


 12
12 0
0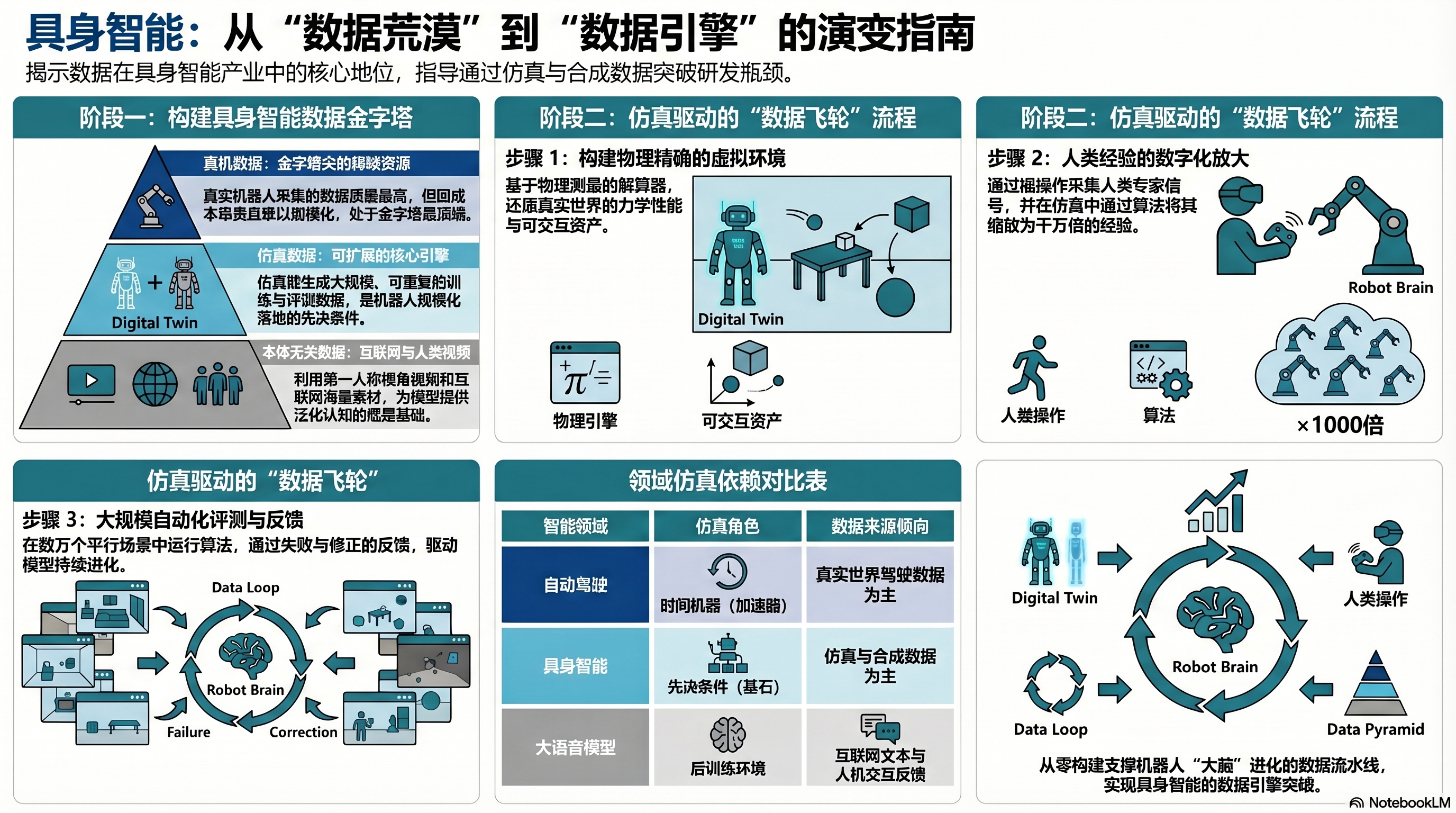
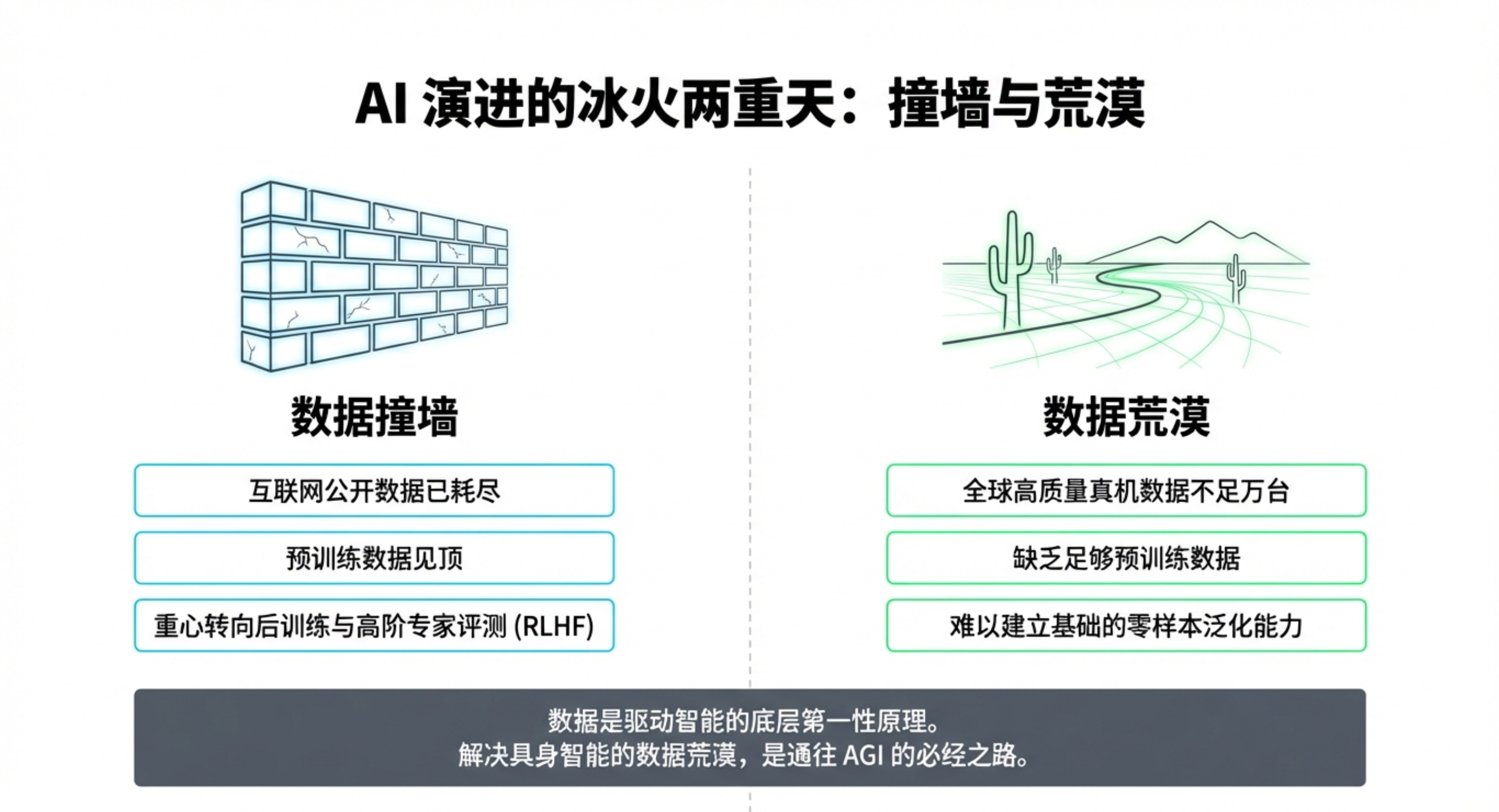
当大语言模型几乎“读完”了互联网上所有公开文本,数据开始枯竭;而在具身智能领域,情况恰恰相反——我们正处在一场数据的极度“荒漠”之中。没有足够高质量的物理世界交互数据,机器人就无法像大模型那样涌现出泛化智能。
本期内容源自光轮智能创始人谢晨的深度访谈。