


 242
242 3
3摘要
DeepSeek-V4 系列标志着大语言模型在超长文本处理效率上的重大突破。通过引入混合注意力架构、流形约束超连接以及优化后的训练与推理基础设施,DeepSeek-V4 在支持 100 万 token 上下文的同时,显著降低了计算成本和显存占用。DeepSeek-V4-Pro-Max 作为该系列的顶级版本,在多个核心任务上重新定义了开源模型的状态。
DeepSeek-V4 系列包括 DeepSeek-V4-Pro(1.6T 总参数,49B 激活)和 DeepSeek-V4-Flash(284B 总参数,13B 激活)。其核心突破在于将传统注意力的二次计算复杂度瓶颈转化为高效的百万级上下文处理能力。在 100 万 token 设置下,DeepSeek-V4-Pro 仅需 DeepSeek-V3.2 推理算力(FLOPs)的 27% 和 KV 缓存的 10%。在性能方面,DeepSeek-V4-Pro-Max 在知识、推理和编程领域展现了极强的竞争力,显著优于现有的开源模型,并在多个维度上逼近甚至超越了顶级闭源模型(如 GPT-5.4-xHigh 和 Gemini-3.1-Pro)。
1. 模型架构与关键创新
DeepSeek-V4 继承了 DeepSeek-V3 的混合专家模型(MoE)框架和多 token 预测(MTP)策略,并引入了三项关键架构升级:
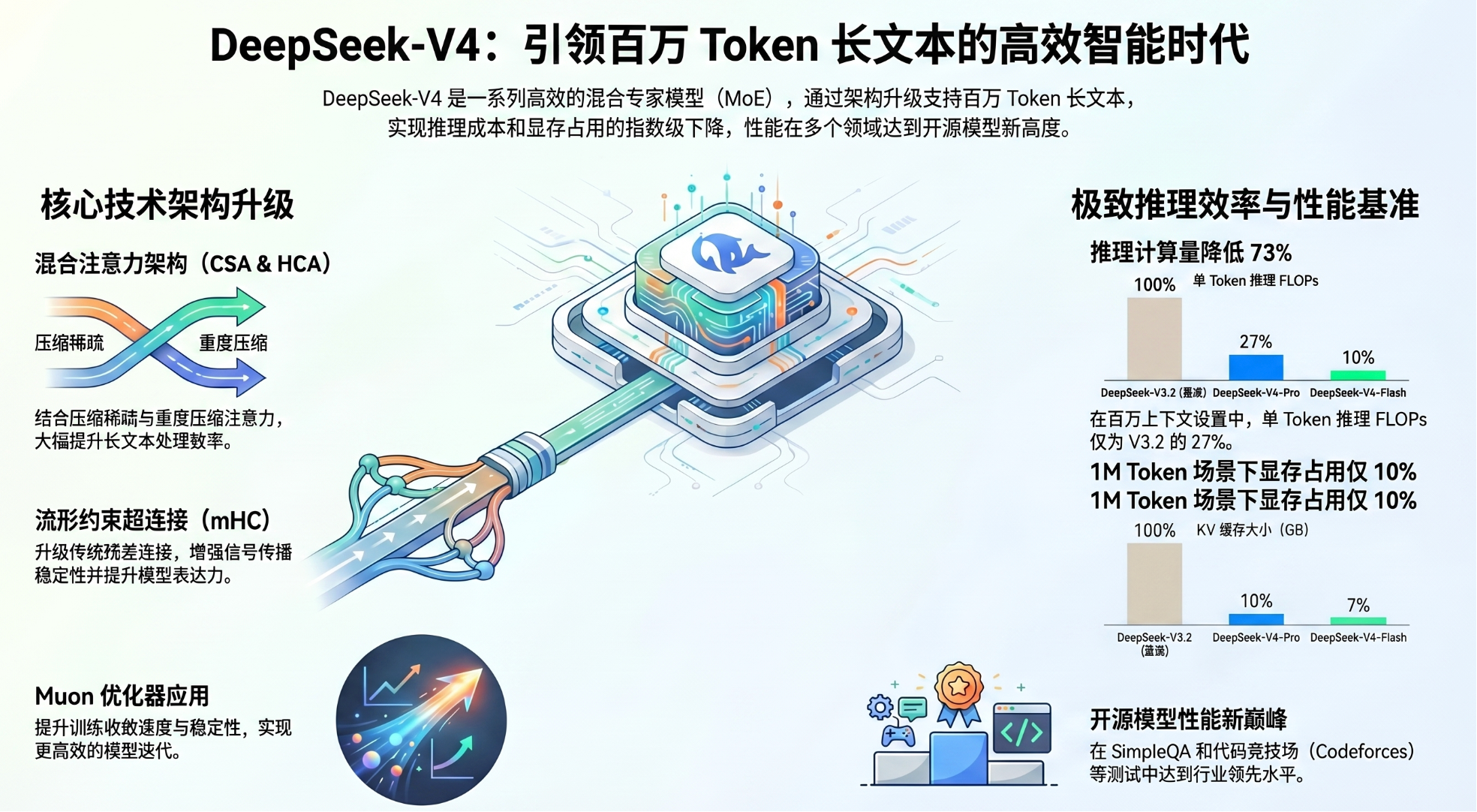
1.1 混合注意力架构(CSA 与 HCA)
为了打破超长上下文的效率壁垒,DeepSeek-V4 采用了压缩稀疏注意力(CSA)与重度压缩注意力(HCA)的交替混合配置。
压缩稀疏注意力 (CSA):
机制: 将每 m 个 token 的 KV 缓存压缩为 1 条目,随后应用深度求索稀疏注意力(DSA),使每个查询 token 仅访问 k 个压缩后的 KV 条目。
优势: 在保证性能的同时,大幅缩减了序列维度的 KV 缓存负担。
重度压缩注意力 (HCA):
机制: 采用更激进的压缩率 m′(m′≫m),将大量 token 整合为单个条目,但保持密集(Dense)注意力模式。
局部增强: 两种机制均配备了滑动窗口注意力 (SWA) 分支,以精确建模局部细粒度依赖。
1.2 流形约束超连接 (mHC)
