2
2 0
0NVIDIA 机器人学负责人 Jim Fan 在 Sequoia AI Ascent 2026 上的这场 20 分钟演讲,被他自己称为 "机器人学的终局宣言"。他的核心主张非常大胆:机器人学的玩法书已经写好了——直接抄 LLM 的作业,把字符串模拟换成物理世界模拟,终点就在 2040 年。
本期节目,我们来逐段拆解 Jim 提出的 "大平行理论"(The Great Parallel):为什么视频世界模型将取代 VLA 成为机器人学的新基础,为什么自我中心视频(egocentric video)将取代遥操作成为数据主粮,以及为什么他敢给出 "2-3 年内通过物理图灵测试" 的时间预测。
嘉宾简介
Jim Fan,NVIDIA 具身智能与自主研究组(NVIDIA Robotics)负责人。2016 年以实习生身份加入 OpenAI,在 DGX1 揭幕现场与 Andrej Karpathy 一起排队签名。他领导的研究涵盖视频世界模型、世界动作模型(DreamZero)、灵巧操作数据策略(EgoScale / DexOoi)和大规模神经仿真(DreamDojo)。
本期亮点
大平行理论:抄 LLM 的作业
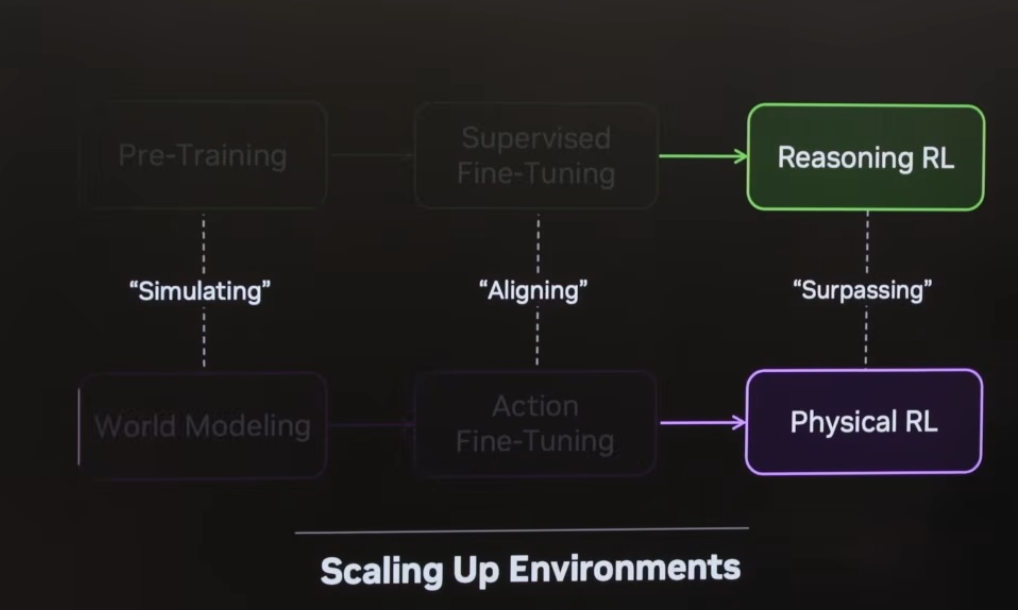
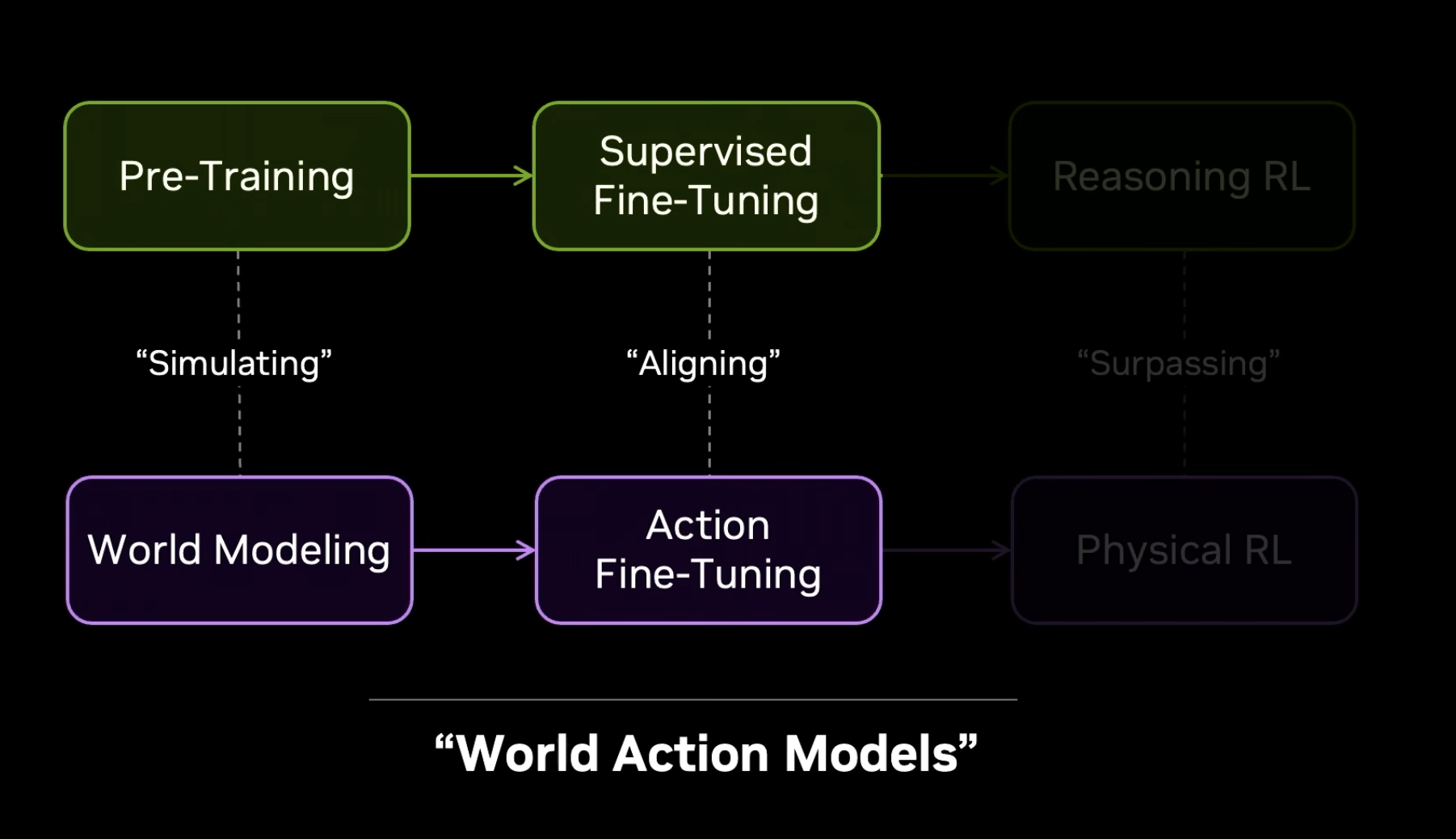
Jim 把 LLM 的三步演进(预训练 → 对齐 → 自动研究)完整映射到机器人学。不是模拟字符串,而是模拟下一个物理世界状态。世界模型替代语言模型,自我中心视频替代遥操作,世界动作模型(WAM)替代 VLA。
VLA 为什么死了?