他曾任职于英伟达、蔚来及硅谷自动驾驶巨头,如今正投身于具身智能的数据基础设施建设。你将了解到,为何仿真技术已从“加速器”升级为“先决条件”;具身智能的“数据金字塔”如何分层(真机数据、仿真数据、人类视频);以及为什么“失败”的纠错数据比完美数据更有价值。同时,谢晨描绘了未来产业生态的四方协作图景:大模型商(大脑)、本体公司(身体)、数据商(引擎)、场景商(落地)。对于关心AI如何从数字世界走向物理世界的你,这期内容不容错过。
具身智能的突破,依赖于以仿真为中心、评价驱动的本体无关数据闭环。数据的价值正从“标注”向“反馈与教学”迁移,而仿真技术则是通向 AGI 物理世界落地的基础设施。
参考:Xie Chen : Data Survey — History, Landscape, Pyramid Structure, and Recipes for AI and Robotics Data
以下为主要内容的图文介绍:





📊 数据即教育——从“填鸭”到“名师指导”
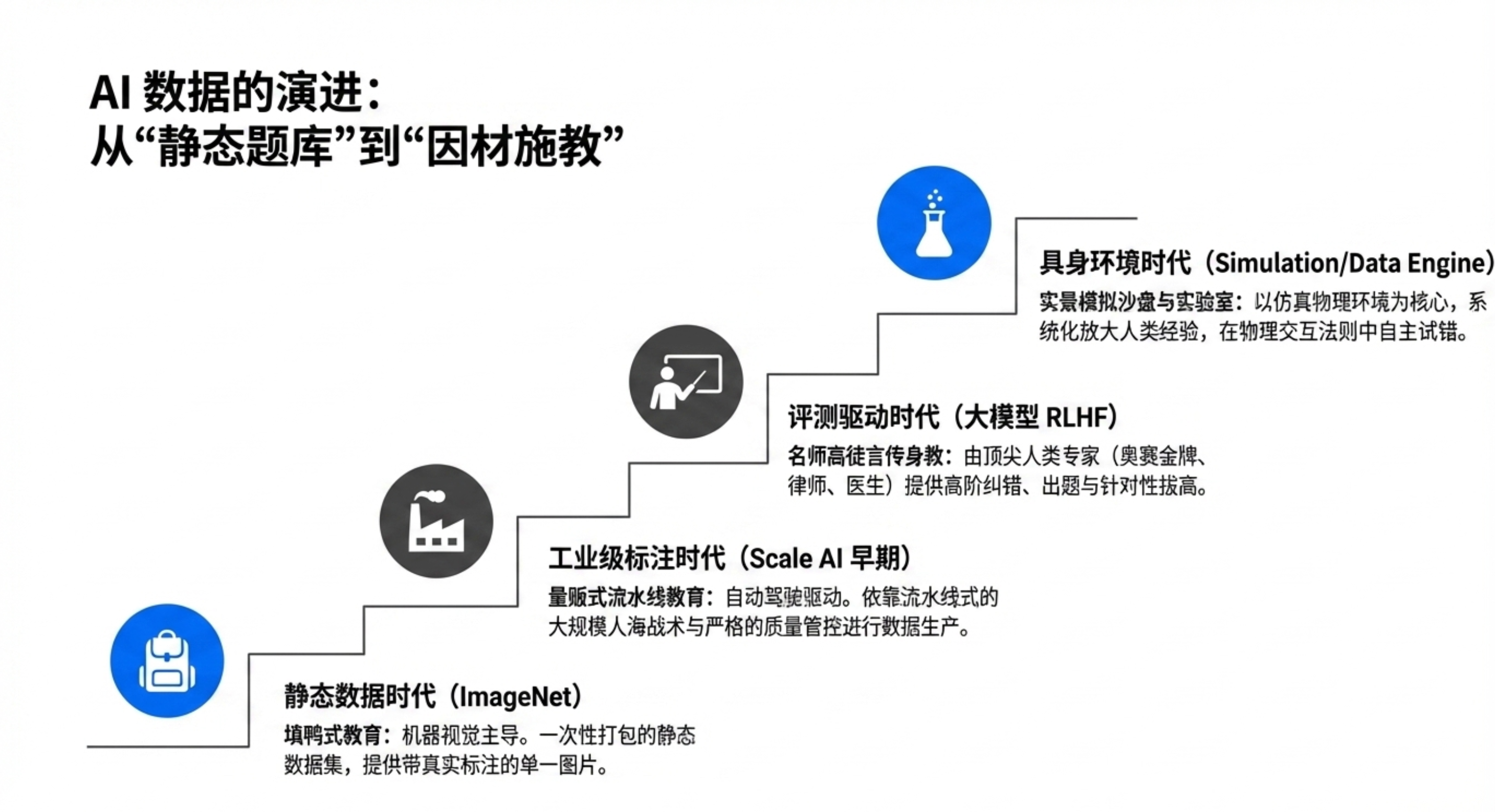
