

 1
1 0
0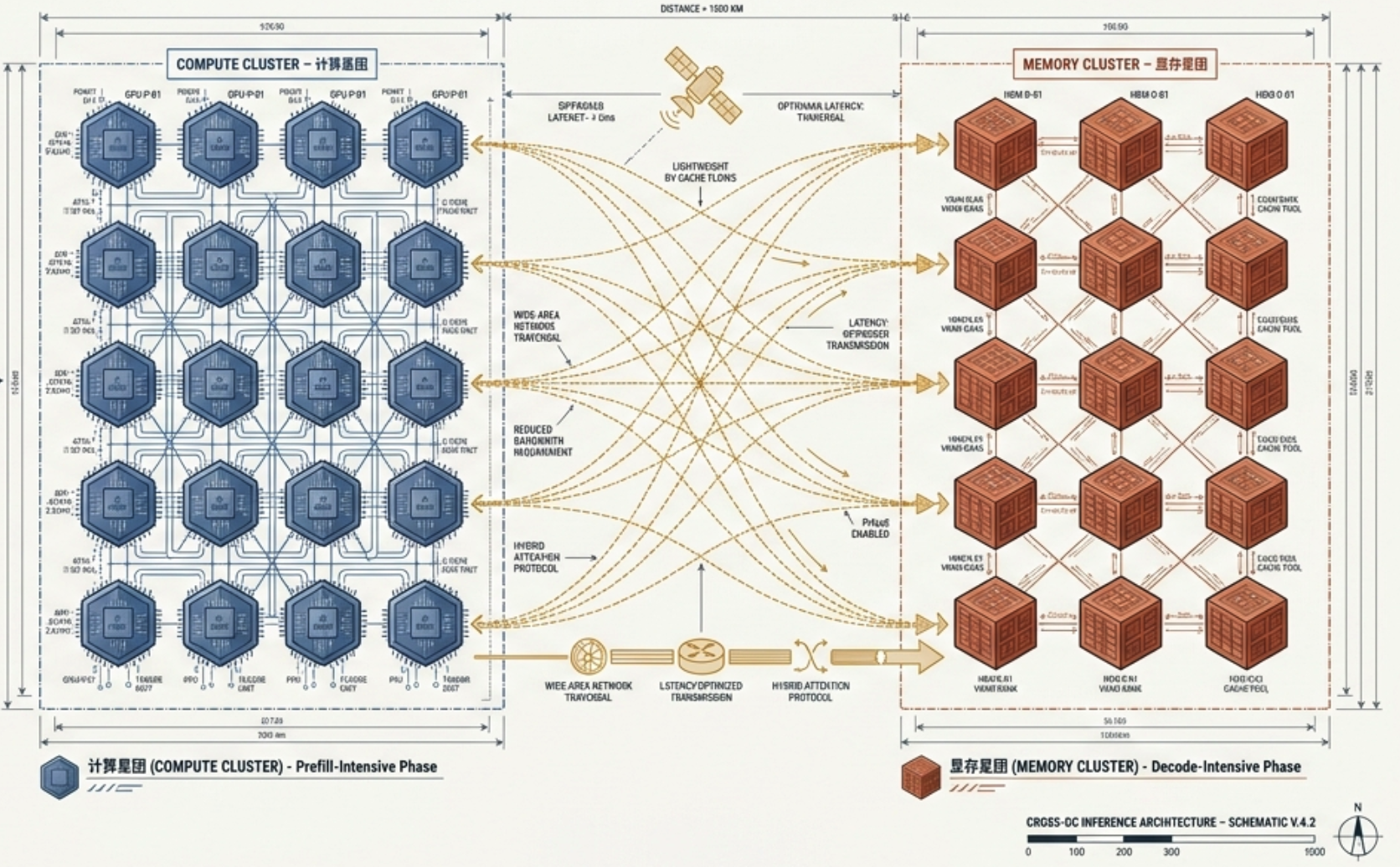
原文:链接
1. 引言:被“带宽墙”困住的AI算力
作为架构师,我们长期以来都面临一个极度奢侈的“烦恼”:为了让大模型推理的 Prefill(预填充)和 Decode(解码)阶段高效协同,我们被迫将昂贵的 GPU 资源锁进一个个昂贵的“RDMA 网络孤岛”中。在传统的 PD 分离(Prefill-Decode Disaggregation)架构下,机房的地理边界就是系统的物理极限。
核心矛盾在于:如果我们将预填充和解码跨中心、跨地域部署,那如洪水般涌出的 KVCache 数据传输成本,是否会瞬间撑爆网络带宽,让 TTFT(首字延迟)变得不可接受?这个困扰业界已久的“带宽墙”,正随着模型架构的范式转移而悄然崩塌。
2. 突破“带宽墙”:为什么 KVCache 不再是沉重的负担?
