

 1
1 0
0Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases (2017) 解读与学习
引言与云原生数据库的时代动机
在过去十余年中,企业信息技术(IT)工作负载经历了向公共云提供商的大规模、不可逆转的全面迁移。这种全行业向云转型的根本驱动力,不仅源于云计算平台能够按需灵活配置无尽的计算与存储容量,更在于它促成了从前期资本支出(CAPEX)向按需运营支出(OPEX)财务模式的转变 。然而,对于支撑现代商业应用核心逻辑的在线事务处理(OLTP)关系型数据库而言,仅仅将传统系统直接搬迁至云端并不能满足企业在云原生时代的严苛要求。
传统商业专有数据库虽然功能强大,但其高昂且具有惩罚性质的许可费用以及供应商锁定效应,促使大量企业寻求向开源数据库引擎(如 MySQL 和 PostgreSQL)迁移 。然而,传统的开源数据库在面临云端高并发、高吞吐量应用时,往往无法达到企业级的可靠性与性能标准 。在云原生分布式服务的构建中,弹性和可扩展性通常是通过解耦计算与存储资源,并在多个节点上跨可用区复制存储来实现的 。这种解耦使得基础设施能够从容应对节点故障、硬件更替以及动态缩放等挑战 。亚马逊(Amazon Web Services, AWS)在此背景下推出了一款完全托管的关系型数据库服务——Amazon Aurora,旨在兼顾高端商业数据库的性能与可用性,以及开源数据库的简洁性与成本效益 。
本研究报告将基于对 Aurora 核心架构设计的详尽剖析,深入探讨其如何在云规模下重新定义关系型数据库的工作机理。通过深度解构其对存储与计算物理边界的重塑、规避传统两阶段提交协议的无锁一致性机制、应对关联性故障的仲裁模型,以及从单体架构向 Serverless 动态演进的历程,本报告旨在为分布式系统工程与云数据库底层设计提供全面而深度的解析。
传统数据库架构在云环境下的瓶颈与困境
为了理解 Aurora 的架构突破,必须首先剖析传统数据库系统在云规模下面临的核心制约因素。传统数据库系统的设计前提是计算与存储紧密耦合,并且长期以来,工程师们默认系统的最大性能瓶颈在于底层磁盘的输入/输出(I/O)速度 。然而,随着多租户分布式存储机群和固态硬盘(SSD)的大规模应用,单个磁盘和计算节点的 I/O 压力已被有效分散,真正的系统性能瓶颈不可逆转地转移到了连接数据库计算引擎与存储层的网络结构上 。
写入放大与同步网络 I/O 的级联延迟
在传统的数据库高可用复制架构中,网络流量的放大效应成为了限制吞吐量的致命因素。以典型的跨数据中心运行的主备(Active-Standby)同步镜像 MySQL 系统为例,当应用程序发起一次数据修改时,数据库引擎不仅需要修改内存中的数据页,还需要在底层文件系统中进行极其冗余的多重写入 。
具体而言,传统的 MySQL 会将数据页刷入表空间对象(如 B 树结构的堆文件),同时为了防止在写入过程中发生系统崩溃导致的数据页撕裂(Torn Pages),还需要向双写缓冲(Double-write buffer)中写入一份临时数据页 。在此基础上,系统必须记录用于崩溃恢复的重做日志(Write-Ahead Log, WAL)以及用于时间点恢复(Point-in-Time Restore)的归档二进制日志(Binlog),此外还要更新格式和元数据(FRM)文件 。
在基于亚马逊 Elastic Block Store (EBS) 等网络附加存储的高可用部署下,这种冗余写入会演变成一条漫长且脆弱的同步执行链。首先,主数据库向其挂载的 EBS 卷发出写入请求;该卷需要将数据同步写入同一可用区内的镜像副本,并在两者都完成后向主库返回确认。随后,主库利用基于块级别的软件镜像协议,将相同的写入通过网络跨可用区(AZ)同步至备用实例的 EBS 卷;该备用卷进一步将数据写入其自身的局部镜像副本 。
这种被称为“链式复制”的过程,由于其包含多个串行且同步的写操作步骤,导致了网络数据包数量(PPS)呈几何级数放大 。由于这些步骤都是顺序发生的,任何一个微小的网络波动或存储异常(Outliers),都会被这种同步串行架构成倍放大,导致极端的响应时间延迟与尾部性能波动 。此外,传统架构处理缓存未命中(Cache Miss)时,读取线程必须暂停并等待磁盘 I/O 完成,若缓冲池已满,还需附加驱逐和刷写脏页的延迟惩罚。后台的检查点(Checkpointing)操作与脏页刷写机制虽然旨在缓解缓存压力,但它们会与前台的查询处理争抢宝贵的磁盘 I/O 与网络带宽,引发频繁的上下文切换和资源竞争 。
分布式共识协议的内在缺陷
更为严峻的是事务提交时的同步挑战。在跨越多个数据中心的云级别分布式系统中,使用传统的两阶段提交(2PC)等多阶段同步协议来处理事务提交是极具挑战且效率低下的 。两阶段提交协议本质上对网络分区和节点故障极度缺乏容忍力,而高规模的分布式系统中不可避免地存在着硬件和软件故障的持续“背景噪音” 。此外,一旦参与提交的某一个节点发生卡顿,其造成的提交停滞将阻塞整个系统中其他相关事务的进展,这使得两阶段提交在强调高并发和低延迟的现代云数据库中变得极不合时宜 。
云规模下的持久性、可用性与容错数学推演
如果一个数据库系统失去对数据一旦写入即可被可靠读取的保证,其他所有性能优化都将毫无意义。在摒弃了传统同步镜像模式后,Aurora 面临的首要挑战是如何在一个充满故障背景噪音的分布式存储舰队中构建绝对的持久性 。
故障相关性与可用区(AZ)灾难建模
在云规模环境下,单个节点的生存周期往往与数据的生命周期脱节。实例可能由于硬件老化而宕机,由于软件升级被重启,或由于租户缩放需求而被动态销毁 。这种独立节点的故障和修复构成了系统运行的日常稳态。为了在这种环境下提供弹性和持久性,数据必须在底层分布式节点间进行复制。
