

 4
4 0
0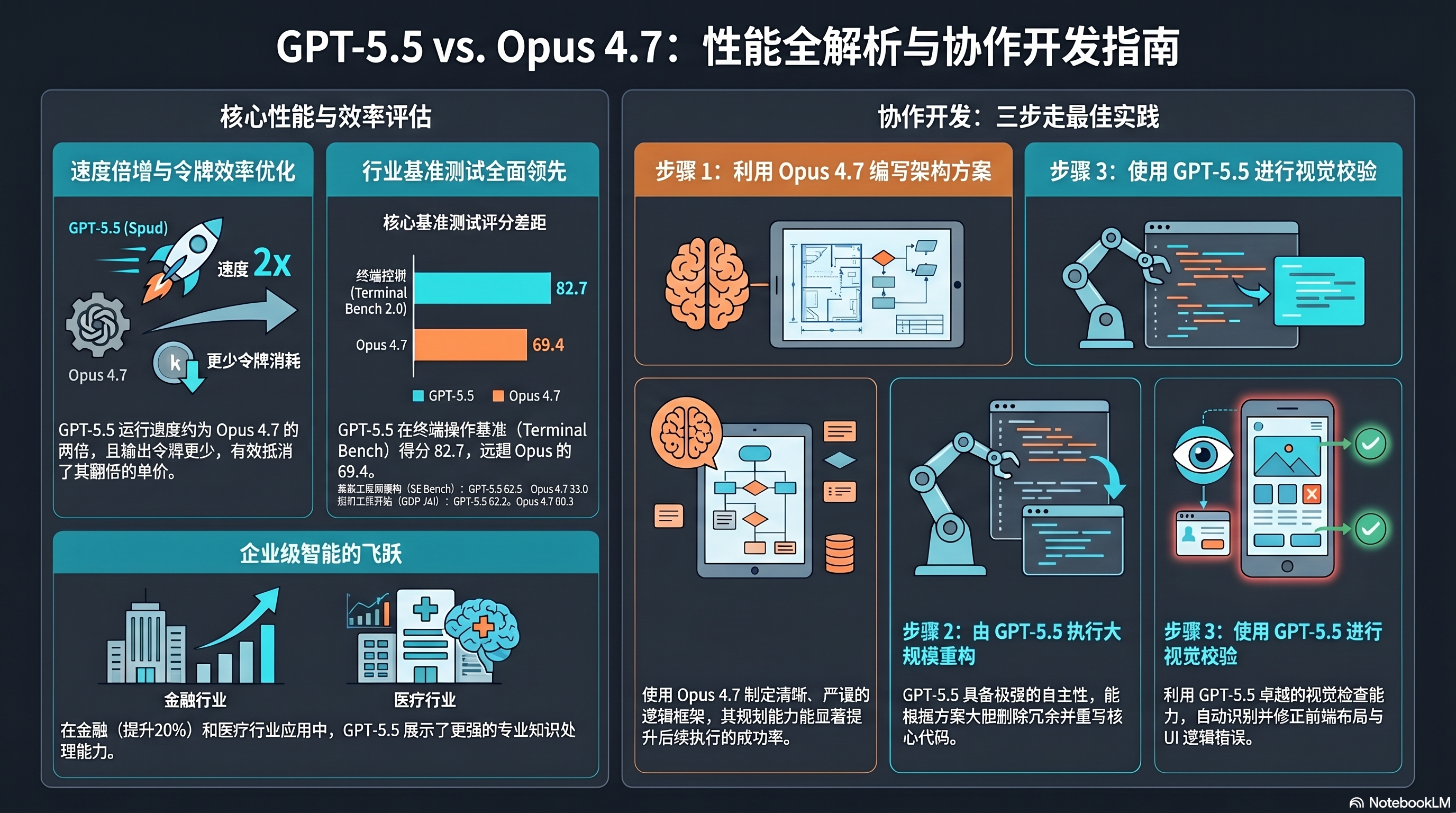
当 GPT-5.5 的终端操作得分飙至 82.7,远超 Opus 4.7 的 69.4;当它在高级工程师基准上拿下 62.5 分,而对手只有 30 分——AI 编程竞赛的格局正在被重新定义。但更令人惊讶的是成本逻辑:GPT-5.5 单价翻倍,却因极高的令牌效率,让总支出反而低于前代和竞品。
本期内容将深度剖析 OpenAI 最新旗舰模型 GPT-5.5(代号“Spud”),并与 Anthropic 的 Claude Opus 4.7 展开全面对比。