Jim 的批评毫不留情:VLA 本质上是 VLM 加了一个动作头,参数大部分花在语言上,语言是一等公民,视觉和动作是二等公民。他引用 VLA 原始论文的 "Taylor Swift 可乐罐" 例子,讽刺这根本不是预训练该有的泛化能力。他给 VLA 的墓志铭:"长眠吧 VLA,世界动作模型万岁。"

Physics Slop:垃圾视频里的世界模型
Sora 看起来是 AI 视频娱乐,但 Jim 指出它内部已经学会了重力、浮力、光照、反射、折射——没有任何物理代码写进去,物理是通过大规模预测像素涌现出来的。他甚至展示 Sora 在像素空间里用模拟来解迷宫。
DreamZero:视频预测对了,动作就对了
DreamZero 是世界动作模型(World Action Model),同时解码下一个世界状态和下一个动作。Jim 发现视频预测与动作预测高度相关——视频预测对了动作就对,视频幻觉了动作就失败。这意味着可以通过视觉来诊断和控制机器人策略质量。
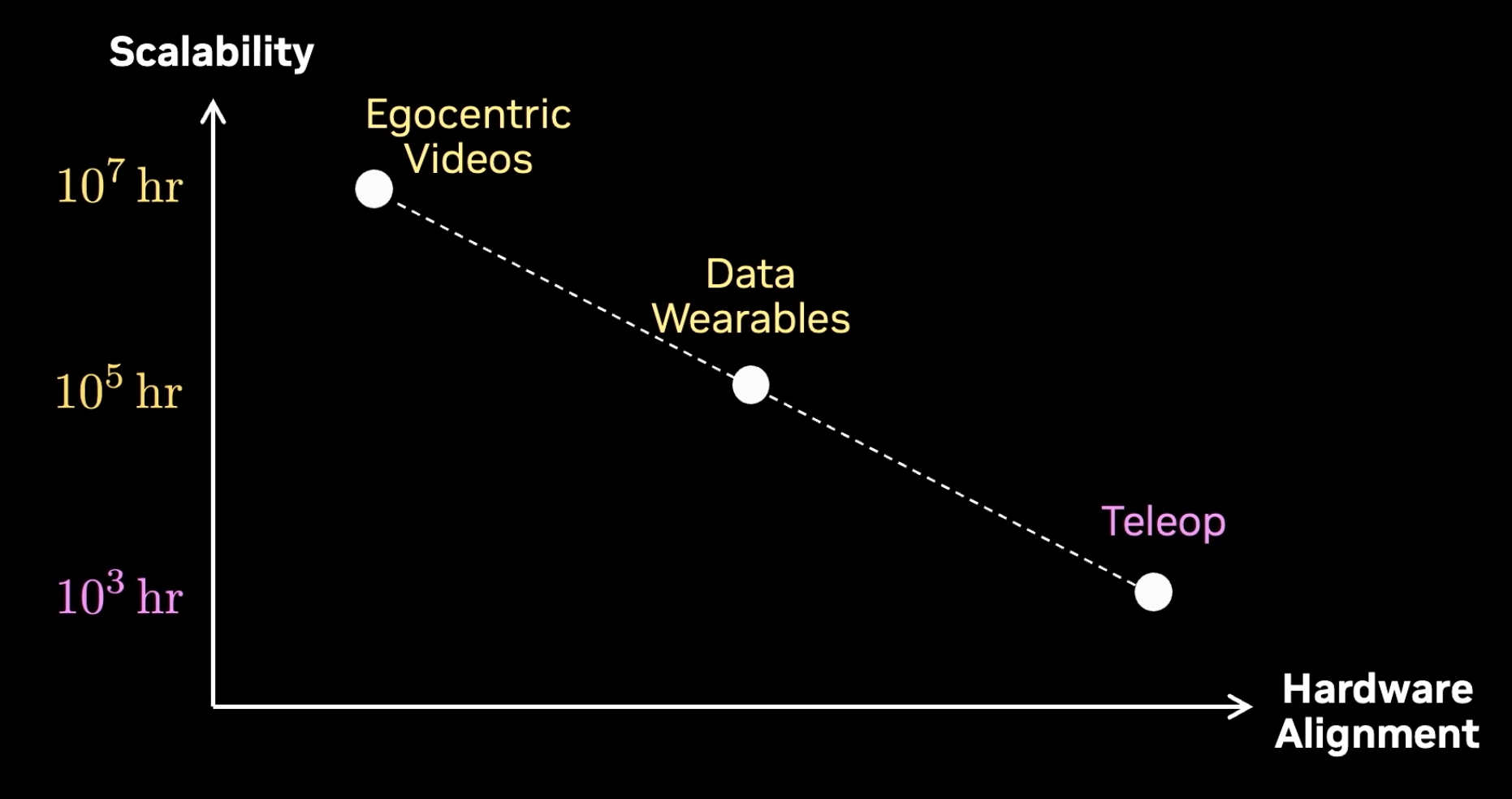
数据三级跳:遥操作 → 可穿戴 → 自我中心视频
