7
7 0
0在全球金融市场的演进历程中,量化交易与高频交易(HFT)已经从早期的简单统计套利,发展为由前沿人工智能、极致网络硬件与超大规模计算集群驱动的系统性工程。在这一高度隐秘且竞争极度激烈的领域中,Citadel Securities、Jane Street和文艺复兴科技(Renaissance Technologies)作为行业的三大标杆,各自展现出了截然不同的交易哲学与技术实现路径。这三家机构在资本市场中汲取超额收益(Alpha)的能力,本质上源于其在数学模型、软件工程范式、网络拓扑结构以及底层硬件加速技术上的深度定制与创新。本报告将深入剖析并对比这三家量化巨头在算法策略、计算与网络基础设施方面的核心差异,并结合2025至2026年的技术演进趋势,揭示驱动现代量化交易系统发展的深层动力。
核心交易策略与前沿算法的哲学分野
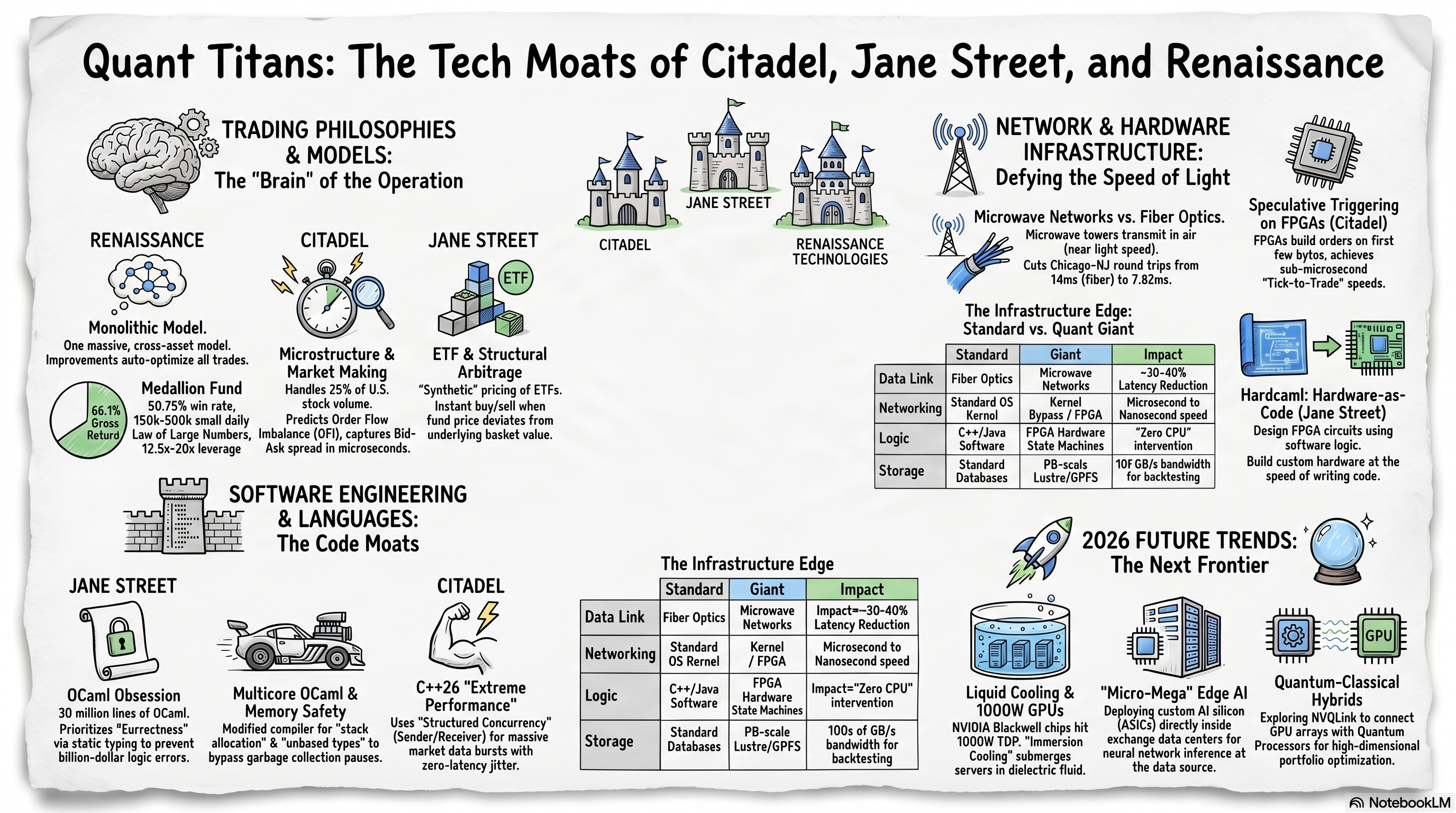
尽管这三家机构均被归类为量化交易巨头,但它们在收益来源、时间维度、算法设计及风险敞口管理上呈现出显著的异构性。它们的策略跨越了从纳秒级的微观结构预测到数天周期的宏观统计套利。
文艺复兴科技:纯粹的数据驱动与多维统一模型
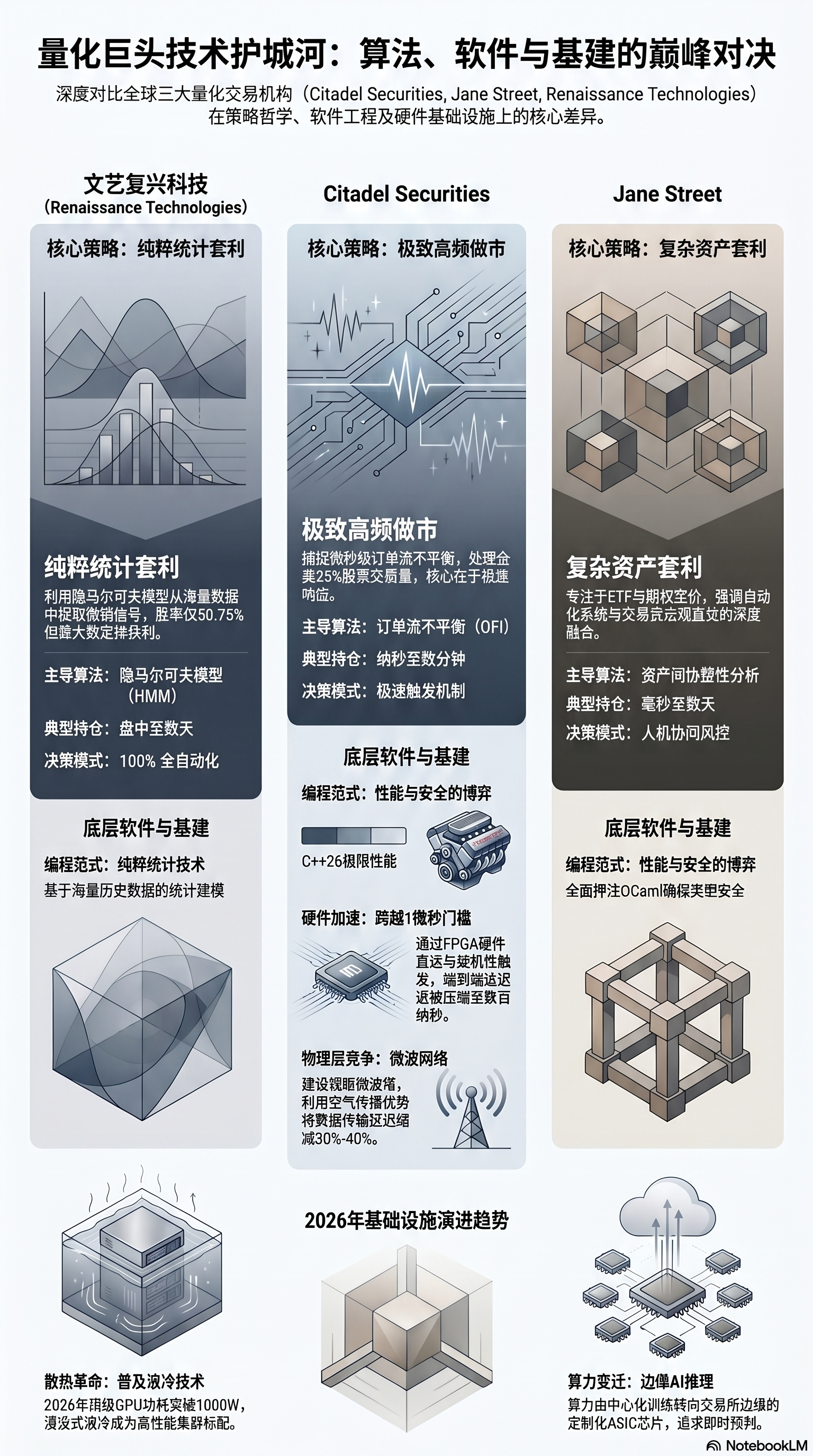
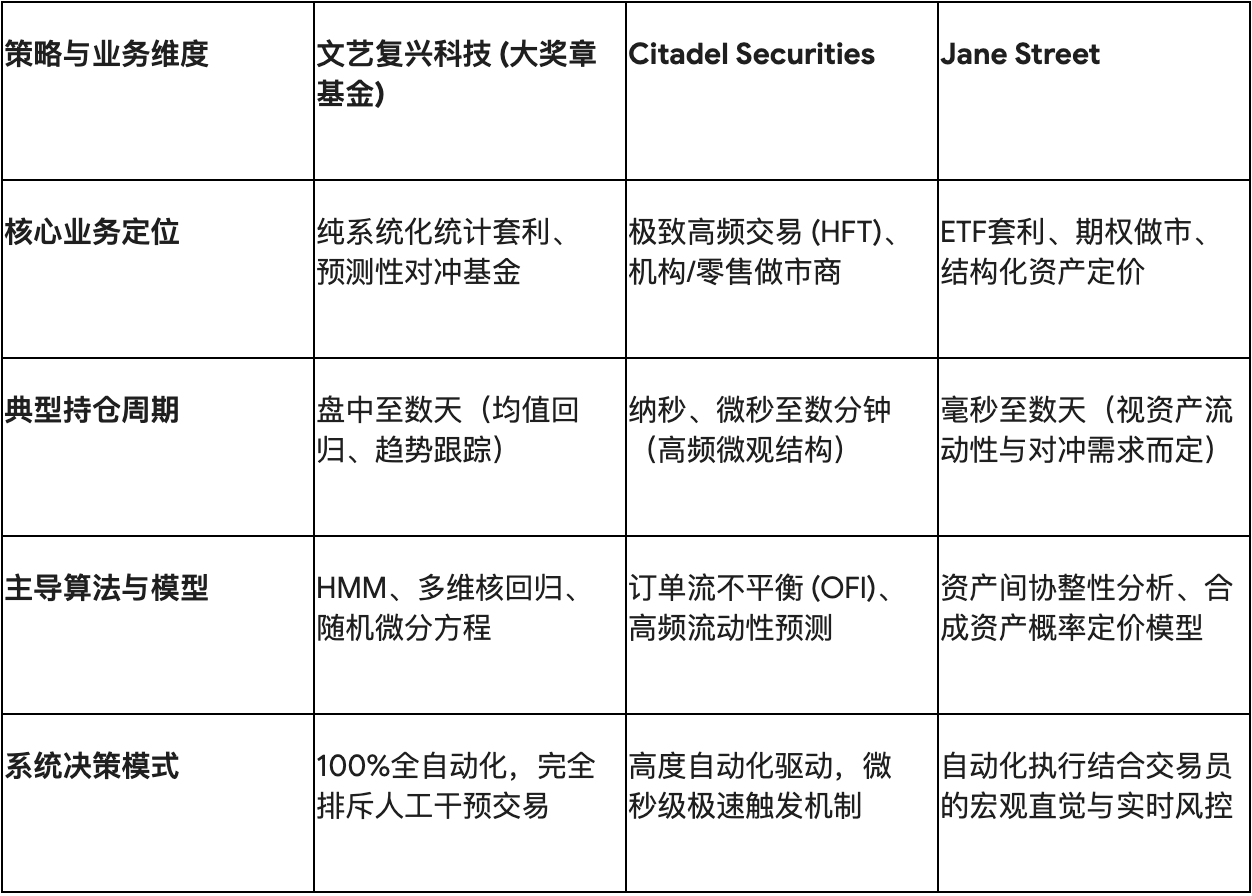
文艺复兴科技(特别是其旗舰的大奖章基金 Medallion Fund)是纯粹系统化、统计套利交易的代名词。该机构的策略核心并不依赖于对传统金融理论或经济学基本面的主观理解,而是建立在从海量噪声中提取微弱统计信号的绝对能力之上。
在其长达三十余年的运作中,大奖章基金实现了年均66.1%的毛收益率和39.1%的净收益率(在扣除了史无前例的5%管理费和44%表现费之后),其最初的1000美元投资若不进行分配,将增长至惊人的9010万美元。这种非凡的业绩并非依赖单一的暴利交易,而是建立在极高频次的交易基数和微弱的统计优势之上。大奖章基金每天自动执行约15万至30万笔小型交易,其算法的整体胜率仅为50.75%。只要在数以百万计的交易中维持这一微小的正向预期,结合系统性的凯利公式(Kelly Criterion)进行精确的头寸规模控制与高达12.5至20倍的杠杆放大,便能通过大数定律实现稳定且惊人的复利增长。
在底层算法层面,文艺复兴极早地将非线性动态系统建模引入了金融领域。其研究团队广泛使用随机微分方程(Stochastic Differential Equations)和布朗运动(Brownian Motion)来模拟资产价格和商品随时间的随机演化轨迹。更为核心的是,该基金率先引入了最初用于语音识别的隐马尔可夫模型(Hidden Markov Models, HMM)以及Baum-Welch参数估计算法。在金融时间序列中,市场往往在不同的“隐藏状态”(如低波动率的趋势市与高波动率的震荡市)之间切换,HMM能够通过观察表象价格的波动来推断市场底层的隐藏状态转移概率,从而允许算法在市场环境发生根本性改变前提前调整头寸。