你会看到,GPT-5.5 如何以“从零重构”的魄力碾压“打补丁”式编程;为何最佳工作流变成“用 Opus 写计划,用 GPT-5.5 执行”;以及它在金融、医疗等企业级场景中高达 20% 的准确率提升。当然,100万 token 的上下文窗口之殇和审美直觉的差距,依然让 Claude 在某些领域保有“上限”。这是一场关于自主智能体未来的关键战役。

GPT-5.5 展现了从“辅助工具”向“自主智能体”的进化。它用更高的单价换来了更低的实际成本,用从零重构的魄力重新定义了 AI 编程。而 Claude Opus 4.7 仍是规划和上下文的王者。最佳实践或许就是:让 Opus 思考,让 GPT-5.5 行动。
参考:
以下为主要内容的图文介绍:






📊 基准测试——终端操作、数学与专业领域全面领先
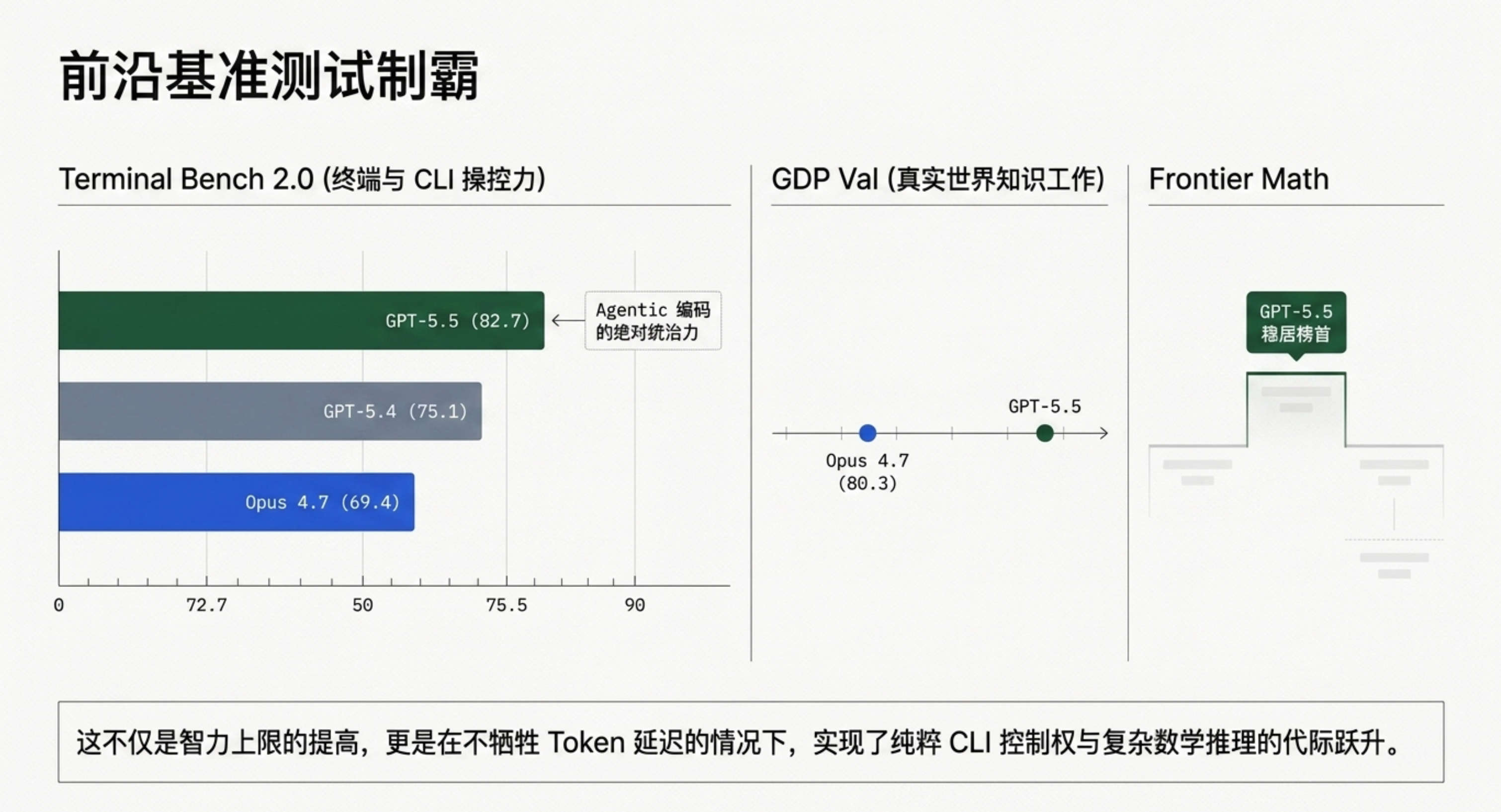
Terminal Bench 2.0:GPT-5.5 得分82.7,远超 GPT-5.4(75.1)和 Claude Opus 4.7(69.4)。
Frontier Math:排名第一,数学推理能力代际领先。
