


 274
274 0
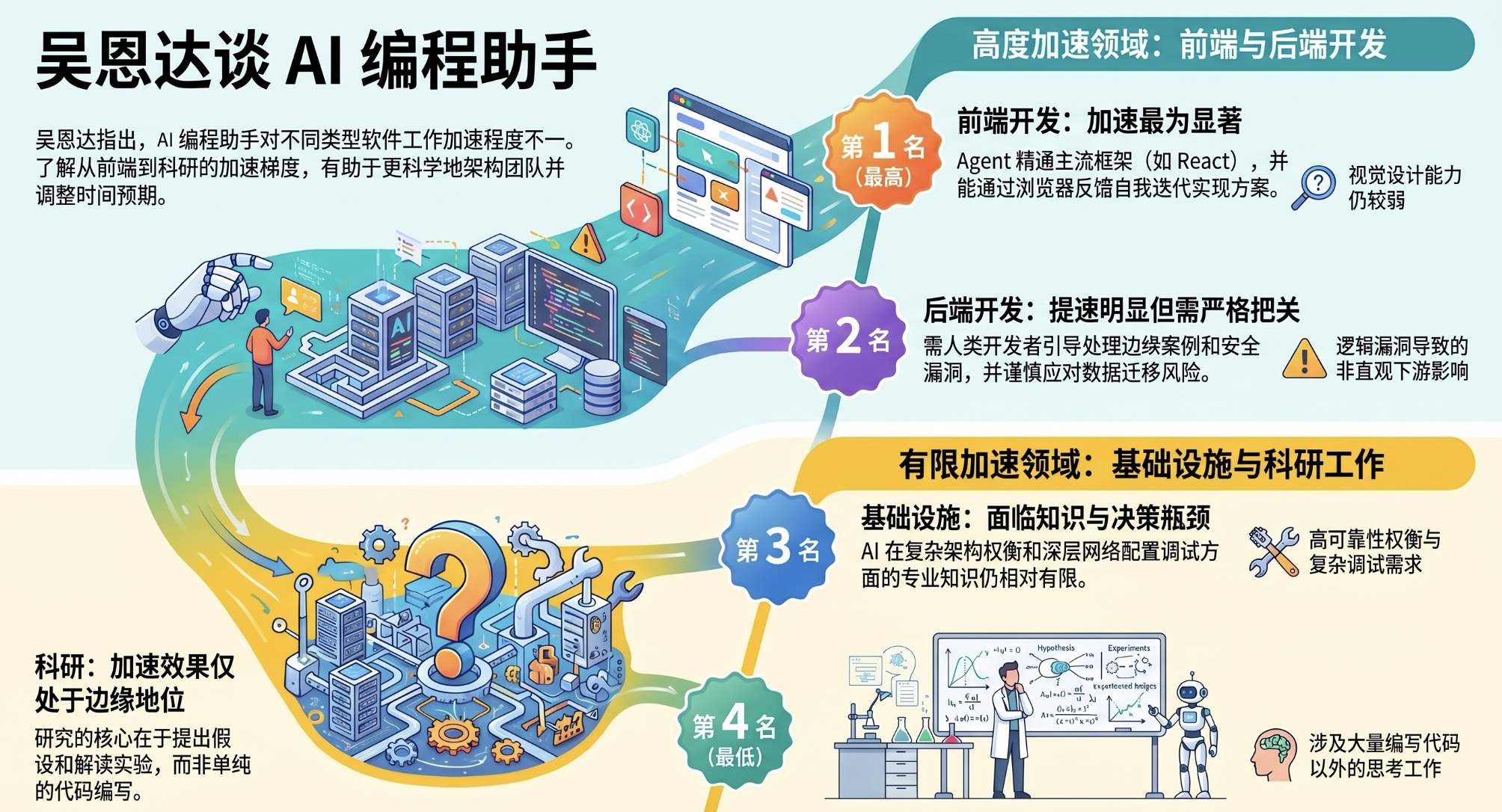
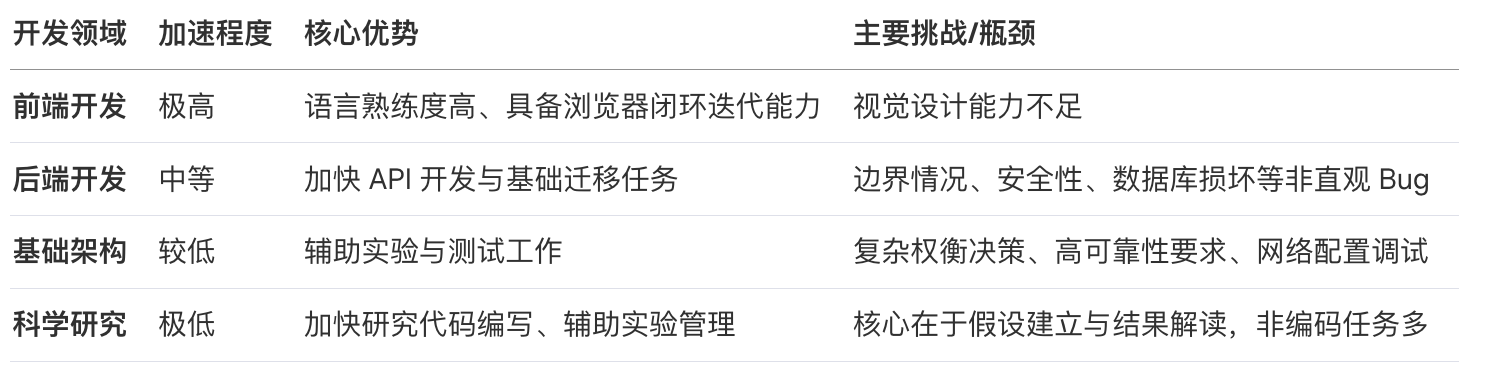
0本报告基于吴恩达(Andrew Ng)的观察,深入探讨了代码智能体(Coding Agents)如何改变软件开发的工作流。核心结论指出,代码智能体对开发效率的提升并非在所有领域都是均等的。根据技术复杂性、决策维度及调试难度的不同,其加速作用呈现出明显的阶梯式差异。目前的加速程度排序为:前端开发 > 后端开发 > 基础架构 > 科学研究。这一认知框架对于管理人员调整团队预期、优化组织架构具有重要的指导意义。
一、软件开发各环节的加速程度深度分析
1. 前端开发(加速程度:最高)
前端开发是受代码智能体影响最深、提速最显著的领域。
技术适配性: 代码智能体精通主流前端语言(如 TypeScript 和 JavaScript)及框架(如 React 和 Angular),能快速生成高质量的实现代码。
闭环迭代: 智能体现在具备操作浏览器并检查构建成果的能力。这种“观察-调整”的闭环能力使其能够自主迭代并完善实现方案。
局限性: 尽管在代码实现上表现出色,但目前的底层大语言模型(LLMs)在视觉设计感方面仍然较弱。
结论: 在已有设计稿或对视觉美观度要求不高的情况下,前端实现的效率已得到飞跃式提升。
2. 后端开发(加速程度:中等)
相比前端,后端开发的复杂性更高,对人类开发者的依赖程度也更深。
逻辑复杂性: 后端开发涉及大量的边界情况(Corner Cases)。引导模型思考这些细微之处以避免安全漏洞或逻辑缺陷,需要人类开发者投入大量精力进行“导航”。
调试难度: 后端错误往往具有隐蔽性和非直观的下游效应。例如,一个细微的 Bug 可能导致数据库损坏并偶尔返回错误结果,这种问题的排查难度远高于前端 Bug。
数据安全风险: 尽管智能体可以协助处理数据库迁移,但该过程极具风险,必须谨慎处理以防数据丢失。
结论: 尽管开发速度有所提升,但资深开发者在构建高性能、高安全性后端方面的价值依然不可替代。经验匮乏的开发者即便使用智能体,也无法达到同等水平。
