

 1
1 0
0Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics (2021) 解读与学习
随着全球数字化转型的不断深入,企业所面临的数据环境正在经历前所未有的剧变。根据国际数据公司(IDC)的预测,到2025年,全球数据圈(Datasphere)的总量预计将达到惊人的175 ZB(Zettabytes)。这种呈指数级增长的数据不仅体现在绝对体积上,更体现在数据生成的速度、来源的多样性以及结构的复杂性上。来自移动应用程序、物联网(IoT)传感器、企业操作系统以及社交媒体平台的连续数据流,彻底颠覆了早期企业信息化时代所建立的数据管理常识。在这一宏观背景下,企业级数据管理平台的底层架构在过去十余年中经历了几次深刻的范式变迁。根据2021年创新数据系统研究大会(CIDR)上由Michael Armbrust、Matei Zaharia等人发表的开创性论文《Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics》,传统数据仓库架构在未来几年内将逐渐式微,并被一种被称为“湖仓一体(Lakehouse)”的新型架构模式所取代。这一论断不仅在学术界引发了广泛探讨,更在随后的几年中深刻重塑了整个数据与人工智能行业的商业生态与技术路线。本研究报告旨在全面提炼与总结湖仓一体架构的历史脉络、核心技术支柱、开源生态演进、商业战略博弈,以及学术界与工业界对其在真实生产环境中面临的挑战与未来在智能体(Agentic AI)时代的发展趋势。
数据平台架构演进的历史脉络与范式重构
要深刻理解湖仓一体架构的崛起,必须追溯数据分析平台的世代演变,因为每一次架构的更迭都是为了解决上一代架构在面临新业务需求时所暴露出的根本性瓶颈。
第一代数据分析平台以传统数据仓库(如Teradata或早期的Oracle数仓系统)为代表,其核心特征是计算与存储高度耦合的本地一体机模式(On-premises appliance)。在这种范式下,企业主要致力于将运营数据库(Operational databases)中的结构化数据提取至集中的仓库中,以支持商业智能(BI)和决策支持系统。这一代平台严格采用“写时模式(Schema-on-write)”,这意味着数据在进入系统之前必须经过严格的清洗、转换和预定义建模,从而确保下游BI消费端能够获得高度优化和高保真的数据质量。然而,随着数据规模的爆发,这种高度耦合的架构显露出了致命的缺陷。企业被迫按照预估的峰值用户负载和最大数据管理量来预先采购昂贵的硬件设备,导致资源利用率极低且总体拥有成本(TCO)极其高昂。更严重的是,随着视频、音频、文本文档等完全非结构化数据在企业总数据资产中的占比越来越大,传统数据仓库根本无法摄取、存储和查询这些异构数据源,成为了企业获取全景洞察的结构性障碍。
为了打破这一瓶颈,工业界在大约十年前开启了向第二代数据分析平台的演进,确立了“数据湖+数据仓库”的双层架构模式(Two-tier Architecture)。在这一阶段,企业开始将海量原始数据从业务系统中剥离,转储至低成本的数据湖中。早期的实践主要基于Apache Hadoop生态运动,利用Hadoop分布式文件系统(HDFS)提供廉价的集群存储。随后,随着云计算的普及,诸如Amazon S3、Azure Data Lake Storage (ADLS) 和Google Cloud Storage (GCS) 等云原生对象存储系统逐渐取代了HDFS。这些云数据湖提供了卓越的持久性(通常达到11个9的可靠性)、跨地域复制能力以及极低的存储成本,甚至支持自动将冷数据归档至更为廉价的存储层(如AWS Glacier)。数据湖体系全面拥抱了“读时模式(Schema-on-read)”,以Apache Parquet或ORC等通用开放文件格式存储数据,赋予了数据极大的摄取灵活性,彻底解决了非结构化和半结构化数据的存储难题。然而,这种灵活性是建立在妥协之上的——数据湖将数据质量控制和治理的难题推迟到了下游链路。在典型的双层架构中,海量原始数据首先进入数据湖,随后,一小部分具有高商业价值的数据子集会被通过复杂的ETL(提取、转换、加载)管道清洗、聚合,并最终导入至下游的云原生数据仓库(如Redshift、Snowflake或BigQuery)中,以支持关键的商业智能报表。
尽管这种“数据湖+数据仓库”的双层架构在物理上实现了低成本海量存储与高性能查询的折中,并且在财富500强企业中占据了绝对的统治地位,但它在逻辑与运维层面引入了极大的“偶然复杂性(Accidental Complexity)”。根据大量企业级部署的反馈与研究数据,这种双层架构体系在当今的商业环境中面临着四个难以逾越的严峻系统性问题。
首先是数据可靠性受到严重破坏。在独立的湖与仓之间维持数据语义的一致性是一项极其困难且昂贵的工程任务。由于数据湖与数据仓库往往由不同的底层引擎驱动,它们在支持的数据类型、SQL方言甚至底层精度处理上存在微妙的差异。企业必须部署和维护持续运行的ETL/ELT数据管道以在两个系统间搬运数据。每一个ETL步骤都增加了系统故障的概率,同时也极易引入潜伏的逻辑漏洞,导致数据质量的无声退化。
其次是致命的数据陈旧性(Data Staleness)。现代商业竞争要求极高的敏捷性,客户支持系统、实时推荐引擎以及供应链预测等业务应用依赖于绝对实时的洞察反馈。然而,由于数据必须经过独立的暂存区,并依赖周期性的批处理ETL作业才能最终加载至数据仓库,导致仓库中的数据相对于数据湖往往存在严重的滞后,新数据的加载周期甚至长达数天。这种由于架构物理隔离带来的延迟被证明是对业务响应能力的极大削弱。一项由Dimensional Research和Fivetran联合发布的大规模分析师调查揭示了这一痛点的严重程度:高达86%的受访分析师承认他们经常不得不使用过时的数据进行决策分析,而62%的分析师报告称他们每个月都会多次因为等待工程团队的ETL资源而被迫中断分析工作。
第三个严峻挑战在于对高级分析与机器学习(ML)支持的结构性受限。现代企业对数据的期望早已超越了历史趋势的BI报表,他们更希望利用海量数据进行预测性建模(例如实时计算“哪些客户流失的风险最高,应立即给予折扣?”)。然而,当今主流的机器学习和深度学习框架(如TensorFlow、PyTorch和XGBoost)完全无法在数据仓库的架构之上高效运行。由于这些框架通常依赖复杂的非SQL代码(如Python或C++)在内存中迭代处理极其庞大的数据集,它们无法通过传统的ODBC/JDBC连接器高效地从数据仓库中提取数据。同时,商业数据仓库由于其闭源性质,彻底切断了机器学习引擎直接读取其底层专有格式存储文件的路径。面对这一死局,数仓供应商通常给出的建议是让用户将数据从仓库中重新导出为平面文件——这荒谬地引入了第三条ETL链路,进一步增加了系统的脆弱性、成本与数据延迟。数据科学家们不得不绕过仓库,直接在数据湖中读取Parquet文件,但这样一来,他们又彻底失去了数据仓库所提供的丰富管理特性,如ACID事务、并发隔离、数据版本控制以及高效的索引机制,导致模型训练常常受到“脏数据”的干扰。
