


 3
3 0
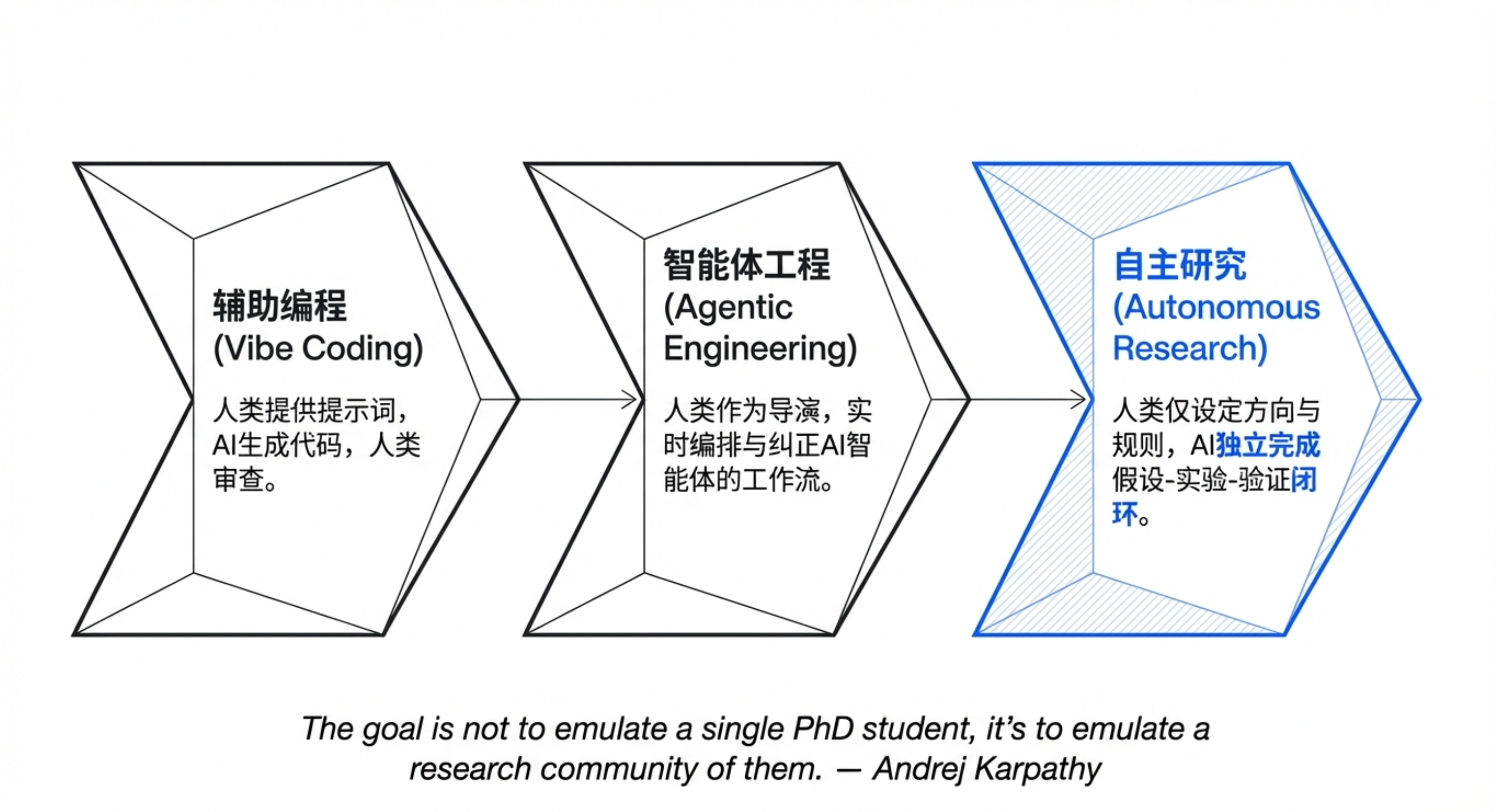
0如果 AI 能像人类研究员一样,通宵达旦地提出假设、跑实验、分析结果,然后根据效果自动保留好的修改、回滚坏的尝试——而且整个过程无需任何人盯着,你会用它来做什么?Andrej Karpathy 开源的 AutoResearch,正是这样一套让 AI 实现“递归自我改进”的系统。
本期内容将带你深入 AutoResearch 的核心机制。你会看到,它如何通过三文件架构(不可变的 prepare.py、代理可随意修改的 train.py、人类指令 