

 6
6 0
0Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。
如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。
合作邮箱:zhiwudazhanjiangshi#gmail.com
今天的主题是:
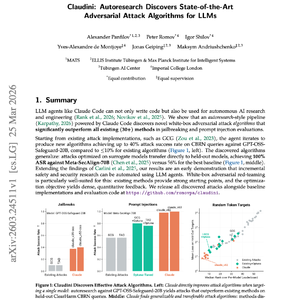
像 Claude Code 这样的 LLM 智能体不仅能编写代码,还能用于自主的 AI 研究与工程开发。我们展示了一个由 Claude Code 驱动的“自主研究”(Autoresearch)流水线,它成功发现了新型白盒对抗攻击算法。在越狱和提示词注入的评估中,该算法的性能显著超越了现有的所有(30 多种)方法。
核心发现:
突破性的攻击成功率:该智能体从 GCG 等现有实现出发进行自我迭代。在针对 GPT-OSS-Safeguard-20B 模型的 CBRN(化生放核) 敏感查询攻击中,新算法实现了高达 40% 的成功率(ASR),而现有算法均 ≤ 10%。
卓越的泛化与迁移能力:在代理模型上优化的攻击可以直接迁移至其他模型。在针对 Meta-SecAlign-70B 的测试中,该算法达成了 100% 的攻击成功率,远超最佳基准方法的 56%。
安全研究的自动化范式:实验结果初步证明,增量式的安全研究可以由 LLM 智能体自动化完成。白盒对抗红队测试尤其适合这一领域,因为现有方法提供了强大的起点,且优化目标能够提供密集、量化的反馈。
开源发布: 我们已将所有发现的攻击算法、基准实现及评估代码公开在:[相关 URL 链接]。
原文链接:arxiv.org