在稠密模型(Dense Models)统治的时代,跨中心传输 KVCache 简直是天方夜谭。衡量这一挑战的核心指标是 KV 吞吐量 (Phi-kv),其定义为:Phi_kv(l) = S_kv(l) / T_prefill(l)。
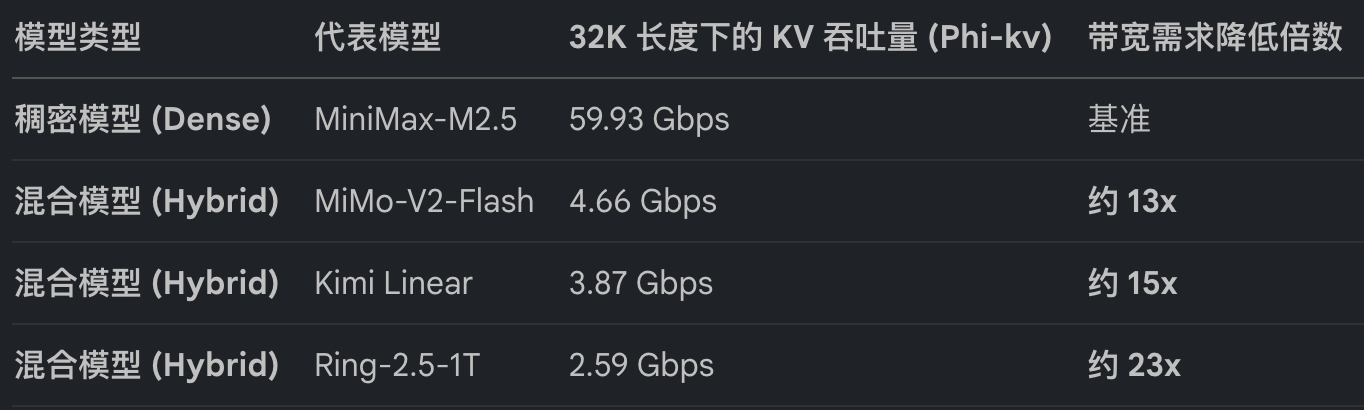
以稠密模型 MiniMax-M2.5 为例,当处理 32K 长度的上下文时,单个实例产生的 KV 吞吐量高达惊人的 60 Gbps。究其原因,是因为预填充耗时(T-prefill)在高性能算力下被压得很低,而产生的 KVCache 体积(S-kv)却随着长度线性爆炸。这种流量强度远超普通商用以太网的承载能力,使得预填充和解码节点必须像连体婴儿一样,死死捆绑在同个 RDMA 织网内。
但转折点已经出现:当带宽需求从“物理红线”降级为一个“可优化指标”时,大模型推理的地理边界就此消失了。
3. 混合注意力机制:模型架构带来的“免费午餐”
最近兴起的混合注意力架构(如 Kimi Linear, MiMo-V2-Flash, Ring-2.5-1T 等)正在从源头解决网络瓶颈。这些模型通过结合线性注意力(Linear Attention)或滑动窗口注意力(SWA)与少量全注意力层,实现了对 KVCache 的降维打击。