此外,文艺复兴的机器学习管线采用了高维核回归(Kernel Regression)和复杂的前馈与递归神经网络(RNN/LSTM),将结构化数据与非传统的另类数据(如天气趋势、航运日志甚至月相)映射至高维空间,以捕获传统线性协整分析无法察觉的隐蔽相关性。与其他机构将不同资产类别的策略割裂运行不同,文艺复兴采用的是一个庞大的、交叉资产的统一分析模型(Monolithic Model)。在这一架构下,研究员对货币对交易算法的微小改进,将通过模型内部的复杂互联网络,自动惠及并优化股票或商品期货的交易逻辑,从而最大化了多资产协同的Alpha捕获能力。
然而,即使是如此精密的基础设施,在面对非理性的人类恐慌与地缘政治黑天鹅时,也面临着算法适应性的极限。在2025年10月的“量化地震(Quant Quake)”中,受突发地缘政治头条新闻、剧烈的板块轮动以及零售资金动量激增的冲击,历史相关性发生断裂,导致文艺复兴面向公众的RIEF和RIDA基金分别出现了-14.39%和-15.6%的回撤。这迫使该机构在2025年第四季度的投资组合中进行高频度的信号轮动,将其13F持仓深度分散至3500个标的,并在Palantir、United Therapeutics和Micron等高波动率的科技与生物医疗资产上部署了数十亿美元的量化驱动头寸,以重新校准其信号发现机制。
Citadel Securities:微观结构预测与极致做市
不同于文艺复兴的统计套利,Citadel Securities作为全球最大的做市商之一,处理着美国股票市场约25%的交易量,其核心策略建立在极低的执行延迟与对订单簿微观结构(Microstructure)的深刻理解之上。
Citadel的算法着眼于微秒乃至纳秒级别的价格发现机制。做市策略的核心在于持续在买卖两端提供报价,通过捕获微小的买卖价差(Bid-Ask Spread)获利,并避免积累隔夜头寸 。其高级交易算法高度依赖于订单流不平衡(Order Flow Imbalance, OFI)的实时计算。通过部署复杂的机器学习模型,Citadel能够在极短的时间窗口(例如30分钟维度的趋势预测)内,判断市场上隐藏的短期买卖压力,并据此动态调整其报价的激进程度与位置 。
高频做市的致命风险在于“逆向选择风险(Adverse Selection Risk)”。当市场由于宏观数据发布或突发新闻出现单边剧烈波动时,做市商的报价极易被拥有信息优势的“有毒流量(Toxic Flow)”击穿。因此,Citadel的算法不仅需要极速处理市场数据流,更需要部署复杂的止损逻辑和跨资产对冲网络,以确保在市场剧震期间依然能够提供流动性并保持盈利 。这也解释了为何其系统架构对确定性延迟(Deterministic Latency)有着近乎苛刻的要求。
Jane Street:结构化资产套利与人机协同
Jane Street的策略在频谱上呈现出独特的多样性。作为全球ETF和固定收益市场做市领域的绝对主导者(2025年第二季度创造了101亿美元的收入),其策略深度融合了概率模型与对金融衍生品定价逻辑的透彻理解。