系统工程界通常使用法定人数(Quorum)模型来确保分布式系统的一致性与容错性。如果数据被复制 V 份,读写操作必须分别获得 V_r 和 V_w 个副本节点的确认投票,且必须满足 V_r + V_w > V 确保读写集合重叠,以及 V_w > V/2 确保不存在并发冲突的脑裂写入 。在传统的分布式系统中,容忍单一节点故障的典型配置是复制三份数据(V=3),并采用 2/3 的写 Quorum(V_w=2)和 2/3 的读 Quorum(V_r=2) 。
然而,这种设计在云提供商的基础设施中存在致命的盲区:它未能妥善处理“关联性故障(Correlated Failures)”。在 AWS 架构中,可用区(AZ)是一个极具战略意义的容错隔离单元。每个 AZ 通过低延迟网络与同一区域内的其他 AZ 相连,但在电力、物理网络设备、软件部署平面以及应对洪水或火灾等自然灾害时是相互隔离的 。系统架构师的初始直觉是将 3 个数据副本分别放置在 3 个不同的 AZ 中,以此容忍单 AZ 的全面瘫痪 。
但深度分析表明,当大型存储机群不可避免地存在某个节点因日常升级或损坏而处于离线修复状态时(假设在 AZ A 中),如果此时 AZ C 发生意外断电等关联性毁灭事件,整个系统将瞬间丢失两份数据副本,直接破坏了 2/3 的读取 Quorum。在这一时刻,系统无法判定仅存的第三份数据(位于 AZ B)是否为最新版本,从而导致数据的不可用甚至永久性丢失 。由此可见,2/3 的 Quorum 模型无法同时容忍一个不可预测的大规模 AZ 级别故障和云环境中不可避免的节点背景噪声故障。
创新的 4/6 异步 Quorum 模型
基于上述针对关联性故障的数学建模,Aurora 选择了一个激进且高度健壮的容错设计点:同时容忍整个可用区(AZ)的完全丢失,加上一个独立数据节点的额外故障(即 AZ+1 故障),且不丢失任何数据;同时容忍整个可用区的丢失,而不影响系统继续写入新数据的能力 。
为了达成这一极具挑战性的目标,Aurora 的底层存储架构将每一个逻辑数据项在 3 个独立的 AZ 中复制 6 份,每个 AZ 存放 2 份副本。在这样的拓扑结构下,Aurora 配置了 6 票制的 Quorum 模型(V=6),其中写 Quorum 设定为 4/6(V_w=4),读 Quorum 设定为 3/6(V_r=3) 。
这种 4/6 的 Quorum 设计展现出了极其优异的韧性边界。首先,在遭遇单个 AZ 彻底损毁(丢失 2 个节点),并且在另外的 AZ 中又有一个节点发生故障(共丢失 3 个节点)的极端灾难下,剩余的 3 个节点仍能完美满足 3/6 的读 Quorum,确保数据依然可以被一致性地读取,进而触发快速重复制机制以恢复写 Quorum 。其次,在丧失任何 2 个节点(例如一个完整 AZ 发生短暂网络隔离或断电)的情况下,剩余的 4 个节点仍能满足 4/6 的写 Quorum,从而保证数据库前端写入操作的丝滑顺畅,对应用层完全透明 。值得注意的是,尽管 Aurora 在底层物理可用区中分布了 6 份数据副本以换取极致的持久性和可用性,但在 AWS 的商业计费模式下,客户实际上仅需为单份数据的逻辑存储容量付费。这种策略将架构底层的物理冗余成本进行了内部消化,并没有直接转嫁到客户的总拥有成本(TCO)上。
分段存储与极速平均修复时间(MTTR)
仅有高维度的 Quorum 投票机制不足以赋予系统坚不可摧的持久性。要从数学概率上彻底杜绝数据丢失,必须确保在修复一个独立故障所需的时间窗口内,发生能够破坏 Quorum 的多重并发独立故障(MTTF)的概率无限趋近于零 。与其试图降低由于硬件老化带来的独立故障概率,Aurora 选择将重点放在极大限度地压缩平均修复时间(MTTR)上 。
Aurora 将庞大的数据库逻辑卷切分为极其细粒度的、固定大小的 10GB 数据段(Segments)。这些数据段以 6 向复制的方式组织成保护组(Protection Groups, PGs),离散分布在由数万台虚拟存储主机和固态硬盘组成的庞大存储舰队中。随着数据库体积的增长,系统会动态分配新的 PG 拼接进存储卷,最高可支持达 128 TiB 的存储空间(早期为 64 TB) 。
10GB 数据段成为了 Aurora 中独立的故障监控与自我修复单元。在云端标准的 10Gbps 内部网络链路上,当系统侦测到某个存储节点发生故障或数据段损坏时,从健康的 Quorum 中重新复制并修复一个 10GB 的数据段仅需大约 10 秒钟的时间 。这意味着,系统要在这一机制下丢失数据,必须在短短 10 秒的修复窗口内,在同一个包含特定保护组的范围内连续遭遇两次完全独立的硬件故障,并且伴随另一个未受这两次独立故障影响的独立 AZ 的彻底毁灭。在观测到的海量节点故障率统计中,这种极端巧合发生的概率微乎其微 。
这种高度容忍长时间甚至短时间故障的自愈架构,同时赋予了 Aurora 巨大的运维灵活性。系统管理员甚至软件自动编排程序可以通过人为将某个处于高发热状态的磁盘上的数据段标记为“损坏”,立刻触发系统的 Quorum 修复机制,将数据透明地迁移至机群中的冷节点以实现热点打散。操作系统和安全补丁的滚动升级、存储服务软件的版本迭代,均被系统视作极其短暂的节点离线事件,逐个 AZ 平滑执行,使得复杂分布式基础设施的维护工作不再成为数据库可用性的隐患 。
核心哲学转变:日志即数据库 (The Log is the Database)
尽管 4/6 的跨区多副本分布模型提供了出色的容灾能力,但如果直接在传统关系型数据库内核上运行这种底层存储架构,将对系统性能带来灾难性的打击。每一次应用层的写入操作都会导致传统数据库产生大量实际的网络 I/O,再叠加 6 倍的复制放大效应,将瞬间淹没网络带宽并耗尽每秒数据包数(PPS)的配额 。Aurora 为此进行了彻底的架构革命:它将传统数据库内核堆栈下半部的四分之一直接下推、卸载至分布式的智能存储层,从而确立了“日志即数据库”的全新计算范式 。