数据与教育类比:谢晨认为,数据对 AI 的意义如同教育对人类学习。不仅是静态信息,更是信号、经验和反馈。
数据产业三阶段:
静态数据集(填鸭式)
工业化规模生产(量化教育)
评价与反馈驱动(名师指导、因材施教)
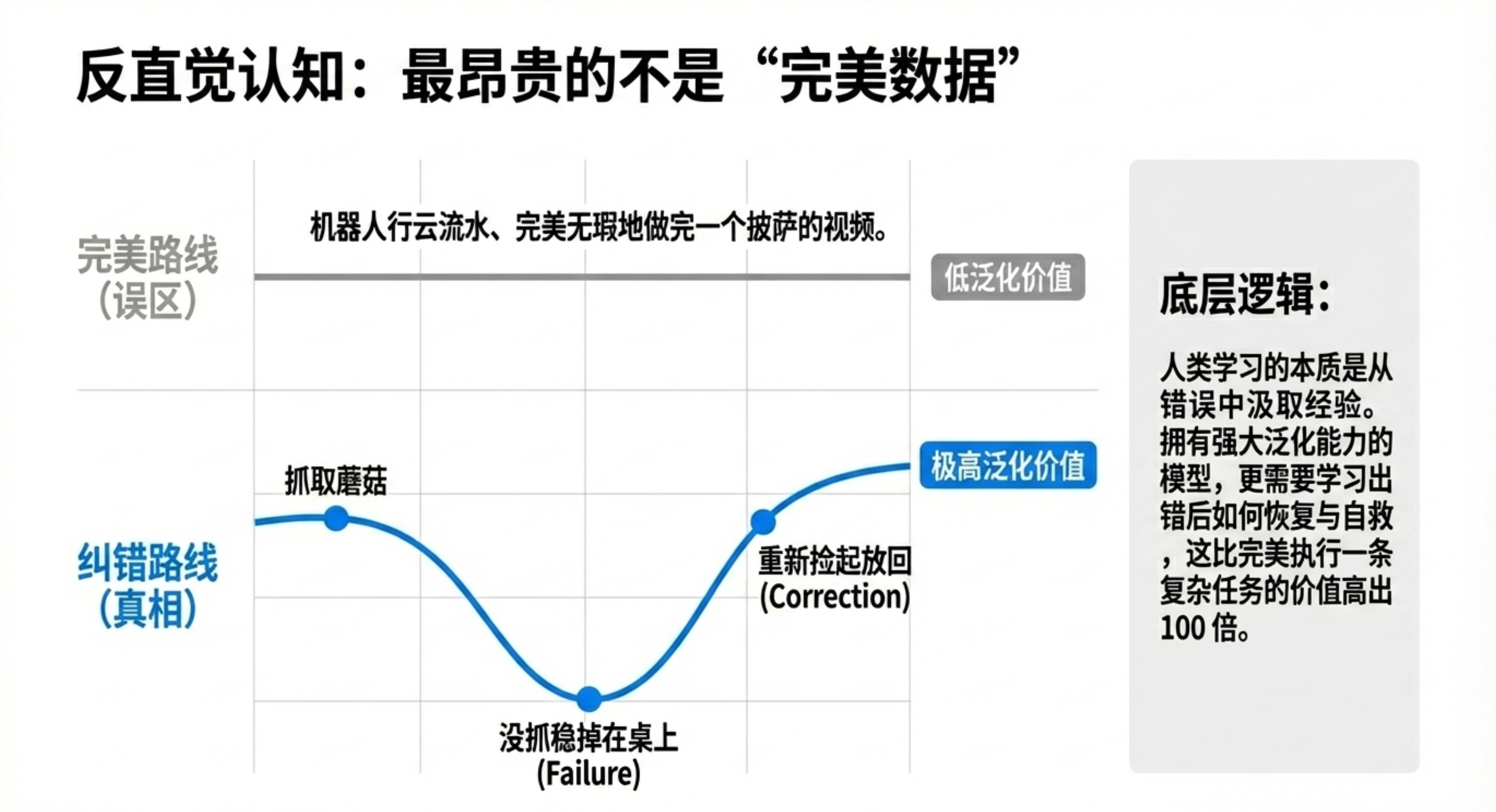
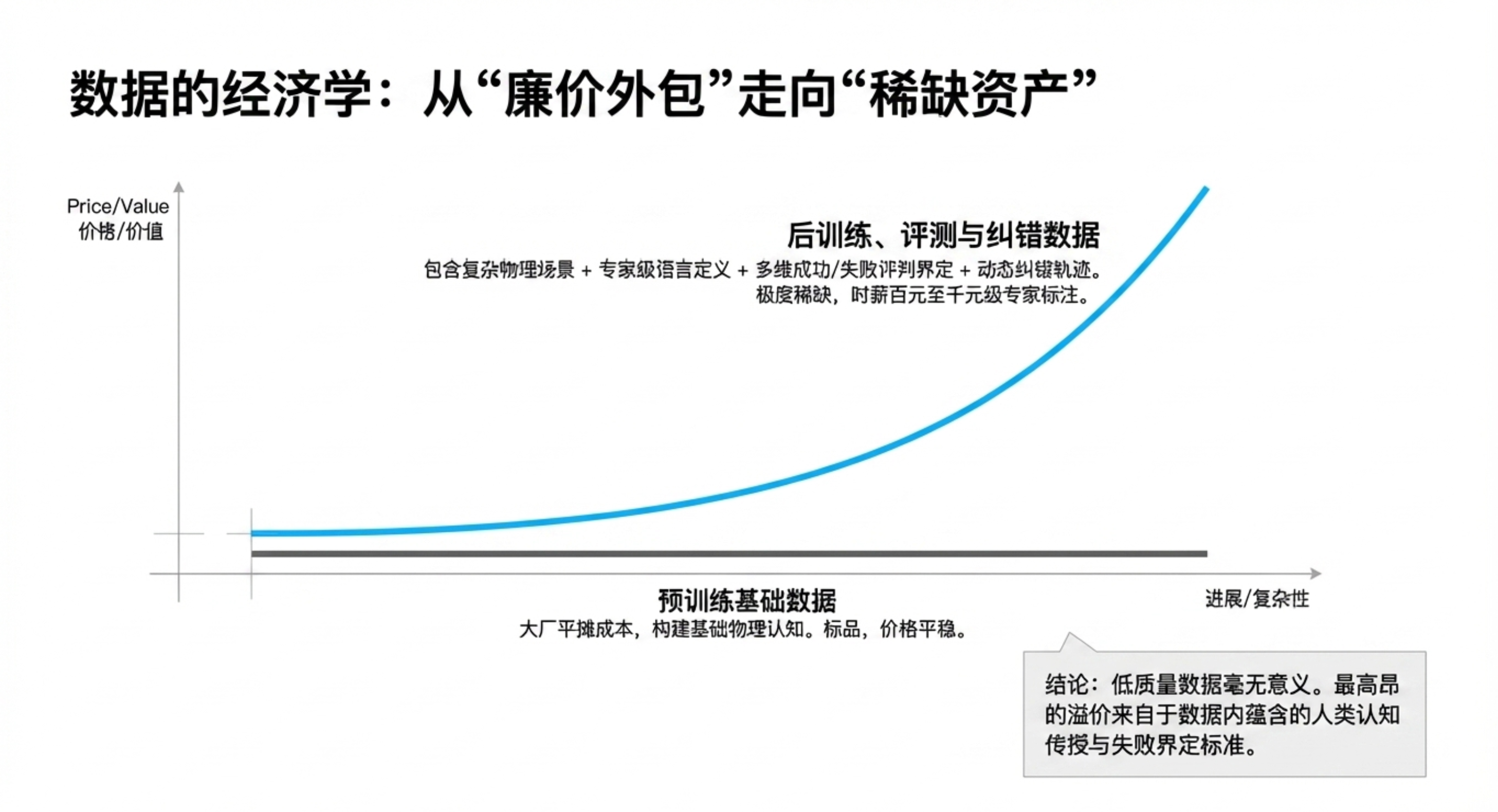
“失败”的价值:在具身智能训练中,先失败再成功的纠错数据(副样本)比完美执行数据更有价值,更接近人类学习过程,能显著提升泛化能力。