ETF套利是Jane Street的王牌策略之一。由于ETF是追踪底层一揽子资产的合成工具,当ETF的市场交易价格与其底层资产的资产净值(NAV)出现微小偏离时,套利机会便应运而生。Jane Street的算法需要实时计算数千种成分股的合成价格,当出现定价错位时,系统会瞬间买入低估的一方并卖出高估的一方,进而向交易所申请申购或赎回份额以锁定无风险利润。这种套利涉及极高维度的协整性分析,并在市场承压、流动性枯竭的极端抛售环境下,对做市商的风险管理与资产剥离能力提出了极大挑战。
有别于文艺复兴的“完全黑盒”与绝对自动化理念,Jane Street的交易哲学强调自动化系统与人类主观判断的深度融合。虽然其日常交易的绝大多数执行完全由机器接管,但由于其广泛参与期权做市、缺乏流动性的公司债定价以及复杂的结构化产品交易,Jane Street投入了巨资构建实时风险监控与交易可视化工具 19。交易员和量化研究员被赋予了极高的权限,能够根据宏观经济事件的直觉预判,干预并调整算法的风险参数。
软件工程范式与系统重构:类型安全与并发美学
支撑上述超级算法持续运转的,是各家机构对软件底层工程范式的根本性革新。在这个对错误容忍度为零、对延迟要求达到物理极限的行业中,选择何种编程语言和系统架构,直接决定了其策略迭代的生死存亡。
Jane Street的OCaml执念与底层编译器改造
在金融行业普遍被C++、Java甚至Python主导的背景下,Jane Street展现出了极其独特的工程文化:全面押注OCaml(一种静态类型、函数式编程语言)。他们维护着超过3000万行的OCaml代码,不仅用于核心的风险管理与交易执行系统,甚至将其延伸到了系统基础设施、运维工具乃至会计系统的编写中。
这种技术锁定的核心驱动力在于“正确性(Correctness)”优先。在处理涉及数十亿美元名义价值的复杂衍生品交易时,传统的低级内存错误(如悬空指针)或多线程数据竞争可能瞬间导致无法估量的巨额损失。OCaml极其强大的静态类型系统和类型推断引擎,使得绝大部分逻辑缺陷在编译阶段即可被拦截。此外,OCaml表达能力极强的模式匹配和代数数据类型,使得开发人员能够以接近数学公式的简洁度来描述复杂的金融衍生品状态机。
然而,传统的函数式编程语言由于依赖垃圾回收机制(Garbage Collection, GC),不可避免地会引入微秒级乃至毫秒级的系统抖动(System Jitter),这对于高频交易而言是致命的性能瓶颈。为了在享受高阶抽象的同时不妥协于性能,Jane Street的编译器团队深入OCaml的运行时底层,并在近几年推动了多项革命性的语言层扩展:
第一,他们主导引入了模态类型(Modal Types)系统。这一扩展为OCaml带来了类似Rust语言的内存安全栈分配(Memory-safe Stack-allocation)能力,使得开发者可以在不触发垃圾回收器的情况下管理生命周期明确的短期对象,同时实现了类型级别的副作用跟踪,并在多核OCaml 5.0的并发环境中提供了严格的数据竞争自由(Data-race Freedom)保证。
第二,Jane Street引入了无箱类型(Unboxed Types)和全新的种类系统(Kind System)。在传统的高级语言中,多态数据结构往往通过指针跳转来实现装箱(Boxed),这会引发严重的CPU缓存未命中(Cache Misses)。新的类型系统允许开发者对内存布局进行极其精细的控制,确保结构化数据以连续、适合缓存预取(Cache-and-prefetch-friendly)的表格形式存在于内存中,从而大幅降低了系统处理高并发市场数据流时的微架构延迟。
