0
0 0
0突破大模型部署瓶颈:APEX 量化技术如何让 MoE 模型在消费级 GPU 上跑赢 F16
引言:打破“显存焦虑”与“性能损耗”的死循环
在本地部署高性能大模型(LLM)时,开发者长期面临一个残酷的博弈:要么为了保留“模型智商”而忍受巨大的显存压力,要么为了塞进显卡而接受量化带来的精度崩塌。难道“轻量化”与“全精度性能”真的不可兼得?
由 LocalAI 团队开发的 APEX(Adaptive Precision for EXpert Models,专家模型自适应精度) 量化方案彻底打破了这一僵局。作为一种专为混合专家模型(MoE)设计的革命性技术,APEX 并非简单的位宽压缩,而是通过对模型内部拓扑结构的深度解构,实现了在体积缩减一半的同时,性能超越 Q8 甚至 F16 原始权重的壮举。更令开发者兴奋的是,该技术与原版 llama.cpp 完全兼容,无需任何底层代码修改即可开箱即用。
敏感度的架构:层级精度梯度的魔法
APEX 的核心洞见源于对模型层级功能的重新认识:并非所有层都对量化误差同等敏感。
在传统量化中,通常采用统一位宽(如 4-bit),忽略了模型的结构特性。APEX 引入了**层级精度梯度(Layer-wise Precision Gradient)**分配策略:
- 敏感的边缘层(L0-4, L35-39): 这些层负责初始的输入嵌入对齐(Embedding Alignment)以及最终的 Logit 生成。它们是模型的“感官”与“表达”,对精度要求极高。APEX 为这些边缘层分配了高精度(如 Q6_K)。
- 冗余的中间层(L10-29): 中间层执行的是相对冗余的中间处理。APEX 对其应用更激进的压缩(如 Q4_K 或 IQ4_XS),从而在不显著影响感知精度的情况下极大地削减参数量。
“层级位置对模型质量的影响比统一的位宽分配更重要。通过这种精细的精度梯度,模型能够以显著更小的体积达到甚至超越 Q8_0 的质量。相比之下,传统的统一位宽分配在同等参数量下会产生不可接受的损失。” —— LocalAI 技术报告
因材施教:驯服共享专家的“高偏态”
MoE 模型的特殊之处在于其结构稀疏性,但 APEX 发现,不同类型的专家在量化容忍度上有着天壤之别:
- 路由专家 (Routed Experts): 尽管它们占据了模型的大部分参数,但由于每 token 仅激活少数专家(如 256 个中的 8 个),其稀疏性高达 97%。只要全精度的 Gate 权重能做出正确选择,非激活专家的量化噪声便不会干扰输出。有趣的是,APEX 发现这些专家的权重分布接近高斯分布(峰度 Kurtosis 仅 3.41),传统的 K-quant 块结构在这种分布下表现优于 IQ 格式。
- 共享专家 (Shared Experts): 它们处于常驻激活状态,且呈现出极高的峰度(Kurtosis 达 13.10)。这意味着其内部存在大量极其关键的离群值(Outliers)。APEX 将其视为质量瓶颈,坚持使用 Q8_0 作为其“最低可用精度”,确保这些核心逻辑单元不发生性能塌陷。
告别维基百科:I-variants 带来的现实世界对齐
传统量化校准(Imatrix)过度依赖维基百科,这常导致模型产生“百科全书式”的生硬文风。APEX 推出的 I-variants 系列引入了全新的校准逻辑:
- 多样化校准: 使用包含聊天、代码、推理和工具调用(Tool-calling)的混合数据集进行校准。
- KL 散度的胜利: 这种策略虽然在 wikitext(维基百科测试集)上的困惑度(Perplexity)会有微小上升,但换来的是更低的 KL 散度(KL Divergence)。这意味着量化模型在逻辑分布上更接近原始模型,从而在 MMLU、ARC 等现实任务中表现出更强的战斗力。
数据实证:APEX Mini 在 12GB 显存上的奇迹
在 NVIDIA DGX Spark (GB10) 基准测试环境下,我们对比了 APEX 与传统量化方案在 Qwen3.5-35B 上的表现。APEX Mini 在极端压缩下的表现足以令人惊叹:
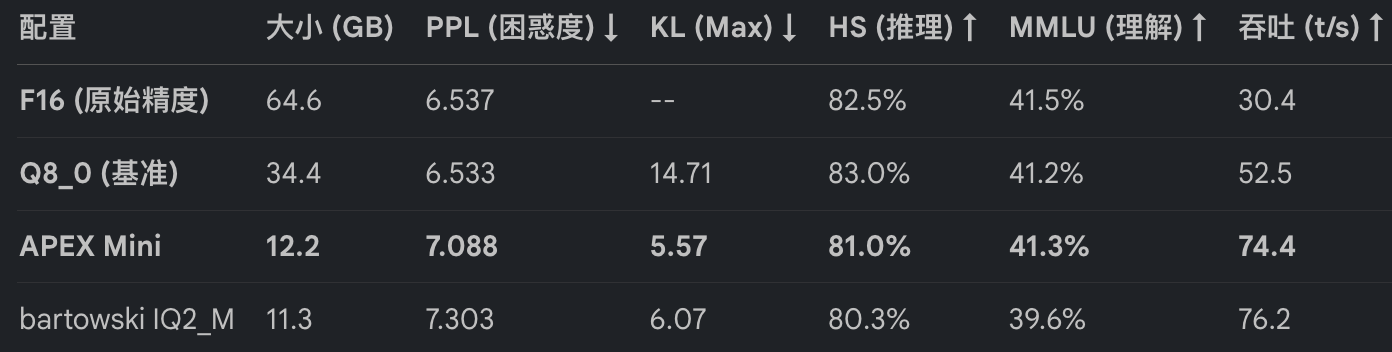
结论: APEX Mini 在仅需 12.2 GB 显存的前提下,在所有核心指标上全面击败了 bartowski IQ2_M,其 MMLU 表现甚至逼近 F16 全精度水平。这意味着拥有 16GB 显存的消费级显卡(如 RTX 4060 Ti)已经可以流畅运行 35B 规模的顶级 MoE 模型。
极致提速:与 TurboQuant 的强强联手
APEX 不仅仅在权重压缩上做文章,它还能与 TurboQuant KV 缓存压缩技术 完美共存。
通过使用 -ctk q8_0 等配置,TurboQuant 能将 KV 缓存压缩达 4.6 倍。这不仅让 Prompt 处理速度提升了 13-14%,更关键的是,它解决了长文本推理的痛点。这种组合让 35B 模型在 16GB 显卡上实现 8K 以上的长上下文推理成为了可能。在 APEX Mini 模式下,生成速度达到了惊人的 74.4 t/s。
结语:开启个人 AI 部署的新纪元
APEX 的出现证明了:通过精细化的精度管理,我们能够突破硬件算力的物理枷锁。它不仅是一次技术方案的更迭,更是一场关于“部署正义”的实践——让尖端的 AI 能力不再被局限在昂贵的服务器集群中。
当 12GB 显存就能驱动曾需要数万元硬件支持的 35B 模型,且表现优于 F16 精度时,本地 AI 部署的物理壁垒已经瓦解。欢迎前往 GitHub (mudler/apex-quant) 获取这些模型,亲自见证 LocalAI 团队带来的技术突破。