这里有一个关键的“Aha!”时刻: 传统全注意力的 KVCache 是“块级增长”的,会随序列长度无限拉伸;而线性注意力的状态(States)是“请求级固定”的。这意味着无论你的上下文是 10K 还是 100K,线性部分的缓存体积始终保持不变。这种特性直接发放了跨中心推理的“入场券”。
下表展示了 32K 上下文下,混合模型与传统模型在 KV 吞吐量上的鸿沟:
“KVCache 友好型模型架构是必要条件,但并非充分条件。真正让跨中心部署变得务实的原因,是模型侧的 KV 减负与系统侧的‘选择性卸载’策略的深度结合。” —— 这正是 PrfaaS 论文的核心洞察。
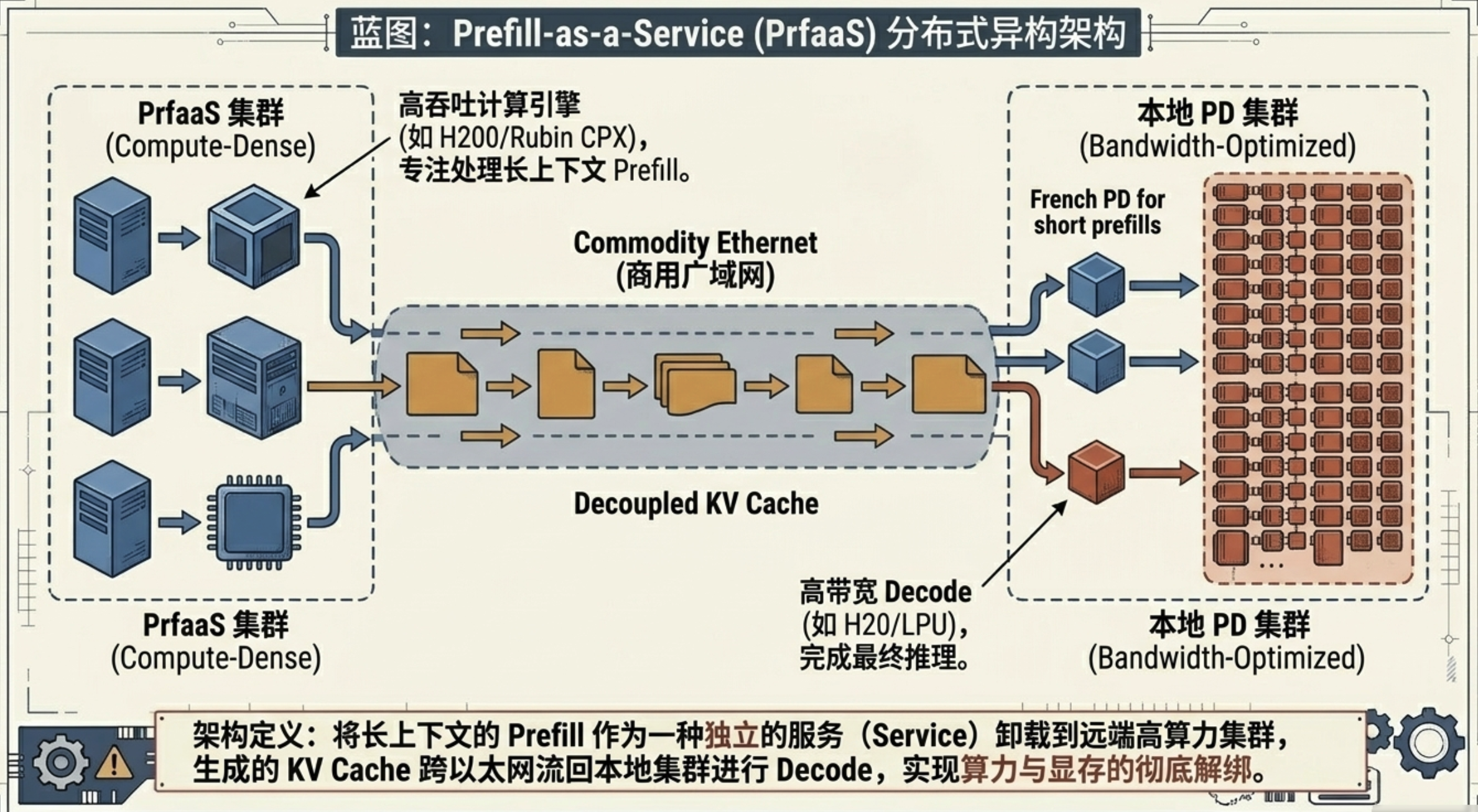
4. PrfaaS:像调用云服务一样处理 Prefill
基于此,Prefill-as-a-Service (PrfaaS) 架构应运而生。它不再强求所有算力同地部署,而是将预填充抽象为一种可跨区调用的云服务。
其精妙之处在于选择性卸载 (Selective Offloading)。系统不会盲目地将所有请求都送往远程,而是根据请求的“增量长度”设定阈值 t:
- 短请求: 留在本地处理,避免网络往返开销。
