

 0
0 0
0标题: PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
作者: Shaoshuai Shi, Chaoxu Guo, Li Jiang, Zhe Wang, Jianping Shi, Xiaogang Wang, Hongsheng Li
arXiv ID: 1912.13192v2
日期: 2019-12-31
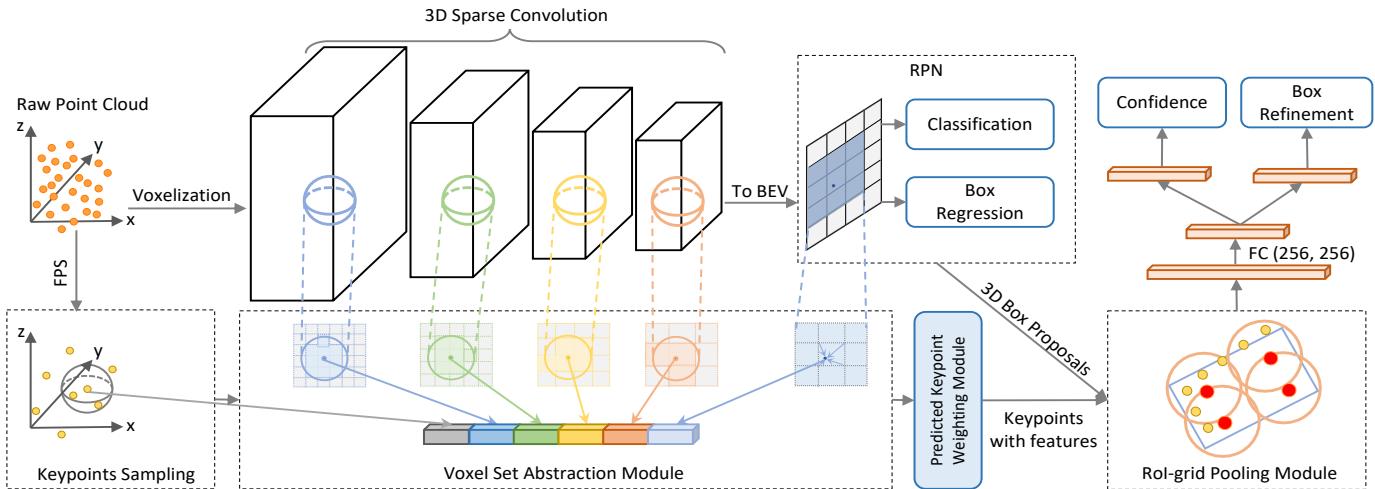
概要:PV-RCNN提出了一种深度融合 3D 体素 CNN 与 PointNet 集合抽象的两阶段检测框架,通过'体素编码-关键点抽象-网格池化'的三级流水线解决点云检测中效率与精度的平衡问题。该方法首先利用3D稀疏卷积高效提取多尺度特征并生成候选框,随后通过 Voxel Set Abstraction 模块将海量体素特征压缩到稀疏关键点,最后借助关键点向 RoI 网格的特征聚合实现细粒度框精修,既保留了体素CNN的计算效率,又获得了PointNet的灵活感受野和精确位置信息。
主干流程:
3D稀疏卷积编码与候选框生成:将原始点云体素化后输入3D稀疏卷积编码器,学习多尺度语义特征并生成高质量的 3D 目标候选框
体素到关键点场景编码:通过 Voxel Set Abstraction 模块将多尺度体素级特征体积总结为一小组关键点,聚合局部几何与语义上下文形成紧凑的场景表示
关键点到网格RoI特征抽象与精修:在每个候选框内采样RoI-grid点,将关键点特征聚合到这些网格点,基于丰富的上下文信息完成置信度预测和框回归精修
声明:本节目论文解析与语音合成均由 AI 完成;解析内容基于本期解读时,该论文在 arXiv 上公开的对应版本;其中所有涉及原论文的图、数据均引用自原论文,如涉及侵权,请及时联系删除;AI 解读难免存在错误遗漏,如有发现欢迎联系修改;如需深入研究,建议阅读原文。