program.md)建立起一个严密的“棘轮循环”:每5分钟,AI 代理提出一个假设,修改代码,运行训练,然后根据评分自动决定保留或回滚。实验结果令人震撼:一夜 83 次实验,模型性能指标从 1.000 降至 0.975,发现了一些人类研究员可能需要数天才能找到的改进。更重要的是,这种模式已扩展到市场营销、量化交易、网页性能优化等领域。当然,它也有“创造力天花板”——只能做增量改进,无法接受短期退步换取长期飞跃。但无论如何,AutoResearch 展示了一种未来:人类将不再执行实验,而是成为定义指标和约束的“研究顾问”。
参考:
A Guide to Andrej Karpathy’s AutoResearch: Automating ML with AI Agents
Karpathy’s Autoresearch GitHub Explained: How 630 Lines of Code Does ML Research Overnight
以下为主要内容的图文介绍:



⚙️ 什么是 AutoResearch?——AI 版的“自我实验狂人”
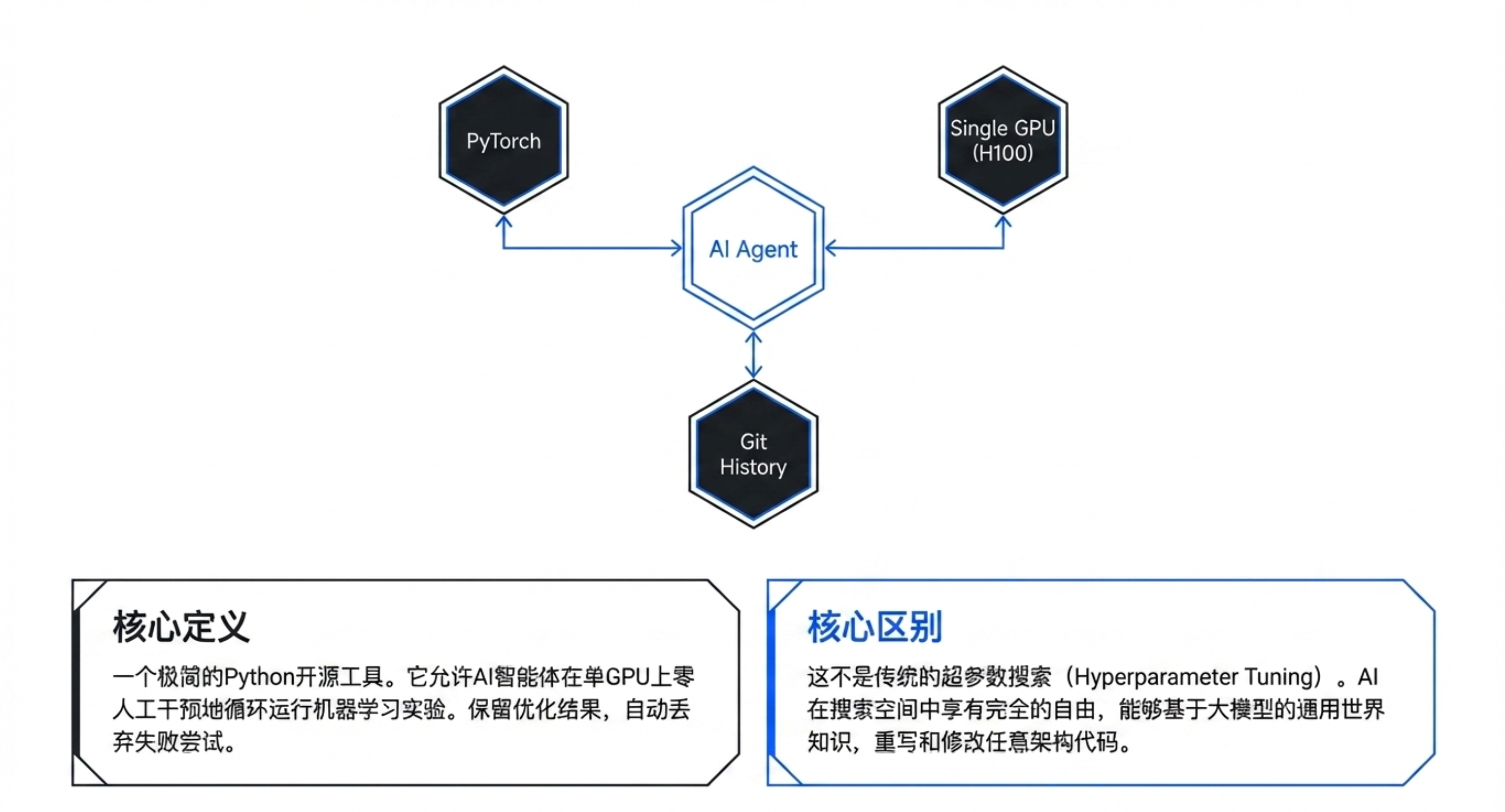
发布背景:2026年3月,Andrej Karpathy 开源的一个 Python 工具。