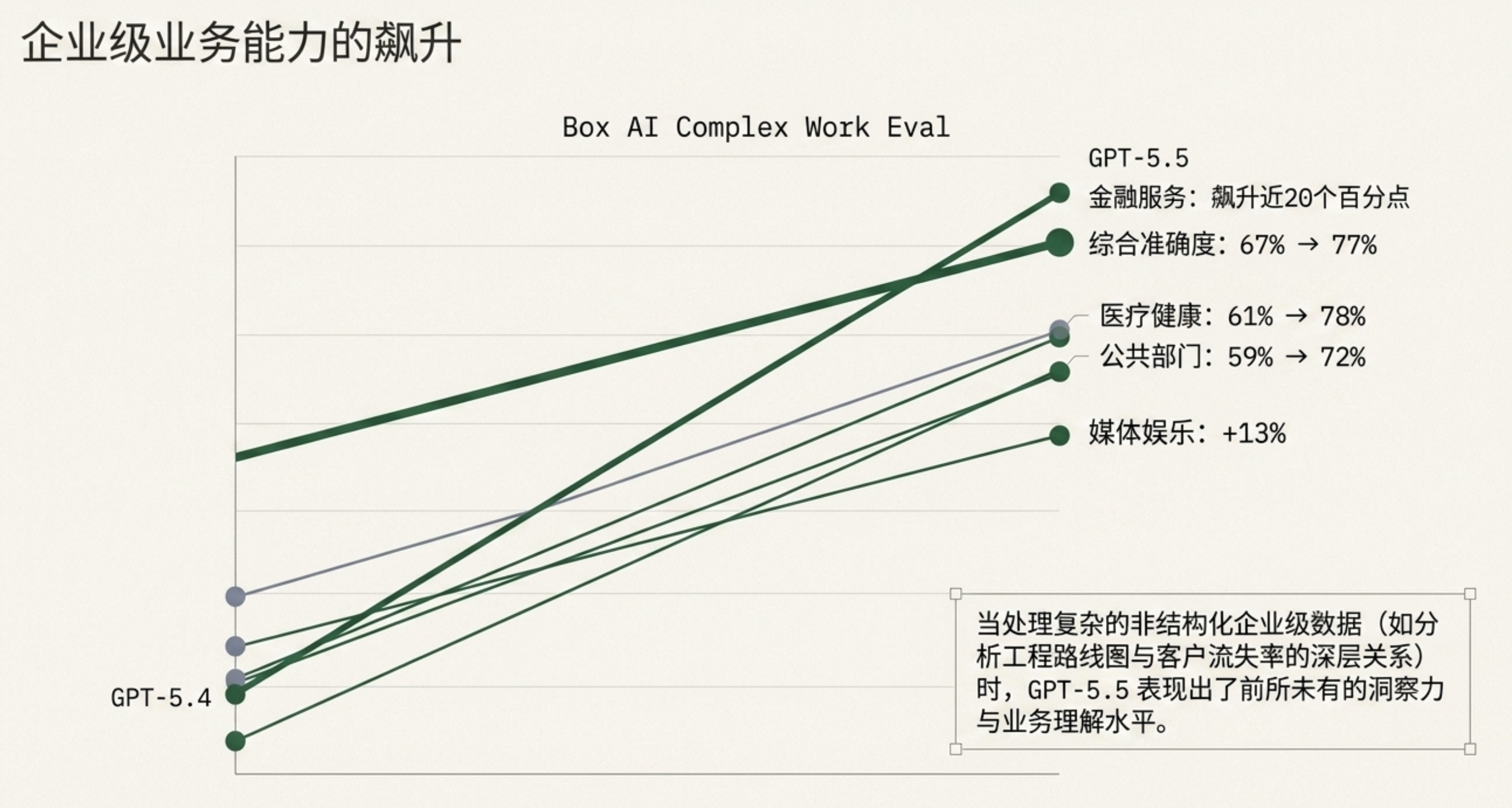
企业级应用(Box AI 测试):
金融服务:准确率提升近20%
医疗保健:从61%升至78%
公共部门:提升13%
媒体娱乐业:显著增长
网络安全(Cyber Gym)与通用知识工作(GDP Val):均优于竞争对手。
🧠 编程革命——从“打补丁”到“从零重构”
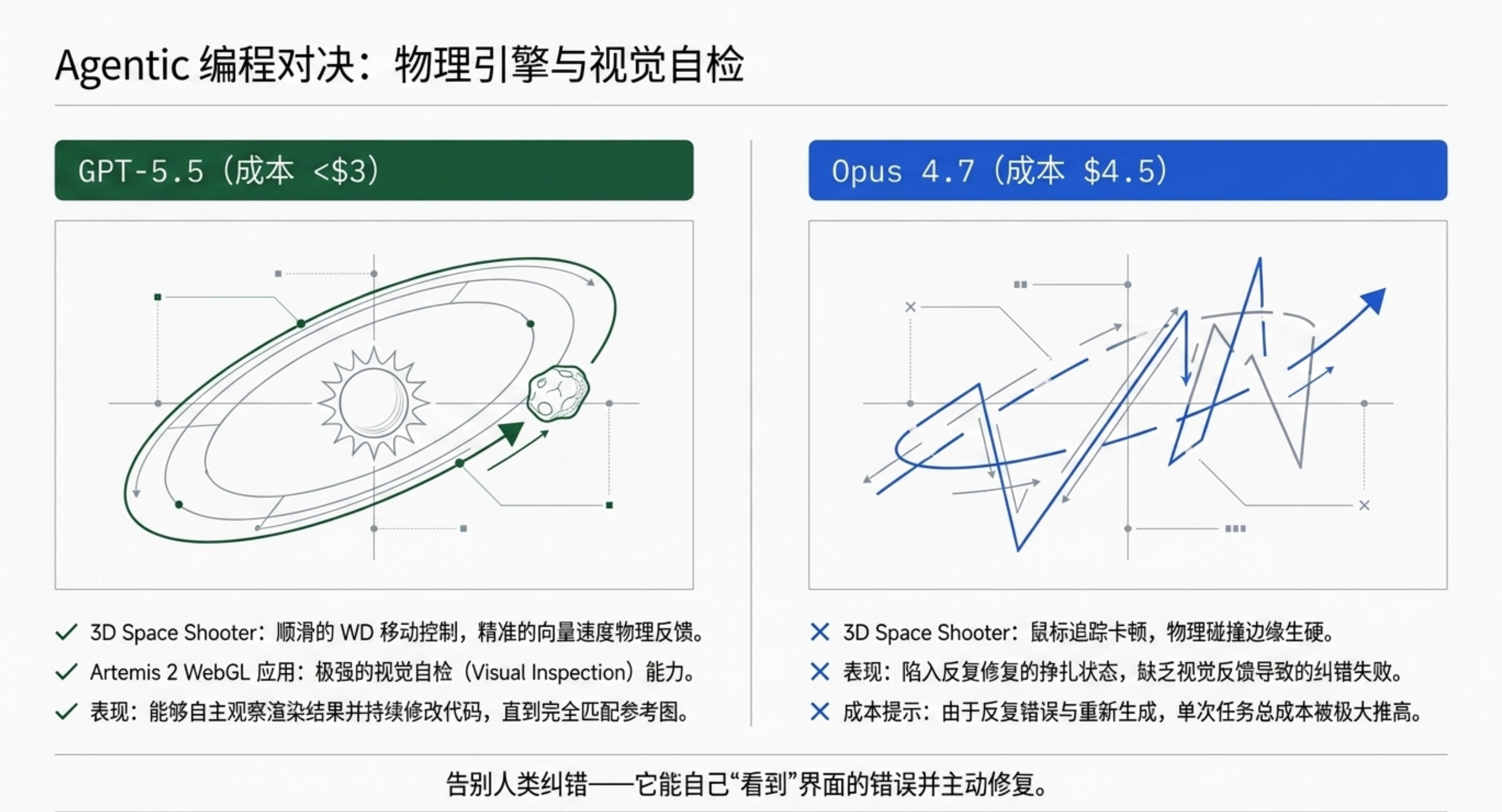
高级工程师基准:GPT-5.5 得分62.5/100,Claude Opus 4.7 仅约30分——差距超过一倍。