- 长请求: 路由至专门的 PrfaaS 集群。这些集群部署了高性能算力,利用普通商用以太网 (Commodity Ethernet) 传回生成的 KVCache。
这种设计完美契合了当前的硬件演进趋势:我们正进入一个“阶段专业化硬件”时代。例如 NVIDIA Rubin CPX 这种专为预填充设计的高算力芯片,可以与 Groq LPU 这种专为解码设计的高带宽芯片异地协同,不再受限于同一台服务器的物理空间。
5. 智能调度:不只是带宽,更是对资源的极限压榨
为了应对波动的网络和不均衡的请求,PrfaaS 引入了双时间尺度调度策略:
- 短期策略(带宽与缓存感知): 调度器不仅实时监控以太网链路的拥塞情况,更具备“缓存亲和性”识别能力。在路由前,它会检查本地 PD 集群是否已经存有该请求的 Prefix Cache。如果本地已有,则优先本地处理;只有当卸载带来的计算加速远超传输延迟时,才会执行跨中心调度。
- 长期策略(流量驱动分配): 这是一个动态的“角色置换”机制。根据长期的流量画像(如用户平均输入长度的漂移),系统会自动调整 PD 集群内部预填充节点(PD-P)与解码节点(PD-D)的数量比例,确保没有任何一个 GPU 会因为阶段性失衡而处于闲置状态。
6. 惊人的实测结果:效率提升 54% 背后的真相