🧱 具身智能的“数据金字塔”
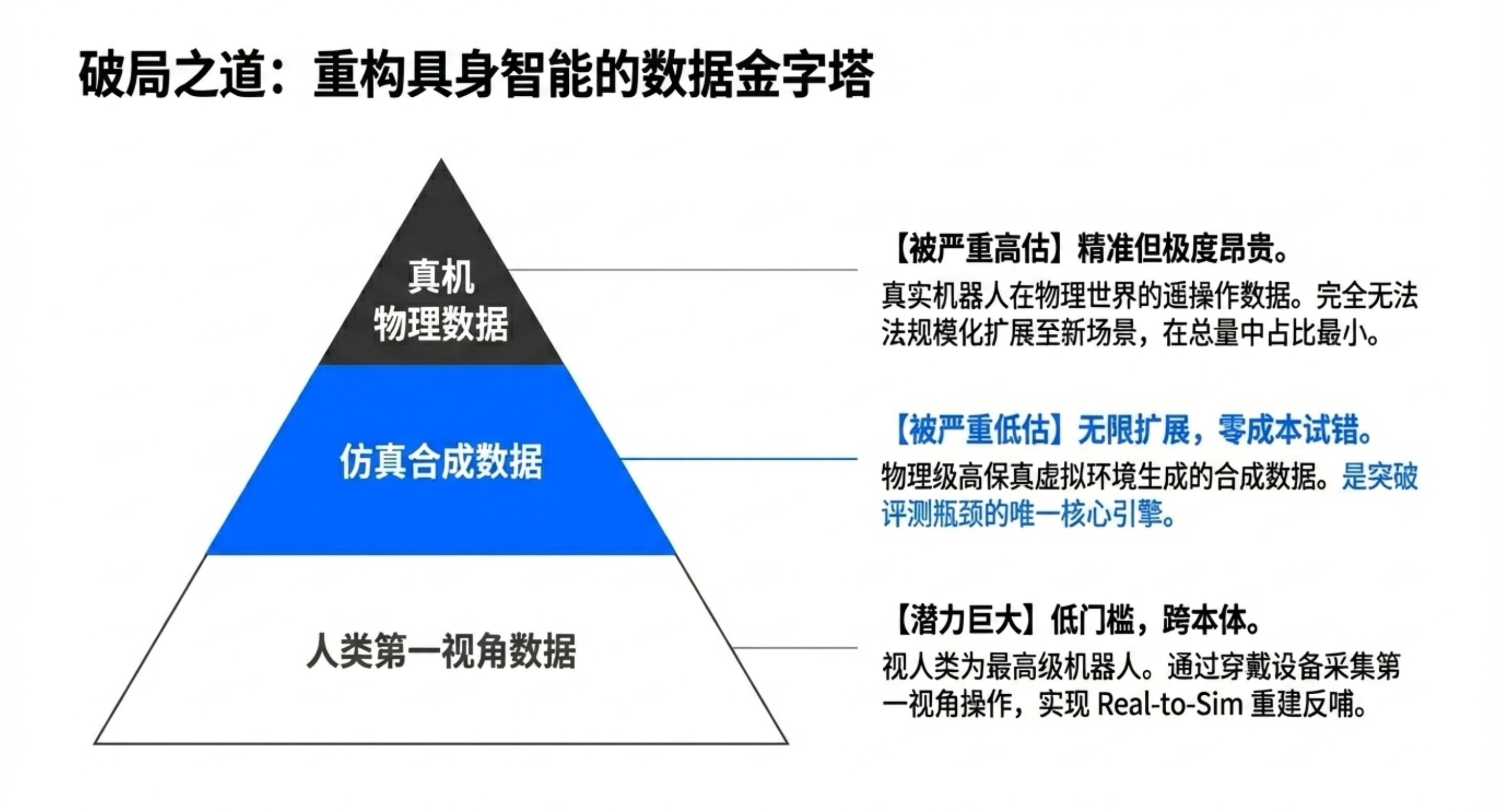
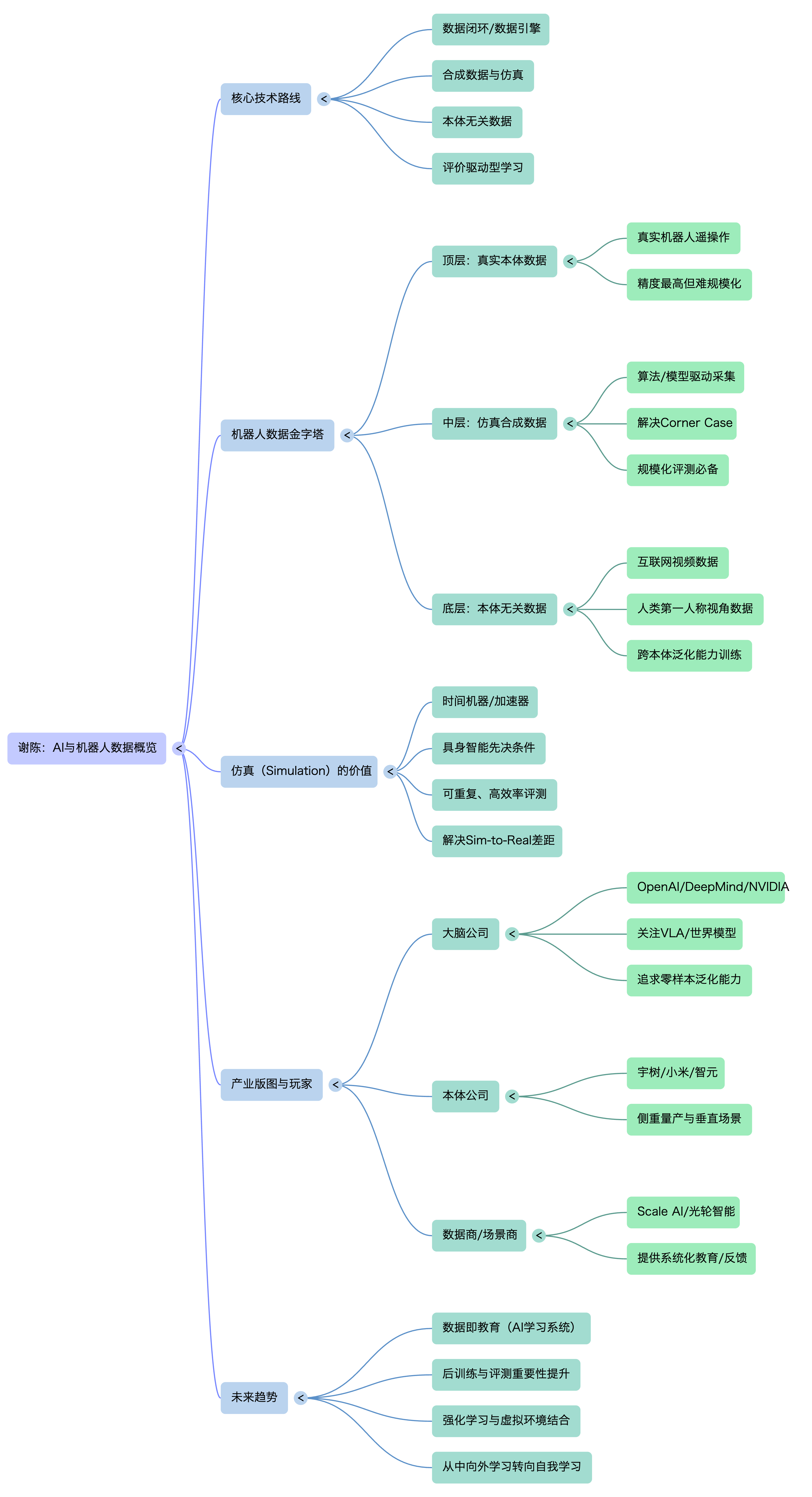
由于目前不存在数百万台机器人采集端侧数据,谢晨提出分层结构:
顶层:真机数据——最准确,但最难规模化、成本最高。
中层:仿真数据——极强的规模化能力,是连接虚拟与现实(Sim-to-Real)的关键。
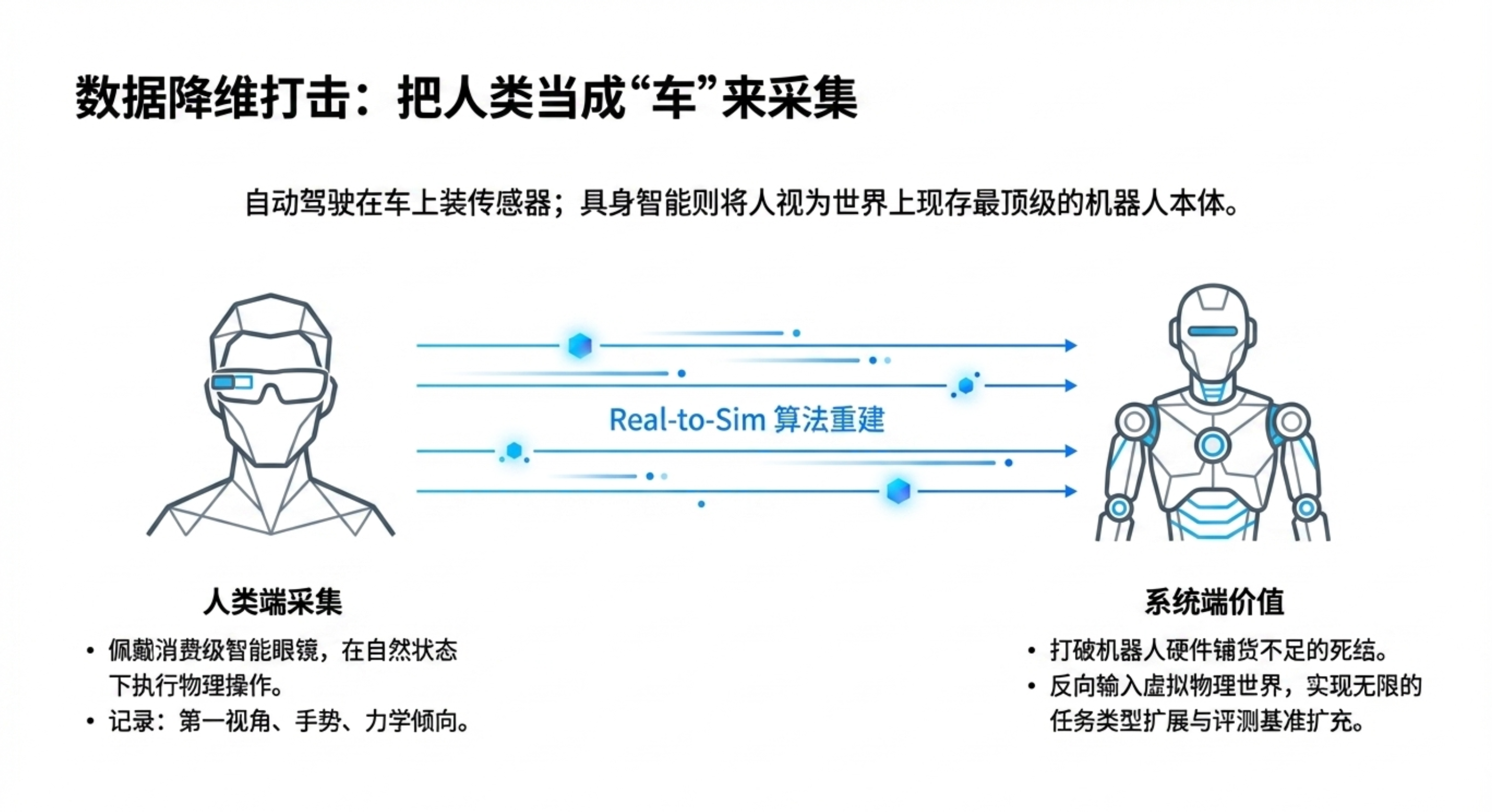