这种从应用层到编译器底层的垂直整合,使得Jane Street构建的JX交易撮合引擎能够在保持代码高度可读性的前提下,实现每秒50万条消息的处理吞吐量,并将端到端延迟控制在个位数微秒级别。
Citadel的C++极限优化与结构化并发
相较于Jane Street在函数式语言上的深度定制,Citadel Securities则在传统的极致性能语言C++上不断挖掘硬件的极限潜力。作为极度依赖微秒级低延迟响应的做市商,其系统的架构哲学围绕着确定性控制与高并发展开。
金融市场本质上是一个非确定性的高频事件流世界,而做市系统必须在这种混沌中保持确定性的控制流、资源分配和低延迟响应。在处理由网卡、GPU加速器、多核CPU以及海量并发I/O引发的复杂异步任务时,传统基于锁、线程池或是复杂回调机制的并发模型,不仅容易导致难以调试的死锁,还会因为频繁的上下文切换而消耗宝贵的微秒时间。
为了应对这一挑战,Citadel的底层系统工程师积极采用并推动了最新的C++26标准中的结构化并发(Structured Concurrency)模型,特别是基于std::execution的Sender/Receiver异步编程范式。这种现代并发范式允许开发者将跨计算域(例如,从网络接收数据包、卸载至GPU进行张量运算、在CPU上进行风控校验并最终返回网卡发出订单)的异步操作进行极其高效、无缝的组合。通过消除传统运行循环(Run Loop)或厚重并发框架的开销,系统能够最大化地剥离业务逻辑与并发管理的耦合,在复杂的市场微暴涨(Micro-bursts)期间维持极其稳定的长尾延迟表现。
网络通信基础设施:跨越光速极限的物理博弈
当量化策略的软件优化已经压榨完最后微秒的利润空间时,竞争的主战场便下沉到了网络拓扑与物理层的硬件加速上。在这一领域,毫秒()、微秒()甚至纳秒()的延迟缩减,往往决定了高频交易系统能否在抢单中胜出。
微波与短波网络:斩断光纤的束缚
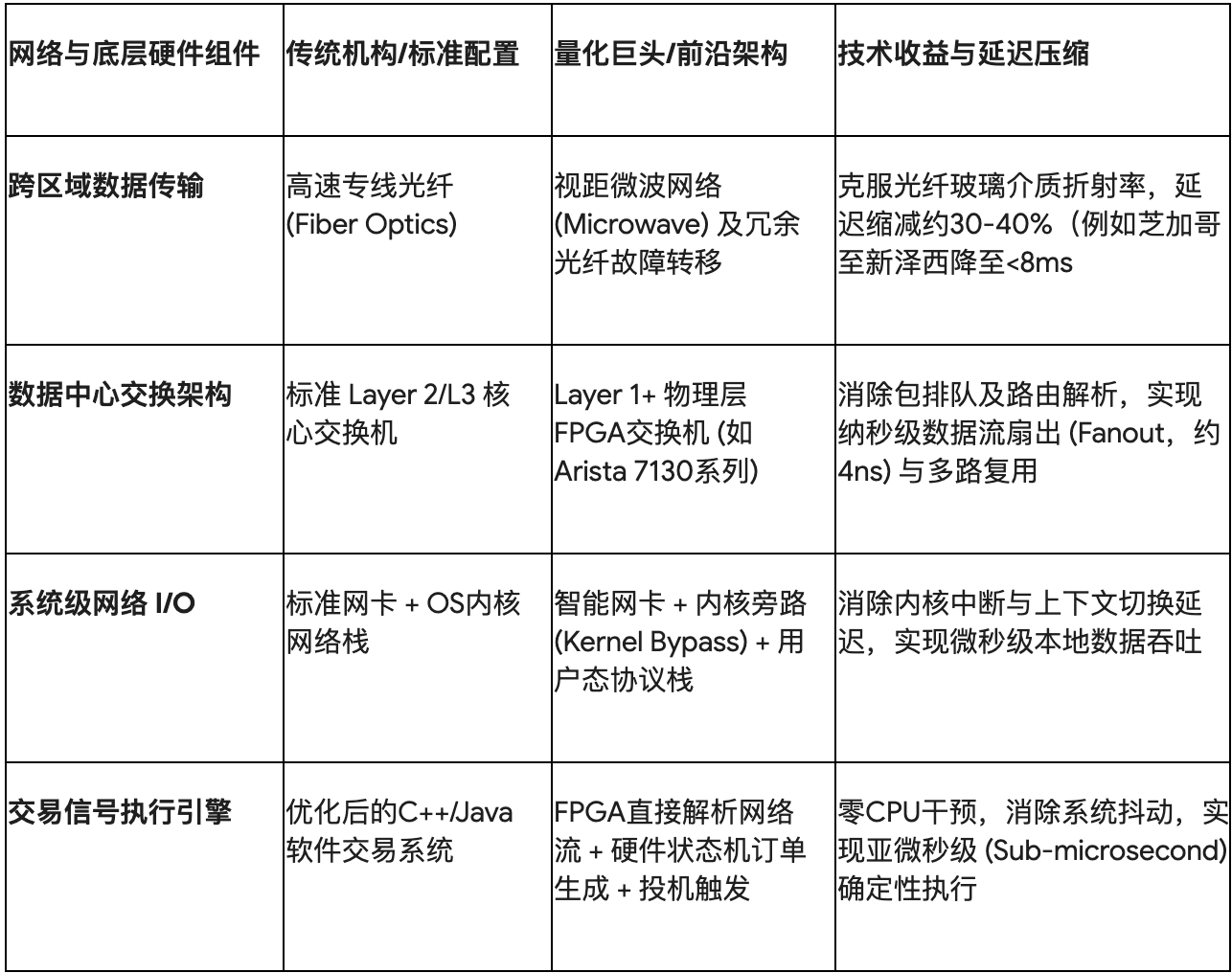
长久以来,金融中心之间的数据传输依赖于地下光缆网络。然而,光纤存在一个不可逾越的物理限制:光在玻璃介质中的折射会导致其传播速度比在真空或空气中慢约30%(即约20万公里/秒)。对于高频交易而言,这意味着时间的流失。
以美国市场最关键的交易走廊为例,连接芝加哥(CME期货交易所数据中心所在的Aurora)与新泽西州(纽交所所在的Mahwah以及纳斯达克所在的Carteret)的常规光纤链路,单程传输时间约为13至14毫秒。为了克服这一限制,Citadel、Jump Trading等机构斥资数千万美元,构建或租赁了点对点的视距微波网络(Microwave Networks)。由于电磁波在空气中以接近光速传播,且微波塔之间的物理路径比蜿蜒的地下光纤更加笔直,芝加哥至西雅图的传输时间可从14毫秒缩短至9.5毫秒,而在芝加哥Aurora至新泽西Carteret的黄金路线上,诸如McKay Brothers提供的QED服务端到端往返时间(Round Trip Time)甚至被压缩至7.82至8.00毫秒的极限区间。