最后,总体拥有成本(TCO)高昂与供应商锁定成为了双层架构难以摆脱的阴影。除了为了维持脆弱的ETL管道而支付的高昂工程师人力成本外,企业还必须为同一份数据支付双重的存储费用(一份在廉价的湖中,一份在昂贵的仓中)。此外,商业云数据仓库通过专有的数据格式“劫持”了高价值数据,人为抬高了企业未来将工作负载或数据资产迁移至其他更优系统的壁垒,形成了实质性的数据孤岛与供应商锁定。
正是在上述矛盾日益尖锐的背景下,湖仓一体架构应运而生。其核心科学问题在于:是否有可能以诸如Parquet和ORC等开放的、标准的、允许直接访问的数据格式为基础,构建出一个兼具数据仓库的高性能、强管理特性,又能让高级分析工作负载直接以极高吞吐量进行I/O交互的新一代系统? 湖仓一体的设计理念就是要在单一平台上弥合数据仓库的治理能力与数据湖的灵活性,通过统一的基础设施满足从实时摄取、大规模数据清洗、合规性审计、商业智能高并发查询到深度学习特征提取的全生命周期需求。
湖仓一体架构的技术奠基与三大核心支柱
湖仓一体并非简单的营销词汇重组,而是一系列底层数据结构设计与分布式计算系统工程的革命性突破。正如Armbrust等人所阐述的,湖仓一体的可行性与优越性坚实地建立在三大核心技术支柱之上,这三大支柱共同构成了新一代数据平台的理论基础与工程实践蓝图。
支柱一:覆盖对象存储的事务性元数据管理层
湖仓一体的第一个技术支柱是彻底改变数据湖底层文件松散无序的组织方式,通过引入事务性元数据层(Transactional Metadata Layer),在维持海量低成本云对象存储不变的前提下,向上层提供类似关系型数据库的强一致性管理接口。传统数据湖系统的底层存储(如S3或HDFS)仅仅提供极其基础的文件系统API,缺乏原生的原子操作能力。这意味着在一个跨越多个Parquet文件的表中执行哪怕最简单的更新或删除操作时,如果系统发生崩溃,都会留下部分修改的损坏状态,导致并发读取者查看到不一致的脏数据。
为了解决这一问题,业界开始设计更为复杂的元数据管理机制。早期的尝试如Apache Hive ACID,利用传统的OLTP数据库来跟踪哪个数据文件在哪个时刻属于Hive表的一部分,并在外部数据库中实现事务更新。然而,这种架构在面对云端海量小文件时扩展性极差。随后的几年中,一系列具有突破性设计的原生数据湖元数据管理层相继涌现,其中以Delta Lake、Apache Iceberg和Apache Hudi最为著名。
以Databricks主导研发的Delta Lake为例,它巧妙地打破了将元数据存储在外部操作型数据库中的惯例,选择将“哪些文件属于当前有效表”的事务日志(Transaction Log)直接以Parquet格式与原始数据并排存储在底层对象存储系统中。这种设计不仅消除了对外部系统高可用性的依赖,更使得元数据层本身能够像数据一样轻松扩展至包含数十亿个对象的超大规模。借助这种带有严格排序和隔离机制的事务日志,湖仓一体不仅能够提供原生的ACID事务保障,还自然而然地催生了诸如零拷贝克隆(Zero-copy cloning,允许在不复制底层物理文件的情况下瞬间复制表结构用于实验)以及时间旅行(Time travel,支持对特定时间点的历史快照进行查询或从意外删除中恢复)等极具价值的高级功能。
此外,事务性元数据层还充当了数据湖数据质量的“第一道防线”。系统可以在该层实现严格的模式强制(Schema Enforcement),确保上游流入系统的数据结构严格匹配表的定义,彻底杜绝数据类型错乱。同时,借助约束API(Constraints API),表所有者能够对写入的数据实施业务规则级别的校验(例如设定某一特定列的取值范围),系统客户端会自动拦截不符合预期的数据记录并将其路由至隔离区(Quarantine),从而在源头上净化了数据管道,使得湖仓一体能够在存储原始数据的同时,无缝支持对其进行加工治理的ETL/ELT闭环。
支柱二:面向机器学习与数据科学的声明式计算抽象
如果说元数据层解决了“数据的治理与可靠性”问题,那么湖仓一体的第二个关键支柱则聚焦于“如何让高级分析引擎以前所未有的效率直接消费这些受治理的数据”。
在传统架构下,机器学习模型训练的瓶颈往往不在于GPU计算,而在于CPU上的数据加载与准备(Data Loading and Preparation)环节。大部分高级分析库都是采用基于内存的命令式代码(Imperative code)编写的,无法像关系型数据库引擎那样在执行前对SQL计划进行全局成本评估与算子下推优化。为了解决这一系统间的不匹配,湖仓一体深度利用了数据帧(DataFrame)抽象这一强大的接口协议。
DataFrame最初由R语言和Python的Pandas库普及开来,为数据科学家提供了一个极其直观的表格式操作模型。在以Apache Spark为代表的现代分布式计算框架中,DataFrame API被进一步升级为“声明式(Declarative)”接口。当用户在TensorFlow、Spark MLlib或自定义Python脚本中调用DataFrame执行诸如过滤(Filter)、聚合(Aggregate)或连接(Join)等转换操作时,底层引擎并不会立即在内存中扫描数据,而是采用延迟评估(Lazy Evaluation)策略,捕获用户的意图并构建出一棵由逻辑算子组成的抽象语法树(AST)。
这一机制的革命性意义在于:Spark或类似计算引擎的优化器现在可以将这棵逻辑语法树深度下推(Push-down)至湖仓一体的数据源插件(Data Source Plugin)层级。这意味着,用户的机器学习负载能够直接且透明地利用Delta Lake等底层的索引机制、数据跳过逻辑(Data Skipping)甚至列修剪(Column Pruning)功能,仅从云对象存储中提取模型训练绝对必要的最少字节数,彻底绕过了传统数据仓库必须将全量数据通过JDBC串行拉取到应用层再进行过滤的性能泥潭。这种架构不仅极大地加速了数据管道,还使得诸如MLflow等实验追踪框架能够与湖仓的时间旅行特性深度集成,确保了数据科学实验的严格可复现性(Reproducibility)。
支柱三:基于开放格式的极致SQL性能优化与数据布局技术
然而,湖仓一体若要彻底替代云数据仓库,面临的最核心的技术质询是:在放弃了传统DBMS引以为傲的“数据独立性(Data Independence)”、必须将底层数据格式(如Parquet)作为允许外部引擎直接访问的公共API暴露的前提下,如何才能追平甚至超越那些采用闭源专有格式极致榨取硬件性能的商业数据仓库的SQL查询速度?