底层:本体无关数据(人类视频/互联网数据)——规模最大,通过人类第一人称视角提供物理世界的基本认知,是实现零样本泛化的基础。
核心趋势:走向“本体无关”数据路线,利用非机器人本体数据训练“大脑”。
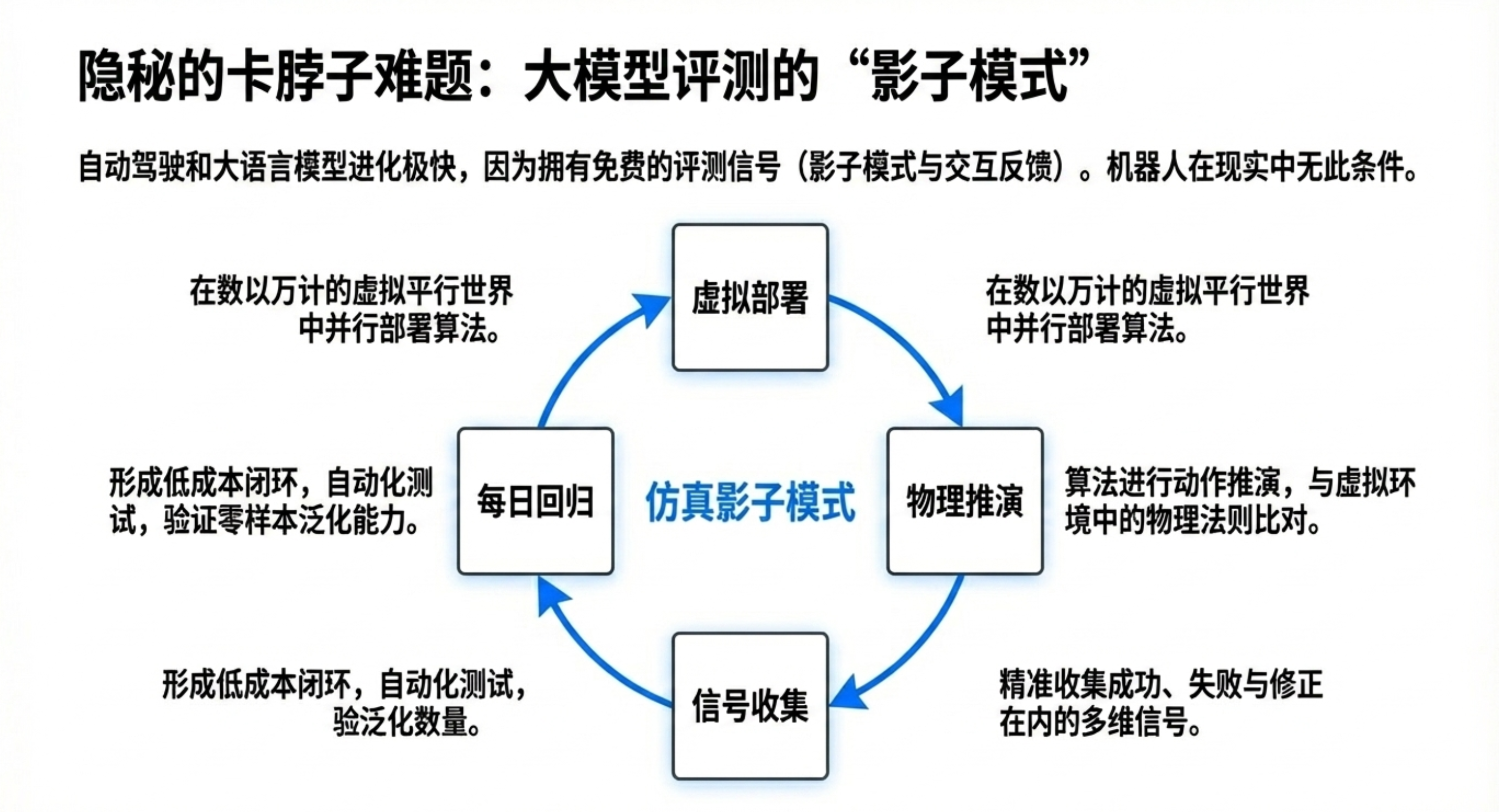
🔧 仿真技术——从“加速器”到“先决条件”
在自动驾驶中:仿真是加速器,非必需。
在机器人领域:仿真是先决条件。没有仿真,规模化训练和评价无法完成。
