

 2
2 0
0说话人1: 大家好,欢迎收听今天的科技漫谈!今天我们来聊聊视频编解码技术。你有没有想过,为什么一部2小时的电影能装进一个蓝光碟里?为什么在手机上看4K视频不会把流量瞬间用光?答案就在于视频编解码技术!这可是现代数字媒体的基石!
说话人2: 视频的本质是什么?是连续静止帧的快速序列播放。人眼的视觉暂留效应要求帧率不低于24帧每秒就能形成连贯的动态感知。
说话人1: 我们先算一笔详细的账。假设视频分辨率是W×H像素,帧率是f帧每秒,每个像素用b个字节来表示RGB颜色,那么每秒钟的视频数据量D等于:D = W × H × f × b。比如1080P分辨率(1920×1080像素)、30fps帧率、RGB色彩编码(3字节每像素),代入公式:D = 1920 × 1080 × 30 × 3 = 186624000字节每秒,大约是180MB每秒!
说话人2: 哇!每秒180MB!那2小时的电影呢?
说话人1: 对于时长为T秒的视频,总存储量V等于:V = D × T。代入2小时(7200秒),V = 180MB每秒 × 7200秒 = 1296000MB,大约是1.3TB!
说话人2: 天哪!1.3TB!这得用多少张蓝光碟啊!看来视频压缩技术真是必需品!我要特别感谢李坚毅博士对视频编解码技术相关资料的精心整理,正是基于这些扎实的技术资料,我们才能深入理解这些复杂的原理。
说话人1: 那视频压缩是怎么做到的呢?核心思想是"预测编码"。简单说,就是通过建模预测像素值,只存储预测值和实际值的差异,这个差异就叫残差。
说话人2: 这个预测的数学模型是什么?
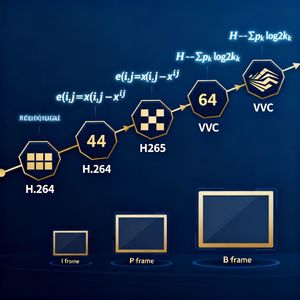
说话人1: 设原始像素值是x(i,j),这里的i和j分别是像素的行、列坐标。预测像素值是x^(i,j),上标尖括号表示预测值。那么残差e(i,j)就等于x(i,j)减去x^(i,j),也就是e(i,j) = x(i,j) - x^(i,j)。
说话人2: 这个方法的原理是什么?
说话人1: 原理是图像像素分布有很强的规律性!对于平滑的区域,比如天空、墙壁,像素值分布非常均匀,预测值和实际值差别很小,残差数据量就大大降低了!而对于细节丰富的区域,比如头发、纹理,残差数据量相对较大,需要通过后续的压缩算法进一步处理。
说话人2: 我听说还有I帧、P帧、B帧三种帧结构?
说话人1: 对!这三种帧分工协作,形成了完整的帧间压缩体系。I帧是独立帧,完全不依赖其他帧,采用帧内预测算法,数学上表示为:x^_I(i,j) = f(x_I(i',j')),其中f(·)是帧内预测函数,(i',j')是帧内相邻像素坐标。P帧是前向预测帧,只参考前序I帧或P帧,数学表达:x^_P(i,j) = g(x_P-1(i+Δx,j+Δy)),其中g(·)是前向预测函数,(Δx,Δy)是运动矢量。B帧是双向预测帧,同时参考前序和后序帧,数学表达:x^_B(i,j) = h(x_B-1(i+Δx1,j+Δy1), x_B+1(i+Δx2,j+Δy2)),其中h(·)是双向预测函数,有两组运动矢量分别表示前后向的位移!
说话人2: 这套帧结构的时间依赖模型真是精妙!从独立预测到前向预测再到双向预测,每一层都在提升压缩效率!李博士在整理这些技术资料时,把数学原理讲得特别清晰,让人一眼就能看懂I帧、P帧、B帧的本质区别和相互依赖关系。
说话人1: 运动矢量是帧间压缩的核心技术。它的本质是通过求解相邻帧间像素块的位移,用位移矢量替代像素块的重复数据,进一步降低冗余。
说话人2: 怎么找到最优的运动矢量呢?
说话人1: 这是一个优化问题!数学上就是最小化像素块灰度值差异之和!公式是:对Δx和Δy求最小值,min over Δx,Δy of sum over (i,j) in Block of |x_t(i,j) - x_t-1(i+Δx,j+Δy)|。其中x_t是第t帧的像素值,x_t-1是第t-1帧的像素值,Block表示像素块范围。
说话人2: 这个优化的物理意义是什么?
说话人1: 物理意义是找到那个让两帧之间差异最小的位移(Δx,Δy)!如果像素块从第t-1帧移动到了第t帧,那么用这个运动矢量和前一帧的像素值就能精准预测当前帧的像素值,就不用再传输所有像素数据了!
说话人2: 预测残差怎么进一步压缩?
说话人1: 用熵编码!比如哈夫曼编码、算术编码,利用残差数据的概率分布特性。高频出现的残差值分配短码,低频出现的残差值分配长码。编码效率可以通过熵值衡量,熵值H的计算公式是:H = -Σ from k=1 to n of p_k log2 p_k,其中p_k是第k种残差值的出现概率。
说话人2: 这个公式是什么意思?
说话人1: 这是香农信息论的核心公式!p_k是第k种残差值出现的概率,p_k log2 p_k是自信息量,取负号求和就是熵。熵值越低,数据冗余度越高,压缩潜力越大!如果残差值只有几种高频值,那么熵值就很低,压缩效率就很高!