由于高频做市策略极其脆弱且机会稍纵即逝,微波链路的竞争甚至引发了复杂的专利纠纷与行业洗牌(例如Network-1技术公司针对Citadel和Jump Trading发起的关于FPGA时钟域管理与超低延迟交易技术的专利诉讼)。尽管微波链路速度极快,但其物理属性决定了它极易受降雨、浓雾等极端天气锋面的衰减影响。为了保证系统的鲁棒性,Citadel等机构设计了高度冗余的网络拓扑结构:一旦监测到天气扰动导致微波信号丢包率上升,底层的Layer 1物理交换机能够在大约数纳秒内将核心订单流量无缝故障转移(Failover)至备用光纤链路上,确保交易的连续性不受损害。
现场可编程门阵列(FPGA):跨越操作系统的边界
为了进一步将数据处理延迟从微秒压缩至纳秒级别,量化巨头们已经放弃了让通用CPU处理关键网络数据包的做法,转而大规模部署现场可编程逻辑门阵列(FPGA)。传统的服务器在接收市场数据时,数据包必须穿过物理网卡、触发CPU中断、经过繁重的操作系统内核TCP/IP协议栈,最终才被复制到用户空间的交易应用中。这一过程即使经过极致优化,通常也需要耗费数微秒的时间。
FPGA通过在硬件电路上直接硬连线(Hardwiring)逻辑流,实现了真正的物理并行处理。在高频交易系统中,机构通常会在配有Solarflare等智能网卡的服务器上利用内核旁路(Kernel Bypass)技术(如efvi接口),或者干脆直接将FPGA串联在以太网线路上。如此一来,当交易所的ITCH或PITCH等二进制市场行情包到达网卡时,FPGA内部并行的状态机会在不经过任何CPU指令周期的情况下,瞬间完成协议解压、字段过滤乃至在硬件内存中实时重建订单簿(Orderbook)的操作。
这种技术的极致应用是“投机性触发(Speculative Triggering)”。在这一架构中,FPGA甚至可以在尚未接收到完整以太网数据帧的情况下,仅凭借解析包头的前几个关键字节,便开始在硬件通道的另一端提前构建反向的买卖订单流。一旦数据包的尾部校验和(Checksum)确认了交易信号的有效性,系统便会在百纳秒内将预先准备好的订单直接抛入交易所网络 33。这种端到端(Tick-to-Trade)的硬件直连响应将总延迟锁定在了不可思议的1微秒以内,甚至在特定场景下可达到数百纳秒,完全消除了操作系统调度带来的延迟抖动(Jitter)。
硬件设计的软件化:Jane Street的Hardcaml革命
尽管FPGA带来了无与伦比的速度优势,但传统的硬件描述语言(HDL,如Verilog和VHDL)开发效率极其低下。它们缺乏现代软件工程的抽象能力,导致工程师在构建复杂硬件管道或解开循环时,极易引入位宽不匹配、状态机死锁等灾难性错误。对于高频交易而言,硬件底层一个微小的逻辑Bug就可能在数秒内导致数百万美元的亏损。
为解决这一工程痛点,Jane Street彻底颠覆了传统的芯片设计流程,自主研发了名为 Hardcaml 的特定领域语言(DSL)。区别于依赖启发式转换的高级综合(HLS)工具,Hardcaml直接嵌入在OCaml语言中,允许硬件工程师使用OCaml丰富的高阶函数、列表和映射表(Functors, Lists, Maps)来动态、参数化地生成复杂的底层RTL逻辑门电路 36。