底层重构能力:与以往模型“修补”模式不同,GPT-5.5 能识别核心原则,敢于删除旧文件,从零开始重构整个系统。
语言偏好:TypeScript 和 Swift 表现卓越,Ruby 相对较弱。
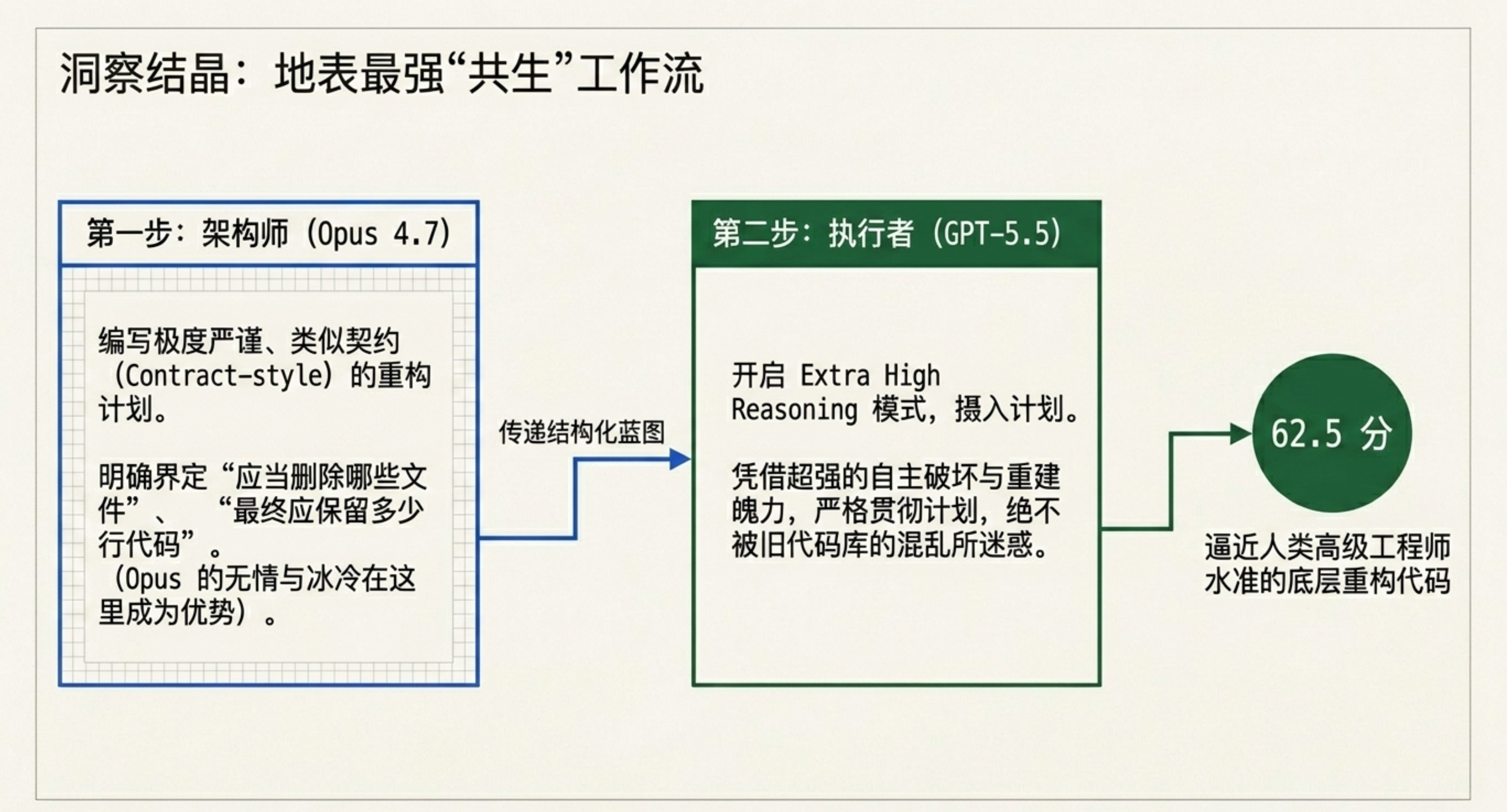
最佳工作流:测试发现,用 Claude Opus 4.7 写详细计划 + 用 GPT-5.5 执行能发挥最强性能。Opus 擅长逻辑清晰、契约导向的规划,GPT-5.5 是当今最强大的“执行者”。
💰 令牌效率——单价翻倍,总成本反降