在针对 1T 参数量级混合模型的实测中,研究者构建了一个极具代表性的异构战场:32 台远程 H200 (PrfaaS 集群) 支援 64 台本地 H20 (解码集群)。结果令人振奋:
- 吞吐量: 相比传统的同构 PD 部署,整体吞吐量提升了 54%。
- TTFT 优化: P90 首字延迟降低了 64%,长文本用户再也不用面对漫长的转圈等待。
- 带宽负荷: 在 100 Gbps 的链路上,跨中心流量仅占用了 13% (约 13 Gbps)。
这意味着,我们完全可以用性价比极高的非顶级算力(如 H20 等)作为解码节点,通过跨中心调用顶配 H200 的预填充服务,跑出远超“顶配全家桶”的效能。
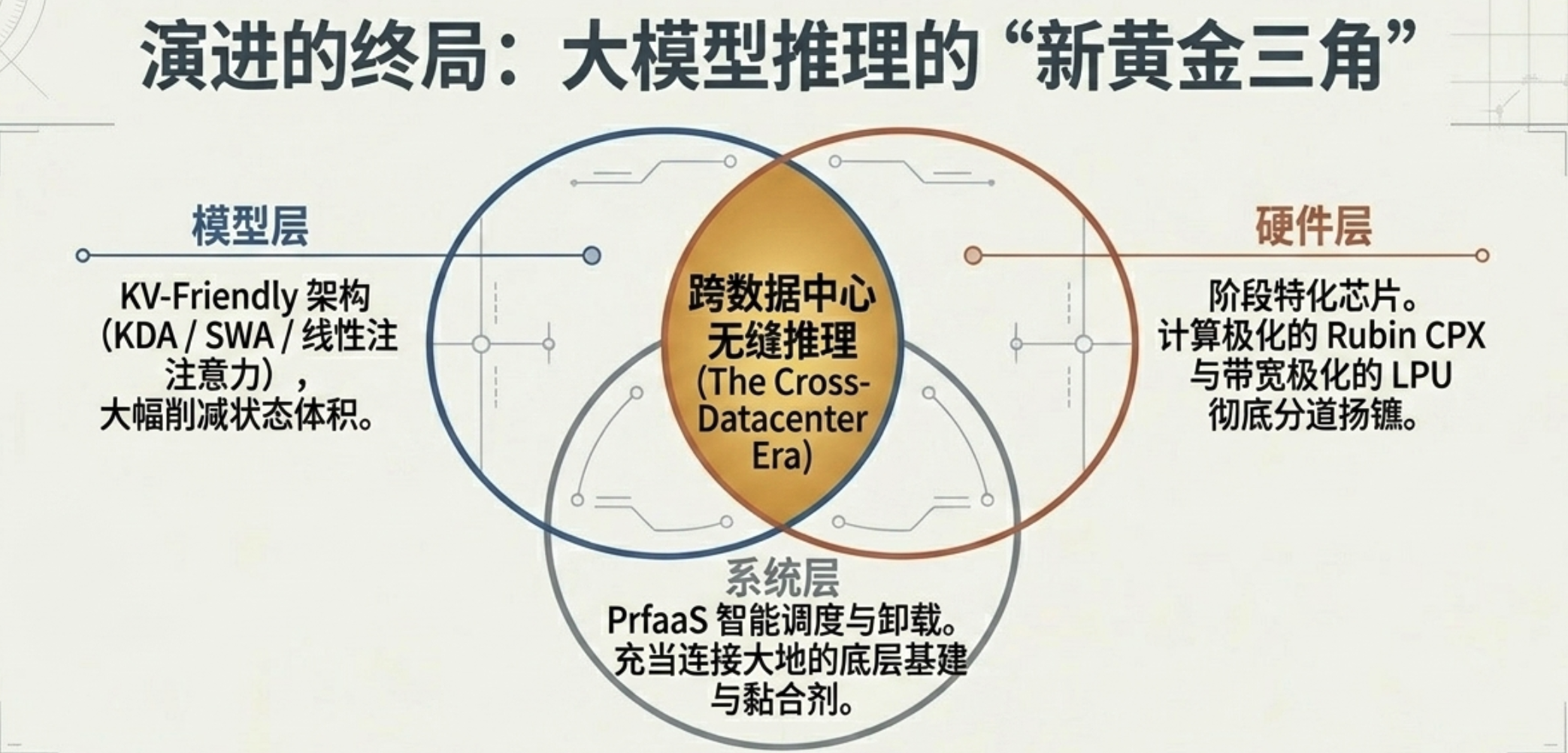
7. 结语:LLM 推理的地理去中心化想象
当模型架构的演进解决了“数据太大”的问题,而系统调度解决了“路不顺畅”的问题,算力将彻底摆脱机房的物理边界。PrfaaS 的成功预示着 LLM 推理正进入一个地理去中心化的新时代。
未来,预填充算力可能会像今天的水电煤一样,由大型算力工厂在电力低廉的区域集中供应,而解码节点则像 CDN 边缘节点一样,部署在离用户最近的地方。
互动思考题: 当 KVCache 可以跨越数千公里实时流动时,全球算力市场的游戏规则将会发生怎样的巨变?欢迎在评论区分享你的看法。
