

 6
6 0
0
引言:从模型训练到应用交付的跨越
在过去的一段时期里,大型语言模型(LLM)的“训练”占据了几乎所有的技术头条。然而,随着 AI 浪潮进入深水区,行业焦点正在发生深刻转移:真正的战场已经从实验室的训练集群转向了用户的交互界面。
正如 Baseten 的 Philip Kiely 所言,推理(Inference)才是“实现 AI 应用程序承诺”的关键环节。如果说训练是塑造 AI 的灵魂,那么推理就是赋予其行动力。对于正在处理数十亿次推理请求的企业而言,如何构建低延迟、高可靠且具备经济规模的用户体验,已成为当前 AI 架构师面临的头号挑战。
核心观点 1:推理不只是“运行”,它是全栈工程的终极挑战
在许多人的固有认知中,推理只是简单地加载模型并运行预测。但 Philip Kiely 在其新书《推理工程》(Inference Engineering)中指出,推理实际上是一项极具挑战性的全栈工程任务。它关乎的是在极严苛的 SLA(服务水平协议) 要求下,如何维持系统的稳定性。
“推理意味着一切——从 CUDA 到基础设施……它有着最紧迫的延迟要求和最高级别的可用性标准。” —— Philip Kiely
对于处于超增长(Hypergrowth)阶段的平台,推理不仅要处理海量并发,更要确保每一毫秒的响应都在可控范围内。这种对性能的极致榨取,使得“推理工程”正成为一门独立的、横跨硬件驱动与分布式系统的学科。
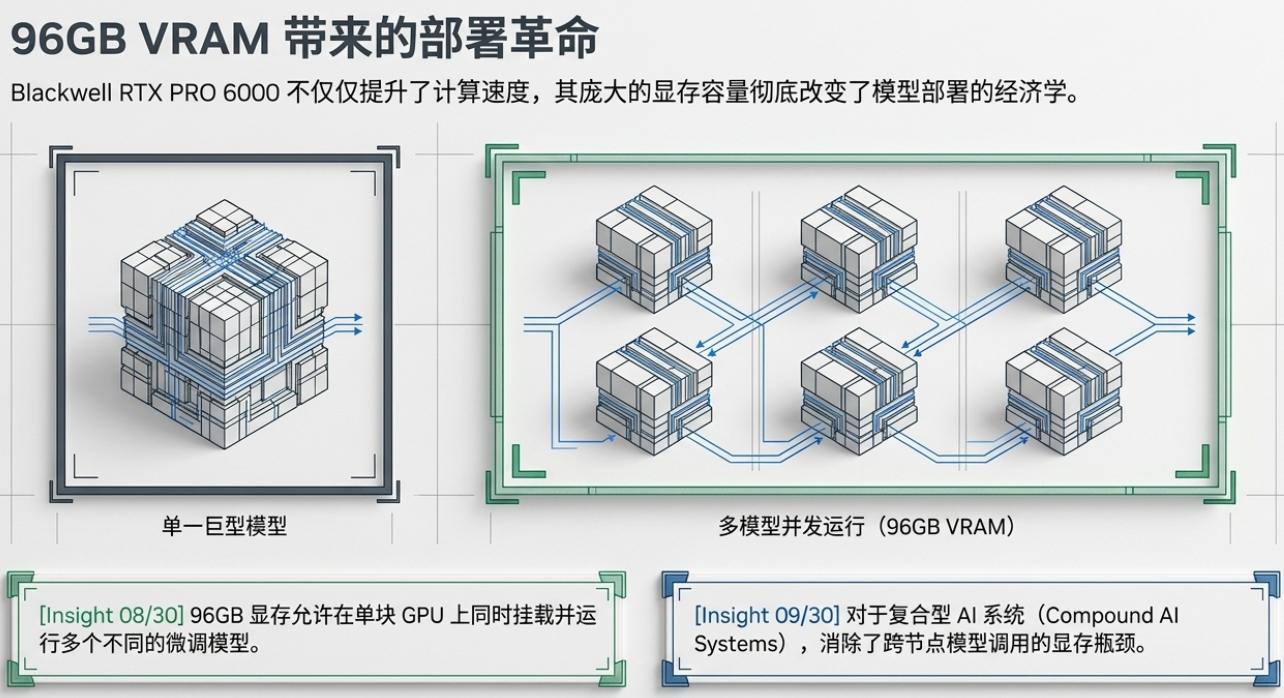
核心观点 2:96GB VRAM 的震撼力——Blackwell 改变了模型部署的游戏规则
硬件层面的革新依然是推动推理进化的原动力。NVIDIA 与 Google Cloud 的深度合作释放了两个重磅信号:Google Cloud 不仅将成为首批提供 Vera Rubin(下一代硬件,预计今年下半年推出)的云厂商,还将全面引入 Blackwell GPU。

其中,RTX PRO 6000 (Blackwell) 配备的 96GB 显存 (VRAM) 被 Philip 评价为“令人疯狂”的突破:
模型堆叠(Model Stacking): 96GB 的巨量空间允许开发者在单个 GPU 上同时“堆叠”运行多个模型。