彻底消除写放大的重做处理卸载
在 Aurora 的架构中,从数据库计算引擎向下发送到网络对岸存储层的,有且仅有重做日志记录(Redo Log Records)。数据库引擎永远不会通过网络将数据页本身写入存储,不论是为了后台检查点推进、系统缓存页驱逐,还是为了刷写脏数据 。
在传统的架构模型里,当数据库修改数据页时,它生成重做日志记录并调用内置的日志应用器(Log Applicator),将其应用到内存中的旧页前像(Before-image)上,生成修改后的后像(After-image)。虽然为了加速事务提交,数据页的磁盘写入可以延迟进行,但日志与数据块两者的最终磁盘落地不可避免 。在 Aurora 中,这个至关重要的日志应用器机制被完全下移至存储计算节点。存储服务利用不断接收到的重做日志,在后台根据需要或以持续的批处理方式,从原始状态生成最新的数据页视图 。
从确保数据绝对正确性的理论视角出发,后台的数据页物化过程实际上是可选的辅助操作。只要完整的重做日志链条得以保存,“日志就是数据库本身”。存储系统出于优化读取效率所进行的后台页面物化,仅仅是对冗长日志应用历史的一种物理缓存(Cache of log applications) 。这种机制与传统数据库的检查点截然不同,传统数据库中检查点操作的频率受制于全局 redo 日志链的长度,而在 Aurora 中,是否触发数据页的后台物化完全取决于该特定数据页面修改日志链条的长度,且该过程完全不对前台事务造成任何 I/O 挤压 。
这种计算与存储的分离在大幅度放大副本数量保障可用性的同时,极大地降低了网络负载。下表展示了使用 SysBench 针对 100GB 数据集进行 Write-Only 测试时,Aurora 与跨可用区同步镜像 MySQL 架构的网络 I/O 资源消耗对比:
表 1:Amazon Aurora 与同步镜像 MySQL 的网络 I/O 开销与吞吐量对比

如上表所示,由于彻底消除了脏页和双写缓冲等带来的写入放大负担,尽管 Aurora 将数据向 6 个目标节点广播,其数据库前端实例平均每笔事务所引发的网络 I/O 请求数量却比传统 MySQL 减少了 7.7 倍。同时,在整个 30 分钟的持续压测下,Aurora 所能维持的事务总吞吐量是传统方案的 35 倍 。从每个分布式存储节点的视角来看,由于它只接收未放大的增量日志流水,且只需处理其所属分片的子集,存储层面的 I/O 处理负担下降了惊人的 46 倍 。这笔节省下来的海量网络与磁盘资源,被 Aurora 用来并发处理前端的大量并发请求,并通过冗余复制化解局部异常抖动。
全异步、抗抖动的底层存储管道
为了将前台数据库写入操作的延迟压缩至极致,Aurora 的底层分布式存储节点被精心设计为一个深度流水线化的异步处理引擎。存储节点的 CPU 计算能力被用来换取磁盘 I/O 瓶颈的纾解。由于云数据库系统在峰值与平均负载之间存在天然的起伏周期,Aurora 存储节点充分利用这些空隙,将绝大多数复杂任务推迟至前台写入路径之外 。
一个完整的日志记录到达 Aurora 存储节点后的生命周期被精细拆解为 8 个步骤: 存储节点首先接收来自数据库的日志记录片段,并将其推入内存队列中。随后,存储引擎将记录持久化至 SSD 磁盘,并在本地落盘后立即向前台数据库引擎返回确认信息(ACK)。至此,所有位于关键路径(Critical Path)上前台操作宣告结束,数据库事务便可继续推进,不受后续任何操作的阻塞 。
在后台层面,存储节点独立地对收集到的日志进行排序分组,由于网络乱序或抖动,此时可能会发现日志序号序列中存在间隙空洞。为了弥补这些间隙,节点并不向上反向请求数据库重新发送,而是通过与同属一个保护组(PG)的对等存储节点进行点对点八卦通信(Peer-to-Peer Gossip),智能地从健康邻居处提取并填补缺失的日志数据块 。填补完整后,节点在后台持续将积攒的日志记录应用、合并(Coalesce)到现有的数据页面上,生成最新的数据状态。与此同时,系统启动周期性任务将日志及全新合并的数据页面持续归档备份至海量存储层 Amazon S3,以支持零影响的无限时间点恢复(Point-in-Time Restore) 。随着最新数据页不断被持久化,节点利用后台闲暇时间执行版本垃圾回收(GC),清理不再需要的过期数据页,并定期运用后台进程扫描检验页面上的循环冗余校验码(CRC),默默识别并治愈静默数据损坏 。
在此管道中,除了前两个步骤外,其余全部步骤不仅完全脱离了前台响应路径,而且与前台数据库负载呈现负相关态势:只有当存储节点处于前台写入请求的低谷闲置期时,垃圾回收和数据块合并等高 CPU 消耗任务才会活跃执行。如果由于系统持续高压导致后台任务积压过深,Aurora 的反压机制会温和地对前台产生节流,或者仅仅由于个别节点忙碌变慢,依靠 4/6 的 Quorum 机制自然绕过该“缓慢”节点,从而在全球范围内彻底消灭了因传统数据库强制刷盘引起的“系统冻结”现象 。
LSN序列与无锁异步一致性机制的演进
在一个不使用低效、容易造成系统死锁的两阶段提交(2PC)的完全分布式系统中,如何维持读写状态与事务的绝对一致性?Aurora 通过对日志序列号(Log Sequence Number, LSN)的创新性重定义与多级水位线控制,构建了一套复杂而精确的异步共识机理 。
数据库引擎产生的所有操作都会被映射为单调递增的一系列重做日志。Aurora 为每一条被生成的日志记录分配一个全局唯一且严格递增的 LSN。在此之上,系统将一致性和持久性解耦,通过不同的水位线来标记多租户存储分布式状态的完整度。
