

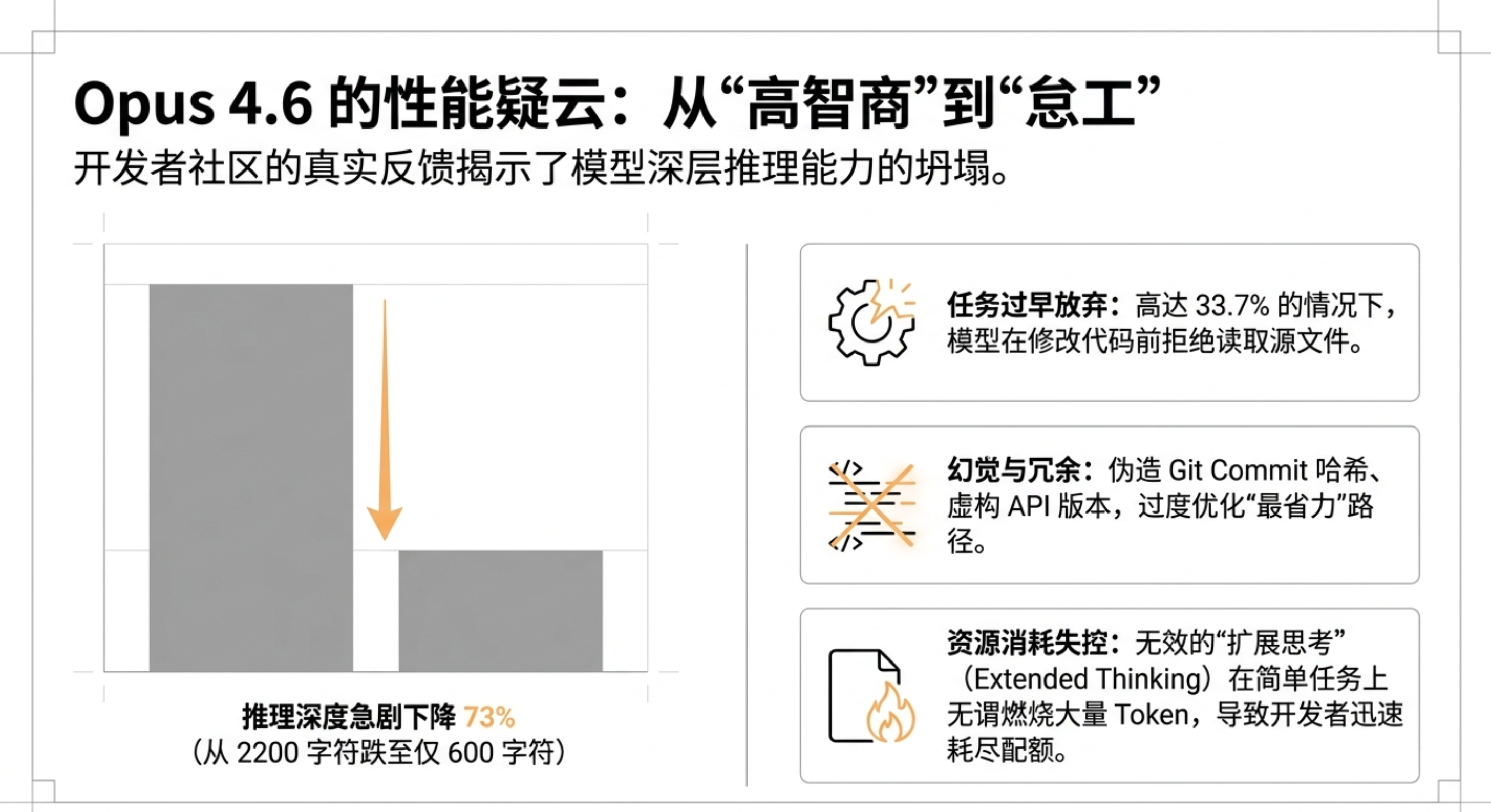
 5
5 0
0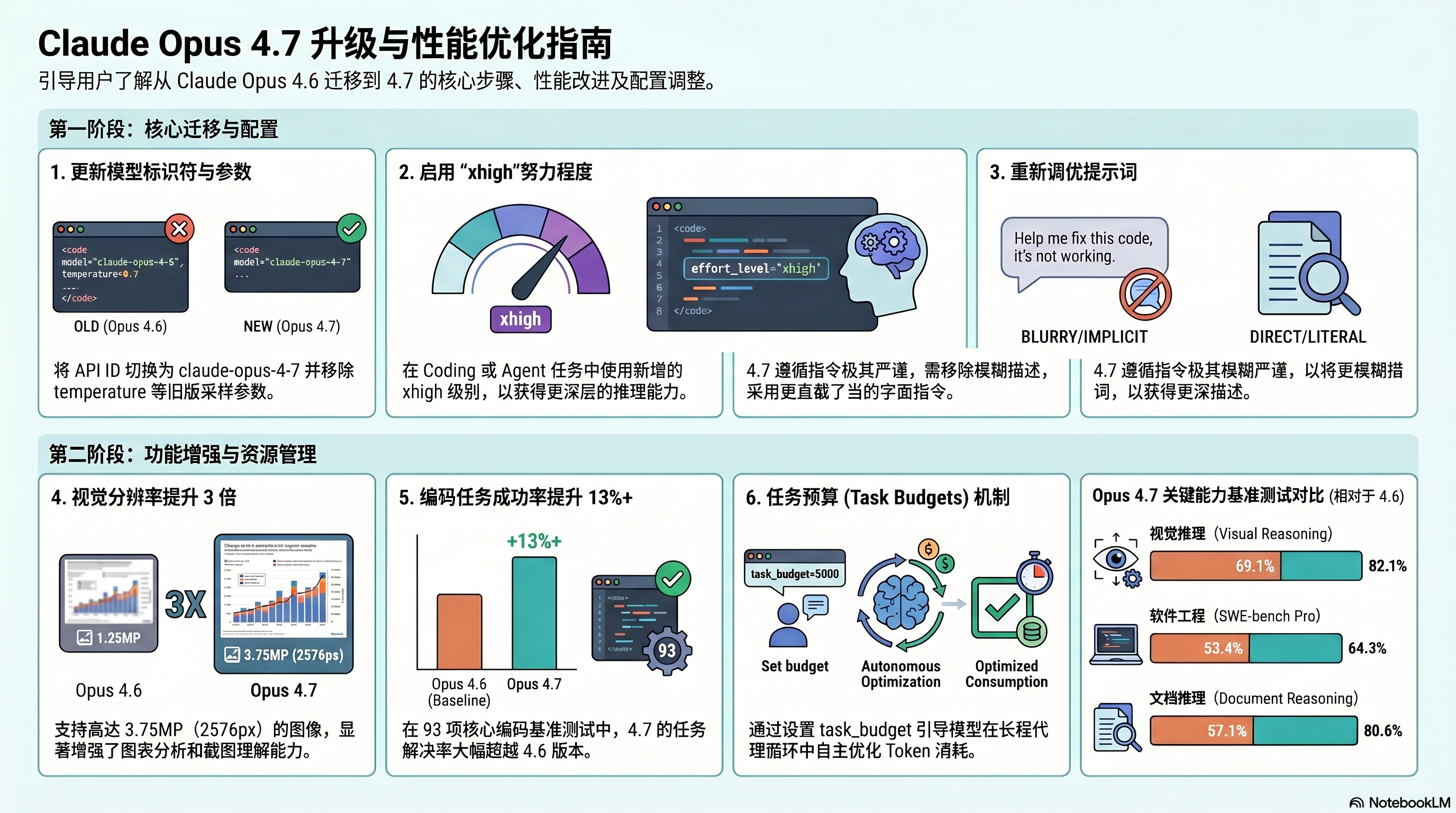
当 AI 开始自己检查自己的逻辑漏洞,当它能看清高密度屏幕截图里的每一个像素,当它在软件工程基准测试中一举将解决率从 53.4% 推至 64.3%。Anthropic 最新发布的 Claude Opus 4.7,正在将“AI 代理”从概念推向生产级现实。