架构简化: 这种单卡多模型的模式极大地降低了对复杂编排层(如 GKE 容器层)的依赖,减少了跨卡通信带来的开销,让系统架构变得更轻量、更高效。
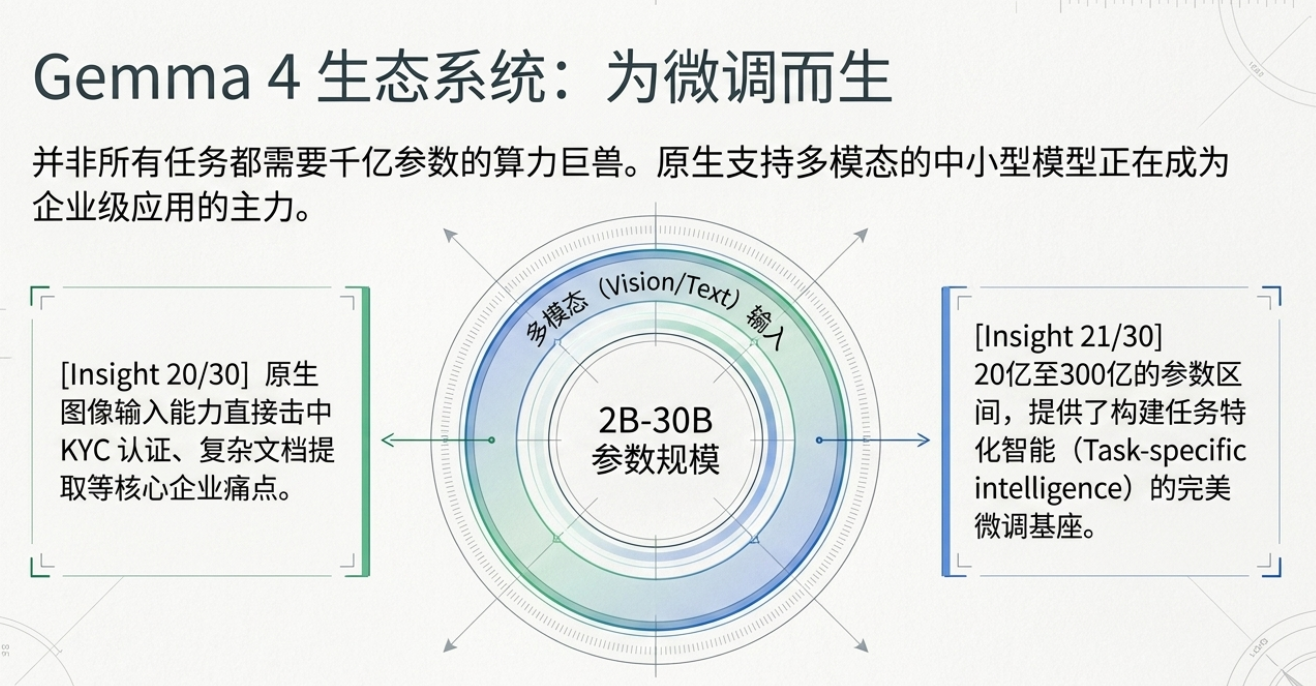
核心观点 3:Gemma 4 的“小而美”策略——为什么参数规模不是唯一标准
在模型选择上,Baseten 团队对 Google 的 Gemma 系列(尤其是最新的 Gemma 4)情有独钟。在他们看来,追求 120B 参数以上的巨型模型并不总是最优解,**特定任务智能(Task-specific intelligence)**才是企业的核心诉求。

激活效率的飞跃: Gemma 4 采用了 4B 参数的 MOE(混合专家模型) 结构,其惊人的激活效率意味着它能在极低的计算成本下实现强大的性能。
尺寸多样性: 从 2B(如高效的 E2B 模型)到 30B,这种灵活的尺寸覆盖为企业微调提供了理想的基座。
原生多模态: Gemma 4 具备原生图像输入能力,这对于 KYC(身份验证)、文档自动提取等企业级应用场景具有决定性意义。