这是一个极具挑战性的系统工程难题。研究表明,湖仓一体可以通过一整套独立于文件格式之外的性能优化层来弥合这一差距。具体而言,主要依赖三大核心优化手段:
首先是智能缓存层(Caching)。得益于底层的ACID事务元数据机制,湖仓计算引擎能够准确地知道对象存储中的文件是否发生了变更。这使得系统能够安全地将大量频繁访问的热数据从延迟极高的S3或ADLS预先拉取,并缓存至处理节点的NVMe SSD甚至是主内存中,且无需担心读取到脏数据。更进一步,这些缓存数据无需保持云端的Parquet原生状态,湖仓引擎可以将其动态转码(Transcoding)为一种更适合CPU向量化执行(Vectorized Execution)的内部高效格式,从而在内存中复现传统闭源数据仓库的极致扫描速度。
其次是构建丰富的辅助数据结构与索引体系(Auxiliary Data Structures)。尽管Parquet文件本身是静态且开放的,但湖仓系统可以在元数据层维护极其精细的辅助信息。例如,系统可以在事务日志中记录数据湖中每一个物理文件内部各个列的最小/最大值边界(Min-Max Statistics)。当执行一个包含过滤条件的SQL查询(如SELECT * FROM sales WHERE date = '2025-01-01')时,优化器会首先检查元数据,直接跳过那些极值范围不包含目标日期的庞大数据块(Zone Maps),实现大规模的数据跳过(Data Skipping)。此外,布隆过滤器(Bloom filter)等高级索引结构也被引入,以进一步加速对高基数(High-cardinality)列的点查性能。
最后也是最关键的是数据物理布局的深度优化(Data Layout Optimization)。在海量冷数据(未能命中SSD缓存)的扫描场景下,最大的性能瓶颈是跨越网络读取冗余对象的I/O开销。湖仓一体系统引入了极其复杂的数据聚簇(Clustering)算法来重塑数据的物理分布。除了简单地根据单维度排序外,湖仓架构支持使用多维空间填充曲线(Space-filling curves,如Z-order和Hilbert曲线)对记录进行重排。这种技术能够打破多列查询时的局部性诅咒,使得同时按时间、地理位置、用户ID查询时,相关的记录在物理文件内部高度紧凑相邻,从而使得文件级的统计信息(Min-Max)变得极为紧密,极大地放大了数据跳过优化的威力。
为了验证这一系列优化技术的有效性,Armbrust等人在CIDR 2021的论文中展示了一组极具说服力的基准测试结果。通过在包含10万个节点规模的系统上运行行业标准的TPC-DS测试(涵盖99个极度复杂的企业级SQL查询,并在30,000比例因子下测试),搭载了上述优化技术的Databricks Delta Engine(一种用C++重写底层执行层面的Spark引擎)不仅在执行时间上匹敌甚至超越了当时AWS、Azure和Google Cloud上四种主流的流行云原生数据仓库,同时还在按需(On-demand)和竞价(Spot)实例的计费模式下实现了更为优越的总体运行成本。这一量化结果在学术界和工业界引起了轰动,标志着基于开放格式的架构在性能上不再是被动妥协的代名词。
多维架构范式对比:数据湖、数据仓库与湖仓一体的演进逻辑
为了更为系统地廓清不同数据基础设施的适用场景与演进路径,我们需要在更加微观的技术维度上对比数据仓库、数据湖与湖仓一体。下表综合了行业内广泛认可的最佳实践与特征分析,展示了这三种架构在核心维度上的显著差异与能力演进。
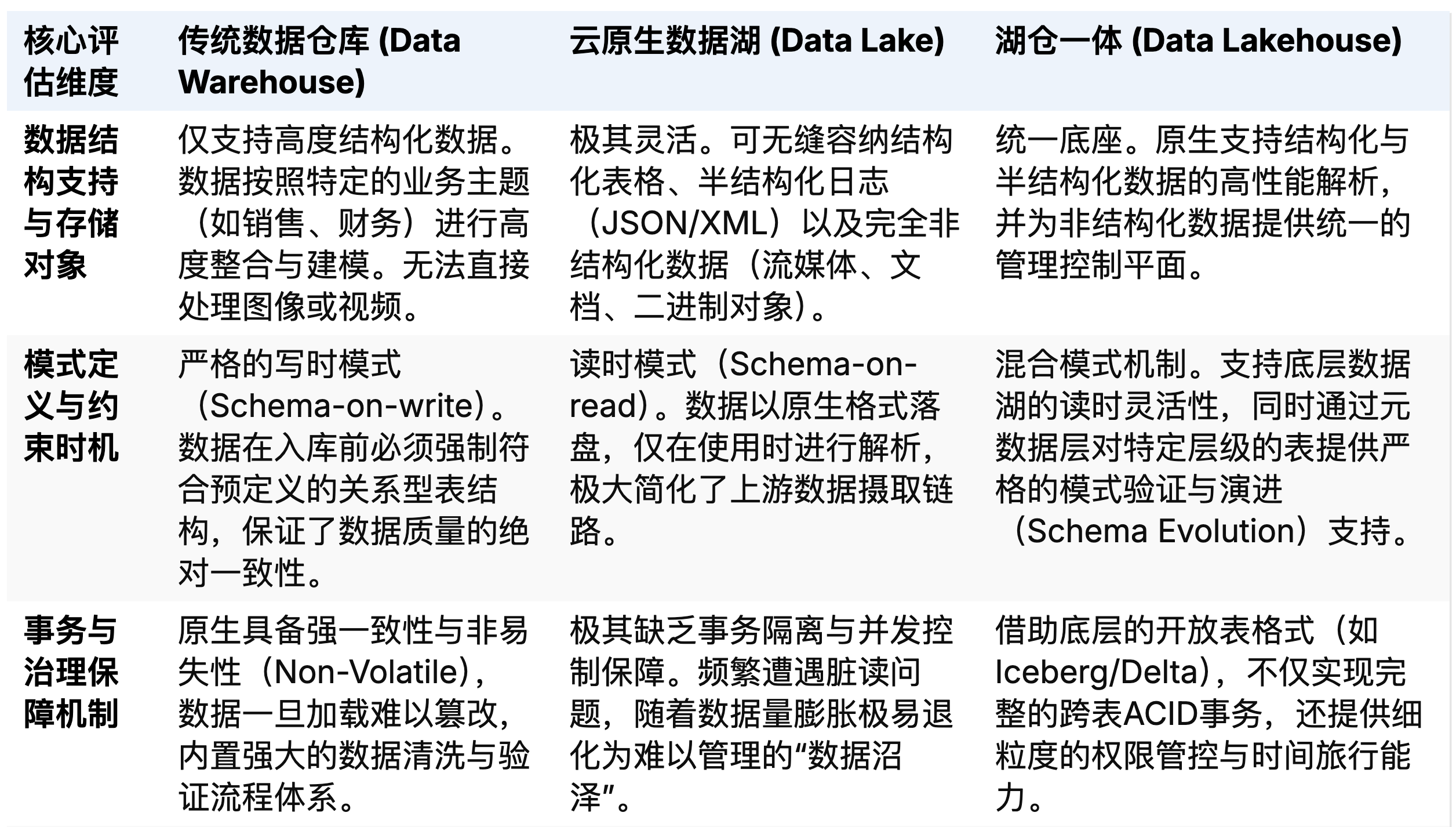

从架构逻辑的深层推演来看,这不仅是一场技术参数的堆砌战,更是一次打破企业组织部门墙的生产力解放。在数据孤岛横行的年代,数据工程师痛苦于维护庞杂的ETL作业网络,业务分析师受困于僵化的BI模型,而数据科学家由于缺乏高质量的数据源只能将时间浪费在底层的数据清理上。湖仓一体通过提供单一的逻辑事实来源(Single Source of Truth),从根本上促成了这三类核心数据角色的底层语义对齐,极大缩短了企业从原始数据摄取到人工智能模型推理上线的端到端价值转化周期。
开放表格式生态的深水区:架构设计与生态演进 (2021-2026)
湖仓一体概念的提出彻底引爆了底层数据存储格式标准化的竞赛。在随后的数年间,业界并未走向单一寡头垄断,而是爆发了一场关于“开放表格式(Open Table Formats)”的技术路线之争。随着时间推移至2025年,Apache Iceberg、Delta Lake和Apache Hudi作为三大核心标准,各自演化出了截然不同的架构哲学,并在技术深水区展开了残酷的博弈与最终的融合。
Apache Iceberg:生态标准化与多引擎互操作的通用语言
由Netflix最初孵化的Apache Iceberg代表了“规范先行(Spec-first)”的设计巅峰。Iceberg的设计理念并不依附于任何特定的计算引擎,它的本质是一个经过极其严密定义的三层树状元数据结构(Metadata Tree)。这种结构通过元数据文件(Metadata file)、清单列表(Manifest list)和清单文件(Manifest files)的层级关系,精确追踪到底层每一个数据文件的快照变更。
