29
29 0
0这份报告将为您深度剖析AI算力基础设施的全产业链。我们将从宏观背景出发,深入细分技术领域,并最终聚焦那些掌握“卡脖子”核心技术的领军企业。
第一部分:宏观分析——AI时代的硬件“军备竞赛”
当前,全球正处于从“传统互联网”向“AIGC(生成式人工智能)”跨越的关键期。AI大模型的训练对算力的渴求呈指数级增长,这直接驱动了全球大型云服务业者(CSP)的资本支出。
资本开支激增:预计2025年,包括谷歌、亚马逊、Meta、微软在内的全球八大CSP厂商合计资本支出将突破4,200亿美元,同比增长达61%。
算力瓶颈转移:随着GPU算力的爆发,计算不再是唯一的瓶颈,“连接”成为了新的核心。AI服务器集群内部需要极高的带宽和极低的延迟,这迫使整个硬件产业链(光通信、PCB等)进行代际更替,从400G向800G乃至1.6T速率全速演进。
第二部分:细分行业分析——光通信与PCB的代际飞跃
在AI算力大背景下,两个细分行业正经历深刻的结构性变革。
1. 高速光通信:从“电”向“光”的终极演进
光模块是数据中心实现高速传输的“翻译官”。
1.6T时代开启:2025年被视为1.6T光模块的商用元年,其复合年增长率预计将超过250%。
前沿路径:
硅光技术与CPO(共封装光学):为了降低功耗并突破空间限制,光器件正从可插拔转向与芯片封装在一起(CPO),这是解决AI集群“功耗墙”的核心手段。
OCS(全光交换):通过光学方式直接进行信号交换,极大地提升了基础设施的可扩展性。
2. 高端PCB:算力服务器的“坚实骨架”
AI服务器对PCB(印制电路板)的要求远超传统服务器。
层数与复杂度:传统服务器多为12-16层,而AI服务器PCB层数已跃升至18-20层以上,甚至达到70层以上的正交背板水平。
材料升级:高速信号传输需要超低损耗材料(如M7/M8/M9级),对精密钻孔工艺(分段钻)提出了严苛挑战。
