

 1
1 0
0Apache Flink: Stream and Batch Processing in a Single Engine (2015) 解读与学习
引言:大数据计算范式的历史演进与架构革命
在过去十余年的大数据处理演进历程中,数据流处理(如复杂事件处理系统)与静态批处理(如大规模并行处理 MPP 数据库和 Apache Hadoop)长期以来被学术界和工业界视为两种截然不同的计算范式与应用类型 。传统上,批处理系统长期占据了数据规模、计算资源消耗和商业落地用例的主导地位,主要用于生成隔天或隔小时的离线报表;而流处理引擎则更多被束缚于特定的实时监控、低延迟预警等专用场景中 。
然而,现代企业的数据生产本质上是一个随时间持续不断的动态过程。无论是用户在电商平台上的点击流、全球物联网(IoT)设备发出的传感器信号、后端应用集群的运行日志,还是关系型数据库中的事务变更流(CDC),其最原始的物理形态均表现为随时间无休止增长的无界数据流 。为了适应这一数据本质,早期的基础设施架构通常采用了一种妥协的工程方案——即人为地切断时间的连续性,将持续的数据流强制缓冲并切割为静态的数据集(例如按小时或按天进行文件分块),进而采用与时间属性完全解耦的批处理模式进行滞后的离线计算 。这种割裂的处理模式最终催生了早期大数据时代最为著名的 Lambda 架构。
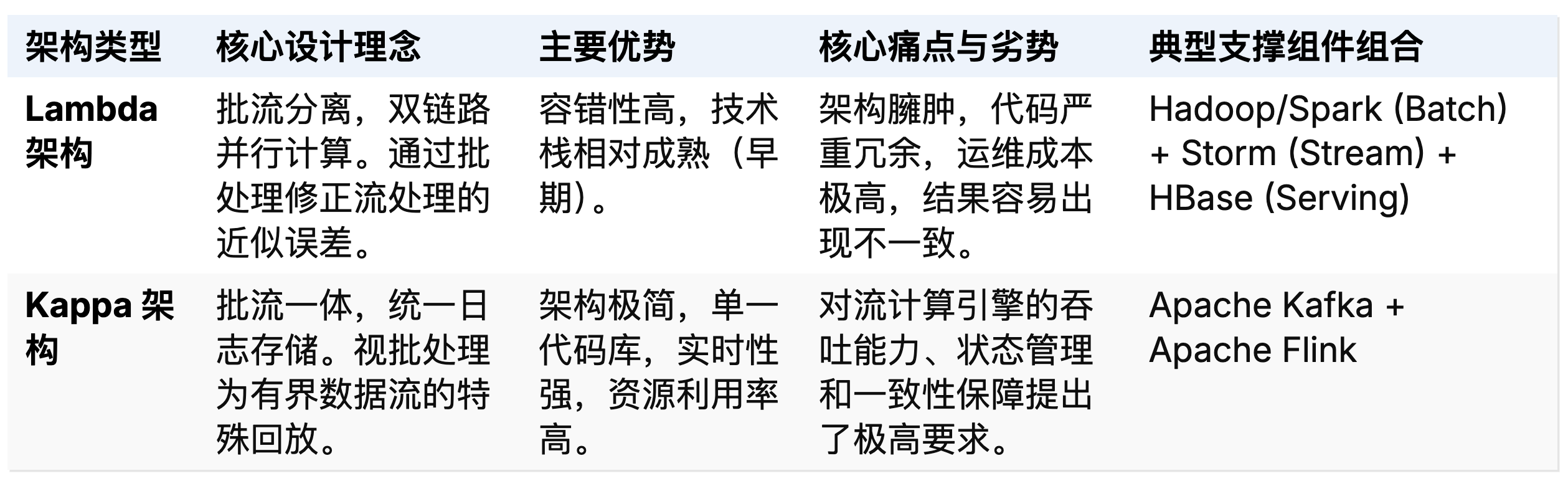
Lambda 架构的妥协与 Kappa 架构的崛起
Lambda 架构最初由 Nathan Marz 提出,其核心思想是通过构建两条并行的物理计算链路来同时满足大规模数据处理对“低延迟”和“高准确性”的双重苛求 。该架构被强行划分为三个层次:负责处理全量历史数据并保证最终一致性的离线批处理层(Batch Layer)、负责提供低延迟近似计算结果的实时加速层(Speed Layer),以及用于对外提供统一查询接口的服务层(Serving Layer) 。尽管 Lambda 架构在一段时间内解决了业务痛点,但其在工程实践中暴露出了灾难性的复杂性:企业开发者必须在两套底层机制完全不同的分布式系统(例如用于批处理的 Apache Hadoop/Spark 与用于流处理的 Apache Storm)中,使用完全不同的编程 API 维护两套业务逻辑完全相同的代码 。这不仅导致了高昂的开发与运维成本,更使得不同计算链路之间的数据对齐与状态一致性调试成为了几乎无法完成的任务 。
为了打破这一架构瓶颈,Apache Kafka 的联合创始人 Jay Kreps 在 2014 年首次提出了 Kappa 架构的概念 。Kappa 架构提出了一种极具颠覆性的“左移(Shift Left)”理念:摒弃双链路的冗余设计,将所有的数据源统一视为不可变的时间序列事件日志(Event Log),并在整个计算生命周期内坚持使用单一的流处理引擎来完成所有任务 。在 Kappa 架构中,批处理不再是一个独立的物理系统,而仅仅是流处理在历史数据回放场景下的一种应用特例 。