Iceberg的引擎中立性使得它在随后的几年内迅速成为了行业的“通用互操作语言”。在并发控制机制上,Iceberg采用了乐观并发控制(OCC)。此外,它首创了隐藏分区(Hidden Partitioning)和分区演进(Partition Evolution)机制,使得表结构的变更对终端用户彻底透明,极大地降低了数据工程的运维负担。到了2025年,Iceberg的REST Catalog协议已经演变为了事实上的行业标准网关,被包括Snowflake (Polaris Catalog)、Databricks (Unity Catalog)、Google BigQuery (BigLake Metastore) 和 AWS (S3 Tables) 在内的所有主流云巨头全面原生集成——实现了“一套API规范,对接所有引擎”的宏大愿景。在更前沿的Iceberg V3规范中,社区甚至在引擎层面引入了通过行级数据血缘检测支持变更数据捕获(CDC)的能力,进一步确立了其在复杂数据工程流水线中的核心地位。
Delta Lake:深耕Spark生态的极致工程与性能闭环
相较于Iceberg的中立哲学,由Databricks主导开源的Delta Lake则走了一条“极致原生与深度绑定”的路线。Delta Lake的底层架构摒弃了复杂的元数据树,而是采用了一种极其简洁的、基于JSON和Parquet文件的仅追加(Append-only)事务日志体系。这种看似简单的架构在与Apache Spark这一大规模分布式内存计算框架深度结合时,爆发出令人瞩目的稳定性与极高的吞吐性能。
Delta的强项在于它为大规模数据转换(Data Transformation)量身定制了一系列开箱即用的湖仓管理功能。例如,其在处理小文件积压时拥有极其高效的后台文件合并(Compaction)机制,以及基于OPTIMIZE命令的自动空间填充优化。然而,正是这种对Spark生态的深度依赖,使得Delta在面对更为广阔的查询引擎生态时显得力不从心。当数据工程师尝试在Spark之外的环境(例如使用分布式SQL引擎Presto或Trino进行即席查询)中运行Delta表时,往往会面临原生的配置瓶颈和陡增的系统复杂性。
Apache Hudi:流式优先、高并发变更与非阻塞写入的霸主
如果说Iceberg和Delta专注于解决大规模批处理与分析型数仓的痛点,那么脱胎于Uber的Apache Hudi(Hadoop Upserts Deletes and Incrementals)则完全是为解决海量高频的增量变更和流媒体数据摄取而生的。在架构定义上,Hudi社区更倾向于将自己定义为一个全功能的“数据湖仓管理系统(Data Lakehouse Management System, DLMS)”,而不仅仅是一个薄薄的元数据层表格式。
Hudi的底层架构围绕着一条严格的时间轴(Timeline-based architecture)展开,详细记录了在表上执行的每一次动作(如提交、清理、合并)。其最为致命的核心竞争力在于其无与伦比的并发控制机制。对于需要高频执行记录级更新(Upserts)和删除操作,且存在多条流式管道并发写入的场景而言,Iceberg和Delta所采用的乐观并发控制(OCC)往往会导致严重的事务冲突,迫使写操作不断回滚重试,拖垮整个集群性能。而Hudi通过实施多版本并发控制(MVCC)与非阻塞并发控制(Non-Blocking Concurrency Control),并结合多达8种以上的可插拔记录级索引(Record-level indexing)机制,完美实现了在海量并发更新时的读写隔离,使得读取和写入操作互不阻塞。此外,Hudi内置的DeltaStreamer等受管摄取服务,自动化的聚簇、压缩与死区清理服务,使其在处理 CDC(变更数据捕获)密集型业务场景时拥有着不可撼动的统治力。
从格式战争到大一统:翻译层的崛起与真正的破局
长达数年的表格式标准之争虽然极大地推动了技术的繁荣,但也给企业带来了痛苦的格式站队风险与生态碎片化灾难。随着系统复杂性的指数级上升,强行推行某一种单一格式不仅脱离了企业技术栈多源异构的实际,也违背了湖仓一体“开放与解耦”的初衷。
在此背景下,行业开始向跨格式互操作性寻求破局之道。Databricks率先推出了UniForm(Universal Format)兼容层技术,通过智能同步元数据,使得原本采用Delta Lake格式存储的数据集能够透明地被任何支持Iceberg协议的外部客户端系统直接读取,迈出了生态互通的第一步。而更为彻底、更具革命性意义的突破则来自Apache XTable(孵化中)项目。XTable由Microsoft、Google和Onehouse等行业巨头联合发起并捐赠给Apache软件基金会,它不创造任何新的物理数据格式,而是提供了一套高度轻量级、无状态的元数据层翻译引擎。借助XTable,企业能够以极低的计算开销实现Hudi、Delta和Iceberg这三大表格式底层元数据的无缝双向转换。这一创新使得用户不仅不再需要被迫做出选择或承担供应商锁定的风险,更能够针对不同的业务负载特性(如流处理用Hudi,BI查询用Iceberg)在同一套物理数据文件上自由切换管理格式。XTable的出现实质上宣告了湖仓一体底层“格式战争”的终结,标志着技术发展进入了跨层融合的成熟期。
现代云数据平台的商业博弈:Databricks与Snowflake的战略交锋