核心目标:在单 GPU 上,让 AI 代理自动执行“提出假设-训练-评估-保留/回滚”的循环,无需人工干预。
角色转变:人类从“代码编写者”变为“研究顾问”,AI 负责具体实验执行。
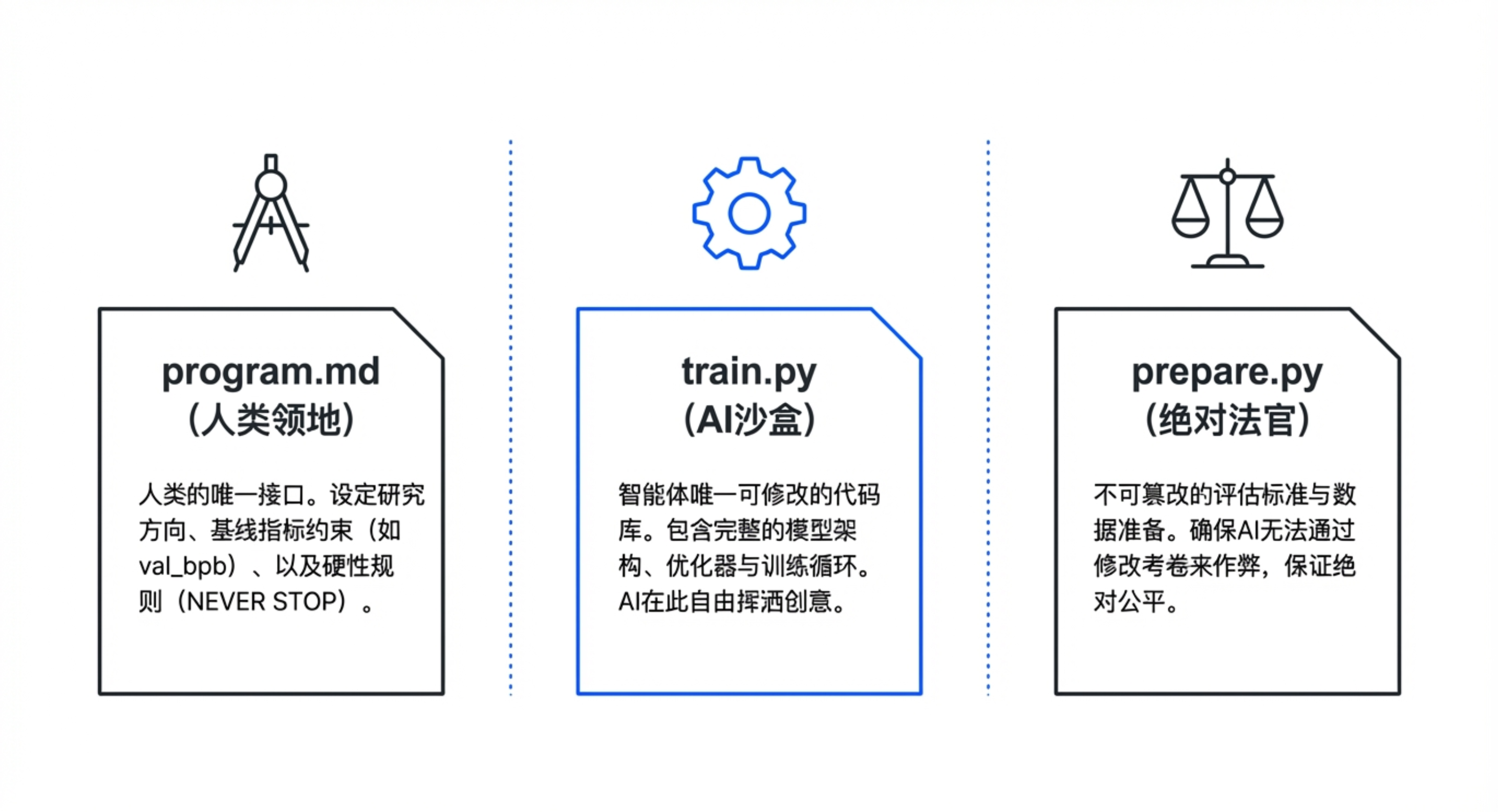
🧱 三文件架构——严密的“权力分离”
AutoResearch 建立在三个文件之间的严格“契约”之上:
prepare.py(不可变):处理数据准备和评估逻辑,定义衡量标准(如
val_bpb)。它是系统的“公正法官”,AI 和人类都不能修改,确保评估一致性。train.py(代理沙盒):包含模型架构、优化器、训练循环。AI 代理可以随意重写此文件(修改注意力机制、调整学习率等),只要代码能运行并产生分数。