本期内容将为你深度拆解这款号称“最强大通用模型”的升级亮点。你会看到,它在自主编程、视觉解析、长程任务记忆上的实质性飞跃;了解新增的“xhigh”努力程度和任务预算功能如何让开发者精细控制推理成本;也会直面其与未公开的“最强模型”Mythos 的差距,以及新版分词器导致 Token 消耗增加的争议。对于任何希望将 AI 真正用于金融分析、法律审查、复杂工程的人来说,Opus 4.7 都是一次值得认真评估的进化。
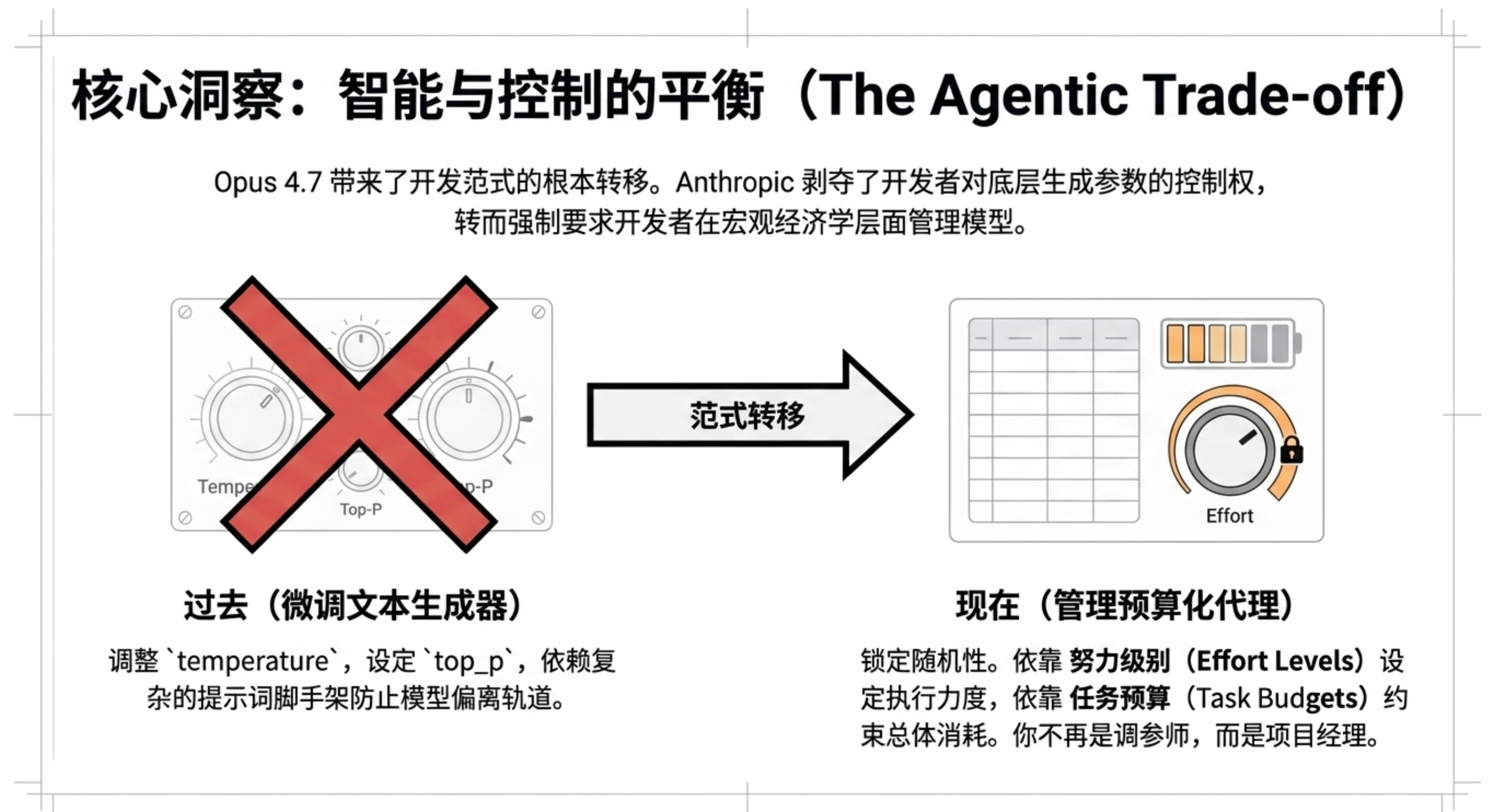
Claude Opus 4.7 不是一次“挤牙膏”式更新,而是向着高度自主 AI 代理迈出的实质性一步。