开源底层标准的演化进程,本质上折射出的是上层商业生态构建与企业级市场控制权的重构。在2024至2026年的云端数据基础设施竞争格局中,这场博弈主要聚焦于两大数据巨头:Databricks与Snowflake。有趣的是,这两家企业分别代表了数据栈演进的两极——Databricks起源于处理非结构化大数据的“湖(Lake)”,而Snowflake则是依托于云原生关系型计算崛起的“仓(Warehouse)”。随着市场对敏捷分析与AI工程的双重需求爆发,两家巨头最终在“湖仓一体”的十字路口展开了最为激烈的正面战略交锋。
架构哲学:细粒度控制与全托管服务的多路对决
两家公司在底层架构哲学上存在着根本的对立,这也决定了它们各自平台的特性倾向。Snowflake作为云端数据仓库的开拓者,其核心理念可以概括为“全托管的简洁性(Fully managed simplicity)”与极致的“计算存储隔离”。在Snowflake的架构体系中,完全独立的虚拟计算仓库(Virtual Warehouses)在各自独占的计算资源池中运行。这意味着高并发的财务报表查询与繁重的数据ETL导入之间在物理层面上实现了绝对的隔离,互不干扰。这种设计为管理员免去了极其繁琐的性能调优与资源抢占管理,同时,由于底层数据块的处理完全交由Snowflake的闭源引擎内部优化,用户获得了真正的“开箱即用”的高并发BI查询体验。
与此形成鲜明对比的是,孕育于Apache Spark开源社区土壤的Databricks则坚定地推行开放底座与高度可编程的湖仓一体架构。Databricks的Delta Lake存储层建立在标准的Parquet文件体系之上,这赋予了高级数据工程师深入底层进行极细粒度干预的自由权——从微调特定表的分区策略、自定义物理文件大小到编写定制化的数据跳过逻辑,尽在掌控。在计算层面,Databricks允许更加灵活且深度的共享资源池配置(Shared clusters),虽然这不可避免地引入了资源隔离与性能分配管理的复杂性,但却极大地提升了在大规模复杂数据转换管道和特征工程计算时的底层硬件利用率。
面对竞争,两者都在积极向对方的腹地渗透。Snowflake推出Snowpark和Native App Framework框架,使得数据科学家能够使用Python或Java在Snowflake平台内部直接执行非SQL的数据转换与机器学习预处理操作,试图削弱Databricks在数据科学领域的主导地位。反之,Databricks通过引入自研的Photon无服务器SQL向量化执行引擎,并在架构上全面拥抱Databricks SQL界面,大幅提升了其在传统高并发商业智能(BI)分析与低延迟查询场景下的战斗力,甚至允许用户通过灵活调整计算集群配置在速度与成本之间进行精准权衡。
目录权限与数据跨界共享治理权的白热化争夺
在底层性能差距逐渐缩小的今天,未来的数据平台之争实质上是整个企业甚至跨企业数据边界的元数据控制权(Metadata and Governance Control)的争夺。
在这一领域,Snowflake始终展现出深厚的积淀。其依赖单一且高度集成的元数据层体系(Horizon Catalog),能够对整个生态内的数据库、表模式、视图体系甚至细粒度的行列级安全规则进行大一统的集中式追踪与管理。借助这种集中式架构,Snowflake构建了极其强大的原生数据共享网络(Data Sharing),企业可以非常轻易且安全地在全球不同的云区域甚至跨越AWS、Azure等不同公有云的Snowflake节点间,与外部合作伙伴进行实时、不可篡改的数据变现与交换。
然而,进入2025至2026年,Snowflake已经不再局限于封闭的全托管数据仓库定位,而是明确向“企业级湖仓(Enterprise Lakehouse)”与完全开放的生态系统演进。Snowflake不仅在Horizon Catalog中原生集成了对Apache Iceberg等开放表格式的读写支持,更推出了具有里程碑意义的Snowflake Open Catalog(前身为Apache Polaris)。作为一个开源且厂商中立的技术目录,Open Catalog允许团队跨多个平台与计算引擎无缝管理Iceberg表,提供了基于REST协议的互操作性与强大的基于角色的访问控制,从根本上打破了以往的厂商隐性锁定,标志着Snowflake全面拥抱湖仓一体开放标准。
作为反击,Databricks推出了旨在重塑数据治理边界的Unity Catalog。这不仅是对Snowflake元数据层的直接回应,更是一种覆盖面更为宽广的联合治理框架。Unity Catalog突破了仅管理结构化表数据的传统认知,它建立了一个可以跨越多个独立Databricks工作空间、甚至横跨不同地域的统一控制平面,能够将非结构化文件资产、经过训练的机器学习模型对象乃至外部非系统内置的数据源纳入统一的安全管控之下。更具战略意义的是,基于完全开放标准的Delta Sharing协议被嵌入其中,企业无需强迫数据消费方也必须购买或部署Databricks系统,就能够实现跨云平台或外部合作伙伴的端到端安全数据分发。
混合架构常态化:企业IT基础设施的现实最优解