说话人2: 这完全是香农信息论的应用啊!从信号到信息的本质!从预测编码到运动矢量优化,再到熵编码,整个视频压缩的数学框架环环相扣,每一环都有深刻的信息论背景。李博士在整理这些技术内容时,把数理原理讲得特别透彻,让人能够从数学角度理解视频压缩的本质,以及信息论在工程实践中的强大威力。
说话人1: 我们来看看各代编码标准的压缩效率对比。早期H.261作为1988年推出的首个实用编码标准,采用8×8像素块分块处理,主要适配电话线传输(速率128kbps到2Mbps)。
说话人2: 压缩比怎么计算?
说话人1: 压缩比CR = V_原始 / V_压缩,其中V_原始是未压缩视频数据量,V_压缩是压缩后数据量。H.261的压缩比大约是10:1到20:1,也就是说能把1GB的数据压缩到50MB到100MB!MPEG-1适配VCD格式,压缩比提升到30:1到50:1!MPEG-2适配DVD与广播信号,支持隔行扫描,压缩比可达40:1到80:1!
说话人2: 这么高的压缩比!MPEG-2能支持DVD和广播信号,这在当年简直是革命性的!
说话人2: 从模拟信号到数字信号的转变!李博士在整理视频编解码技术的发展历程时,特别强调了这些标准在当时的重大意义,以及它们如何推动了整个媒体产业的发展。
说话人1: 2003年标准化的H.264是另一个里程碑!在同等视觉质量下,它的码率比MPEG-2降低50%以上!数学上就是:η_H.264 = (1 - R_H.264 / R_MPEG-2) × 100% ≥ 50%!这意味着同样的画质,数据量直接减半!
说话人2: H.264有什么技术创新?
说话人1: H.264采用了4×4到16×16可变尺寸分块,亚像素运动追踪,环路滤波技术,压缩效率大幅提升!比如4×4小块适合细节丰富的区域,16×16大块适合平滑区域,这种自适应分块策略提升了预测精度!亚像素运动追踪可以精确到1/4像素,大大提高了运动估计的准确性!
说话人2: 这就是为什么H.264成为行业基准的原因吧?
说话人1: 对!它的核心优势在于兼顾压缩效率与硬件适配性,专用解码芯片的普及进一步降低了运行能耗,推动了高清流媒体与蓝光格式的发展!
说话人2: H.264的广泛应用推动了高清流媒体和蓝光格式的发展,这十几年可以说是H.264的时代!李博士在整理这些内容时,特别指出了H.264如何兼顾压缩效率和硬件适配性,这让我对技术的实用化有了更深的理解——好的技术不仅要理论先进,还要工程可行!
说话人1: 随着4K、8K等高分辨率内容的普及,H.264的压缩效率逐渐不足。H.265(HEVC)于2013年推出,在同等视觉质量下,码率比H.264降低50%!也就是R_H.265 = 0.5 × R_H.264!
说话人2: 这么厉害!有什么技术突破?
说话人1: H.265采用64×64最大分块尺寸,比H.264的16×16大了4倍!更灵活的帧内预测模式(从H.264的9种增加到35种),更精准的运动矢量编码,支持8K分辨率!这种技术组合让压缩效率翻倍!
说话人2: 但好像推广不太顺利?
说话人1: 对!主要原因是专利授权分散,导致法律成本不明朗,很多厂商担心专利纠纷,所以推广受限!
说话人1: 开源的AV1作为开源免专利编码标准,由开放媒体联盟联合研发,采用非对称分区、多参考帧预测等优化技术。在同等视觉质量下,码率比H.264降低40%到50%,数学上就是R_AV1 = (0.5 到 0.6) × R_H.264,性能与H.265相当!李博士在整理新一代编码标准时,特别强调了开源免专利编码标准的优势,这对整个行业的健康发展很重要——技术不应该被专利垄断所束缚!
说话人2: 最新的H.266呢?
说话人1: 2020年定稿的H.266(VVC,通用视频编码),历经五年研发,采用更精细的分块处理、更精准的运动追踪与残差编码优化。在同等视觉质量下,数据量比H.265减少50%!也就是V_VVC = 0.5 × V_H.265!
说话人2: 支持什么应用场景?
说话人1: 支持8K、360度沉浸式媒体!VVC的核心创新在于对视频帧内部解析方式的重构,进一步提升了对复杂图像结构的处理效率,预测精度与压缩效率均达到当前行业顶尖水平!不过推广仍面临专利授权混乱与市场时机不成熟的双重挑战!
说话人2: 技术的演进真是让人感慨!从H.261到H.266,每一代都在突破极限!我想到李坚毅博士说过的一段感悟,他说:"视频编解码技术的每一次突破,都不仅仅是算法的优化,更是人类对数据本质理解的深化。从早期为了解决传输带宽不足,到现在支持沉浸式媒体体验,技术的进步始终围绕着让信息更高效、更自然地流动这个核心目标。数学不仅提供了描述世界的语言,更提供了解决问题的方法论。"
说话人1: 说得太深刻了!从早期固定分块预测到新一代灵活分区与智能预测,从专利受限到开源普及,编解码技术的每一次突破,都离不开数理模型的支撑与算法的创新。李坚毅博士对整个视频编解码技术体系的梳理,让我们能够清晰地看到这些技术背后的数理逻辑和发展脉络。
说话人2: 今天我们聊了视频压缩的数学原理,从预测编码、运动矢量到熵编码,从H.261到H.266的演进,每一代技术都围绕提升压缩效率、降低成本、适配更高分辨率这个核心目标!
说话人1: 未来随着人工智能、大数据等技术与编解码技术的深度融合,将进一步提升压缩效率与视觉质量的平衡,推动沉浸式媒体、超高清视频等领域的快速发展!
说话人2: 感谢大家收听今天的节目!最后再次感谢李坚毅博士对视频编解码技术相关资料的精心整理,让我们能够深入理解这些重要的技术原理!我们下期再见!