它的视觉能力、长程任务处理和自我校验机制,为金融、法律、生命科学等专业领域打开了新的可能。当然,Token 成本的增加和桌面应用的稳定性问题,也提醒我们:每一次跃进都伴随着新的权衡。

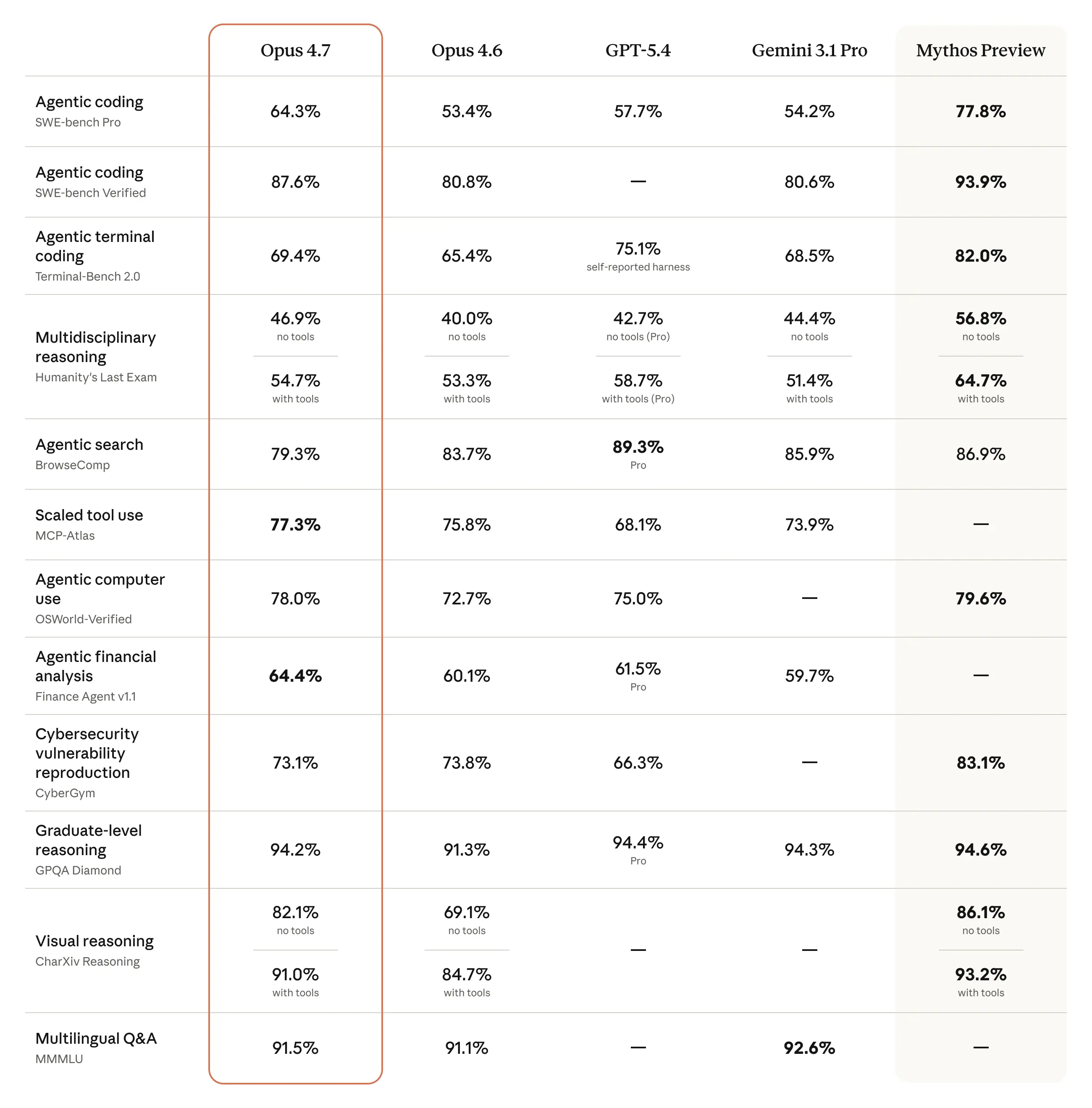
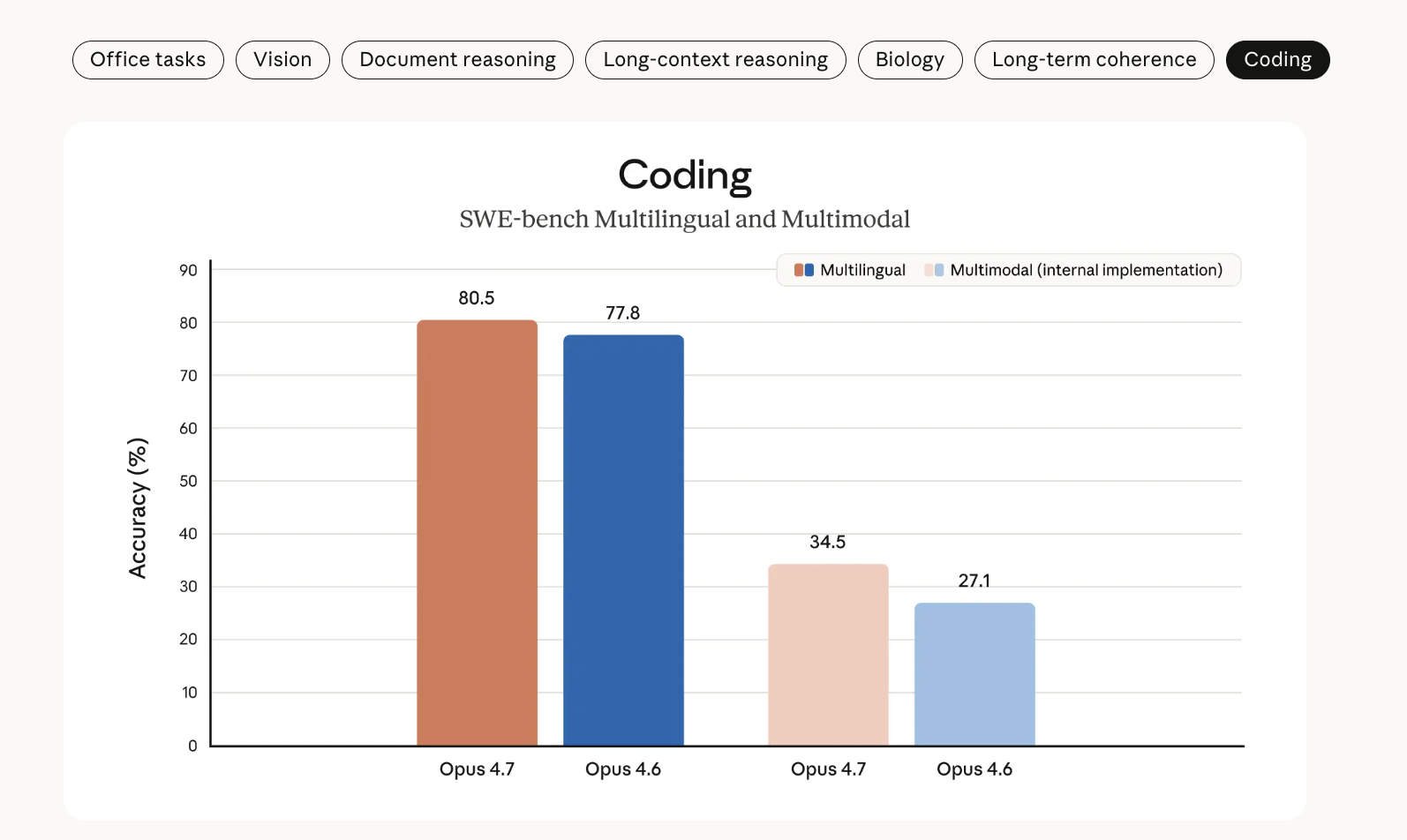
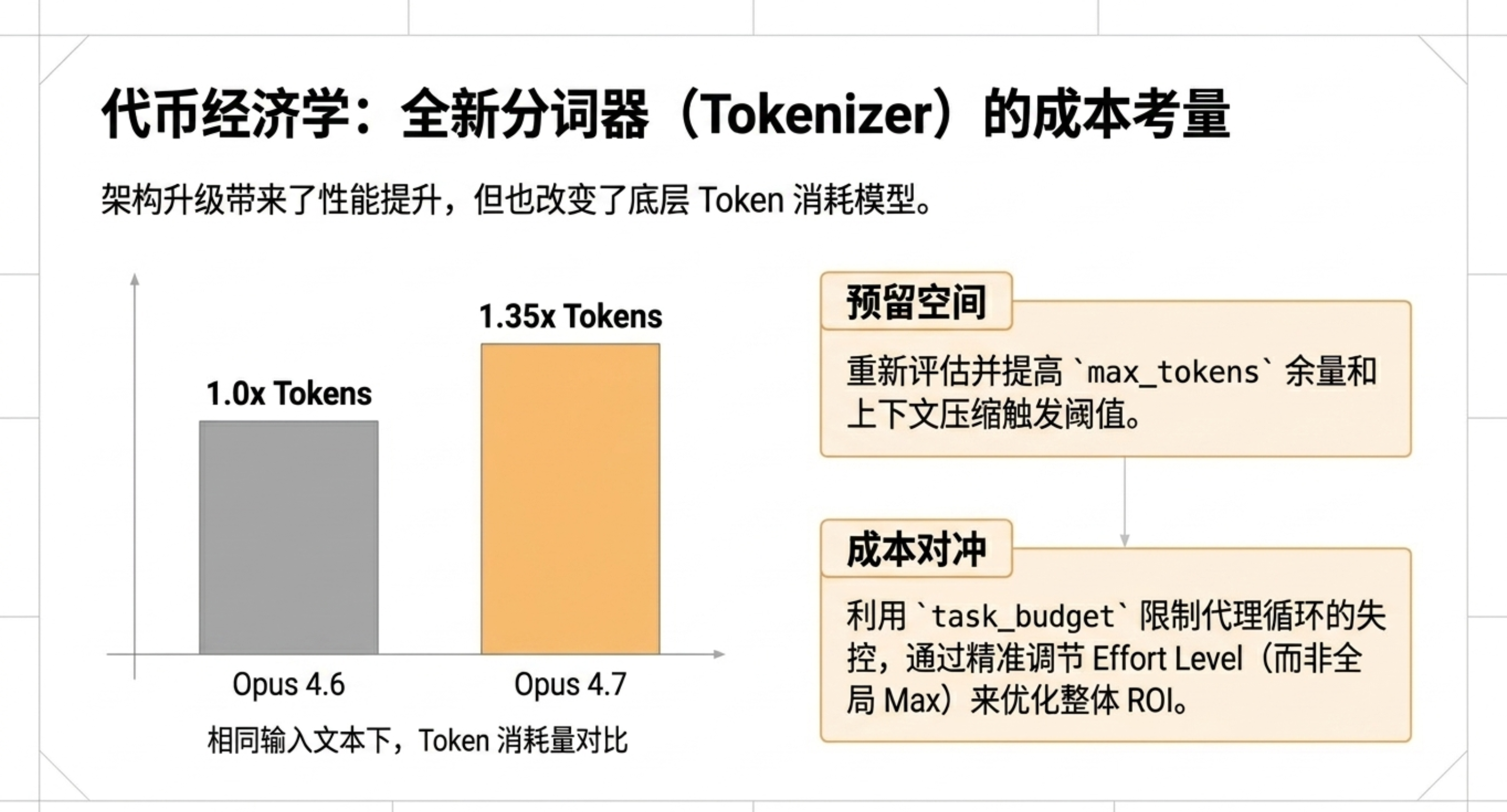
4.7 使用了新的分词器,token 使用成本比 4.6 高了 1 ~ 1.35 倍:

参考:
以下为主要内容的图文介绍:





📊 软件工程能力——从“53.4%”到“64.3%”的跨越
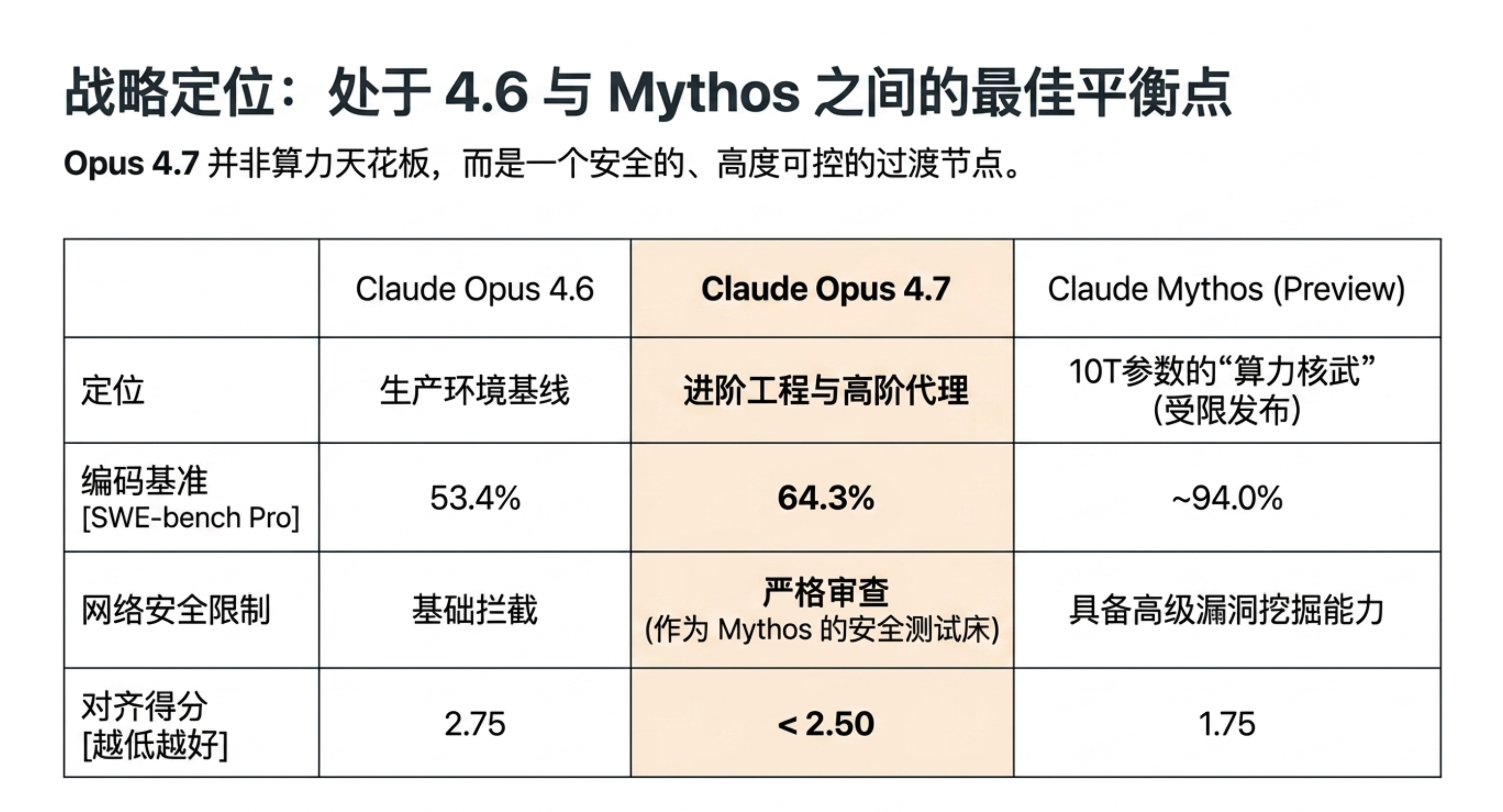
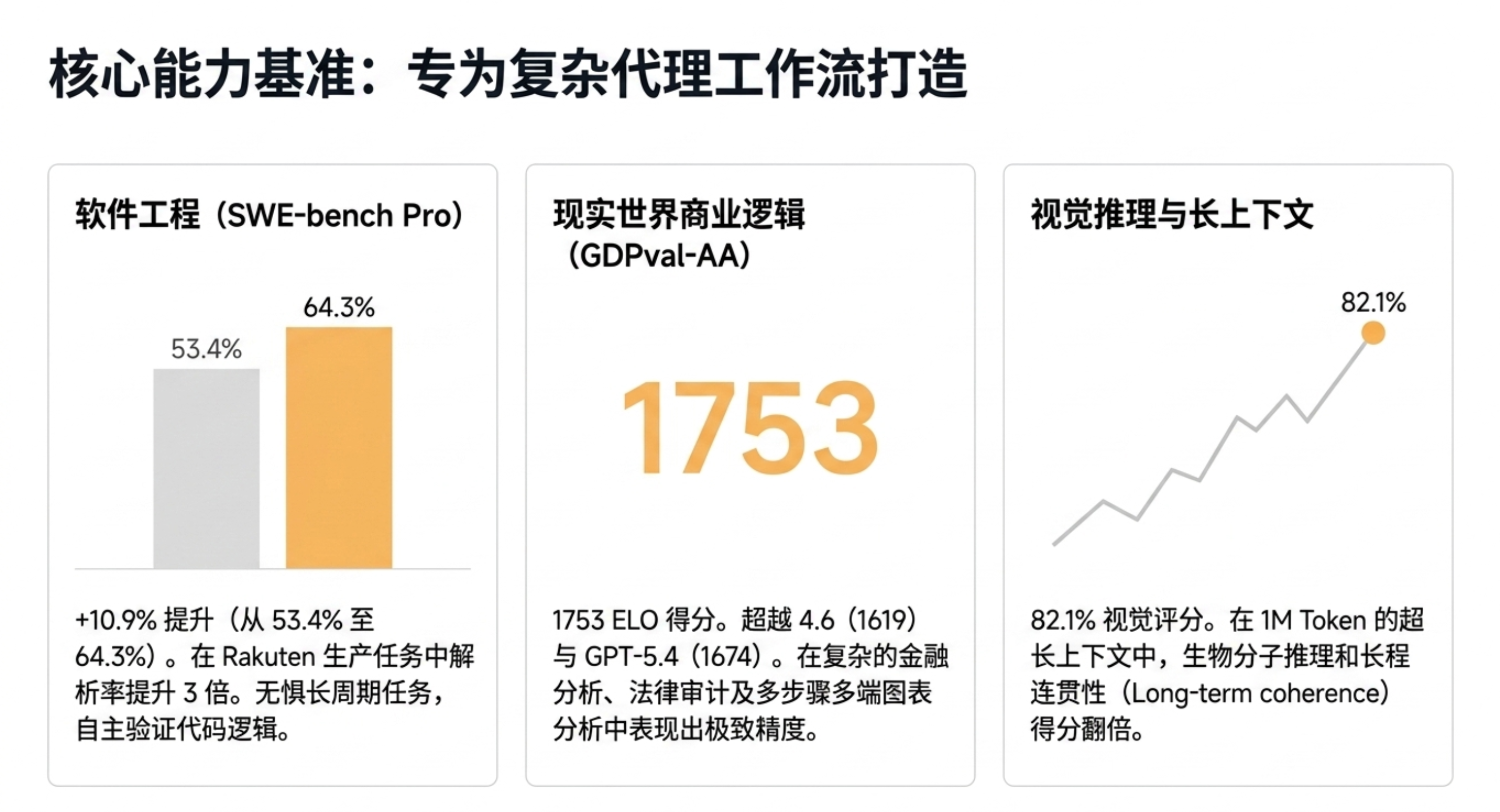
SW-bench Pro 基准:Opus 4.7 解决率从 4.6 版本的 53.4% 提升至 64.3%,增幅超过10个百分点。
自主长程任务:能够更独立地处理 Bug 修复、CI/CD 工作流、Rust 引擎构建等需要严谨逻辑和持久注意力的复杂工程。