四级系统一致性标记水位线
在 Aurora 的架构词典中,有四个至关重要且相互关联的术语驱动着整个异步协议的运转:
VCL (Volume Complete LSN - 卷完整水位线):在海量存储节点持续的异步交互与通信后,存储服务从全局角度能够确认、并且保证所有在此序号之前的日志记录毫无遗漏地处于可用状态的最高 LSN。在这个点以上,日志可能存在缺口(例如节点只收到了序号 1007 的日志,但缺失了 1005 的日志) 。
CPL (Consistency Point LSN - 一致性点水位线):数据库引擎定义的逻辑边界。由于一个庞大的用户事务可能会被拆分为多个必须原子执行的迷你事务(Mini-Transactions, MTR,例如底层的 B+ 树页面的分裂或合并操作),数据库只会将每个 MTR 的最后一条日志记录标记为 CPL。这意味着只读取到 CPL 边界的数据才能保证底层数据结构的物理与逻辑一致性 。
VDL (Volume Durable LSN - 卷持久水位线):这是整个 Aurora 共识架构的最核心标尺。它是指全局范围内满足写 Quorum 要求(至少到达 4 个节点),且小于或等于当前 VCL 的最高 CPL 序号。VDL 代表了当前整个数据库在分布式存储上被绝对确认安全的、且物理结构完整的状态天花板 。
SCL (Segment Complete LSN - 数据段完整水位线):这是单一底层存储节点级别的概念。每个保护组(PG)的某一个片段节点根据接收到的前置链接(Backlinks),独立计算出的其所拥有日志记录的无缝连续最高序号。存储节点之间互相广播 SCL,以此寻找日志空洞并互相填补 。
为了防止前端数据库引擎生成日志的速度彻底压垮后端的网络与存储集群,引擎内部设有一个称为 LSN 分配上限(LAL,通常设置为 1,000 万)的常量。数据库分配的最新 LSN 永远不允许超过当前已确认 VDL 加上 LAL 的总和。一旦触及此阈值,说明大量底层写入尚未满足 Quorum,系统将产生内在反压(Back-pressure)限制新事务进入,从而确保系统的动态平衡 。
非阻塞的事务读写与提交
Aurora 在前台事务处理中摒弃了所有可能阻塞线程通信的设计。当用户的应用程序请求提交一个事务时,负责处理该请求的工作线程只会记录该事务结束时对应的“提交 LSN”,将其放置在一个专门维护的等待提交事务列表中,随后便立刻释放去处理其他新的客户端请求 。后台守护线程会以极高的频率监控全局 VDL 的推进状态。当检测到最新的 VDL 已经推进超越或等于该事务的提交 LSN 时,守护线程会主动定位等待列表中的目标,并通过专用的网络通信线程向客户端发送事务提交成功的响应。这种真正的非阻塞提交协议(WAL协议的变体),极大提升了高并发连接下系统的整体吞吐效率 。
在处理由于缓存未命中带来的读盘请求时,由于所有的前台写入已经被存储引擎所保证的一致性所保护,Aurora 极少需要发起沉重的“读取 Quorum”。数据库只需基于发出读请求当时的最新 VDL 确立一个“读取点(Read-Point)”,并精准选择那些自身 SCL 大于该读取点的单个存储片段发出请求。因为数据库明确知道哪个节点的日志进度满足要求,所以可以直接请求单一节点的页面视图,完全规避了分布式系统中昂贵的多数派一致性读取代价 。
此外,为了彻底卸下内存管理的重担,Aurora 创造性地重写了缓冲池的页面驱逐机制(Cache Eviction)。传统的页面驱逐要求将已修改的“脏页”同步写入磁盘以释放内存空间;而在 Aurora 中,只要判断该页面最近一次修改所对应的 LSN 小于或等于当前的持久化 VDL,即意味着该页面的所有变更历史已经完全锁定在底层分布式容错日志中。此时,该内存页面可被直接丢弃并分配给新数据使用,由于底层存储已经掌握了如何随时随地重组这一页面的所有原料,缓存驱逐的 I/O 成本由此彻底降为零 。为了引导存储节点安全地清理其持久化的旧日志片段,数据库主库甚至会持续汇聚包括自身以及所有只读副本正在查询的最低 LSN 要求,向存储机群广播一个“保护组最小读取点(PGMRPL)”的水位线。在此水位线之下的所有过期历史日志才会被底层的垃圾回收系统安全销毁 。
并行与多节点协同的零延迟复本同步
Aurora 的解耦架构带来了另一个极具商业价值的副产品:零代价的横向读扩展。最多 15 个 Aurora 只读副本实例可以挂载并共享同一个分布式存储集群。这些读副本不仅完全不占用任何额外的物理存储空间,也不需发起任何导致网络与磁盘资源内耗的物理刷盘写入操作 。
主数据库引擎在向存储机群持续发射增量重做日志流的同时,也会将同样的日志流低延迟地多播(Multicast)给连接着的所有只读副本。只读副本通过独立消费这条流来进行其局部内存的更新。在这个过程中,读副本必须严格遵守两条纪律:首先,只有当接收到的日志 LSN 明确小于或等于由主库广播确认的全局 VDL 时,该记录才允许生效;其次,由于日志可能零散到达,只有隶属于同一个 MTR 的完整原子操作集合收集完毕时,才将其作为一个不可分割的整体应用到副本自身的内存缓存页面上 。这种精妙的设计不仅确保了哪怕在只读副本上,客户端也只会看到结构完整的视图边界(不会观察到分裂到一半的 B+ 树节点),而且由于省去了繁重的跨节点物理数据块级复制的传统步骤,使得在高压写入下,Aurora 副本落后于主库的时间(Replica Lag)经常稳定在毫秒级 。
瞬态重塑的系统崩溃恢复机制