规模化评价的唯一路径:仿真不仅提供训练数据,更是唯一能低成本、可重复、大规模验证算法有效性的工具。
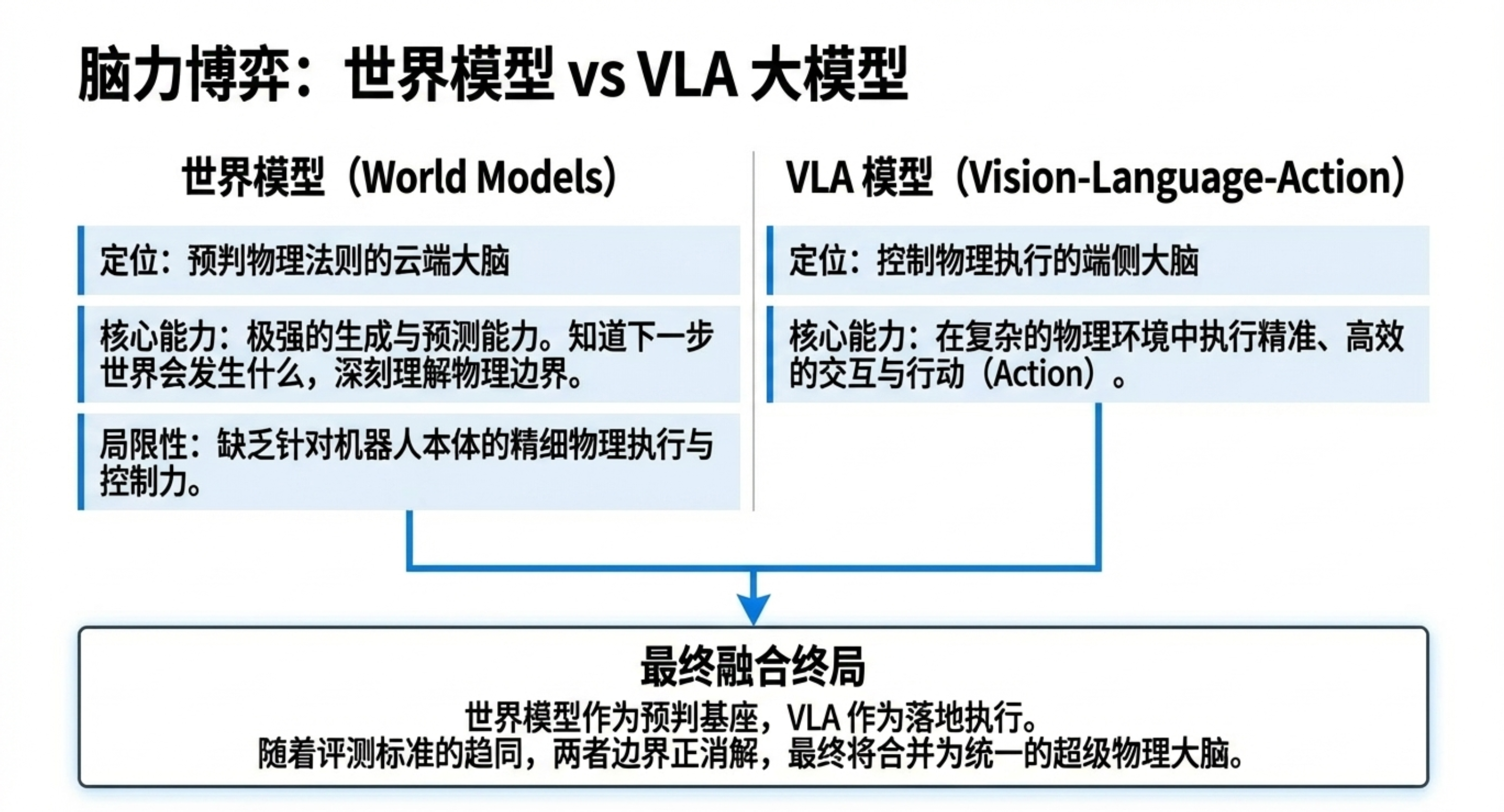
与世界模型共生:仿真提供物理准确性,世界模型提供生成与预测能力。二者相互依赖,并非替代。
🧩 产业版图——四方协作与“大脑-身体”分离
未来生态四方:大模型商(大脑)、本体公司(硬件与部署)、数据商(数据引擎与评价)、场景商(落地场所)。
大脑与身体分离:具身智能大脑由基座大模型厂商主导(泛化性要求高),本体公司专注硬件稳定性与场景微调。