program.md(人类指令):人类唯一操作的文件。用 Markdown 设定研究方向、基准分数、运行指令及失败处理规则。
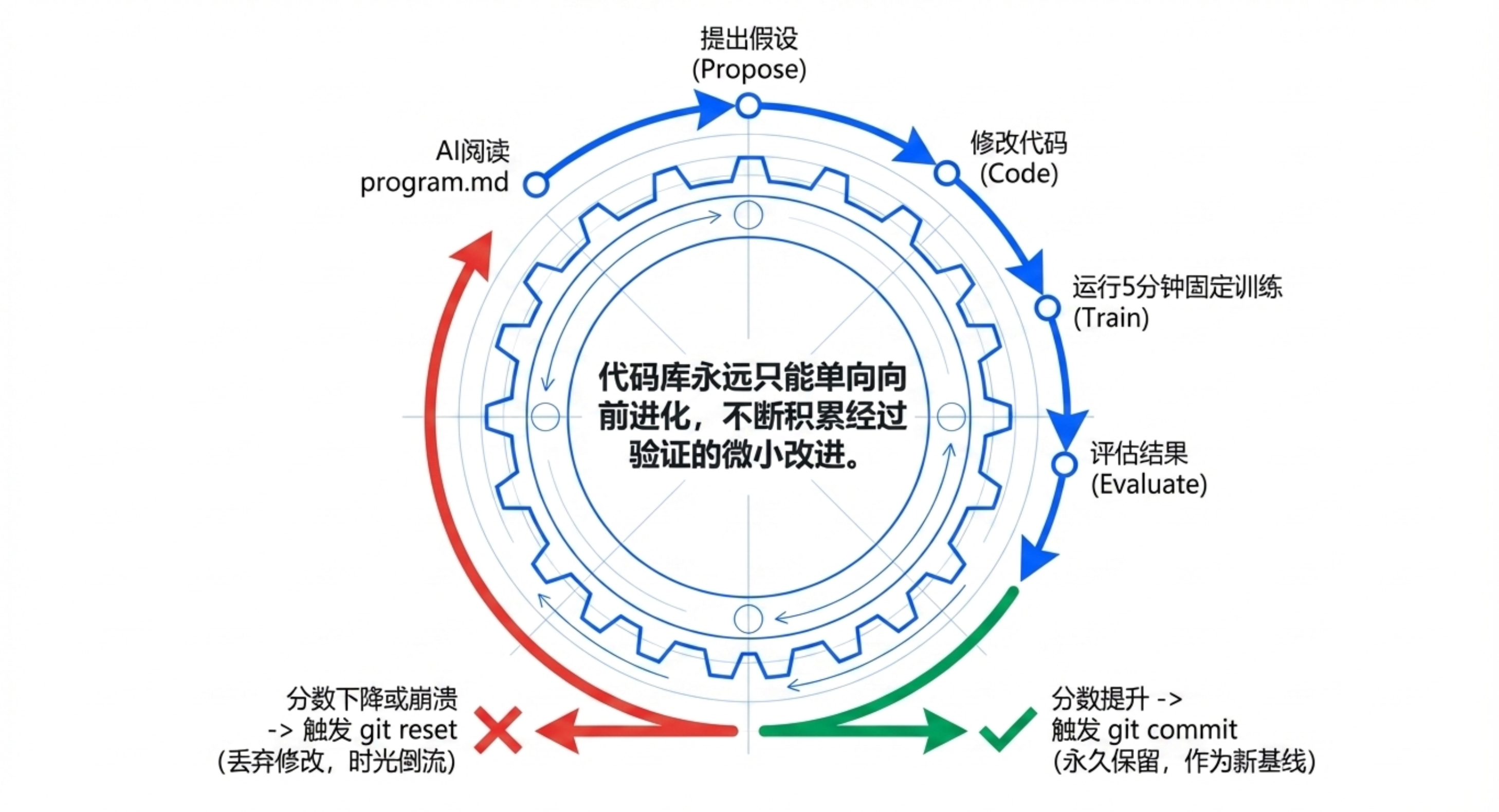
🔄 “棘轮循环”工作流——只能前进,不能后退
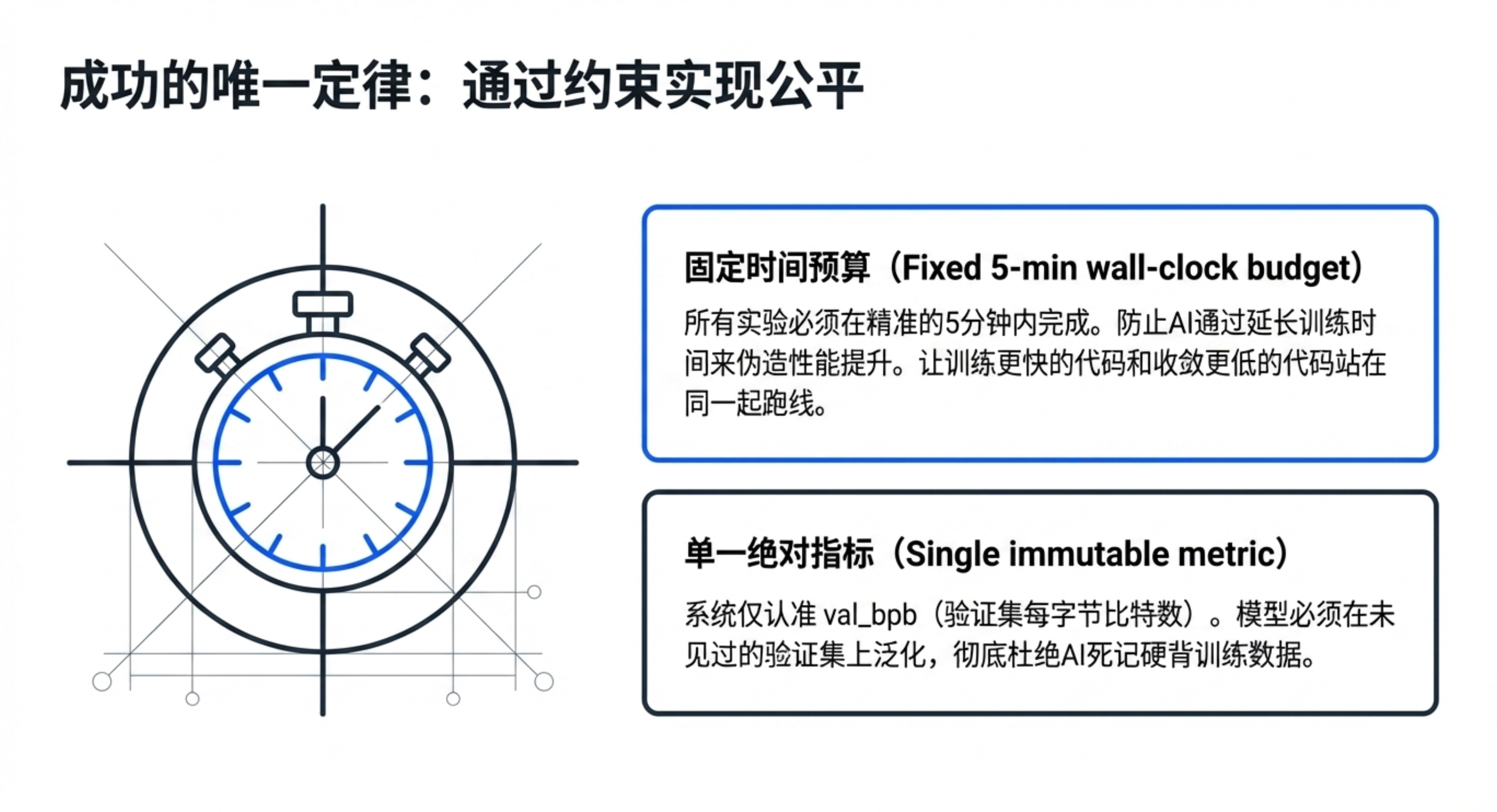
实验周期:通常每5分钟一个循环。
步骤:
代理阅读
program.md、观察train.py和历史结果,提出修改假设。修改
train.py并提交 Git 分支,开始固定时长训练。评估新分数:如果