更为关键的是,Hardcaml继承了OCaml极其严格的静态类型系统。在电路生成的展开(Elaboration)阶段,系统会自动进行彻底的位宽推断与类型冲突检查,从根本上消除了导致硬件崩溃的低级互连错误。同时,Hardcaml配备了一整套现代化的验证工具链,包括可生成ASCII波形图的周期精准模拟器(Cycle-accurate Simulator)、事件驱动仿真环境,以及深入集成SAT求解器的形式化验证(Formal Verification)工具。这一工程奇迹使得Jane Street的量化研究员能够以编写软件的敏捷速度,安全地在Arista 7130系列Layer 1+ FPGA交换机上开发、测试并部署极低延迟的网络过滤、组播分发与纳秒级时间戳抓取逻辑(MetaWatch),甚至在2022年的ZPrize零知识证明密码学加速竞赛中一举夺魁。
计算基础设施:从PB级数据仓库到AI超算集群
如果说高频做市商(如Citadel和Jane Street的部分团队)追逐的是纳秒级的“即时响应”,那么诸如文艺复兴科技等侧重于中频统计套利与深度预测模型的机构,其基础设施的核心则是“计算的深度与数据的广度”。
文艺复兴:PB级金融数据湖与并行文件系统
文艺复兴之所以能够稳居量化王座数十年,其庞大的历史数据仓库与数据清洗工程功不可没。早在数十年前,其数据科学家Sandor Straus便开始系统性地收集并清洗各类市场数据,剔除价格序列中的错误与断层。如今,该机构维持着一个规模已达PB级(Petabyte,1 PB相当于约1.1万部4K高清电影)的极其庞大的数据湖,且每天以40TB的惊人速度增长。这些数据涵盖了跨资产历史价格、高精度的微观订单簿深度、多维波动率矩阵,以及数量庞大的另类数据集。
要支持如此海量数据的实时查询与模型回测,传统的存储系统根本无法胜任。这要求部署专为国家级超级计算机设计的分布式并行文件系统,如Lustre和IBM的GPFS(现称为Storage Scale)。 在底层架构上,这些并行文件系统通过分离元数据处理与实际数据读写,实现了吞吐量的指数级提升。例如,Lustre将元数据服务器(MDS)与对象存储服务器(OSS)独立开来,支持数百GB/秒的聚合I/O带宽与近乎线性的扩展能力。这种粗暴且高效的底层存储设计,使得文艺复兴数以万计的计算核心能够同时、毫无阻塞地遍历过去几十年的全球金融时间序列,为其复杂的隐马尔可夫模型和神经网络权重提供源源不断的数据吞吐支持。据估计,为了维系这一囊括了数据摄取、模型训练与薪酬体系的庞大超级计算生态,文艺复兴每年的基础设施与人力开销高达7.5亿美元,但在其超额利润面前,这仅仅维持了惊人的85%业务利润率。
异构超算集群与定制计算生态
计算层面,文艺复兴也是最早采用大规模超算的金融机构之一。从早期利用定制化的IBM Blue Gene/L超级计算机阵列(该系列超算通过高度定制的互连架构和能效比设计,曾长期霸占全球Top500超级计算机榜首),到如今转向配备最新NVIDIA GPU集群与HPE Cray超级计算架构的现代化平台,量化巨头与全球顶级科研实验室在算力部署上的界限已逐渐模糊。