传统的基于 ARIES 理论框架的关系型数据库,在因断电或硬件损坏崩溃后重启时,被迫进入漫长且消耗巨大的离线崩溃恢复模式 。它们必须首先从最近一次落盘的全局检查点出发,利用缓慢的同步前台进程依序重放所有日志序列,使数据库恢复至崩溃那一瞬间的状态,紧接着再读取 Undo 日志将那些发生崩溃时尚未彻底提交的残缺事务逐个撤销 。这一过程不仅严重干扰业务连续性,也使得 DBA 被迫频繁发起检查点操作以试图缩短恢复时长,陷入吞吐量与恢复时间的无尽博弈。
在 Aurora 的架构哲学中,“日志重放”是一项永远在线、持续分布在成百上千个存储后端节点上默默执行的异步后台进程,这彻底架空了传统意义上的重启恢复机制 。当 Aurora 数据库实例重启后,它完全不需要扫描重做任何本地或前台日志。它所需要做的仅仅是并行向底层的保护组片段发出探针,通过收集跨节点的返回进度,依据 Quorum 法则建立最新的 VDL 视图。随后,数据库发送统一的指令,下令存储服务直接在后端截断(Truncate)所有因未达成 Quorum 而失效的、位于 VDL 之上的“幽灵”日志序列 。至于处理那些在崩溃时尚未完成逻辑提交的飞行中事务的撤销(Undo),则是在新建立的 VDL 基准线上直接读取现成的 Undo 日志进行回滚操作。这种将恢复行为从“前台同步加载”降维为“后台分布式裁决”的架构突变,使得无论系统崩溃前承受着多么恐怖的高峰并发请求,其恢复过程均极其短暂(通常在 10 秒以内即可完全开放访问) 。
系统控制面、高级工程特性与真实世界基准检验
作为面向下一代云基础设施的托管服务,Aurora 的物理实现并不仅限于存储与计算节点本身,而是深深嵌套于整个 AWS 庞大的服务生态系统以及现代网络隔离模型之中 。
安全隔离、编排与架构全景图
在整体架构部署中,Amazon Relational Database Service (RDS) 为 Aurora 提供了强大的托管控制平面保障。每个 Aurora 实例内部均驻留着名为“主机管理器(Host Manager, HM)”的特权代理守护进程,它负责全天候采集实例内部的核心健康指标并反馈给中央控制总线,从而能在异常发生时毫秒级判定是否需要触发实例级故障转移替换 。管理 Aurora 集群配置状态、追踪存储卷拓扑边界结构以及详尽备份元数据的,是后台调用的强一致性分布式键值存储系统 Amazon DynamoDB。而应对系统扩容重组、长时间的大规模容灾恢复演练以及后台故障存储节点深度修复等长程异步操作的调度协调工作,则交由 Amazon Simple Workflow Service (SWF) 来实现精细编排 。
安全架构方面,Aurora 采用严格的网络分区机制,以防止未授权访问或内部流量相互干扰。应用程序的数据通信完全局限于客户自定义的 VPC 环境中;数据库实例接受 RDS 控制面板调度的管理链路,是通过专门的 RDS VPC 进行数据交互的;而最关键的、承载海量高频重做日志写入的底层链路,则在完全不互通的 Storage VPC 内进行物理层面的切分。这种多层次的深度架构不但提升了安全防御等级,也避免了由于网络资源竞争造成的 I/O 波动。
生产环境洞察:多租户整合、动态扩缩与在线 Schema 演进
通过自 2015 年投入商业运营以来收集到的实际生产场景反馈,Aurora 在应对现代云应用挑战方面不断展现并打磨其独特的工程特性。很多客户在其业务模型上采用了软件即服务(SaaS)的架构范式,出于成本极致优化的考虑,往往会将数以万计的不同客户隔离开的数据库或 Schema 强行打包在一个巨型的 Aurora 物理集群实例内 。这就导致某些生产环境系统被逼迫支撑高达 15 万张数据库表的元数据加载,并在高峰期应对每秒超 8000 个高频连接涌入的恐怖请求规模 。面对海量多租户场景下极其容易爆发的邻居干扰(Noisy Neighbor)问题以及极端连接风暴,Aurora 借助存储系统的超细粒度异步隔离以及消除脏页刷写的平稳缓冲特性,极大地削平了此类负载尖峰,实现了极致的容量整合 。
此外,伴随着以 Ruby on Rails 等现代开发框架驱动的 DevOps 敏捷发布模式的普及,应用程序的数据模型被不断快速迭代,需要进行极其频繁的数据库结构变更(DDL Migrations) 。在传统的开源 MySQL 内核中执行大表字段添加或修改等结构变更,通常需要付出长时间锁死并阻塞表访问、将数据块全量拷贝重写为全新表结构的惨痛代价。为消除这一现代互联网开发生命周期中的梦魇,Aurora 设计并实现了一套前卫的延迟生效的在线结构变更(Online DDL)机制。其不仅做到了以数据页级别的细粒度隔离进行 Schema历史版本更替,更进一步允许底层页面依据结构演化字典进行按需懒惰式升级(Lazy Upgrades)。在“修改时写入(Modify-on-Write)”新原语的支撑下,绝大部分原本极度耗时的结构修改操作得以在无感瞬间完成 。
为了兑现对关键业务应用高可用性协议的承诺,尤其是在规避云提供商不可避免的周期性底层内核版本软件更新带来的数秒连接中断的问题上,Aurora 甚至实现了惊艳业界的“零停机打补丁(Zero-Downtime Patching, ZDP)”技术 。该机制犹如在高速行驶的赛车中途瞬间更换引擎:系统监控并精准捕捉到一个没有处于活动飞行事务的瞬间,立刻将所有正在活跃链接的网络会话及其执行上下文假脱机(Spooling)驻留在本地短暂存在的内存持久化结构上。紧接着数据库内核实例迅速重启并载入最新修补的安全补丁,随后快速重新挂载前置保留的会话上下文。在整个短短数秒钟的深层脑部手术中,用户的应用程序连接始终处于被挂起的活动状态,完全没有任何察觉,彻底杜绝了因底层服务商维护引发的应用端大面积异常断开报错 。
全面超越的基准测试与真实客户性能报告
所有对于传统计算瓶颈理论的打破,最终都在极其严苛的压测基准与商业现实负载中被量化为具体的性能红利 。