自我校验能力:在规划阶段就能发现自身的逻辑错误,减少无效尝试,这是向真正自主代理迈进的关键一步。
🖼️ 视觉感知——分辨率翻三倍,看清每一个像素
分辨率提升:最高支持分辨率从1.15MP跃升至3.75MP(长边可达2576px)。
应用场景:能够精确读取复杂图表、高密度截图、扫描版PDF表格,甚至进行像素级的视觉任务。
文档处理:在金融报告、法律文书、科研论文的视觉解析上表现显著增强。
🧠 记忆与上下文管理——告别重复“自我介绍”
文件系统记忆:更好地利用草稿本、说明文件等外部记忆,能在长周期协作中记住重要笔记。
减少重复:不再需要每次对话都重新交代项目背景、偏好设置,模型会主动调用已存储的信息。
⚙️ 技术创新与 API 变更
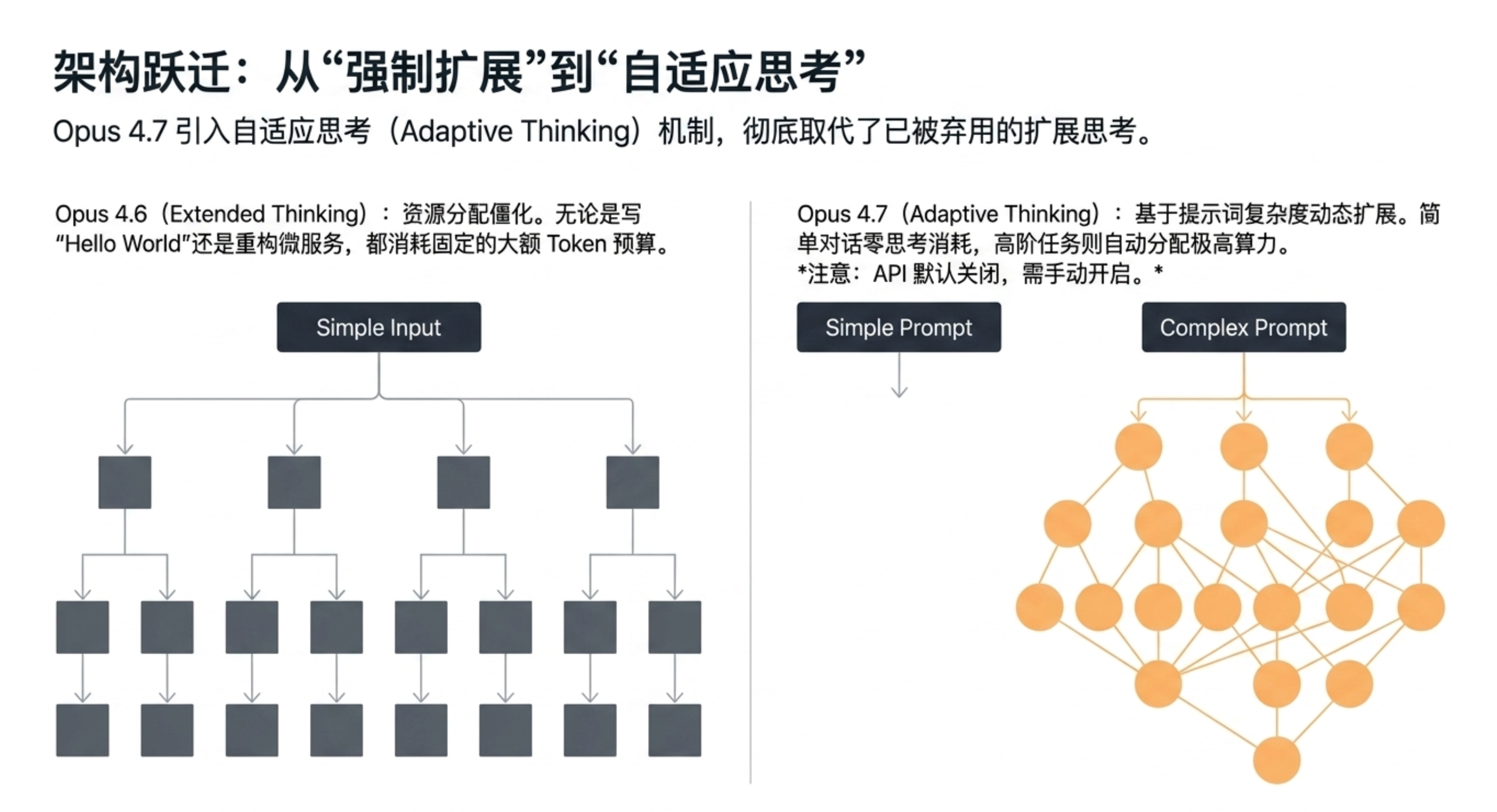
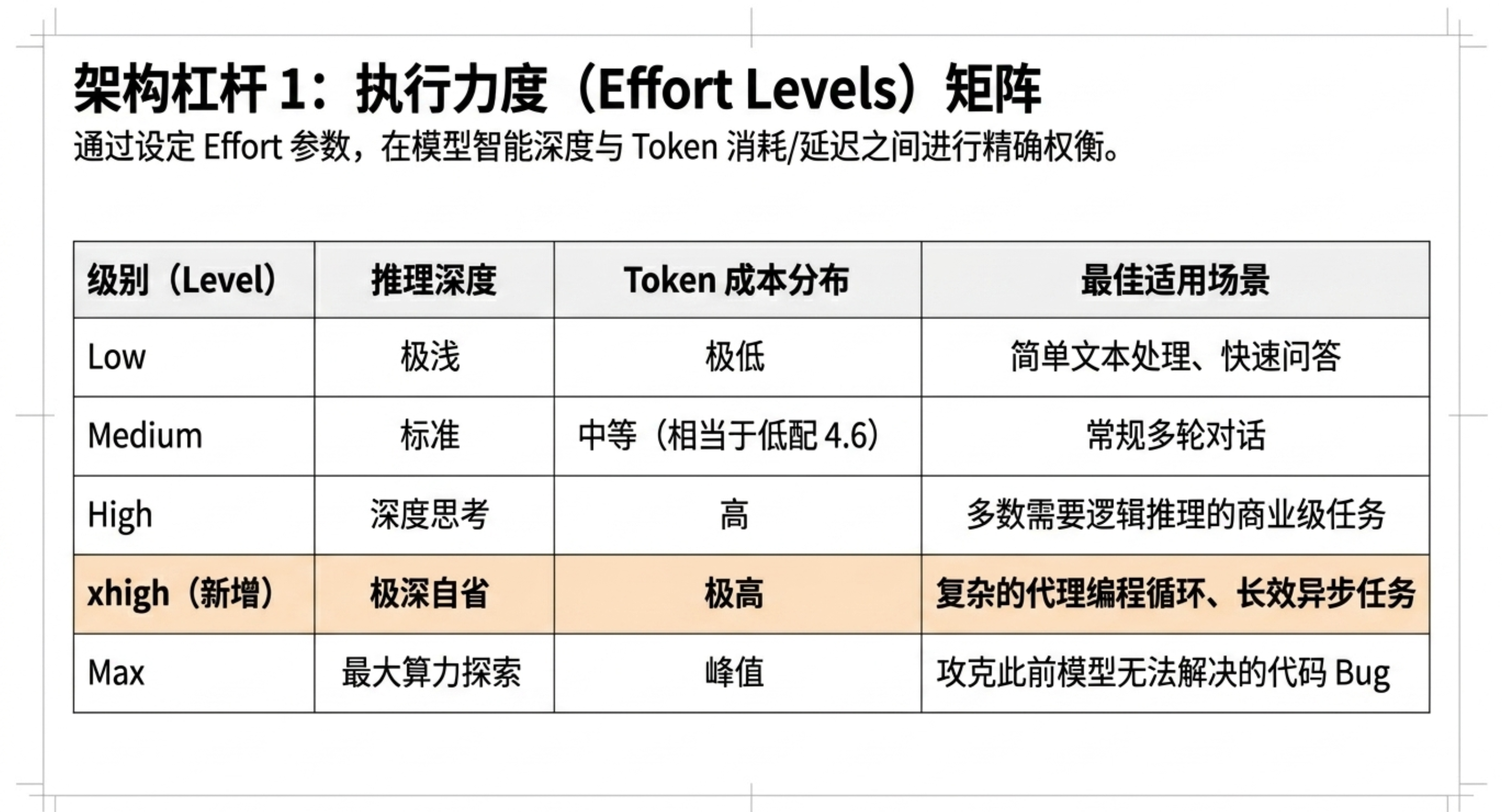
新增“xhigh”努力程度:在 coding 场景下官方推荐优先使用,提供更精细的推理深度与响应延迟平衡。
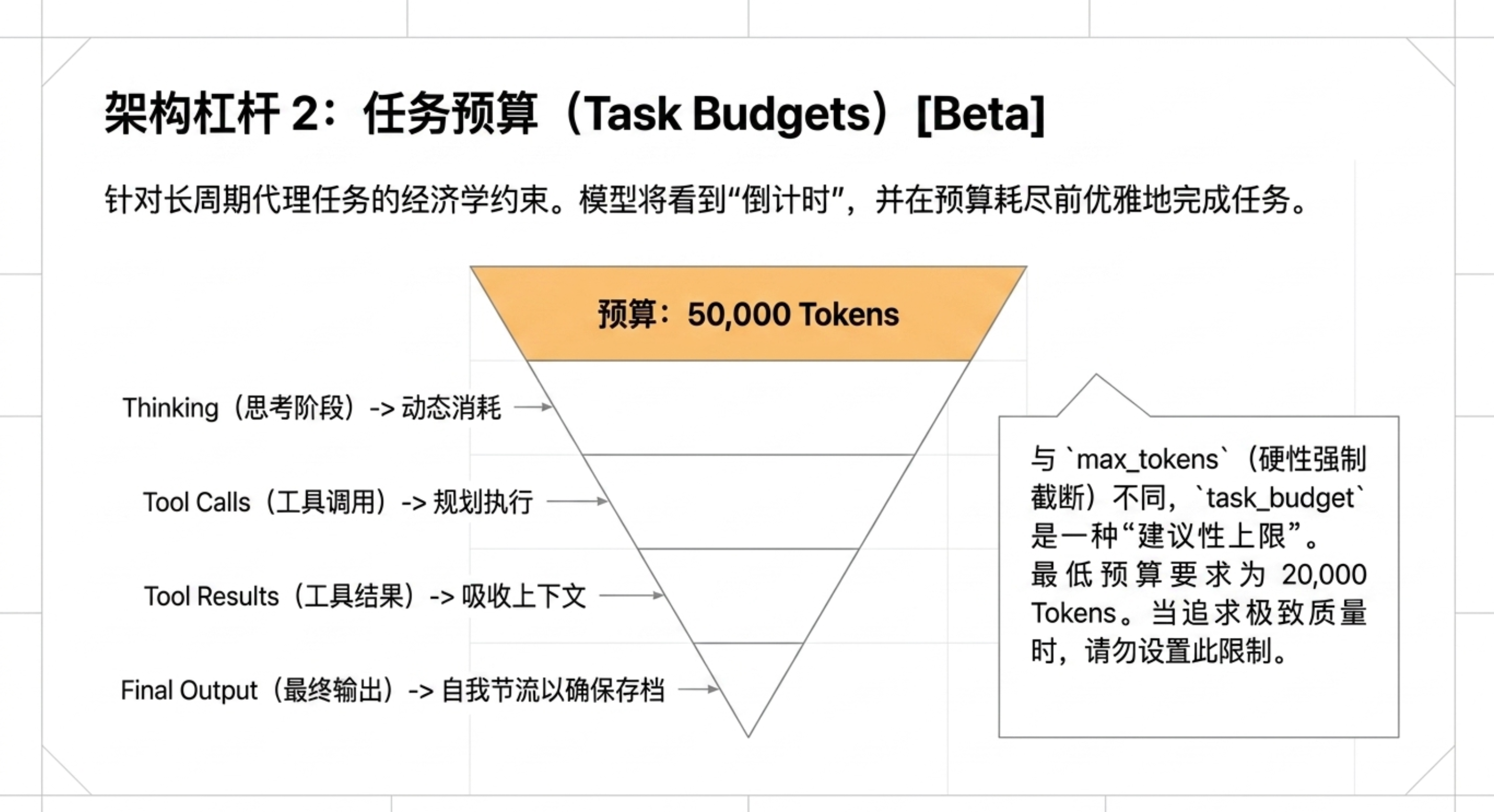