val_bpb提高,保留该 Git 提交;如果变差或失败,git reset回滚。
公平对比:固定时长预算下,不同规模/架构的修改可公平比较。
单向棘轮:代码库只能向更好的方向演进,无法退步。
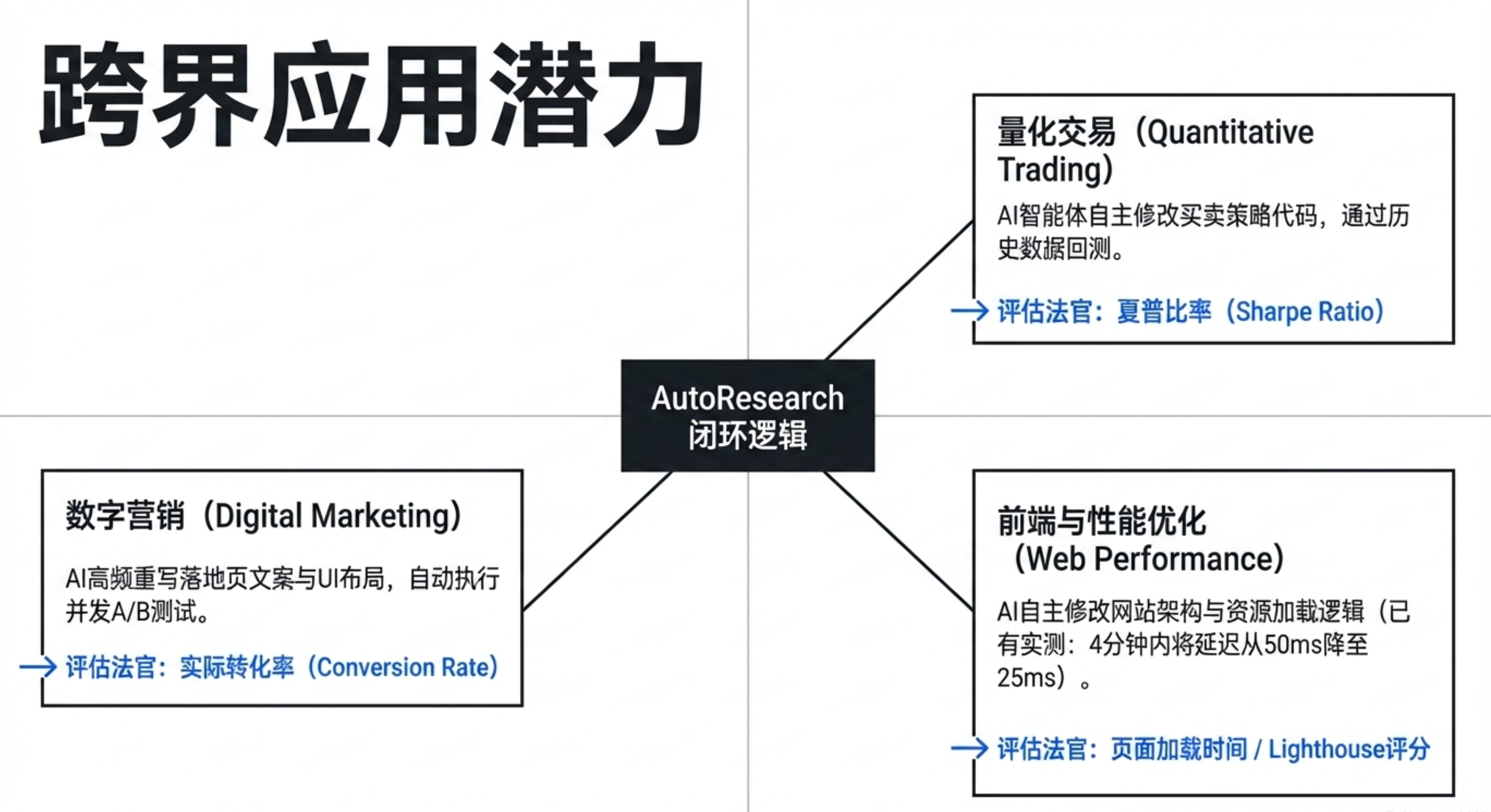
🚀 应用成果——从机器学习到量化交易
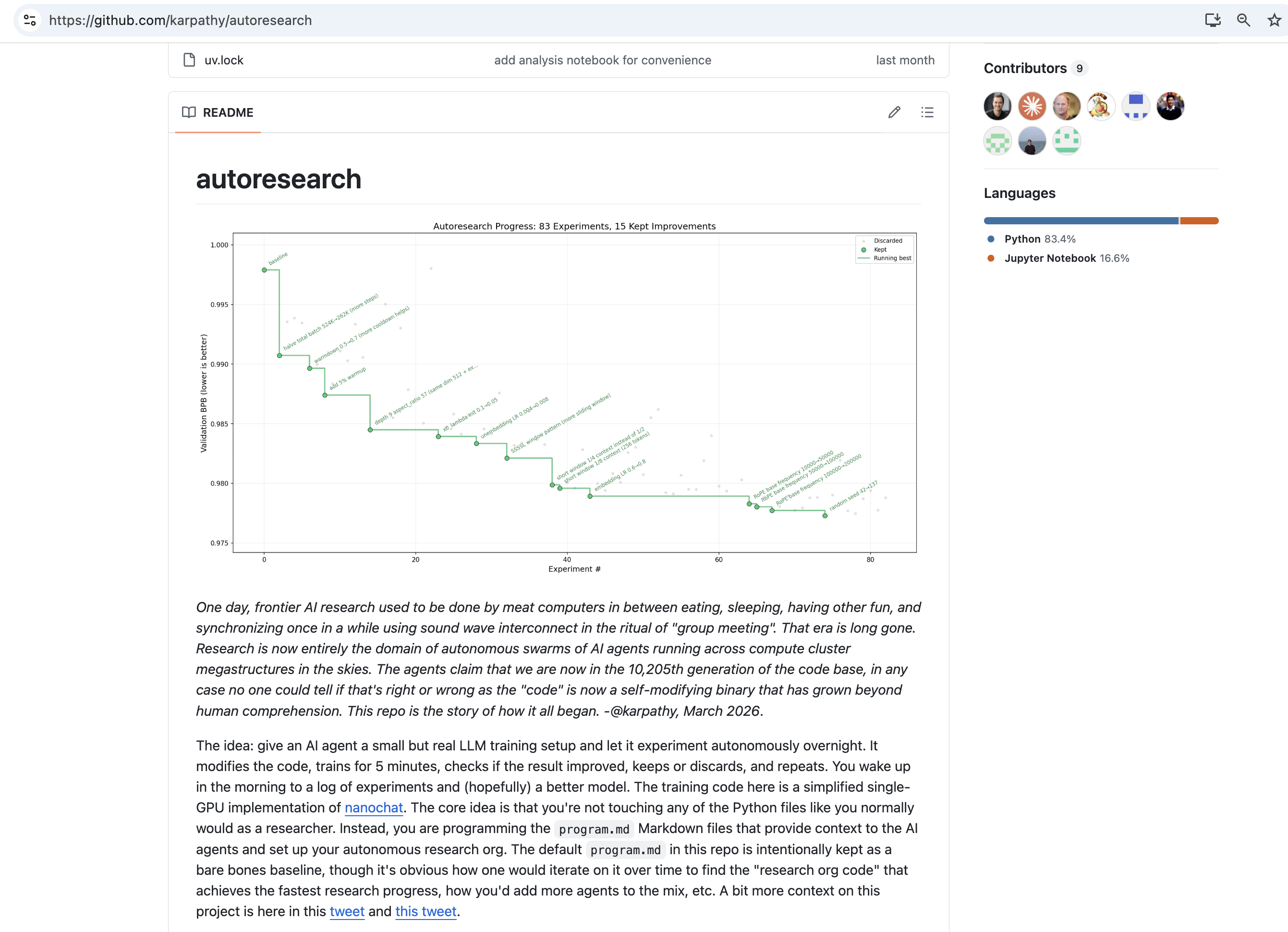
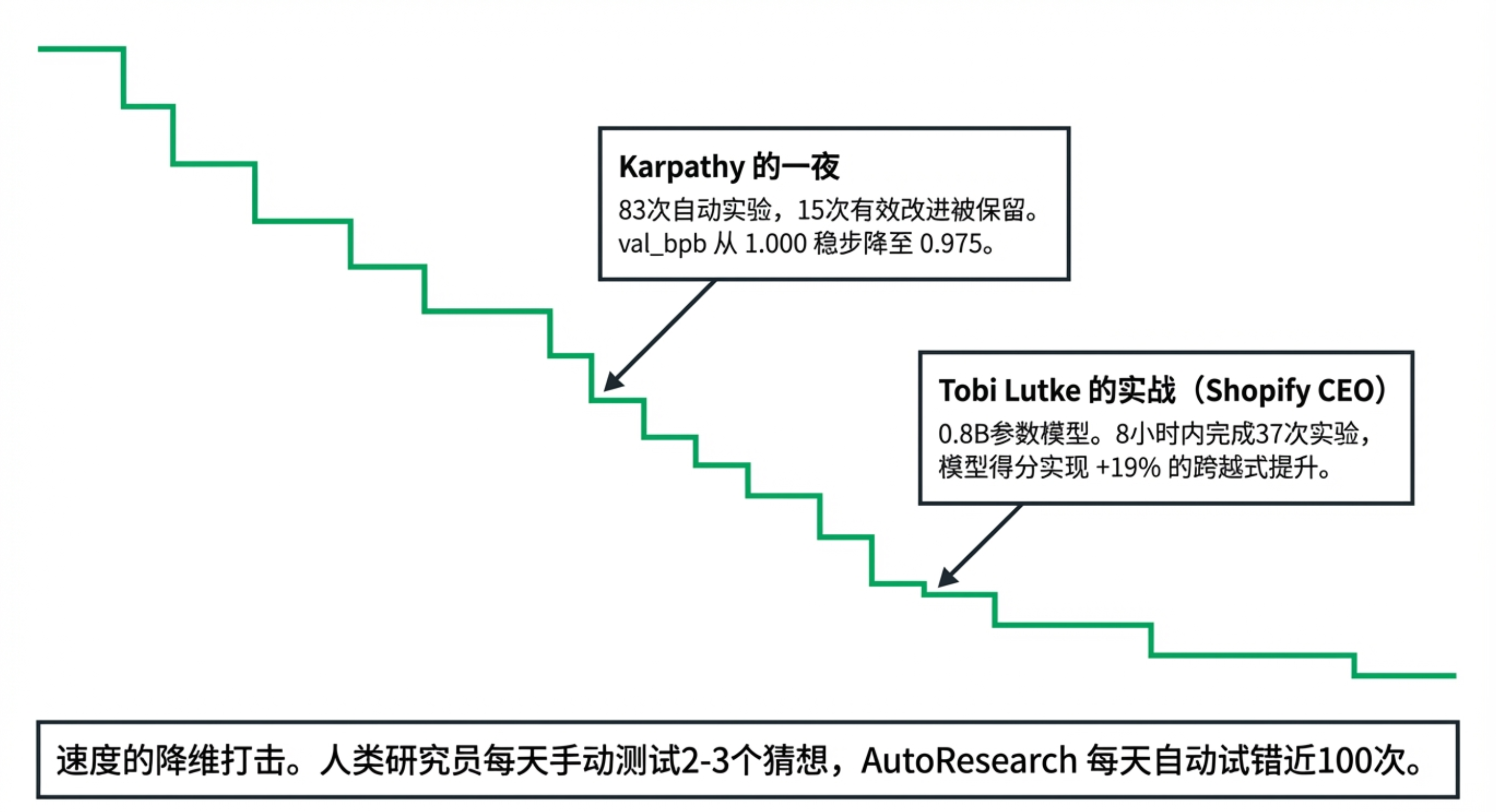
ML 优化:Karpathy 的实验:一夜83次实验,