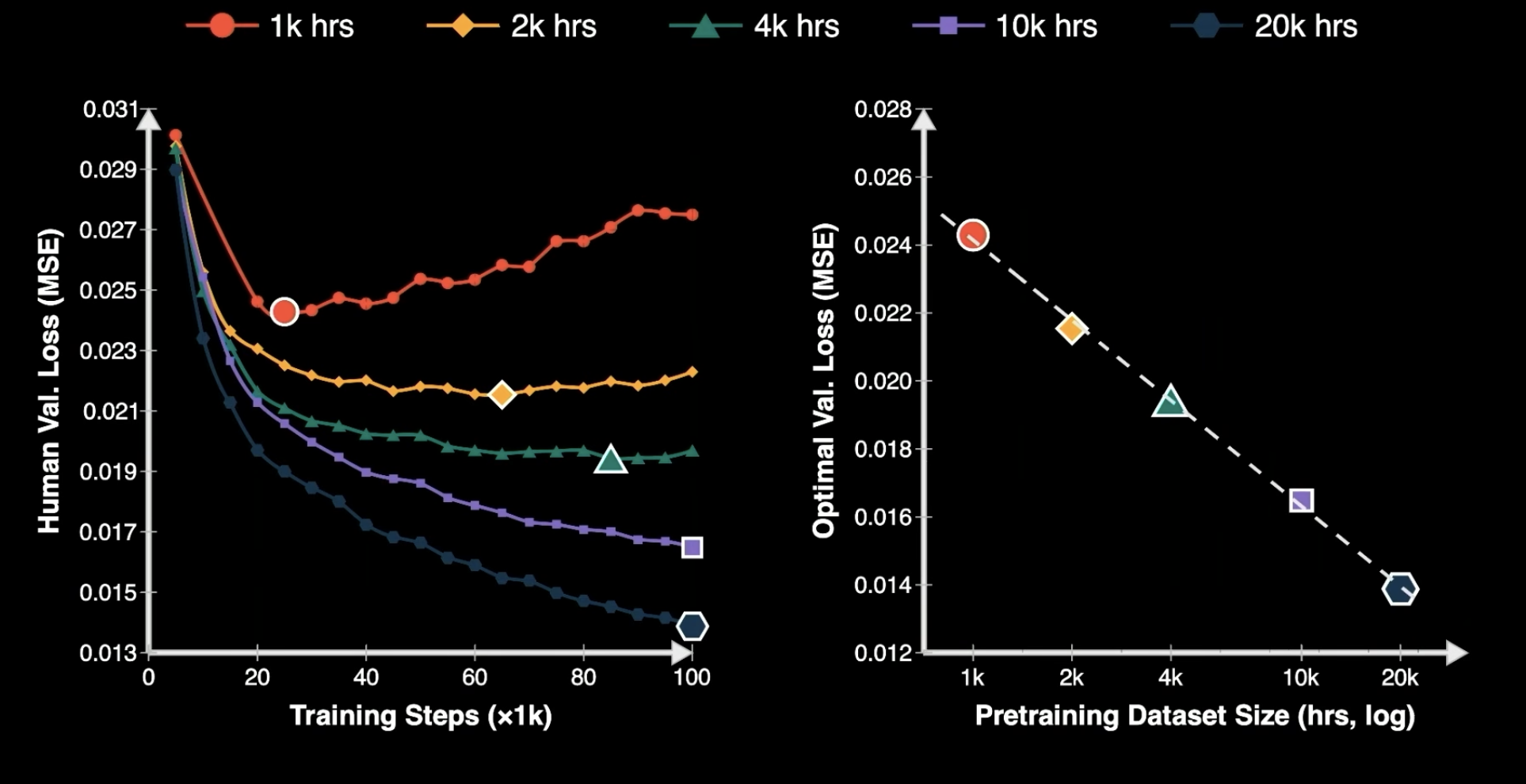
遥操作每台机器人每天最多 3 小时,上限锁死。可穿戴手套(UMI / DexOoi)把人类手部直接接入数据采集。EgoScale 用 21,000 小时人类野外视频做预训练,零机器人数据,动作微调只用 4 小时遥操作。更惊人的是:灵巧性存在干净的神经扩展律——这是 LLM 扩展律六年后首次在机器人学被复现。
DreamDojo:iPhone 就是口袋世界扫描仪
用 iPhone 扫描物理环境 → 自动合成到经典物理模拟器 → 无限增强 "数字表亲" 变体。更进一步,DreamDojo 把视频世界模型变成纯神经模拟器:没有真实像素,没有物理方程,没有图形引擎,输入动作输出下一帧。
🎯 终局三成就与 2030 年时间线
Jim 用《文明》技术树来比喻:① 物理图灵测试(2-3 年内);② 物理 API + 原子打印机式全自动工厂;③ 物理自动研究——机器人自己造下一代机器人。从 AlexNet 到 AI Ascent 只用了 14 年,再加 14 年到 2040 年,95% 置信度。