尽管商业巨头在市场营销中往往强调自身方案的全面性与唯一性,但来自一线生产实践的客观调研揭示了一个复杂得多的混合现实。根据theCUBE Research在2025年发布的追踪数据,高达52%的Snowflake存量客户同时也在他们的IT基础架构中运行着庞大的Databricks集群系统。
这一数据深刻地表明,在面对现代企业复杂多变、规模庞大的业务需求时,非此即彼的零和选择并非明智之举。理性的企业正在拥抱一种基于负载隔离的混合“同类最佳(Best-of-breed)”架构策略。在典型的生产范式中,企业将高度消耗算力、涉及非结构化解析的海量数据清洗流水线、流式数据摄取、深度机器学习特征提取以及AI模型训练部署在以Spark为核心引擎的Databricks平台中;而将经过高度提纯、需要满足严格合规审查、支撑执行层仪表盘(Dashboards)并且要求极致并发响应的结构化SQL分析数据湖沉淀至Snowflake中进行对外发布与数据变现。在这种模式下,湖仓一体的概念已经超越了单纯的单一平台架构属性,演变为了指导整个企业多异构系统之间高效流转与解耦的宏观数据编排范式。
湖仓架构落地面临的现实技术困境与学术批判
任何技术范式在从理想化的白皮书走向充满历史包袱的真实生产环境时,都不可避免地伴随着惨痛的工程代价。在2022年至2025年期间,随着湖仓一体架构在全球头部企业的大规模部署,学术界和一线的工业实践者开始透过“一站式无缝融合”的营销外衣,对其实际落地过程中所暴露出的一系列深层次的结构性限制、系统性摩擦以及运维灾难进行了深刻的反思与批判。
与现代数据栈(MDS)工具链的剧烈结构性摩擦
在过去的云数据仓库时代,以dbt(Data Build Tool)为首的声明式数据转换框架成为了现代数据工程的核心标配。dbt推崇一种极为敏捷的工程模式:通过频繁地、以非破坏性的方式在数据库内部彻底重建(Rebuild)整个复杂的视图层级与临时实体表,来确保从原始数据到聚合指标层的商业逻辑状态的绝对一致性与可复现性。
然而,当这种基于“重构即更新”的工作流生硬地移植到湖仓一体系统时,引发了灾难性的性能崩溃与成本超支。这种矛盾根源于底层架构基因的错位。如前文所述,湖仓一体若要获得媲美数仓的极致查询性能,高度依赖于底层极其稳定的物理文件布局——例如经过长时间后台聚簇优化生成的紧凑型Parquet文件块、复杂计算得出的Z-order空间排序以及精细编排的元数据日志快照。dbt的持续全表重建逻辑,意味着系统必须在云对象存储(如S3)上发起海量的I/O覆盖操作,频繁擦除并重写庞大的Parquet文件丛集,同时导致事务日志体积剧烈膨胀。这种频繁的文件变动(Churn)不仅极大地损耗了计算引擎执行数据跳过(Data Skipping)优化的有效性,更使得原本在传统数仓中运行极为迅速、成本可控的自动化数据测试和质量校验套件在湖仓架构下变得异常缓慢且极为昂贵。
为了缓和这一工程摩擦,当前的业界被迫采用了一种妥协式的“奖章架构(Medallion Architecture)”混合路径。企业选择将dbt的繁重建模任务严格限制在最为结构化、逻辑上更接近数仓的顶端业务层(Gold层/数仓层),而对于直接面向数据湖底层接收海量、无序原始接入数据的铜层(Bronze层)和承载大规模清洗转换逻辑的银层(Silver层),则放弃dbt的大规模重建模式,转而利用更为底层的湖仓专属算子和严苛的增量更新机制进行数据追加,从而在一定程度上容忍了开发周期的拉长和代码管理的割裂。
乐观并发控制在高频竞争下的系统性失败
供应商在推广湖仓一体理念时,常常向决策者宣称其采用的开放表格式(如Iceberg或Delta)能够自动且完美地赋予数据湖等同于关系型数据库的ACID事务特性。但这在理论计算机科学层面被证明是一种高度简化的承诺,掩盖了深层架构妥协带来的脆弱性。
在传统关系型或OLAP数据库中,ACID事务是构建在紧耦合的底层存储引擎引擎层面的,往往通过精细的行级或块级悲观锁机制在内存池中予以保障。然而,湖仓一体的事务机制必须构建在如AWS S3这样本身无状态、不支持锁的云对象存储基础之上。因此,系统通常采用基于日志校验的乐观并发控制(Optimistic Concurrency Control, OCC)来“模拟”这种数据库原语。在OCC机制下,并发写入请求会被允许平行地构建新的数据文件,但只有在最终将变更指令写入中央元数据日志的一瞬间才会进行状态校验。
如果企业仅仅是进行低频的离线批处理作业,这种机制运行良好。但在面对复杂真实的现代业务场景——例如数十万台物联网(IoT)设备高频向同一时间分区执行微批次的流式更新,同时后台又并发运行着数个离线数据修正任务时,如果多个执行节点频繁命中同一分区的元数据空间,OCC机制就会无可避免地触发大规模的事务乐观锁冲突。此时,遭遇冲突的写入任务不仅必须被强制废弃当前批次生成的所有数据对象,还要回滚并重新启动繁重的重试(Retry)循环。这种在极高数据争用(High-contention)场景下的雪崩效应可能导致极端的性能抖动,甚至致使整个数据摄取链路崩溃。这也是为何在追求极致流控和海量复杂变更的金融交易与物联网监控系统中,许多架构师更倾向于引入基于多版本并发控制(MVCC)和细粒度冲突解析树的Apache Hudi,而非简单依赖基础版OCC格式的原因所在。
昂贵的迁移陷阱与被掩盖的生态碎片化危机