DeepSeek-V4 引入了 mHC 以强化相邻 Transformer 块之间的残差连接。
流形约束: 将残差映射矩阵 Bl 约束在双随机矩阵流形(Birkhoff 多面体)上。
稳定性: 该约束确保了映射矩阵的谱范数有界,极大地增强了深层堆叠时的信号传输稳定性和模型表达能力。
1.3 Muon 优化器
除了 Embedding、RMSNorm 和 mHC 的静态偏置外,全量模块均采用 Muon 优化器。
正交化: 采用混合 Newton-Schulz 迭代(共 10 次迭代)实现权重的近似正交化,显著加快了模型的收敛速度并提升了训练稳定性。
2. 效率与基础设施优化
DeepSeek-V4 实现了全栈式的工程优化,确保在极长上下文场景下的实用性。
2.1 推理与计算效率
在 100 万 token 上下文场景中,与 DeepSeek-V3.2 相比:

FP4 量化感知训练 (QAT): 对 MoE 专家权重和 CSA 索引器路径应用 FP4 量化,大幅减少内存流量。
磁盘 KV 缓存: 针对共享前缀请求,引入磁盘存储策略,支持多种缓存策略(如全缓存、定期检查点、零缓存重计算)以平衡存储与算力。
2.2 专家并行与通信重叠
开发了 MegaMoE 融合算子,将 MoE 的 Dispatch/Combine 通信与 GEMM 计算完全重叠。
波次调度: 通过细粒度的专家波次划分,计算与通信持续并发,在通用负载下实现 1.50x 至 1.73x 的加速。
3. 训练与后训练流程
3.1 预训练数据与规模
数据量: 训练于超过 32T(Flash 版)和 33T(Pro 版)的高质量多元 Token。
策略: 逐步扩展序列长度,从 4K 提升至 16K、64K,最终达到 1M。
稳定性控制: 引入预知路由 (Anticipatory Routing) 和 SwiGLU Clamping 技术,有效抑制了训练过程中的损失尖峰(Loss Spikes)。
3.2 专家演进与策略内蒸馏 (OPD)
领域专家培养: 针对数学、代码、智能体等领域分别进行监督微调(SFT)和强化学习(RL,采用 GRPO 算法)。
生成式奖励模型 (GRM): 弃用标量奖励模型,利用模型自身的逻辑进行评估,实现评估能力与生成能力的同步优化。