任务预算(测试版):为完整代理循环设置建议性 Token 预算,模型能在预算内优先处理核心工作并优雅结束。
自适应思考:移除了旧版的“扩展思考”模式,仅保留更优的自适应思考。
⚠️ 分词器更新:新算法提升了性能,但相同文本的 Token 消耗增加了1.0至1.35倍——开发者需重新评估成本。
🛡️ 第五章:安全性与市场定位
网络安全防护:新增实时检测与拦截机制,能自动阻断与高风险网络攻击相关的请求。
行为风格变化:模型变得更直接、有主见,减少了多余的表情符号和寒暄;同时更“字面化”地遵循指令,要求用户提示词更精确。
与 Mythos 对比:虽然 Opus 4.7 在各维度仍略逊于尚未广泛开放的“最强模型”Claude Mythos Preview,但在实际生产场景(金融、法律、跨工具协作)中已足够卓越。
💬 第六章:评价与争议
正面反馈:Vercel、Notion、Replit 等公司高管称其为“游戏规则的改变者”,尤其在自主性、错误恢复和复杂工具调用上。
争议:有观点质疑 Anthropic 是否曾刻意调低 4.6 的性能来衬托 4.7;同时新版桌面应用被曝存在较多 Bug,引发对 QA 流程的担忧。