Citadel Securities同样在积极重塑其大规模并行计算生态。他们通过与Google Cloud建立深度合作,构建了具备近乎无限弹性的定量研究平台。通过利用搭载特定张量处理单元(如Ironwood TPUs)的云端实例,结合高达19.2 Tb/s芯片互连带宽(ICI)的MoE架构和消除系统延迟的集合加速引擎(CAE),Citadel成功将以前需要数天乃至数周才能完成的极大规模复杂并行分析任务,压缩到了短短数小时甚至几分钟内。
Jane Street为了满足极其严苛的微秒级交易模型推理需求,同样深入了机器学习架构的最底层。传统的GPU计算模式通常面向大批量的吞吐量优化,这并不适合要求超低延迟的高频推理。因此,Jane Street的系统工程师需要深入编写高度定制的CUDA底层算子,实施复杂的算子融合(Kernel Fusion),并精细编排CPU与GPU之间的数据交换节奏。这种将CPU的串行控制与GPU的极度并行计算相重叠的技术,确保了其机器学习模型在进行高频盘中预测时,硬件资源能够得到无缝且无延迟的极致利用。
2026年及未来的基础设施演进趋势
站在2026年的时间节点,随着生成式人工智能(GenAI)、大语言模型(LLMs)以及海量另类数据的进一步渗透,量化金融的计算基础设施正在经历一场系统性的热物理与架构拓扑的蜕变。
1. 液冷技术(Liquid Cooling)的强制性普及
随着AI算力的爆发,计算芯片的制程密度与能耗呈指数级上升。至2026年,专为庞大AI集群和高频推理设计的单枚顶级GPU(如NVIDIA Blackwell系列),其热设计功耗(TDP)已逼近或突破1000瓦特的大关。导致的结果是,承载这些芯片的单体机架功率密度轻易突破了40kW甚至100kW的极限。在这一热负荷下,传统的风冷(Air Cooling)数据中心架构已彻底失去散热余量(Headroom),甚至面临基础设施熔毁的风险。
因此,顶级量化机构的私有数据中心和核心托管设施正在全面向液冷技术转型。其中,**直接芯片液冷(DLC, Direct-to-Chip)通过在CPU和GPU表面贴装冷板,能够带走60%至80%的核心废热,已成为当前新建设施的部署底线,并被大型云厂商确立为AI设施的标准规范。更为前沿的是两相浸没式液冷(Two-phase Immersion Cooling)**技术,它将服务器完全浸没在具有极低沸点的特殊介电绝缘液中,通过液体沸腾气化带走热量。这一技术不仅将数据中心的能源使用效率(PUE)无限逼近理论极限的1.05,更极大地压缩了物理空间,使得量化机构能够在寸土寸金的交易所旁置数据中心(Colocation)内,塞入算力密度更为恐怖的超级计算节点。在2026年,液冷已经不再仅仅是为了降低制冷电费的运维考量,而是能否持续部署最新一代高频算法架构的核心战略门槛。
2. 算力架构向推理与边缘AI迁移
过去几年中,量化机构的巨额算力投资主要集中在“模型训练(Training)”阶段,需要庞大且集中式的数据中心来咀嚼PB级的历史数据。然而,到2026年,算力格局正显著向“推理(Inference)”转移。