Kappa 架构虽然在理论上无比优雅,但在其提出之初,市面上的流处理引擎(如早期的 Apache Storm)普遍存在吞吐量低下、缺乏精确状态管理、无法应对大规模历史数据回放等致命缺陷,导致许多企业对其望而却步 。正是在这种对“真正具备高吞吐、低延迟且状态一致的统一引擎”的极致渴求下,Apache Flink 迎来了其爆发的契机。
奠定基石的 2015 年经典文献
2015 年,由 Paris Carbone、Stephan Ewen、Volker Markl 等来自瑞典皇家理工学院(KTH)、柏林工业大学(TU Berlin)以及 data Artisans(后被阿里巴巴收购)的学者与工程师共同撰写的开创性论文《Apache Flink: Stream and Batch Processing in a Single Engine》在 IEEE 数据工程公报上发表 。这篇获得了超过 1440 次学术引用的重量级文献,不仅是对 Flink 核心架构的全面技术总结,更是一份宣告计算范式转移的宣言 。论文明确提出了 Flink 的核心设计哲学:绝大多数的数据处理应用,无论是实时复杂事件处理(CEP)、持续数据管道、历史数据批处理,还是图分析与机器学习等迭代算法,都可以被统一表达并执行为支持流水线(Pipelined)调度且具备强容错能力的分布式数据流图 。该研究不仅深远地影响了后续数据管理与流处理融合的技术走向(例如对 FlowDB 等学术原型系统的启发 ),更为整个大数据行业如何构建 Kappa 架构提供了最坚实的基础设施级答案。本报告将以该论文为核心骨架,结合 Flink 在随后十年的最新技术演进与工业界实践,对该引擎进行 exhaustive 级别的深度解构。
统一流批处理的系统架构与分布式执行模型
Apache Flink 的底层系统架构被精心设计为一个分层明确、高度解耦的软件栈,由底至上可划分为物理部署层、核心引擎层、API抽象层以及领域计算库层 。这一分层架构确保了系统不仅能灵活适配包括单机 JVM、独立集群(Standalone)、Apache YARN 资源管理器,以及 Google Compute Engine、Amazon EC2 乃至现代 Kubernetes 等多种云端环境,同时也为上层开发者提供了极其丰富且表达力强大的编程接口 。
在软件栈的绝对核心位置,是 Flink 的分布式流式数据流引擎(Distributed Streaming Dataflow Engine)。该引擎将所有业务逻辑抽象为由有状态算子(Stateful Operators)和数据流(Data Streams)互联构成的有向无环图(DAG) 。基于这一运行时核心,Flink 原生提供了两套平行的基础 API:用于处理有限静态数据集的 DataSet API(即传统意义上的批处理),以及用于处理无限持续数据流的 DataStream API 。然而,最为精妙的设计在于,无论是 DataSet 还是 DataStream 程序,最终都会被 Flink 的图构建器与优化器编译为同一种底层的运行时可执行数据流图 。这种设计使得核心引擎本身完全不必感知其处理的是批任务还是流任务,从而在物理执行层面上真正实现了批流统一织入 。在 API 层之上,Flink 进一步封装了面向图计算分析的 Gelly 库、面向分布式机器学习的 FlinkML,以及面向复杂事件处理的 CEP 库和高度 SQL 化的 Table API 。