大厂激进投入:过去一年,OpenAI、Google DeepMind、NVIDIA、阿里等资源从纯语言模型向物理世界AI倾斜。
🚀 行业终局——从“数据工厂”到“数据引擎”
数据公司的新定义:不是标注工厂,而是以评价为中心的系统驱动型实体,通过技术放大人类经验。
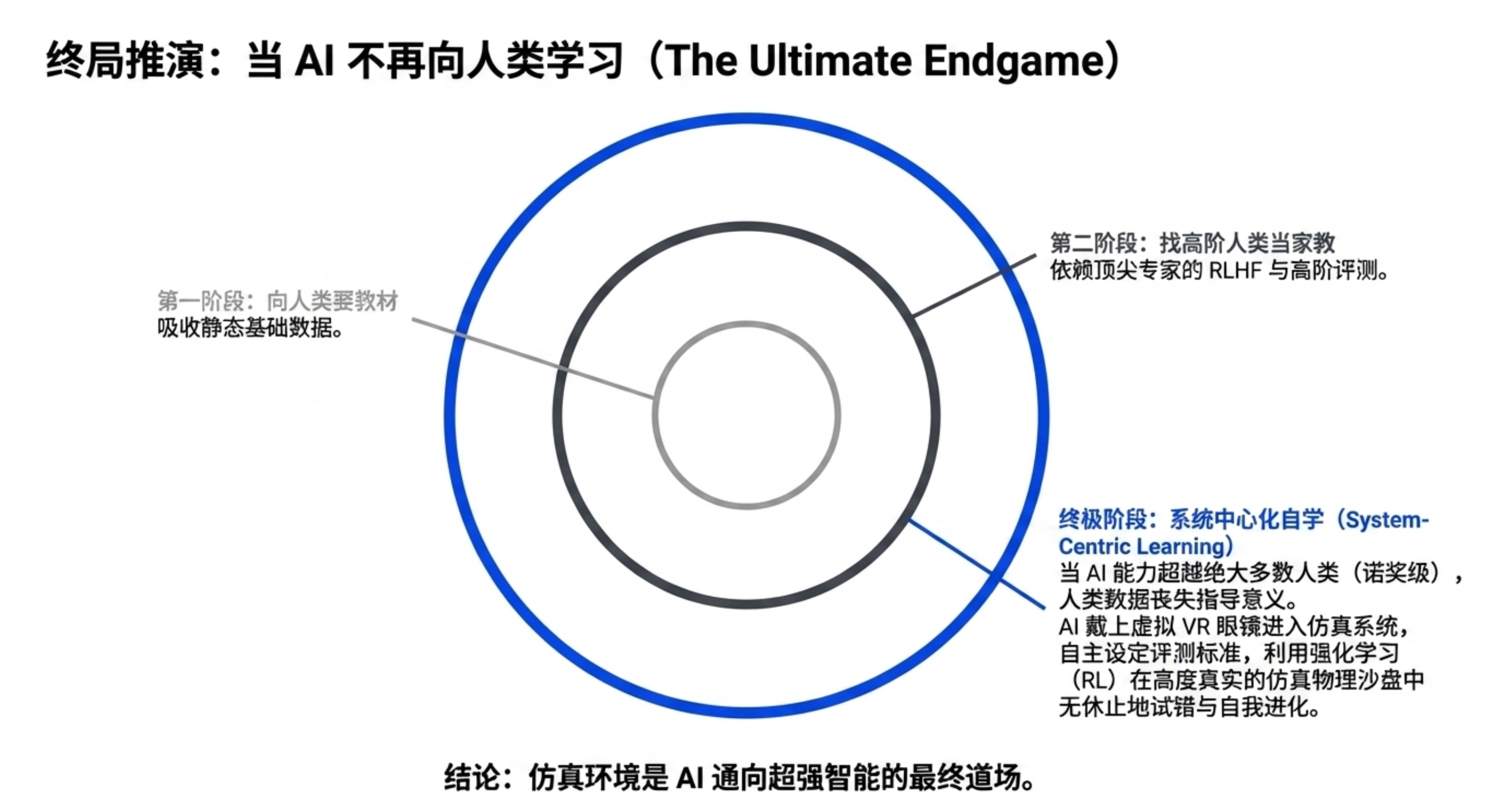
AI 的自我修炼:远期,AI 将从向人类学习转为在仿真环境中通过强化学习自我进化。届时,高质量的仿真环境和评价指标将成为最核心的需求。