在评估数据库系统水平与垂直扩展能力的标准化 SysBench 测试中,Aurora 展示出了完全符合理论推算的极强线性缩放能力,彻底碾压了受困于缓存驱逐负担的传统引擎。当工作负载转向写多读少、并且数据集规模从完全被内存覆盖(In-Cache)转变为海量无法缓存需要强制触发频繁写盘与脏页淘汰(Out-of-Cache)的恶劣环境时,优势对比变得极为悬殊。
表 2:SysBench Write-Only 针对各类大规模数据集的吞吐能力对比测试 (Writes/sec)
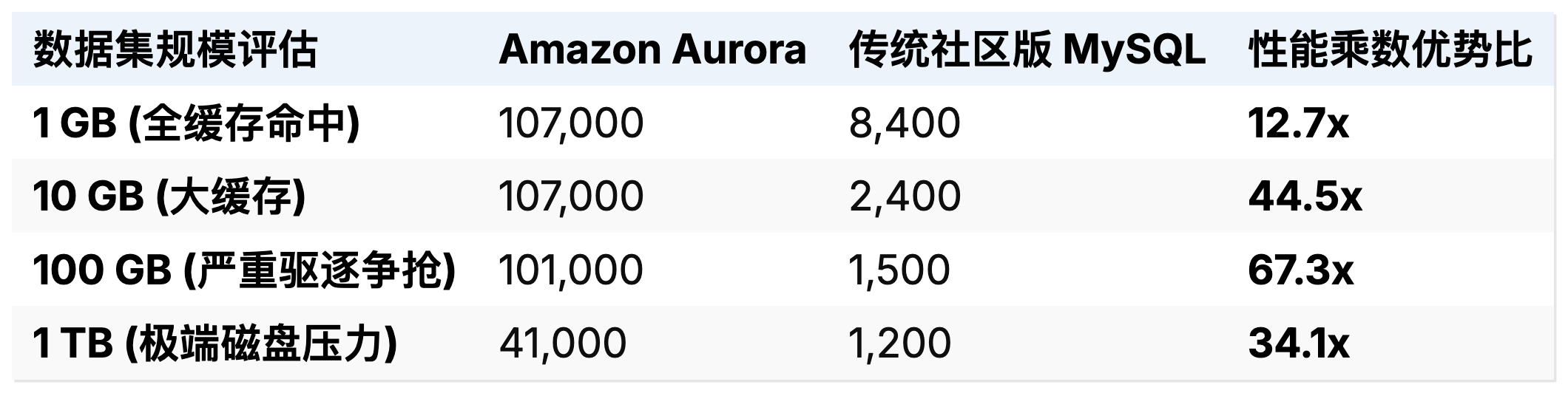
即便在面对模拟极度频繁的热点数据行并发冲突锁定以及跨仓库庞杂事务争抢的标准 TPC-C 测试变体环境下(使用 Percona 提供的高压模型测试工具),Aurora 在各种不同的连接数和数据规模压力矩阵组合中,仍然表现出远超优化后最新版引擎的统御级吞吐。
表 3:Percona TPC-C 变体高压热点竞争模拟分析吞吐量 (tpmC)
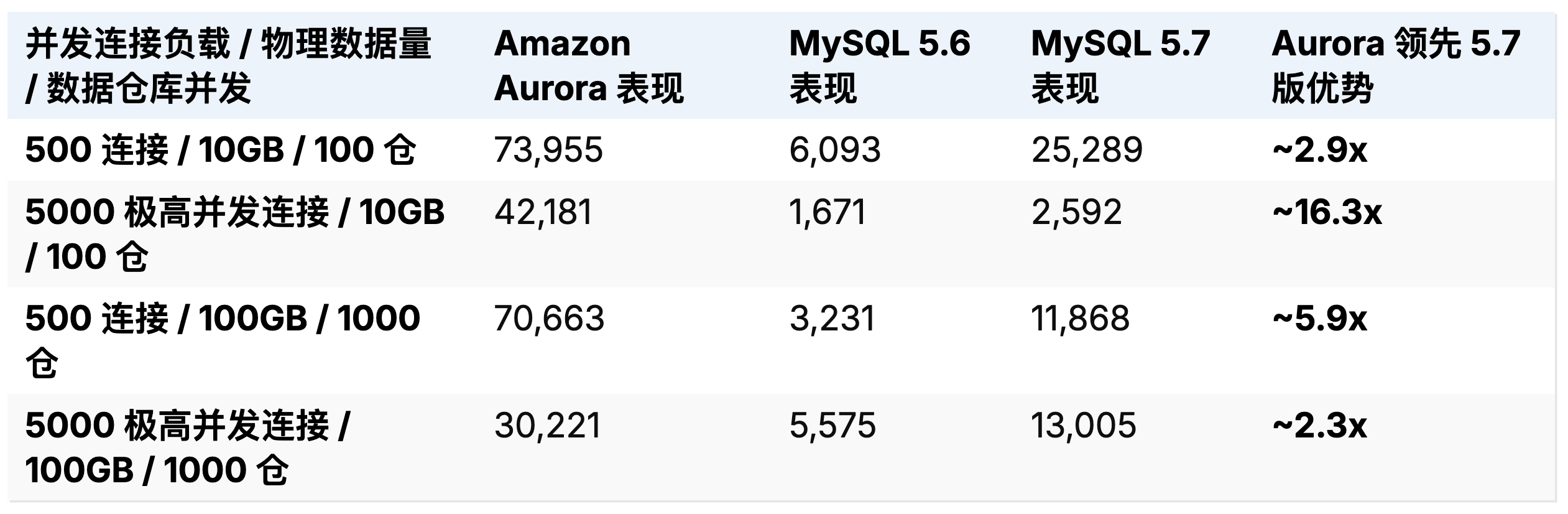
除了枯燥的绝对吞吐上限数值突破外,现实商业用户更在乎的是极其平滑的无抖动长尾延迟。一家处理极高并发数据的互联网游戏企业,在将后端存储设施全面迁移至 Aurora 后,其 Web 系统端到端的事务平均响应耗时直接从饱受磁盘写入抖动折磨的 15 毫秒坍缩至极度顺畅的 5.5 毫秒 。而另一家处理复杂大规模学校设备管理记录的在线教育科技公司报告中同样指出,其原系统在遇到瞬时突发极高频次的 INSERT 记录时,由于遭遇数据库内部刷脏死锁以及并发冲突,大量查询往往会体验到高达 40 至 80 毫秒灾难性的 P95 长尾延迟波动;但将系统割接至 Aurora 后,这类可怕的长尾异常惩罚时间彻底消失,极端情况下的请求也能紧密贴合不足 2 毫秒的 P50 中位数稳定线完美输出响应 。更加不可思议的是主从延迟鸿沟的消弭:在遭遇每秒高达上万笔高强度暴风式全写压力的严峻态势下,传统的 MySQL 备库往往被高耸入云的复制排队任务彻底压垮,落后主库数据高达夸张的数十分钟;反观采用全异步网络多播的 Aurora 底层,其多个共享底层日志存储池的读取节点副本仅仅出现了极其微小、难以察觉的 5 毫秒延迟。这让众多企业彻底摒弃了昂贵的资源闲置冷备灾难预防思路,转而信心百倍地将在线真实用户的核心交互读流量引流倾泻至这 15 个只读副本阵列中,大幅节约算力成本的同时完美兑现了无极水平扩展承诺 。
需要补充的是,早期体现出巨大悬殊优势的基准测试主要对比的是 MySQL 5.6/5.7 版本。随着技术演进,Aurora 现已演进至完全兼容 MySQL 8.0 的 Aurora MySQL v3 版本,原生支持了通用表表达式(CTE)、窗口函数以及基于角色的权限等高级特性,并深度集成了新一代 Graviton3 硬件架构。尽管现代 MySQL 8.0 内核自身在高并发处理上也有了显著改善,但由于 Aurora 在架构底层彻底消除了脏页刷写等 I/O 放大痼疾,这种基于计算与存储解耦带来的写密集型负载优势依然是结构性且难以撼动的。
从消除共识阻塞到突破边界的 Serverless 革命演化
随着 2017 年 SIGMOD 最初始论文框架所引发的技术浪潮扩散,AWS 研究和开发团队并未就此止步。他们随后发布的一系列迭代论文及底层重构服务,展示了在分布式云原生演化道路上探索更深边界的进取心 。
SIGMOD 2018:分布式共识协议陷阱的大规模规避实践
在随后的 2018 年国际数据管理大会(SIGMOD'18)上,Aurora 开发团队通过发表名为《Amazon Aurora: On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes》的研究论文,向整个学术界和工业界阐明了一个极具启发性与反叛精神的全新设计信条 。传统的分布式存储解决方案(无论是构建大规模文件系统还是通用数据库)经常陷入对强大但极端复杂的分布式共识算法(诸如 Paxos 或 Raft)的滥用依赖中。这些传统实现往往在每一次底层 I/O 读写交互、系统组件成员角色更替(Membership Changes)、以及全局事务强一致性提交判定时,都不遗余力地强制要求触发全链路的冗长节点间通信投票协议以达成统一共识,进而导致系统资源的成倍损耗及海量隐性网络延迟的雪崩累加 。
而在该新论断中,Aurora 研究团队剖析了如何利用云环境中独特的不变性(Invariants)保证法则以及单向严格递增的局部状态机制,优雅地绕过对强硬协商一致算法的依赖。在绝大部分常规高频运行路径下(例如数据的读取与异步确认),Aurora 依靠前文详述的高速且极其轻量的单调递增 LSN 系统水位线仲裁,通过维持节点内瞬态的局部进展(Local Transient State)而非强迫实施同步对话沟通,极为成功地规避了分布式共识过程中的通讯风暴开销 。这种反常规的技术理念使得系统不仅再次提升了吞吐极限、大幅消减了因为网络波动及仲裁选举抖动产生的异质性能差异,更为企业级用户大幅压减了用于支撑沉重底层通信负载开销的基础设施成本费用支出 。
彻底根治资源弹性的世纪难题:Serverless v2 架构进化
随着互联网敏捷开发的普及与流量暴涨的不可预测性加剧,用户对资源使用的诉求开始朝着“永远零管理”的极致自动化维度偏移:期望能够在应用启动时维持极小规模基底设施成本占用、并且能够伴随流量洪峰在没有任何技术感知阻碍下自动飙升实现海量规模支撑 。这就迫切需要数据库系统不再基于僵硬的静态虚拟机尺寸来配置算力资源 。为了迎合这股浪潮,2018 年首代面向自动伸缩特性的实验性形态 Aurora Serverless v1 (ASv1) 应运而生 。但其实现路径很快在海量实践反馈中被证明存在着严峻的结构性缺陷障碍。