分布式进程模型与物理执行网络
从分布式集群的进程物理拓扑来看,Flink 采用了一种经典的主从(Master-Worker)架构,其运行依赖于三大核心组件的紧密协同:客户端(Client)、作业管理器(JobManager)与任务管理器(TaskManager) 。
首先,客户端负责接收用户编写的代码逻辑,执行初步的类型推断,基于数据交互的结构特征(Schema)生成专属的数据序列化器,并将抽象代码转化为逻辑数据流图(Dataflow Graph) 。值得注意的是,针对 DataSet 批处理程序,客户端还会额外引入一层类似传统关系型数据库的基于成本的查询优化器(Cost-based Query Optimizer),以决定最优的物理执行路径,随后才将优化后的图提交给 JobManager 。
JobManager 扮演着整个分布式计算网络的主控大脑角色,负责统筹协调数据流的物理分布式执行 。它的核心职责极其繁重:必须实时跟踪每一个分布式算子和数据流分区状态的生命周期,负责新算子的资源调度,并在全局层面上发起和协调检查点(Checkpoints)的生成与灾难恢复 。在启用高可用性(High Availability)集群配置时,JobManager 会在每次成功生成检查点后,将确保集群恢复所需的最小元数据集合持久化至外部高可用容错存储中。这样一来,一旦主 JobManager 发生硬件级宕机,处于热备用状态的 JobManager 能够通过读取元数据迅速接管集群,重建执行状态图并恢复作业 。
真正的计算繁重工作则完全交由分布在集群各处的 TaskManager 节点承担 。每个 TaskManager 是一个独立的 JVM 进程,负责执行分配给它的一个或多个并发算子子任务(Subtasks),并定期通过基于 Actor 系统的 RPC 心跳向 JobManager 汇报其健康状况与计算进度统计 。为了实现单机内的高效并发控制与绝对的内存资源隔离,TaskManager 引入了任务槽(Task Slot)的设计概念 。TaskManager 拥有的 Slot 数量决定了其能够同时支持多少并发任务。不同子任务在不同的 Slot 中运行,使得其内存配额受到严格保障。此外,TaskManager 内部还驻留着用于管理数据网络传输的连接管理器(Network Manager)和负责缓冲与落盘管理的内存/I/O管理器(Memory/IO Manager),这些组件共同构成了决定 Flink 吞吐与延迟表现的底层物理基础 。
数据交换协议、网络缓冲与吞吐-延迟的极致平衡
在 Flink 编译生成的分布式计算图中,算子之间的数据传递通过中间数据流(Intermediate Data Streams)这一核心抽象来实现。中间数据流在物理执行时具有高度的参数化伸缩特性,它代表了一个指向生产者算子所产生数据的逻辑句柄,可以被配置为在流水线(Pipelined)模式与阻塞(Blocking)模式之间进行灵活切换 。