定价:输入$5/百万token,输出$30/百万token,是 GPT-5.4 的两倍。
效率奇迹:完成相同任务所需 token 数远少于前代。例如生态系统模拟中,GPT-5.5 仅用2.8万输出 token,达到 Opus 4.7 用25万 token 才有的效果。
实际成本:多项测试显示,尽管单价翻倍,但由于 token 消耗大幅减少,总支出往往低于 GPT-5.4 或 Opus 4.7。
🗣️ 性格进化与用户体验
告别冗长:抛弃了 GPT-5.4 “僵硬、正式、长篇大论”的风格,变得更简洁直观,直接给出结果而非论文式解释。
文字创作:在商业写作和声音/文风复制上表现卓越,能微妙捕捉特定风格。
极低延迟:得益于 GB200/GB300 推理优化,性能大幅提升同时保持了与5.4相同的响应速度。
⚖️ 第五章:局限性与对比
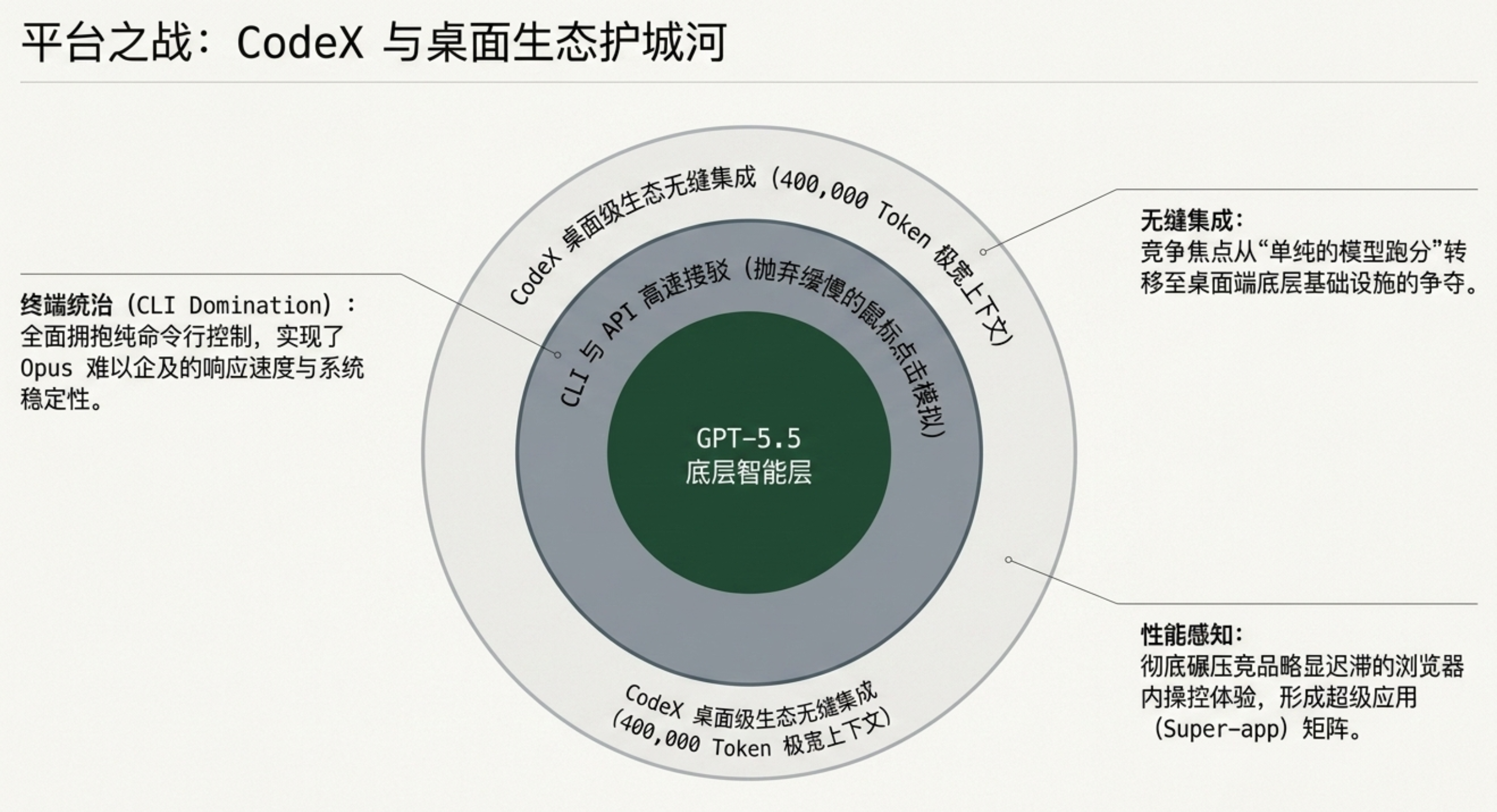
上下文窗口:40万 token(Codeex 中),仍逊于 Claude Opus 4.7的100万。
审美直觉:在某些需要极度敏锐洞察力或审美判断的任务中,Claude 4.7被认为“上限更高”。
可用性:已在 ChatGPT Pro 和 Codeex 中上线,API 开发版即将推出。