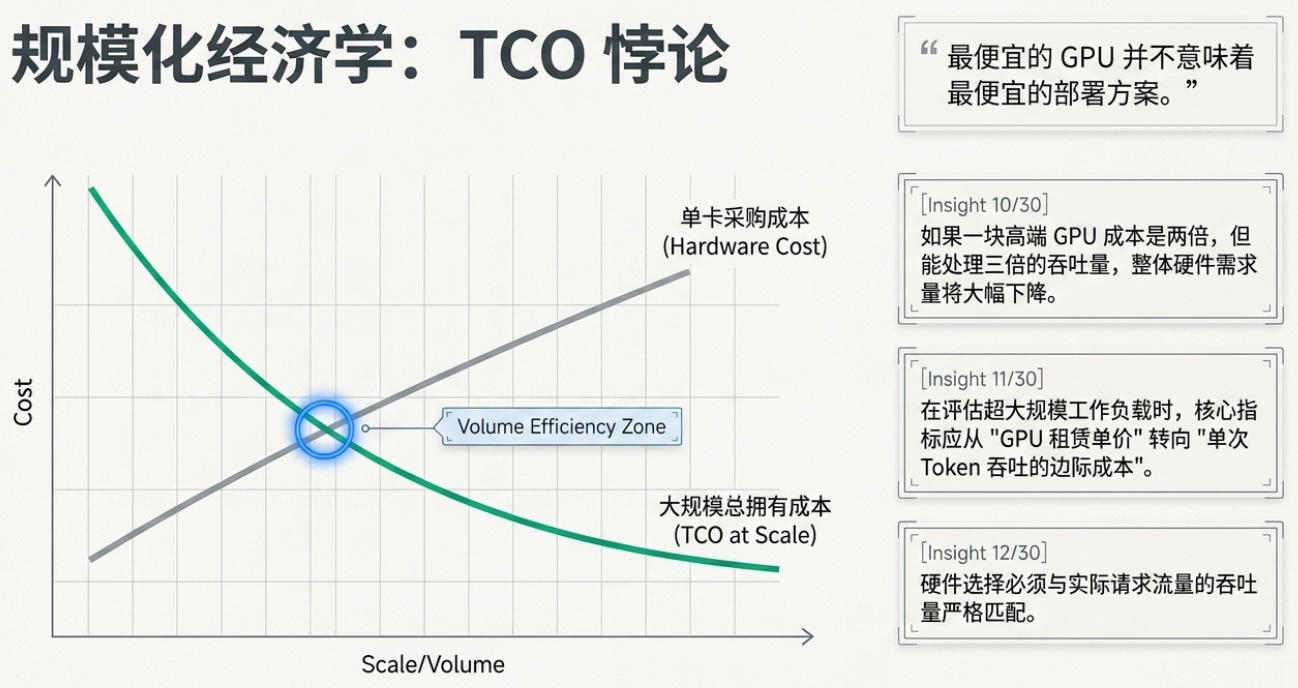
核心观点 4:打破 TCO 迷思——“单位吞吐量成本”才是金标准
在评估基础设施时,决策者往往被单个 GPU 的租用价格迷惑。Philip 提出了一个关于总体拥有成本 (TCO) 的深刻见解:在高负载场景下,最贵的 GPU 反而是最经济的选择。
逻辑核心:
单价 vs. 吞吐量: 虽然顶级硬件(如 B200)单价高,但其吞吐能力往往是中低端硬件的数倍。
硬件密度: 如果一块高性能 GPU 能完成三块普通 GPU 的工作,那么你所需的硬件总量、维护成本及网络延迟都会大幅下降。
衡量标准: 架构师应关注 “单位吞吐量的成本(Cost per unit of throughput)”。在处理数十亿规模的推理请求时,高性能硬件能显著降低长期运营成本。
核心观点 5:解决“发夹弯”难题——GKE 与多模型复合系统
现代 AI 应用已进入“智能体工作流(Agentic Workflows)”时代。一个典型的 复合 AI 系统(Compound AI System) 在完成一次用户任务时,可能需要在不同模型间进行数十次交互。