流水线数据交换模式是 Flink 应对无界数据流的默认机制,同时也广泛应用于那些不需要打断执行流的连续批处理任务中。在这种模式下,生产者算子产生的数据记录在序列化后会被直接推入网络,并立即被并发运行的下游消费者算子消费。这种机制不仅彻底消除了数据中转落盘的昂贵 I/O 开销,更深层的系统工程意义在于:它建立了一个天然的反压(Backpressure)传播通道。当消费者算子因为 CPU 瓶颈或外部系统阻塞导致处理速度下降时,TaskManager 内部的网络缓冲池会迅速被填满,这种物理层面的拥塞会通过 TCP 协议栈自然地向上传递给生产者,迫使生产者自动降速,从而有效防止系统在面对瞬时流量洪峰时因内存耗尽而崩溃 。
相反,阻塞数据交换模式则专用于有界数据流的复杂批处理场景 。在该模式下,生产者算子必须在其生命周期内将所有计算结果缓冲、排序并完全写入存储层(通常是溢写到磁盘)后,消费者算子才会被 JobManager 调度启动 。这种阶段分离(Stage isolation)的阻塞式执行策略,虽然牺牲了实时性并增加了磁盘 I/O 和内存开销,但对于执行如排序归并连接(Sort-Merge Join)等管线破坏性算子而言至关重要,它能从物理层面上绝对隔离各个计算阶段,防止复杂的分布式死锁,并极大降低了对集群瞬时峰值资源的要求 。
网络缓冲超时策略的艺术
为了在流水线模式下实现低延迟与高吞吐的极致性能平衡,Flink 摒弃了低效的逐条数据网络调用(Tuple-at-a-time),而是将其数据交换机制建立在高度优化的网络缓冲区(Network Buffers)交换机制之上 。当一条业务数据记录在生产者端处理完毕并准备发送时,它首先被 Flink 的自定义序列化器转换为字节序列,并写入一个预先分配的物理网络缓冲区中 。该缓冲区仅在满足两个硬性触发条件之一时,才会被封装为网络数据包推送给底层的网络通信组件:一是该缓冲区的固定字节容量已被数据完全填满;二是系统设定的缓冲超时时间(Buffer Timeout)阈值已被触发 。
这一巧妙的设计使得 Flink 能够针对截然不同的业务需求进行极致调优。以 2015 年论文中展示的运行在 30 台机器(120个核心)上的分布式 grep 压测实验为例:如果将缓冲超时时间设定为一个极低的值(例如 0 毫秒),数据记录在进入缓冲区后几乎会被立即触发发送指令。这种策略能够实现惊人的低延迟——系统可提供约 20 毫秒的第 99 百分位延迟(99th-percentile latency);然而,频繁的小数据包网络传输会引入高昂的操作系统上下文切换、网络层头部开销与线程争用,导致集群在此极速响应模式下仅能维持每秒 150 万次事件的吞吐量 。
反之,如果逐渐增大缓冲超时时间,系统延迟会随之上升,但由于多条记录被紧密打包在同一个大型缓冲区中批量发送,单条记录分摊的网络开销急剧下降,促使系统吞吐量呈指数级攀升。当超时时间被放宽至 50 毫秒时,虽然第 99 百分位延迟退化至 50 毫秒,但集群的整体吞吐量竟突破了每秒 8000 万次事件的恐怖级别 。这种极其灵活的底层缓冲机制,赋予了 Flink 在纳秒级高频交易与 PB 级离线数据清洗这两个极端光谱之间自由游走的能力。