所谓的湖仓一体带来了“系统的极简主义”,往往只存在于PPT架构图之中,而在实际演进过程中,其带来的系统运维负担和迁移摩擦常常被低估。对于一个严重依赖传统本地数据仓库和数千个错综复杂的存储过程代码的企业来说,向湖仓一体平滑过渡不仅需要投入极其漫长的重构周期和惊人的资本支出,更隐含着巨大的运营风险。此外,由于底层技术栈的前沿性和复杂性,企业还不得不面对一笔隐形的财务支出——高昂的人力培训与重组成本。数据库管理员(DBA)必须从熟悉传统的SQL索引结构转变为掌握如何在分布式Spark环境中排查内存溢出故障、如何设定合理的垃圾回收机制以及如何规划表级别的数据整理(Vacuum/Compaction)策略。
更为讽刺的是,许多学术批评指出,湖仓一体标榜的核心卖点——打破商业壁垒、彻底消解“供应商锁定(No Vendor Lock-in)”——在现实操作中更像是一种乌托邦式的幻觉。尽管所有的海量底层物理文件确实以完全中立的Parquet格式存储在企业直接控制的私有云S3存储桶中,但其上层的元数据格式生态系统已经表现出极其严重的碎片化和系统性割裂。不同的分布式计算引擎(如Apache Spark、Trino、Presto、Athena等)在读取相同的开放表格式(如Iceberg或Delta)时,对其高级特性的支持程度呈现出巨大的落差。例如,极其关键的“读取时合并(Merge-on-Read)”算子或某些特定版本的统计信息跳过功能,可能仅仅在Databricks高度定制化的Spark商业版集群中能够流畅执行,而一旦企业试图将这部分查询负载透明转移到另一个“开放的”开源查询引擎上,就可能会遭遇灾难性的性能暴跌或诡异的数据不一致性故障。这种由于代码解释差异所造成的隐性绑定,意味着即使在开放格式时代,用户仍然难以真正地、无缝地在不同供应商平台之间自由迁徙其核心工作负载。
数据架构的未来范式:智能体时代与统一语义层的崛起
数据技术的发展从未停歇。当我们站在2025年至2026年的历史交叉口,大语言模型(LLMs)的大规模普及和Agentic AI(智能体人工智能)技术的爆炸式发展,正在将底层湖仓一体架构推向一个全新的演进周期。数据基础设施的核心矛盾,正在从上一个十年的“如何大规模、低成本地存储与海量并行计算”,发生着根本性的偏转,转变为“如何构建能够为全自动执行的AI智能体提供极低延迟、高保真且具备多模态推理能力的全量业务上下文”。
独立抽象的演进:统一通用语义层的战略中心化
在现代大型企业环境中,随着数字化程度的加深,多维度的商业智能工具栈(如Tableau、Power BI齐头并进)、交互式Jupyter笔记本平台以及各种内嵌生成式AI辅助查询工具(如SQL Copilots)呈几何级数蔓延,导致原本隐藏的“指标定义碎片化”问题迎来了爆发。当一个负责客户留存的分析师通过Tableau提取“本季度活跃用户”指标,而另一个接入了底层数据库的自然语言处理Agent被提示要求预测同一数据时,如果底层的海量湖仓数据结构中缺乏一套强有力的、统一抽象的业务逻辑层作为缓冲,这两种不同的查询通道在解析底层相同的Iceberg表结构时极有可能生成完全不同且彼此矛盾的SQL脚本,最终返回令人迷惑且具有破坏性的相悖结论。
为了彻底解决这一数据网格(Data Mesh)时代最为棘手的本体性难题,将业务逻辑与底层物理存储完全解耦的“通用语义层(Universal Semantic Layer)”(例如以Cube或Coalesce为代表的先进方案)开始从架构的边缘逐渐渗透并占据舞台的中央枢纽位置。值得注意的是,随着AI与BI的深度融合,到了2026年,“语义层”的概念已经发生了显著的细分与演变,目前行业内主要涵盖四种截然不同的产品形态:面向传统BI的语义层、面向开发者的指标API(Headless架构)、数据仓库原生的Text-to-SQL交互界面,以及专门面向AI智能体的语义执行层。在这种多BI工具与多AI智能体并存的极度复杂环境中,现代通用语义层不仅充当翻译网关,其核心价值更在于充当一个统一的知识管控平面。这一层级作为一道横亘在复杂的底层云原生多计算引擎与前端形形色色消费应用之间的刚性翻译网关,允许数据领域专家(Domain Experts)在极高层次上一次性且权威地定义组织关心的核心业务实体(Entities)、关键绩效指标(Metrics)、跨表连接逻辑(Joins)以及极其细致的访问隔离策略(Policies),从而确保所有的下游消费端都能获取一致且经过严格审计的事实来源。更重要的是,它能在毫秒级将这些业务语义自动、精确地翻译并路由为针对底层特定的Lakehouse引擎(无论是基于Databricks的Delta池、Snowflake的虚拟仓还是BigQuery集群)高度优化并缓存的执行计划。随着语义层能够与诸如Snowflake Horizon或Databricks Unity Catalog进行深度元数据握手,这标志着湖仓架构完成了从简单的“被动式数据资产罗列”向真正意义上的“可计算企业级知识中枢”的惊险跃升。
面向Agentic AI的跨云智能实时湖仓构建
早期的湖仓一体架构脱胎于解决庞大数据批处理和静态机器预测模型的痛点,这种离线驱动的设计理念已经越来越难以支撑Agentic AI智能体对于极高频动态响应、无缝跨云交互和多模态复杂推断的苛刻吞吐要求。传统的湖仓一体主要针对大规模离线数据准备与批处理而设计,但现代底层基础设施正在向“AI原生”底座演进,以持续的反馈循环和实时数据流全面取代传统的批处理模式。通过将特征存储(Feature Store)与模型服务(Model Serving)直接且深度地整合至湖仓架构中,系统能够无缝支持实时的AI特征工程与在线机器学习推理。在这一驱动力下,以Google BigQuery Omni架构体系和Snowflake Openflow深度技术集成为代表的下一代“跨云智能湖仓(Cross-cloud Lakehouse)”平台正在迅速崛起。
