


 0
0 0
0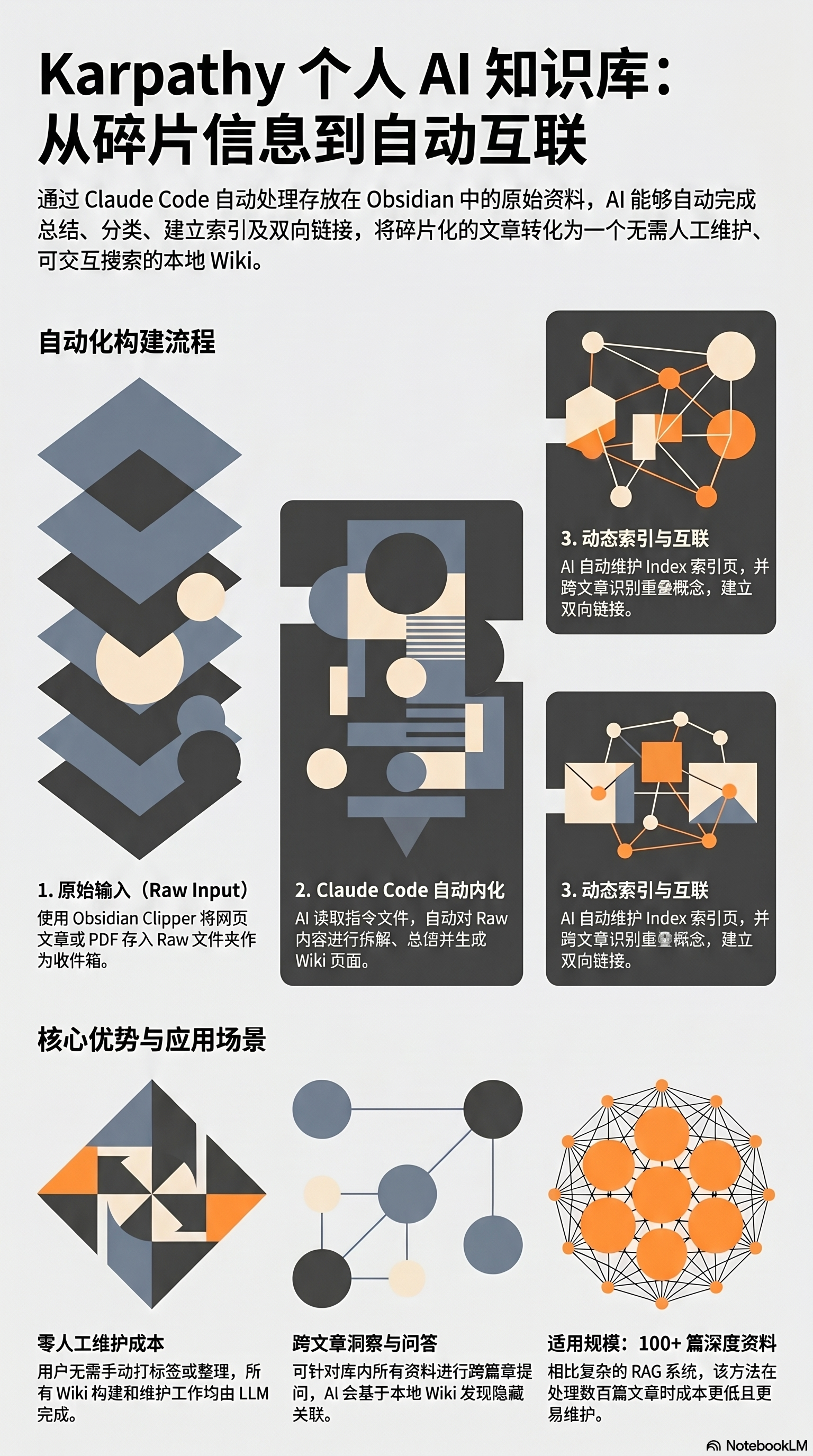
引言:终结“笔记黑洞”的数字化困境
你是否也曾陷入过“收藏从未阅读”的死循环?看到深度好文便如获至宝地存入 Notion、Obsidian 或书签栏,心想“以后一定会看”,结果它们最终都变成了数字化尘埃。这种“笔记黑洞”源于三大痛点:收藏即遗忘、笔记间缺乏深度联系,以及面对海量信息时手动整理的无力感。
最近,特斯拉前 AI 主管、OpenAI 联合创始人 Andrej Karpathy 在 X 平台上分享了一套引发硅谷技术圈热议的 AI 笔记方法论。这套方法彻底颠覆了传统的分类模式,其核心价值在于:让 AI 成为你知识库的首席执行官(CEO),而不仅仅是一个被动的搜索工具。
Takeaway 1:AI 领地——从“手动整理”到“全自动化”的范式转移
Karpathy 提出了一个极具挑衅性的观点:在 AI 时代,知识库不再需要人类亲力亲为地进行排版和分类。他认为,个人知识库应该是 LLM(大语言模型)的“私人领地”,人类应当从行政式的整理工作中彻底抽身。
在这种新范式下,你的唯一任务就是“喂料”。你只需将文章、PDF 或网页截图丢入 Raw 文件夹,剩下的拆解、总结、打标签以及建立逻辑链接的工作,全部交由 AI 自动完成。
“你几乎永远不需要自己编辑 Wiki,因为这是 LLM 的地盘——构建和维护它完全是 AI 的工作。”
这种“放手”给 AI 的做法,是现代知识工作者的最高级“生活黑客”行为:将低价值的归档劳动外包给算法,将高价值的思考与创作留给自己。
Takeaway 2:去数据库化——逻辑索引胜过数学相似度
与传统基于向量数据库的 RAG(检索增强生成)系统不同,Karpathy 的方案并未采用复杂的 Embeddings(嵌入)技术。相反,它构建在最纯粹的 Markdown 文件之上。
这是一种从“数学检索”到“逻辑推理”的跃迁。系统的灵魂在于由 AI 维护的 Index(索引页)。在传统 RAG 中,系统通过数学相似度寻找答案;而在 Karpathy 的系统中,AI 会像人类图书管理员一样,通过阅读 Index 目录来定位信息。
这种**基于索引的推理(Index-based Reasoning)**确保了系统在处理个人量级数据时,能够保持极高的逻辑严密性和运行速度,避免了向量检索中常见的“语义偏离”问题。
Takeaway 3:知识连接的“涌现”——可视化你的思维图谱
这套系统最令人兴奋的特质是它的“涌现性”(Emergence)。通过 Obsidian 的 Graph View(关系图谱),你可以直观地看到 AI 如何在不同文章之间穿针引线。
以硅谷思想家 Naval Ravikant 的两篇文章为例:一篇探讨“阅读是学习的基石”,另一篇研究“如何寻找特定知识”。在 AI 的处理下,它会自动识别出两者共同的底层逻辑——“持续学习”(Continuous Learning),并以此为一个共享节点(Shared Node),将两篇看似独立的笔记自动串联起来。