除了常规的业务数据流转外,Flink 还在数据分区中注入了一系列被称为“控制事件(Control Events)”的特殊标记记录。这些控制事件包括用于协调全局快照和容错的检查点屏障(Checkpoint Barriers)、用于驱动事件时间窗口触发的水位线(Watermarks),以及用于在循环执行图中同步图计算超级步的迭代屏障(Iteration Barriers) 。控制事件与常规数据记录一样,在单个流分区内保证绝对的先进先出(FIFO)顺序。当接收算子遇到这些控制事件时,会触发相应的系统级钩子(Hooks)执行特定的异步协调逻辑。值得注意的是,Flink 不对经过重分区(Repartition)或广播(Broadcast)操作后的整体数据流提供跨分区的全局严格排序保证,而是将处理乱序到达记录的责任完全交给更为高层的算子逻辑(如事件时间窗口机制)去消化,以此换取底层执行引擎最大程度的无锁并发效率 。
时间语义模型与全能型窗口分析机制
在无界的连续流处理领域中,系统如何定义、感知和度量“时间”,直接决定了业务统计结果的准确性与系统的环境适应能力。特别是在现实物理世界中,由于分布式系统网络拓扑的复杂性、不可预知的传输延迟、设备硬件时钟的偏差,以及系统可能发生的宕机重启,数据在到达流处理引擎时,几乎必然会出现乱序(Out-of-Order)现象。为了构建一个具备严格正确性保证的分析框架,Flink 在其核心模型中明确区分并支持了三种截然不同的时间语义 。

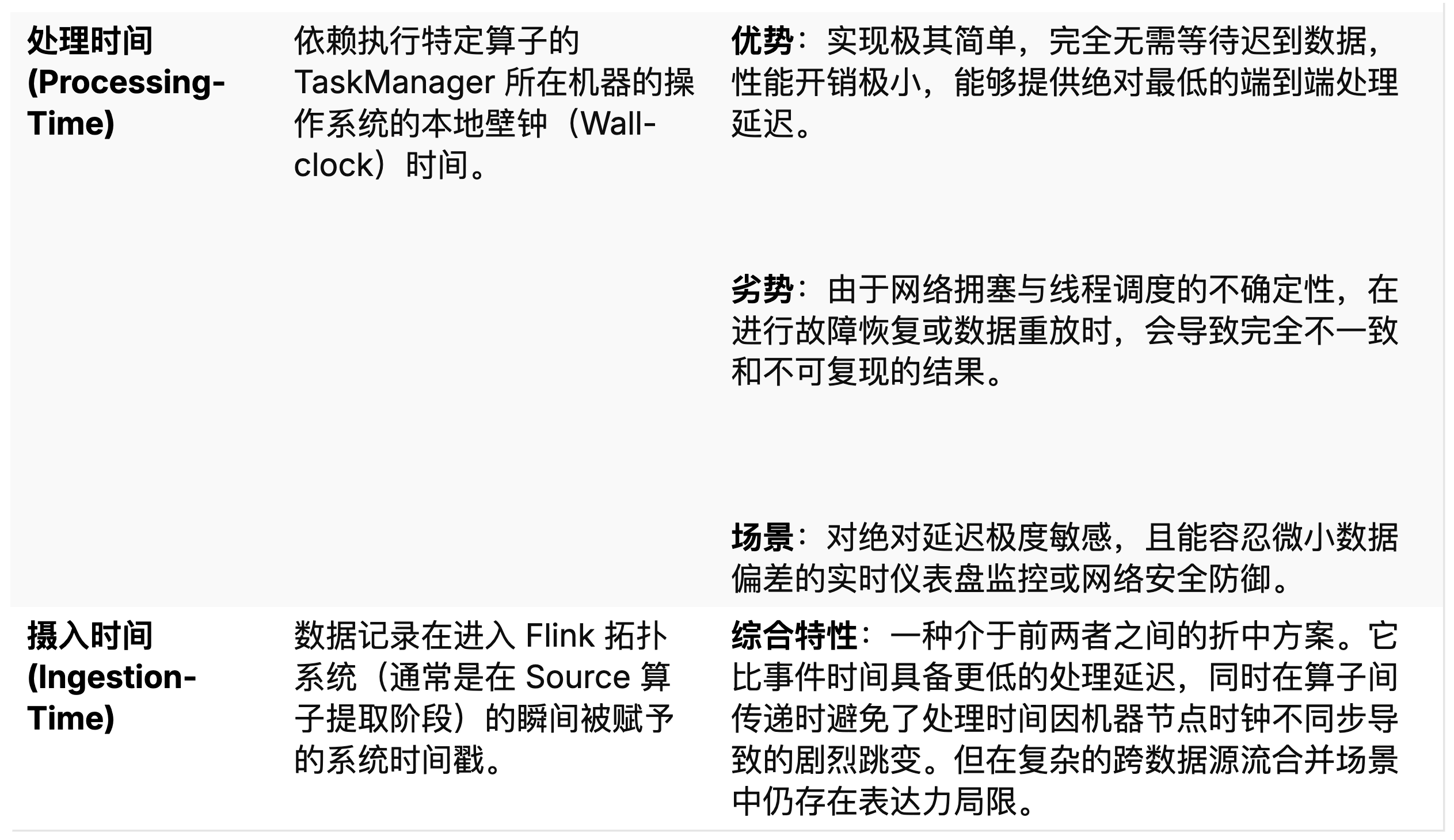
水印机制:克服分布式时钟偏移的利器
在采用事件时间语义时,由于真实世界的时间不可逆,而系统接收到的数据时间戳却是乱序无规的,系统必须拥有一种度量“事件时间进展”的全局标尺。为此,Flink 受到 Google MillWheel 等前沿原型系统的深刻启发,引入了水印(Watermarks)这一核心概念 。
水印本质上是一种特殊的控制事件,包含一个全局递增的时间戳属性 t。当一个携带时间戳 t 的水印被生成并注入数据流中,随后流经某个具体的计算算子时,它是在向该算子及其下游宣告一个严厉的断言:基于系统当前的观察与启发式算法推断,所有实际发生事件时间早于 t 的数据记录都已经全部到达系统,未来不应该再出现比 t 更早的数据 。
水印通常在数据拓扑的 Source 源节点处产生,并随着数据流向全图传播。简单的一元算子(如 Map、Filter)仅需透明地转发它们收到的水印。然而,对于那些基于时间执行复杂聚合逻辑的算子(如事件时间窗口算子),水印的作用至关重要。算子内部的触发器逻辑只有在接收到超越窗口截止时间的水印时,才敢于放心大胆地触发窗口的计算与结果输出。更为复杂的是,当一个算子接收来自多个上游流分区的数据时(例如在执行流关联 Join 操作时),由于不同分区的消费速度差异巨大,Flink 系统会严格遵循最小水印对齐(Minimum Watermark Alignment)原则——即算子自身的当前事件时间被严格锁定为所有输入通道中所接收到水印的最小值。这一保守的对齐机制,是确保复杂多路流处理环境在乱序数据面前依然能够输出完全正确结果的最后防线 。
彻底解构流式窗口抽象:分配器、触发器与驱逐器
窗口操作(Windowing)是流处理引擎将无尽延伸的无界流逻辑切分为有限边界的有界视图,从而执行聚合运算的核心机制。为了彻底覆盖工业界所有已知甚至未知的窗口需求模式,Apache Flink 摒弃了僵化的硬编码窗口类型,转而将其内置于有状态算子之中,并抽象出一套由三个核心且正交的模块化组件构成的异常灵活的声明式 API:窗口分配器(Window Assigner)、触发器(Trigger)以及可选的驱逐器(Evictor) 。