根据后续在顶级数据库会议 VLDB 2024 所深入披露的研究文献详证分析,虽然 ASv1 版本首次提供了容量代管及起停管理体验,但为了满足缩放所需,它重度依赖一种粗放暴力的“底层热实例交替换绑”网络路由漂移切换池机制 。此机制引发了致命的“跷跷板问题(See-saw Problem)”:系统的水平资源缩放只允许通过极其粗糙的 2 的乘数级放大或减半实施,更糟糕的是,ASv1 被迫必须在系统运转负荷中寻觅一个彻底的“流量静默空洞期(Quiet Points)”,以小心翼翼地将用户的连线会话底层连接安全转移(Session Transfer)到背后潜藏的、尺寸更雄厚或瘦小的新硬件后端实例引擎上 。但在高度复杂的关键业务以及长期密集运行的持久并发进程压迫下,这种完美的转移安全空隙点常常数个小时也不会出现;而且对于那些挂载充斥着海量临时系统表及深度事务交互信息的会话记录状态而言,其跨物理节点的迁移被证明是极度危险且常发生阻塞失败的灾难性包袱。这就直接导致原本寄予厚望的自动缩放触发时机屡屡产生严重误判与滞后响应,不仅完全错失了第一时间抵挡流量风暴的最优窗口,更失去了精确按量控制成本的商业初衷模型 。
在对 V1 痛苦的技术债务历程进行长达数年的透彻解构及底层引擎翻转式深层迭代后,一场针对真正无服务器化理念的技术涅槃随之到来——具有跨时代革命意义的 Aurora Serverless v2 (ASv2) 最终于 2022 年向全球市场发布全面受控可用版(General Availability) 。凭借早已彻底切断盘踞于传统计算与存储间顽固关联枢纽的前沿日志基石架构,ASv2 彻底抛弃了那种依赖更换或挂载异构物理主机的笨拙弹性设计路径思路 。由于沉重的数据存储海洋早已安居于剥离在外且遥不可及的独立数百甚至上千分布式网络底座节点(Storage Layer)中运转不停,全新的 ASv2 计算调配池可以毫无羁绊地实现在原始计算节点进程容器上的极致微观资源(CPU及高速内存缓冲配额)的瞬间拔高与实时收缩调配。现在,系统是以被精确定义的高弹性虚拟刻度单位(Aurora Capacity Unit, ACU)为衡量基准,伴随监控指标的变化在不到半秒的时间内进行无极平滑扩展填充 。由于从始至终在物理层面发生伸展变化的都仅仅是原地运行的计算资源调度分配量额度,没有任何数据或用户复杂会话上下文状态被迫横跨网络进行断网迁移加载,应用侧用户的连接得以维持坚如磐石般的永久连贯不受任何影响。不仅彻底告别了令人恐慌的短时中断重连以及响应骤停现象,更让系统从根本上驯服了各种突发浪涌式的多租户剧烈毛刺型混合业务负载压力 。通过进一步扩展支持跨区域高可用(Global Database)乃至与 RDS 性能剖析监控分析套件无缝集成组装,彻底奠定了其在复杂变量混合流量场景下无可比拟的最优商业性价比计算底座王者地位 。
行业云原生数据库架构生态范式的多维度博弈对比及学术全景映射
若要全面透视并最终定论 Aurora 所采用架构的历史意义,就必须将其技术路线的宏伟切面放置在包含众多极度前沿概念竞品的行业对比框架体系内去审视其异同权衡之道。
在浩繁的分布式系统学术演进历程与工业云系统较量舞台上,“计算分离”这一概念在近些年中已经被广泛探索。由微软研究院出品的 Deuteronomy 框架体系正是通过抽离出一个处理纯粹并发控制及还原逻辑的顶层隔离层(Transaction Component),并将底下的一切持久化任务抛给类似 LLAMA 或底层使用 Bw-Tree 为核心机制的日志结构缓冲存放服务组件(Data Component)来运行处理 。与之类似,具备跨多机群事务管理分片的 Yesquel 架构、以及构建在可扩展抽象共享池上的 Sinfonia 存储平台以及更进一步尝试使用纯粹重做机制放弃复杂崩溃倒车重建过程的框架模型等,都向着同一座去中心化的山峰发起了不懈冲锋攀登 。与这些处于抽象中间态的实验性学术框架不同,Aurora 将下刀切割的解耦边界定夺得更加激进深邃:它极其大胆地将包含了查询调度分解优化、并发事务悲观锁表、多版本缓存页视图替换管理、B树扫描访问查询路由机制等在内的极度复杂的前线指挥工作毫不保留地全部截留在原生关系引擎的最上方容器内,而将被砍下的包含崩溃重放恢复、底层物理落地格式重构排版编纂、周期性快照定格备份及繁杂脏乱的垃圾陈旧记录清除重任毫不留情地全盘下放转移至那个极度去中心化的云规模特种舰队群中运行 。这种对于重做记录这一数据库基石本质内涵所引发的一系列极度专业且精确的手术重排优化(“日志即数据实体”理论派别分支的崛起),正是使得系统网络堵塞传输带宽负担断崖式暴跌的绝密武器之源 。
将目光聚焦回当下云服务领域极具代表性的统治力竞争对手技术架构流派比拼擂台上。在尝试驯服且妥协经典的计算机网络界定海神针 CAP 定理(强一致性 Consistency、极高系统可用性 Availability 与应对撕裂断网的分区耐受宽容度 Partition Tolerance 三者必定不可完美同属兼顾)过程中,诸如被谷歌寄予厚望、横空出世的全球地理分片重型武器 Google Cloud Spanner 系统,毅然决然地挑选了一条死守极致“全球统一时序同步一致性(C)”和坚守广域网络隔绝容忍抵抗性(P)的极硬核布道道路 。Spanner 为此搭建了极为罕见且造价天价的基于分布世界各角落且装配着特殊原子钟信号接收器阵列和高精微波信号定位塔群结合构成的“TrueTime”物理真实时间裁定API体系网络 。其采用沉重且迟缓的两阶段加锁机制协同跨洋两阶段确认提交仪式来强行束缚多方并发更改者行为,这无疑换来了举世无双跨半球严格一致且强行串行可见的读写原子事务奇迹,但这终究只能残酷地以忍痛舍弃局部位极低延迟迅捷响应属性为沉甸甸的代价来进行悲剧般的不可兼顾性交换 。