这种“自动连线”功能能帮你打破信息茧房,发现那些隐藏在文字背后的思维盲点,促使跨学科的灵感火花在你的本地硬盘里自发碰撞。
Takeaway 4:会“自愈”且“进化”的生命力知识图谱
Karpathy 的知识库并非静态的档案库,而是一个自我修正的数据闭环(Self-correcting data loop):
- 动态增长:当你向 AI 提问时,它生成的深度回答会被重新转化为 Wiki 页面存入系统。这意味着,你与 AI 交流越多,知识库就越厚实。
- 健康检查:AI 会定期对知识库进行“体检”,主动识别笔记中的逻辑矛盾或知识盲区,甚至会提醒你:“你在‘具身智能’领域的资料较薄弱,是否需要补充几篇相关论文?”
- 运行说明书:系统中关键的
claude.md文件是 AI 的“行动纲领”,它定义了数据组织的逻辑标准,确保 AI 每次运行都能保持高度的一致性。
落地指南:核心工具与架构
想要复刻这套顶级笔记系统,你需要以下三个工具:Obsidian(本地存储与可视化)、Claude Code(AI 自动化引擎)以及 Obsidian Clipper(网页抓取引擎)。
以下是 Karpathy 推荐的核心文件夹结构:
文件夹/文件
功能说明
Raw
素材收件箱:存放待处理的原始文件,内含 Assets 子文件夹存储图片。
Wiki
核心知识区:分为 Concepts (概念), Entity (人物/组织), Source (源文件摘要)。
Index
全库索引:AI 快速定位信息的逻辑地图。
Log
活动日志:追踪 AI 读了什么、改了什么,防止重复劳动。
claude.md
指令手册:定义 AI 的身份、规则及 Wiki 写作风格。
实操小贴士: 使用 Obsidian Clipper 浏览器插件,可以将任何网页一键推送到 Raw 文件夹,随后在终端调用 Claude Code 运行“Ingest”命令,即可见证知识库自动生长的奇迹。
适用边界与技术局限
作为一名效率专家,我必须指出该方法的现实边界:
- 成本压力:驱动 Claude Code 需要付费订阅计划,频繁的 API 调用会产生 Token 费用。
- 处理时效:该系统追求深度而非速度,每篇文章的深度分析可能需要几分钟。
- 规模限制:受限于 LLM 的 Context Window(上下文窗口),此方法最适合个人级的精选库(约 100-300 篇),若文档量过万,仍需回归传统 RAG 架构。
- Token 消耗:由于 AI 每次操作都需要读取 Index,随着知识库扩大,单次查询消耗的 Token 会逐步增加。
结语:从“数字化囤积”迈向“数字化思考”
Andrej Karpathy 分享的不仅是一个技术 Demo,更是一种全新的知识哲学:在这个 AI 触手可及的时代,“拥有信息”已毫无门槛,“处理信息”才是真正的竞争力。
这套方法将我们从繁琐的分类与标签中解放,让我们重新回归到思考本身。想象一下:如果你的笔记系统能在你每晚入睡时自动“思考”,并在清晨为你呈现出从未察觉的思维关联,你的学习效率将产生怎样的质变?
别再囤积了,现在就丢两篇文章进去,开启你的自进化知识之旅。