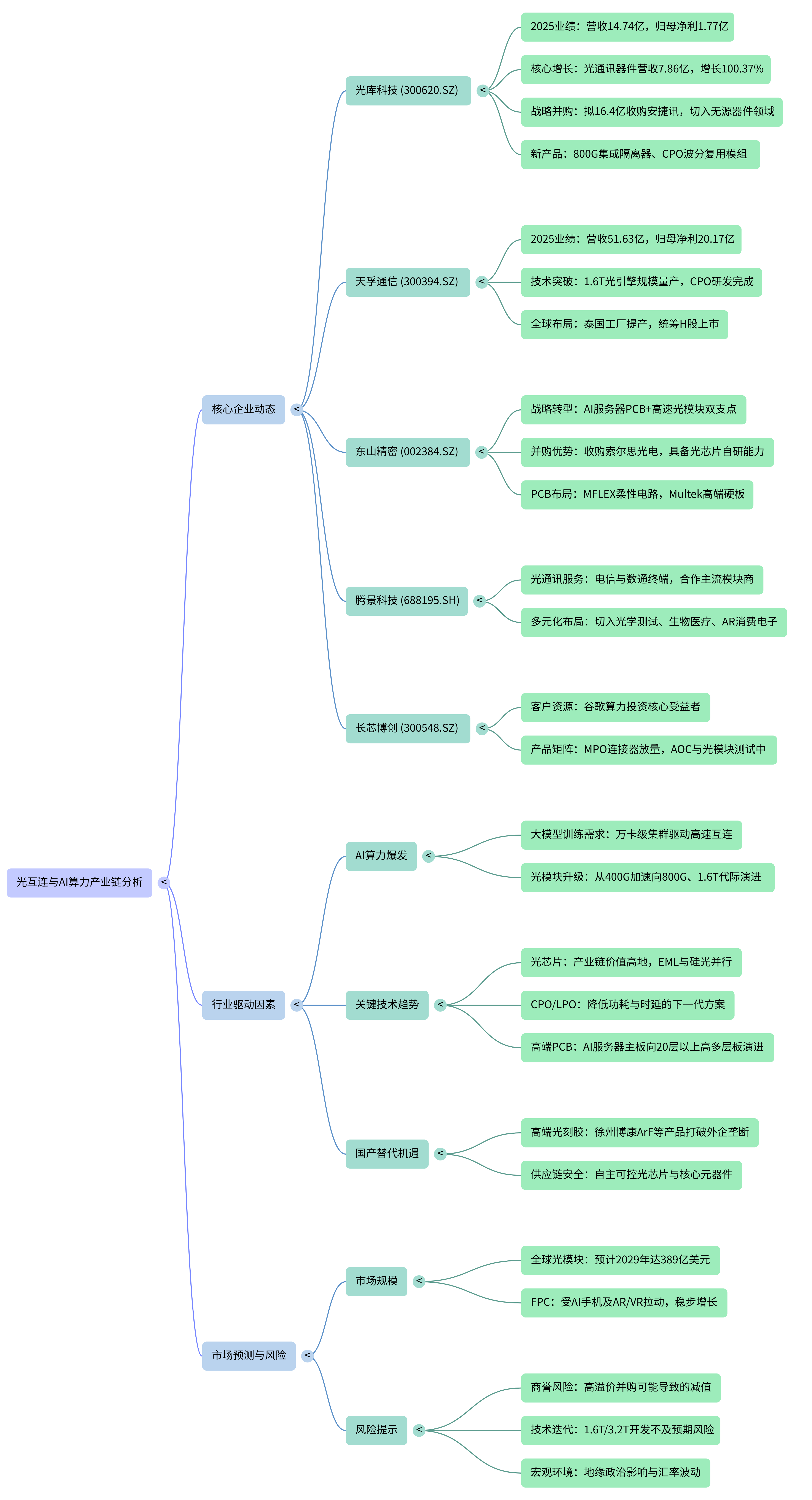
第三部分:卡脖子企业分析——掌握产业链命脉的领军者
在这些细分赛道中,以下公司凭借其在核心芯片、高端装备或工艺上的壁垒,占据了难以替代的“卡脖子”地位。
1. 光芯片自研——东山精密(收购索尔思光电)
核心壁垒:光芯片是光模块价值最高、最难攻克的环节。东山精密旗下的索尔思光电具备稀缺的100G/200G PAM4 EML光芯片自研及量产能力。在1.6T时代,拥有自研芯片意味着不仅能降低成本,更能保障在高端产品的供应链安全。
2. 超高精密封装——罗博特科(子公司ficonTEC)
核心壁垒:硅光和CPO时代的封装精度要求从微米级提升到了亚微米级(±0.3~1μm)。其子公司ficonTEC是全球极少数能提供此类全自动耦合封装设备的厂商,是英伟达等巨头量产硅光产品的“标尺”。
3. 光引擎量产标杆——天孚通信
核心壁垒:天孚通信在1.6T光引擎上已实现规模量产,并前瞻性地完成了CPO配套器件的研发。在光器件的高度集成化趋势中,天孚通过垂直整合多个工艺平台,成为了全球高速率器件的“总集成商”。
4. 精密刀具与PCB工艺——鼎泰高科
核心壁垒:面对AI服务器PCB层数激增和增厚,普通钻头无法满足精度。鼎泰高科开发的分段钻工艺和精密钻针,解决了厚板加工的良率难题,是高端AI PCB放量过程中必不可少的“铲子”。
5. 产业链底层支撑——腾景科技与光库科技
腾景科技:掌握高激光损伤阈值薄膜等核心技术,产品应用于光模块、AR眼镜及半导体设备,是精密光学组件的底层基石。
光库科技:在超高速调制器芯片(薄膜铌酸锂)领域深度布局,并正通过重组收购安捷讯来强化“有源+无源”一体化解决方案,卡位下一代光互联。
这不仅是一场技术的较量,更是产业链垂直整合能力的博弈。从光芯片到精密制造,这些企业正通过突破核心技术,助力中国在全球算力竞赛中占据一席之地。