由于在实盘交易中,模型需要以毫秒乃至微秒的速度对海量的实时流数据做出响应,一种被称为**“微大型边缘AI(Micro-Mega Edge AI)”**的部署架构正在兴起。机构开始在紧邻交易所撮合引擎的托管机房边缘,直接部署专门针对低延迟推理优化的超高密度AI机架。这些边缘系统不再依赖通用的笨重GPU,而是越来越多地采用专为低延迟设计的定制化推断硅片(Custom Silicon/ASIC),结合混合计算模型,直接在数据产生的物理源头执行极其复杂的神经网络预判与风控指令,极大地削减了数据回传远端数据中心所产生的物理延迟。
3. 量子计算与超大规模互连的探索
面对金融市场无限复杂的非线性和海量的非结构化数据(如央行声明、卫星图像、全球多语种社交媒体情绪等),传统超算的扩展法则开始面临边际效用递减。为了打破这一瓶颈,依托于NVQLink等极低延迟互连技术的最新架构,正试图将庞大的GPU并行阵列与初具规模的量子处理器(Quantum Processors)进行混合编排。借助如NVIDIA的CUDA-Q平台,部分顶级量化前沿实验室已开始探索利用量子模拟来处理诸如动态投资组合的高维寻优或极端衍生品非线性定价等传统经典计算机极难攻克的计算鸿沟。
总结
纵观Citadel Securities、Jane Street与Renaissance Technologies的技术与策略演进图谱,清晰地揭示了现代量化交易并非单一维度上的比拼,而是跨越了数学算法、软件工程架构与极限硬件物理的综合立体战。
文艺复兴科技构建了一座由纯粹数据与极繁统计模型构筑的深邃堡垒。其优势建立在跨越近半个世纪的高纯净度数据积累、基于Lustre/GPFS打造的PB级并行存储巨兽,以及独步天下的隐马尔可夫与非线性机器学习模型之上。他们不纠结于微秒级的网络抢跑,而是以庞大的并行算力和严谨的概率大数定律,从海量历史与替代数据中系统性地碾压市场的局部无效性。
Citadel Securities则将“微观执行的暴力美学”演绎到了极致。作为全球金融市场的流动性心脏,Citadel在异步C++26底层并发架构的支撑下,利用高度冗余的视距微波网络“穿透”了地理距离的物理障碍,并通过内核旁路与具备投机触发能力的FPGA智能网卡切碎了时间维度。它们在极度残酷的纳秒级做市竞争中,凭借对微观订单流不平衡的敏锐捕捉与极致的软硬件协同,构筑了压倒性的高频优势。
Jane Street开辟了一条充满智慧的“工程安全与优雅”路线。在涉及深层定价逻辑的ETF与结构化衍生品套利领域,他们摒弃了随波逐流的技术选型,通过深度重构OCaml编译器及其静态类型系统,构建了兼具极高可读性与并发安全性的核心撮合平台。进一步地,他们通过自研的Hardcaml语言降维打击了传统的底层硬件设计流程,将FPGA与Arista定制化物理层交换机完美融合。这不仅确保了系统在极端波动中具备极高的抗脆弱性和处理确定性,更为交易员融合宏观直觉的干预预留了充足的高维空间。
迈入2026年,在千瓦级液冷机架普及与边缘AI微型计算工厂兴起的推波助澜下,量化交易的技术护城河已变得高不可攀。这些处于金融与科技绝对顶端的机构,仍在不断跨越物理学、计算机科学与金融工程的交叉前沿,持续拓展着人类资产定价与风险交换体系的终极边界。