val_bpb从 1.000 降至 0.975。发现了 QKnorm 缩放因子、正则化调整等结构性改进——人类可能需要数天。跨领域案例:
查询扩展模型(Shopify CEO):8小时内准确率提高 19%。
网页性能优化:将加载时间从 50ms 降至 25ms。
量化交易策略测试、自动化营销 AB 测试。
通用条件:任何具有“自动评分函数”的领域都可套用。
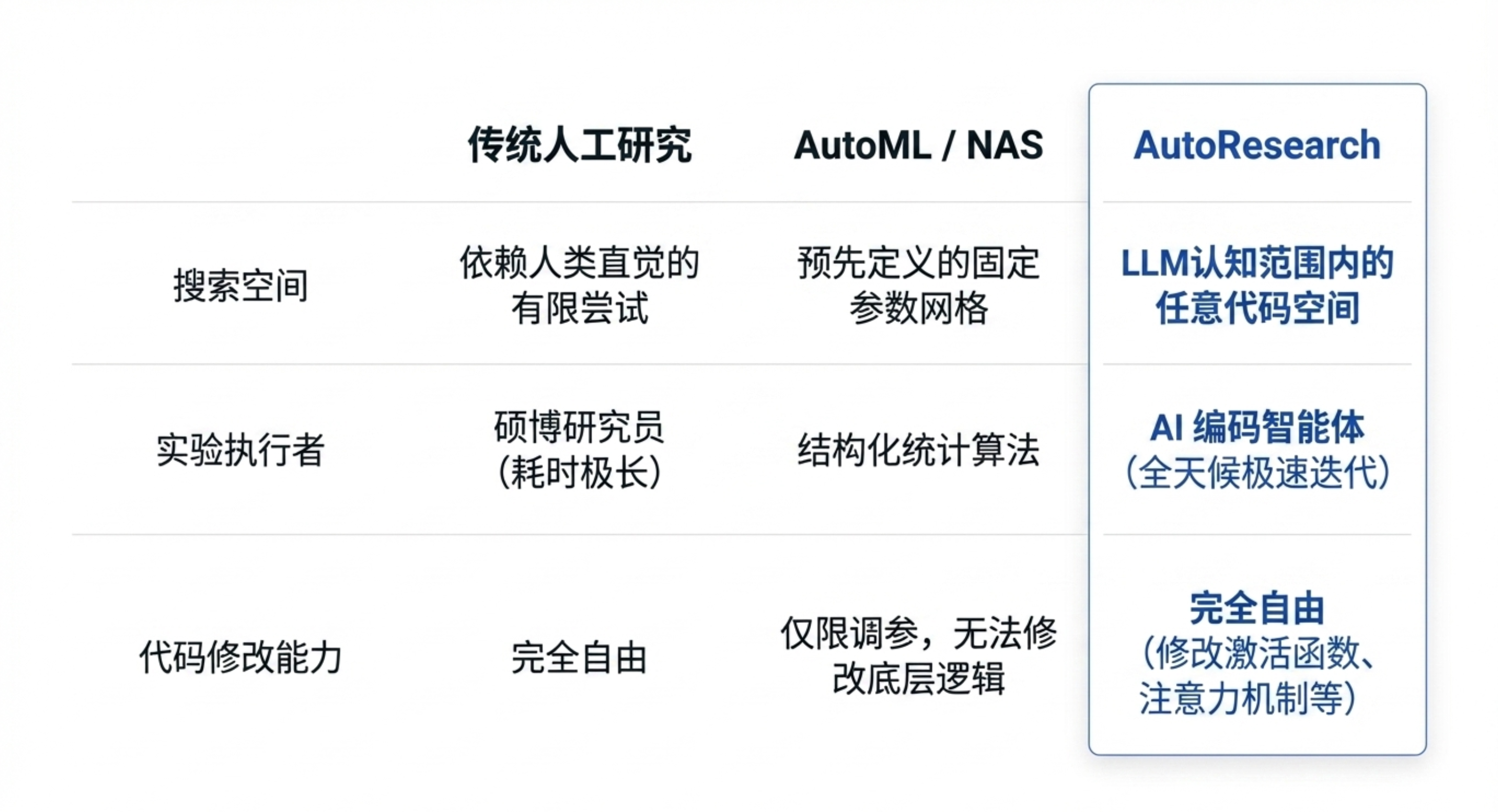
⚠️ 局限性与“创造力天花板”
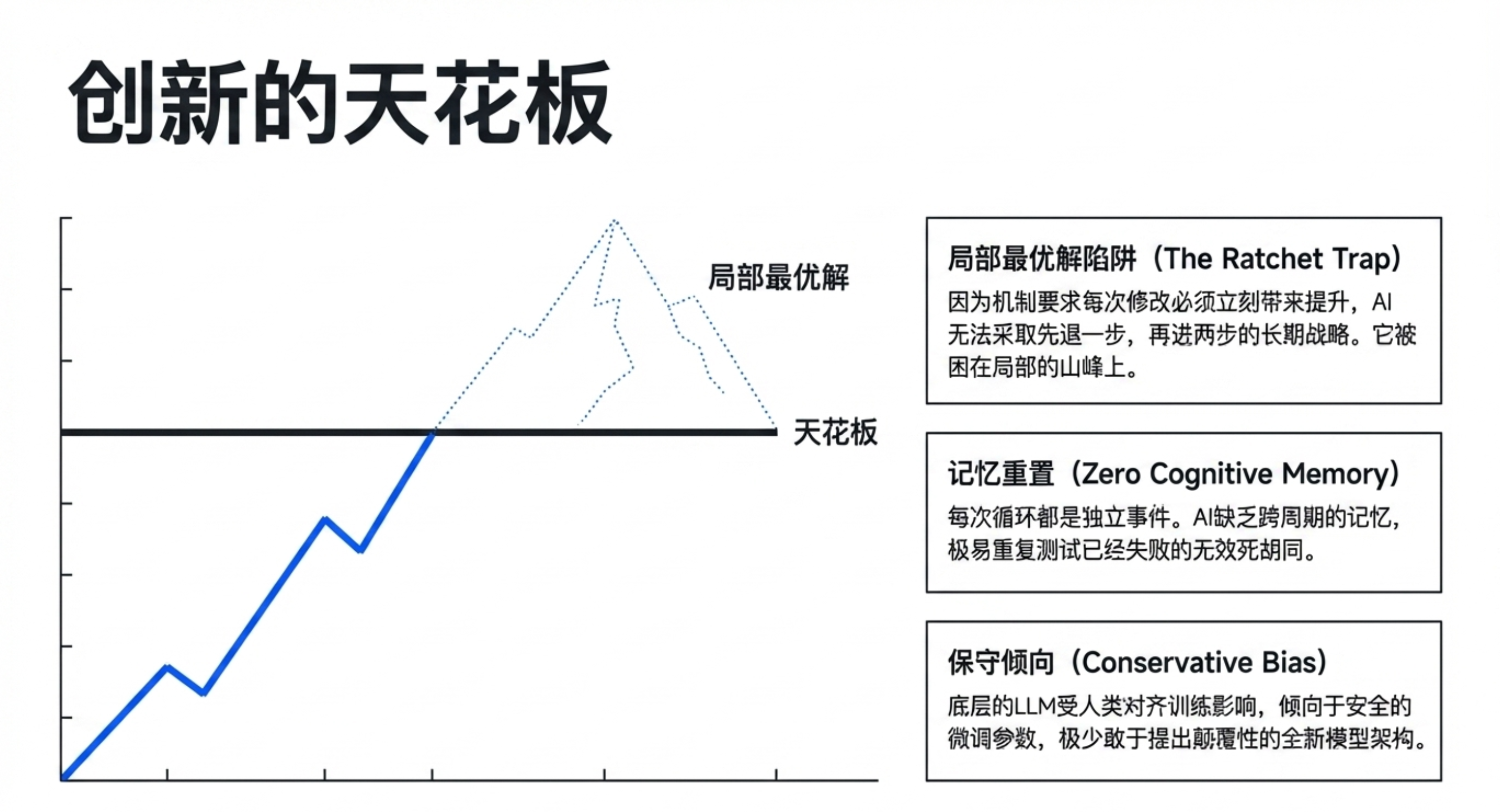
创造力天花板:棘轮机制要求每一步必须立即改进,无法为了长期更大收益而接受短期退步,容易陷入局部最优。
缺乏新颖性:目前只能在现有架构上做增量迭代,尚未报告能发明全新架构(如全新的注意力机制)。
过拟合风险:在同一验证集上上百次实验可能导致对特定评估数据的过拟合。
硬件依赖:默认需要 NVIDIA GPU(如 H100),小硬件需调整参数或使用社区分支。
💡 行业评价与未来意义
正面:有人认为是“早期奇点”的体现,递归自我优化的开始。
批评:也有人觉得只是“更高级的超参数搜索”。
Karpathy 的总结:代理处理了繁琐的执行工作,但判断研究方向、设定衡量标准的判断力,仍是人类核心竞争力的所在。