策略内蒸馏 (OPD): 采用多教师、全词表逻辑分布蒸馏,将多个领域专家的能力合而为一,避免了传统权重合并带来的性能损耗。
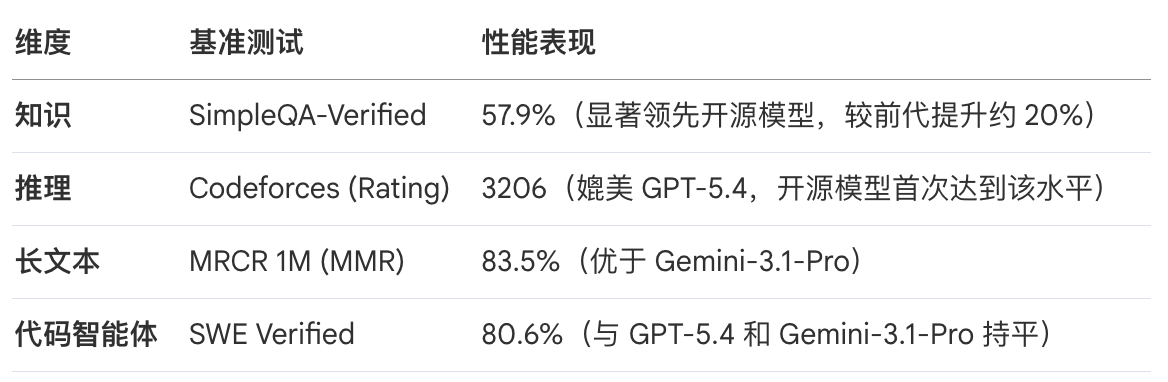
4. 性能评估结果
4.1 核心基准测试
DeepSeek-V4-Pro-Max 在多个维度展现了卓越性能:
4.2 真实世界任务
中文写作: 在功能性写作上以 62.7% 的胜率击败 Gemini-3.1-Pro;在创意写作的质量上胜率达到 77.5%。
白领办公: 在深度信息分析、文档生成等 30 项专业任务中,DeepSeek-V4-Pro-Max 的非负胜率(胜+平)达到 63%,显著优于 Opus-4.6-Max。
搜索增强: 引入智能体搜索 (Agentic Search),通过迭代调用工具,在复杂 Q&A 任务中显著优于传统的检索增强生成(RAG)。
5. 智能体功能增强
交替思考 (Interleaved Thinking): 针对智能体场景,模型在工具调用回合中保留完整的思考链路(Thinking Traces),无需跨轮次重新构建解题状态,充分利用 1M 上下文优势。
快速指令 (Quick Instruction): 在对话前缀中添加特定特殊 token(如
<|query|>、<|action|>),利用已有的 KV 缓存并行执行辅助任务(如搜索意图识别),极大降低了首 token 延迟。DSec 沙箱: 建立了弹性计算平台,支持每集群数十万并发沙箱实例,通过预取加载和故障容错机制确保智能体执行的安全性与稳定性。
6. 结论与未来方向
DeepSeek-V4 系列通过突破性的架构设计,开启了开源模型百万级长文本的新纪元。尽管目前的架构由于集成了多种验证性组件而略显复杂,但其在推理算力与内存占用上的巨大节省为未来的测试时缩放(Test-time Scaling)和在线学习奠定了基础。
7. 局限性与改进:
预知路由和 SwiGLU 钳位的底层原理仍需深化研究。
未来将探索 Embedding 模块的稀疏化,进一步优化多模态能力与长程智能体任务的鲁棒性。
📺播客说明
本播客采用虚拟主持人进行播客翻译的音频制作,因此有可能会有一些地方听起来怪怪的。如想了解更多信息,请关注微信公众号"西经东译"获取AI最新资讯。如有后续想要听的其他外文播客,也欢迎联系微信:mayday2303。