Google Kubernetes Engine (GKE) 在此展现了其作为管理运行时的独特优势,尤其是在处理 Philip 展示的 22 个 B200 规模 的演示负载时:
攻克 Hairpinning(发夹弯)问题: 在复杂网络中,模型间的频繁通信容易产生不必要的延迟。GKE 优化了基础设施层面的路由,为每一轮对话节省数十毫秒。
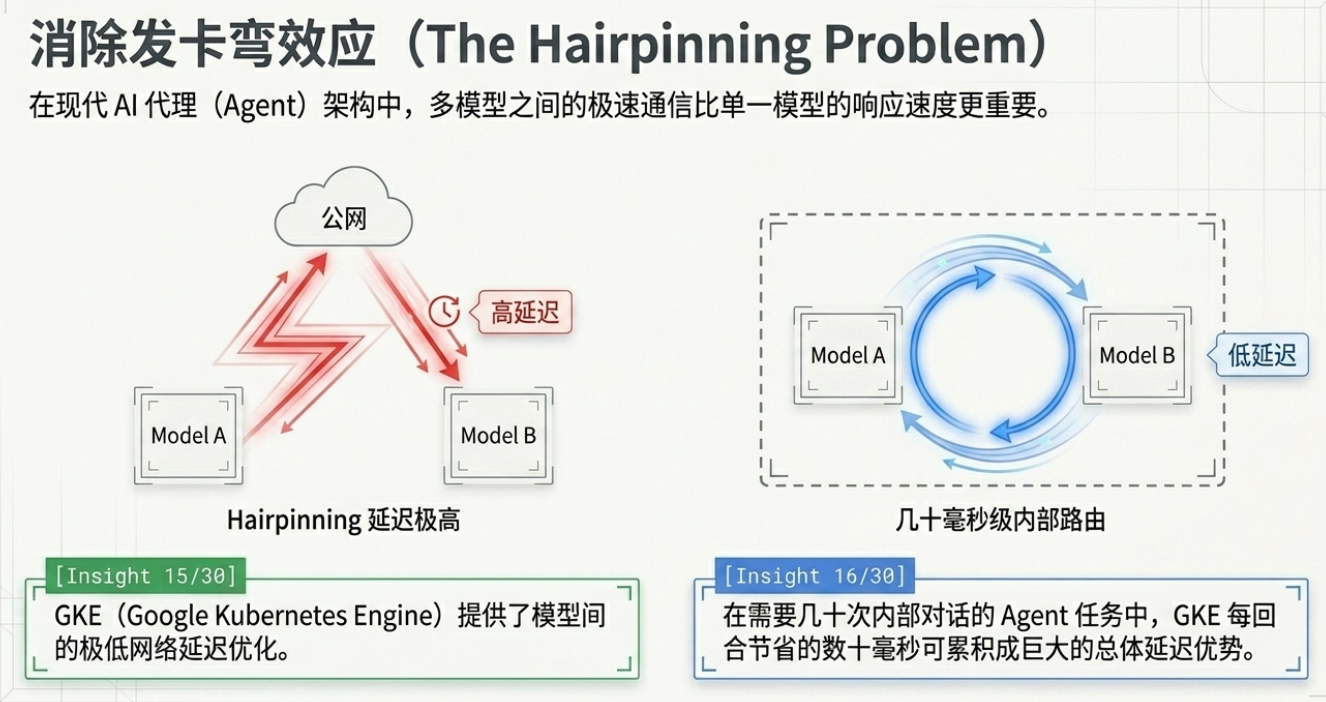
累积优势: 对于一个涉及 20 次模型调用的智能体流程,这种优化能累计节省数百毫秒,直接决定了终端用户对“响应速度”的感知。

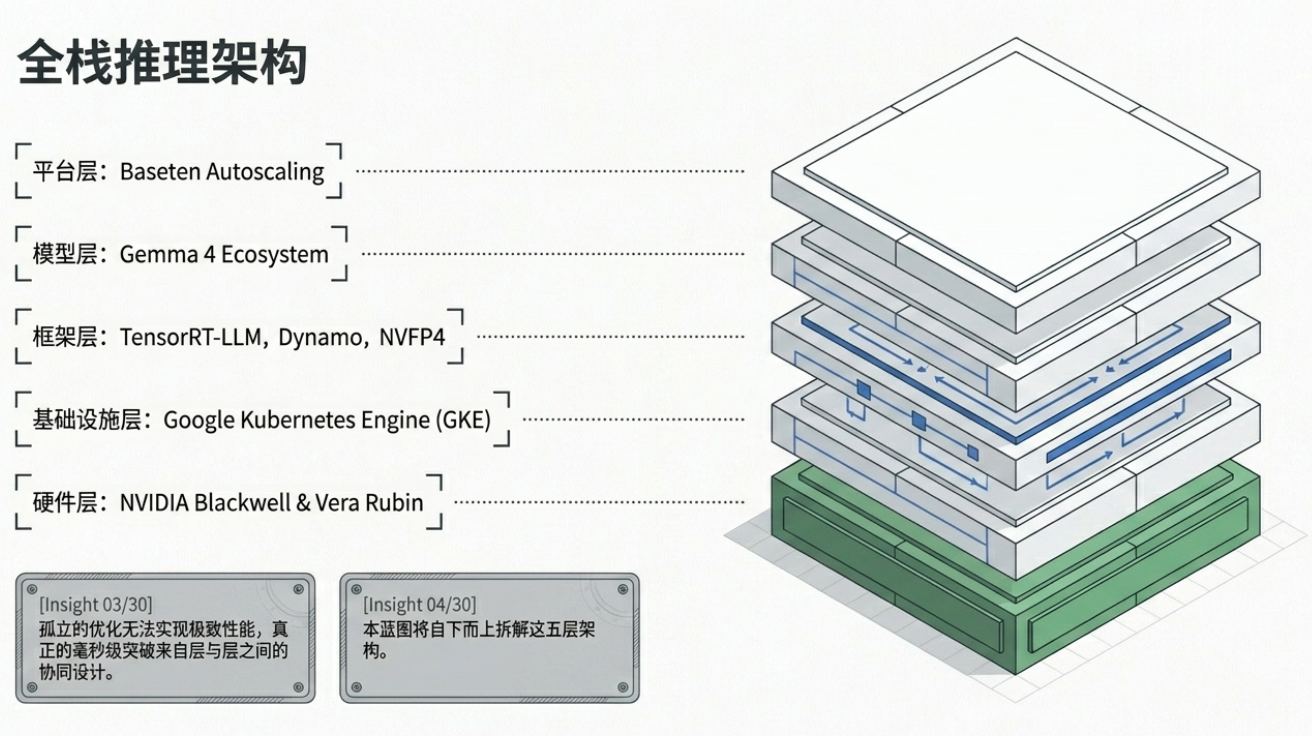
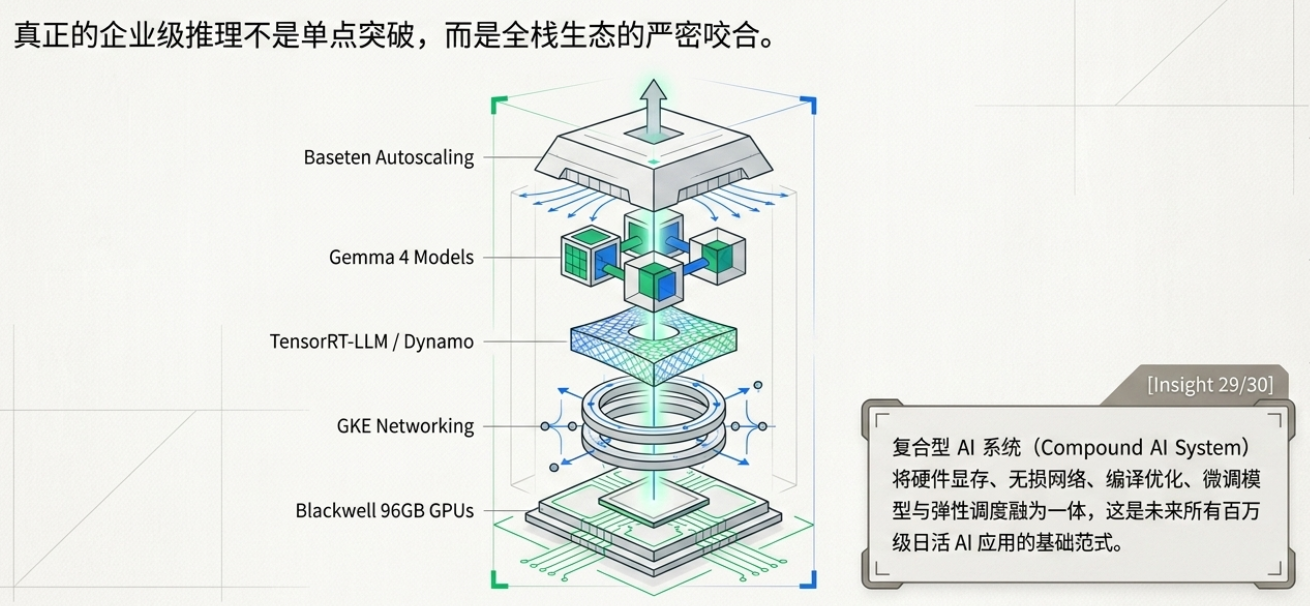
技术避雷指南:开发者如何榨干硬件性能?
为了帮助开发者在生产环境中释放硬件潜力,NVIDIA 的 Jay Rodge 与 Baseten 总结了以下核心工具链:
TensorRT-LLM: NVIDIA 官方推出的开源 SDK。只需数行代码即可针对特定 NVIDIA 硬件(如 Blackwell)生成优化后的推理引擎。
NVFP4: 配合 Blackwell 架构的新型精度格式,是实现巅峰推理速度的“性能钥匙”。
NVIDIA Dynamo: 专为生产环境设计的开源扩展工具。Baseten 是该工具的全球首批生产环境使用者,证明了其在大规模负载下的稳定性。
量化框架(Quantization Frameworks): 在内核层(Kernel layer)进行量化优化,是提升模型在不同硬件间迁移效率的关键。

结论:推理工程的黄金时代
AI 的竞争已经进入下半场,这不仅是算法的较量,更是工程能力的博弈。从底层芯片的精度优化,到像 GKE 这样的容器编排通信优化,每一个细节都在重新定义 AI 应用的边界。
我们正站在从“运行模型”向“工程化交付体验”转型的十字路口。硬件的革新(如 96GB VRAM)与软件协议的进化正在合力降低 AI 的落地门槛。
最后,请思考一个问题: 在您的 AI 路线图中,您是在单纯地为“运行模型”而构建,还是在为“满足 SLA 并交付极致用户体验”而进行全栈工程化?