这些具有前瞻性的新一代基础设施平台在核心机制上实现了两项里程碑式的突破。首先是物理计算边界的彻底消解。底层查询引擎被赋予了极其强悍的跨域穿透能力,能够无需进行任何形式的大规模数据搬迁或管道拉取,直接通过元数据网络感知并高速协同处理分布在不同公有云(AWS、Azure、Google Cloud)环境中的Iceberg或Delta等格式数据源。例如在全球顶级流媒体巨头Spotify的平台改造实践中,这种新型的具有完全互操作性的抽象存储接口与湖仓架构,彻底打破了由不同工具链和不同云地域所筑起的物理与部门壁垒。它使得内部横跨内容推荐、财务结算以及用户行为分析的各个核心业务团队,能够极度自由地使用从BigQuery到Dataflow等各种引擎或开源组件,对同一份源头数据实体进行并行计算处理,而全流程中未产生任何冗余的计算拷贝。这种极致的精简极大地缩减了数据准备的时间窗口并释放了前所未有的工程弹性。
其次,是真正打破了传统分析型系统(OLAP)与高频在线事务型系统(OLTP)之间长期存在的逻辑鸿沟。通过诸如Snowflake Postgres整合等技术创新,下一代湖仓平台使得高频产生的实时运营交易数据无需经历漫长的湖仓间转运周期,即可瞬间变为AI智能推理层可读取的高维特征,从而为整个AI Agent系统构建了一个无缝融合的、“全天候持续在线流转(Always-on Context)”的超级实时决策底座体系,使其能够打破物理界限跨越操作型和分析型数据进行高阶自主决策。
结论与战略建议
自2021年CIDR会议上由Armbrust等人系统性地提出湖仓一体(Lakehouse)架构理论体系以来,这一开创性的理念已经彻底跨越了最初带有颠覆性色彩的技术设想阶段,在波澜壮阔的五年时间里演变并确立为了支撑现代全球数字经济运转的确定性基础设施底层架构标配。通过极其精妙地在基于标准的、低成本的分布式海量对象存储平台之上,叠加了一套具备工业级强健ACID事务保障能力的开放性元数据管理层,并无缝整合了能够被数据科学社区广泛采用的声明式机器学习抽象框架与底层被极限压榨硬件性能的高智能计算引擎,湖仓一体架构以极其优雅的姿态成功打破了长达数十年存在于极其僵化但安全的数据仓库体系与极其灵活但极度难以治理的数据湖体系之间似乎无解的零和博弈难题。
诚然,在这项宏大范式体系向现实落地扎根的痛苦进程中,它遭遇到了一系列深层次的危机与反弹——例如与既有现代数据流高频重建构建工具链(如dbt架构生态)之间的剧烈底层结构性逻辑不兼容问题、基于云环境下的无状态对象存储系统通过乐观并发控制在遭遇极限多源高并发写入时暴露出的系统吞吐极限与锁争用崩溃瓶颈,以及隐藏在“开源通用”这层政治正确营销面纱之下极其陡峭的运维学习曲线与高度碎片化的算子解释隔离隐患。但从更宏观的演进趋势来看,整个行业正在通过源源不断、令人惊叹的底层工程架构创新进行纠偏与迭代修复。从通过轻量级元数据映射彻底抹平底座割裂的Apache XTable项目诞生,到能够兼容多端交互实现单点定义的通用企业语义抽象层的战略级中心化布局,甚至是过去势如水火的Databricks与Snowflake这两大云端巨头通过Unity Catalog和Horizon向对方核心应用腹地互相深层次渗透并达成了某种基于不同业务负载混合配置部署的最佳实践平衡中,我们能够清晰无误地感知到:全球企业级数据底座平台架构的发展浪潮,正在不可逆转地从过去那种通过高高的供应商技术壁垒和黑盒数据格式圈地自萌的封闭系统时代,急剧且极其深入地向以全面拥抱开放底层表格式标准、强力贯彻存储与多模态计算彻底解耦,以及面向生成式人工智能技术(GenAI)提供极其原生的高保真上下文流传输能力为核心竞争主轴的全景互联时代转型。
面向不可预知的未来,随着具备自主执行与多轮深度逻辑演绎能力的Agentic AI(智能体人工智能)技术以前所未有的深度全面接管企业应用边界,以及去中心化跨多云平台的协同网格计算架构底座技术的彻底成熟落地,湖仓一体系统(Data Lakehouse)所承载的历史使命也将发生根本性跃迁。它将不再仅仅满足于充当一个庞大但死寂的、用于被动地统一归集和低频处理海量关系型异构结构化数据与巨量高冗余非结构化流媒体文件的静态基础数据底座仓库;相反,基于其无与伦比的弹性和扩展性,它必将快速且极富生命力地演化为一张极其敏锐的、动态接驳企业各个物理孤岛业务实体脉络与支撑高阶智能体进行低延迟抽象复杂认知逻辑推理之间的超级“中枢数据神经控制系统网络”。对于当下正在进行或规划进行数字化深水区改革升级转型的全球企业决策层架构师而言,全栈拥抱并彻底深耕基于极其成熟的开放表格式标准的湖仓一体架构工程建设理念,已绝不再是应对短期某一两项繁杂数据并发计算瓶颈的被动战术性防御选择,而是关乎在这个即将全面爆发、由海量实时数据流与高阶深度人工智能模型进行双轨强劲引擎驱动竞争的极高维度商业对抗时代中,企业最终能够凭借其信息处理反应速度和底层知识抽象保真度存活多长、走多远并构建出何种坚不可摧商业护城河的最核心的战略必然之举。