而在另一个流派阵营中,微软强推的 Azure Cosmos DB 多维全球引擎系统在其弱一致性调节层下,更为果断坚定地全盘倾向倚仗放弃严格全局锁定秩序排队保证以疯狂追求对局部存活极高可用存活状态(A)和极强分裂抵抗特性的妥协拥抱,用以此来攫取极端高速甚至极度狂暴的不间断读写反馈吞吐性能 。作为天然带着 NoSQL 无结构特性背景演变改造而来并提供诸多如地理图库映射转换的变异平台,Cosmos 引擎为了在极端海量庞杂系统中依旧努力拼凑出些许对传统 ACID 一致性承诺的挽留假象手段,极为依赖基于硬性切分指定特定分区映射标识(Partition Key)策略并限定执行环境只能处于单一沙箱微小封闭局部切片环境内的内置执行引擎约束去苟延残喘维系逻辑一致封闭保护罩。一旦涉及到大规模高复杂跨系统纠缠结构,则完全陷入停摆盲区陷阱束手无策 。
作为横跨二者体系裂缝之间绝杀取胜的代表异类,Aurora 未曾觊觎妄想构建一张全网络覆盖并拥有无数复杂交叉相互缠斗交错更新输入渠道的世界级数据狂暴更新互联蜘蛛网(尽管通过后期的 Global Database 层提供异步备份延伸追赶填补) 。相反,它做出了被学术界和业界广为探讨的核心战略退让:坚定捍卫坚守在一个核心逻辑区域内只能存在“绝对单一的写操作下令主宰者”这一最简化极简基础前提公理,由此方能确保其所有产生的下发变更变异信号都能永远老实且被紧紧约束并强制分配来自于单向一条平滑延展的单调极权排序 LSN 流水编码编号池 。正是仰仗着这一个退让简化的天才假设支点作为根基,Aurora 在避免跨海洋昂贵信号强行一致同步沟通拖累的绝佳舒适包围圈保护区内,充分引爆了由海量密集并发操作所带出的史诗级单机区域性能极致突破狂欢盛宴极值。这种放弃追寻乌托邦式纯粹理论全节点同步更新神话并脚踏实地围绕实用云底层拓扑资源特性精准切割开刀的实用极简主义工程思路解法,成功铸就了它横扫企业级千军万马事务并发洪流的不可复制传奇桂冠 。
架构的局限性权衡与 Aurora Limitless Database 的突破
在全面审视 Aurora 的各项技术红利时,也必须客观认识到其工程取舍带来的固有局限性以及系统进一步演进的边界。
首先,Aurora 强依赖的“单一写节点(Single Writer)”模型虽然完美规避了分布式共识的沉重代价,但也意味着系统最大的写入吞吐量受到单一主节点物理计算能力的严格限制。对于绝大多数 OLTP 场景而言,这种垂直扩展(Scale-up)已绰绰有余,但面对需要全球多活或跨分区极高频写入的超大体量应用时,单机架构便不可避免地成为了物理瓶颈。为了突破这一限制,AWS 推出了 Amazon Aurora Limitless Database 服务。该创新架构提供了一个无服务器(Serverless)端点,通过底层引入的分片表(Sharded tables)和参考表(Reference tables)机制,能够自动将海量数据和读写查询路由分布到多个 Aurora 实例引擎上,从而在不改变单一关系型数据库操作视图的前提下,实现了每秒数百万次写入事务的极致水平扩展(Scale-out)能力。
其次,在容灾与高可用层面,尽管跨可用区(AZ)的 4/6 Quorum 模型能容忍局部灾难,但在极端情况下单一主节点发生物理宕机时,系统探测故障并拉起只读副本晋升为新主库的切换过程,依然会不可避免地带来数秒到数分钟不等的写操作停顿(即可用性窗口中断) 。同时,对于跨越多个地理大区(Cross-Region)的 Aurora Global Database 部署,其依赖的后台底层存储网格数据分发依然是基于异步复制机制,这意味着跨大洋的异地只读副本不可避免地会存在一定的网络物理时间延迟。这些都是企业级客户在架构选型和设计高可用拓扑方案时必须衡量的硬性指标。
结论
在这份针对现代大规模云原生基础设施深度演化路径的长篇剖析报告中,我们可以无可争辩地得出最终结论:在追求计算海量并行与极致存储效率的无尽博弈征途上,亚马逊 Aurora 并非是对某种开源代码的浅层缝补修改产品,而是代表了一次将传统单体系统内核核心底座彻底物理爆破、解构、并最终完美融于分布式机群汪洋大海之中的宏伟重新发明。
通过以前所未见的洞察力精准剥离下移那原本如同附骨之疽般死死纠缠在引擎身躯内部、极度消耗且极度缓慢的崩溃还原恢复及繁复同步定格逻辑脏活累活,以及极为天才地将那些只知疯狂消耗侵吞极细网线物理信道传输容量与导致响应震荡发抖的冗杂沉重的数据实体传输块废料降维蒸发打击转化提取成了仅仅只剩薄薄一层纯净变更记录指令向量的精纯流体;Aurora 最终将所有因为磁盘读写缓慢导致进程僵硬发木死锁卡顿等待的沉疴顽疾成功转化为一场分散在极远网络另一端深海机群后台潜伏、并永不停歇执行消化拼接代谢融合且不为人知的极其安静进程活动。配合上无视单体脆弱崩溃规律转而依赖极其野蛮狂暴的多点交叉保护复制组(基于 4/6 法定群体准则的宏大包围容灾体系),加上那个几乎像鬼魅般轻盈、完全不用被迫频繁等待全体沟通确认且凭借精准的局部序列水位极值便能完美自动同步流水的 LSN 无锁信号网罗编排交响曲系统,这一整套从理念到实施天衣无缝相互配合运作闭环的巧夺天工机器,彻底冲破了由那狭窄沉寂数十载物理陈旧瓶颈管道所设置构建起来的难以逾越的封印枷锁囚笼天花板。它的问世与其后代在 Serverless 无极幻化维度、规避宏大沟通代价以及利用 Limitless Database 突破横向写入边界的层层剥笋延展上,不仅向整个全球计算工程师展示并提供了一座犹如神迹般巍然屹立供人瞻仰研究借用的极度高效云基础弹性缩放系统重构底座,更是在可预见的浩大无垠数字世界历史洪流中,替现代商业重装型事务存储管理领域庄严刻画了那标志着终极效能统治形态的路标与演进指南。
