

 0
0 0
0标题: Multi-View 3D Object Detection Network for Autonomous Driving
作者: Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia
arXiv ID: 1611.07759v3
日期: 2016-11-23
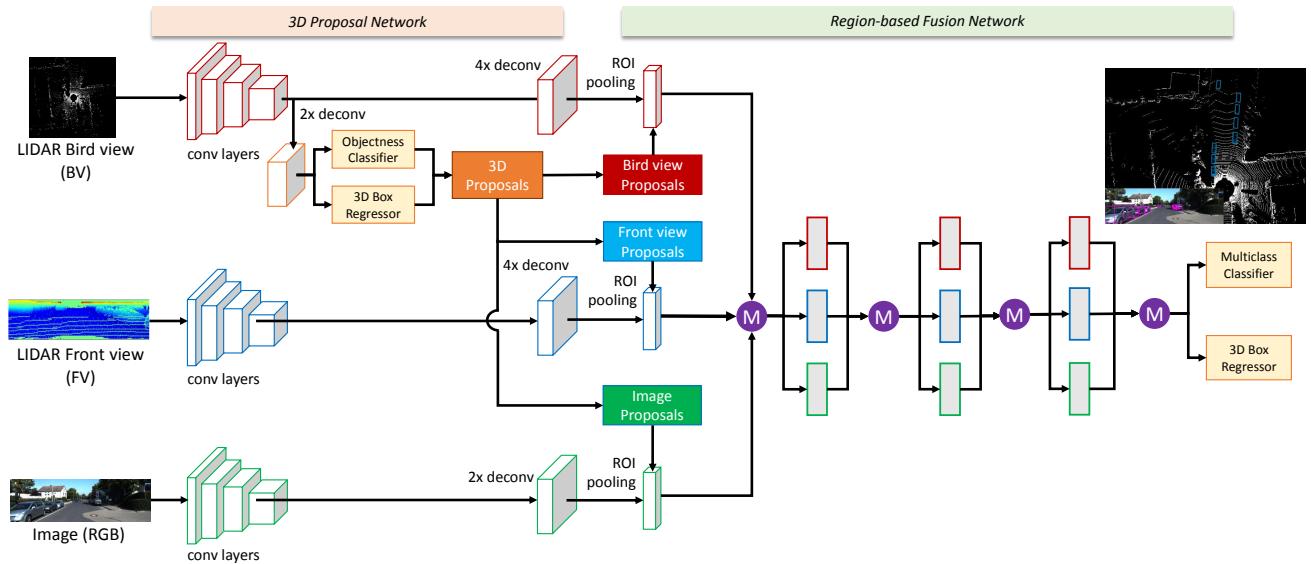
概要:论文提出MV3D框架,通过将稀疏3D点云编码为紧凑的鸟瞰图(BEV)和前视图表示,结合RGB图像输入,采用'先提候选、再融合精修'的策略解决自动驾驶场景下的3D目标检测问题。该方法首先基于BEV生成3D候选框,再通过深度融合机制交互三视角的中间层特征(而非简单的早期或晚期拼接),最终联合预测物体类别和带方向的3D边界框,实现了激光雷达几何精度与图像语义信息的有效互补。
主干流程:
多视角输入编码:将稀疏LIDAR点云投影并编码为鸟瞰图(BEV)和前视图(FV)两种紧凑的2D表示,同时接收RGB图像,构成三路基输入
3D候选框生成:基于鸟瞰图表示,利用2D RPN机制在3D空间中高效生成候选框(3D proposals),这些候选框可自然投影到任意视角
多视角特征提取:将3D候选框投影到鸟瞰图、前视图和图像平面三个视角,通过ROI池化提取各视图的固定长度区域特征向量
深度融合与预测:通过深度融合网络(deep fusion)在多个中间层交互三视角特征(element-wise mean),基于融合后的特征联合预测物体类别和带方向的3D边界框
声明:本节目论文解析与语音合成均由 AI 完成;解析内容基于本期解读时,该论文在 arXiv 上公开的对应版本;其中所有涉及原论文的图、数据均引用自原论文,如涉及侵权,请及时联系删除;AI 解读难免存在错误遗漏,如有发现欢迎联系修改;如需深入研究,建议阅读原文。