3. 基础架构(加速程度:较低)
在涉及高可靠性和复杂权衡的基础架构领域,代码智能体的贡献相对有限。
知识储备不足: LLMs 对于基础架构相关的复杂权衡(Tradeoffs)认知有限。例如,在追求 99.99% 的可靠性同时将站点扩展至 1 万活跃用户,这类决策需要深厚的专业背景。
实验瓶颈: 构建优秀的基础架构需要长期的测试与实验周期。虽然智能体可以协助部分测试工作,但核心环节依然是进度缓慢的人工过程。
故障排查难度: 基础架构的 Bug(如细微的网络配置错误)极其难以定位,需要极深的技术专家经验,这超出了目前智能体的能力范围。
结论: 在关键的基础架构决策和故障处理中,人类专家的经验仍然是核心,智能体加速效果不明显。
4. 科学研究(加速程度:最低)
研究工作因其高度的非代码属性,受智能体的影响最小。
研究流程的复杂性: 研究本质上是一个“思考新想法 -> 建立假设 -> 运行实验 -> 解读结果 -> 修正假设”的迭代过程。
非代码任务占比: 虽然智能体可以加快研究代码的编写速度,并协助编排和跟踪实验(使研究员能同时管理更多实验),但研究中的大部分工作并非编码。
结论: 目前代码智能体对研究效率的整体提升仅处于边缘地位。
二、效能对比摘要表
三、管理决策建议
了解代码智能体在不同领域的效能差异,对于构建高效软件团队至关重要:
调整产出预期: 团队领导者应要求前端团队实现比一年前“大幅缩短”的交付周期,但对于研究团队,其进度预期不应有太大变化。
人才配置: 在后端和基础架构等领域,不能盲目依赖 AI 替代资深开发者。智能体可以作为提效工具,但复杂的架构设计和关键决策仍需由经验丰富的专业人士把控。
心智模型构建: 组织应采用这种“分层加速”的心智模型,来评估 AI 工具在不同部门的实际投入产出比。
📺相关链接与资源
[文章来源]www.deeplearning.ai
本播客采用虚拟主持人进行播客翻译的音频制作,因此有可能会有一些地方听起来怪怪的。如想了解更多信息,请关注微信公众号"AI西经东译"获取AI最新资讯。如有后续想要听的其他外文播客,也欢迎联系微信:mayday2303。