窗口分配器(Window Assigner):其唯一职责是决定每一条新流入的数据记录应该被分配到哪一个或哪几个逻辑窗口中。这不仅仅局限于时间维度。例如,在定义滑动窗口(Sliding Windows)时,分配器会将单条数据复制引用并放入多个存在时间重叠的逻辑窗口集合中;而在定义全局窗口(Global Window)时,分配器会将所有到达的数据一股脑地放入同一个永无止境的虚拟窗口内 。
触发器(Trigger):触发器负责监控窗口内部的状态以及系统时间的流逝,并包含了一组逻辑,决定窗口关联的聚合操作具体应当在哪个绝对物理时刻被执行和输出。例如,一个常规的事件时间触发器会在系统的水印超过该窗口的预定结束时间戳时激活;而一个基于数据特征的触发器则可能在检测到某特定告警标志位时瞬间引爆计算 。
驱逐器(Evictor):作为一个可选的高级拦截机制,驱逐器允许在触发器激活之后、但窗口业务聚合函数实际执行之前(或之后),对窗口内目前缓冲的所有数据进行过滤或裁剪。例如,在一个仅保留最近 100 条数据的全局窗口场景中,驱逐器负责无情地剔除掉第 101 条及更早的历史记录 。
通过这三大组件的模块化组装,Flink 的窗口分配过程表现出了独一无二的完备表达力,不仅能够轻松地复现业界的周期性时间窗口(Tumbling/Sliding Time Windows)与计数窗口(Count Windows),甚至能够原生支持基于时间间隔断层的会话窗口(Session Windows)、标点符号窗口(Punctuation Windows)、界标窗口(Landmark Windows)以及增量聚合窗口(Delta Windows) 。
更为深刻的是,这种将计算(分配器)与输出时机(触发器)彻底解耦的设计理念,从根本上解决了一个长期困扰分布式流计算的死结:迟到数据(Late Data)处理问题 。在 Flink 的灵活窗口机制下,一个窗口完全可以配置复合触发器,在接收到早期数据流时输出一个低延迟的近似结果(类似于 Lambda 架构的加速层),而在水印穿过窗口截止期时输出一个精确结果,甚至在之后面临极其罕见的重度迟到数据时再次触发更新逻辑,覆盖旧值。这种在同一个单一操作内同时计算“早期近似”与“延迟精准”结果的卓越能力,彻底终结了企业需要去组合不同系统进行批流分离架构设计的噩梦,真正奠定了 Kappa 架构的技术基石 。
容错保障的核心机制:从经典理论到异步屏障快照(ABS)算法
在大规模长时间运行的连续数据流计算任务中,由于其分布式的本质,硬件节点崩溃、网络交换机分区、软件层面的内核级死锁乃至整个机房的断电,都是几乎一定会发生的常态化故障。与离线批处理系统中“任务失败只需简单重启重新读取静态文件即可”的容错策略完全不同,一个在生产环境中运行了数周乃至数月的流处理作业,其内部累积了海量的状态(如复杂的机器学习参数模型、尚未触发的滑动时间窗口数据等)。如果面临故障时需要从源头重放数月的事件流进行状态重建,这种在时间维度上不受限制的恢复成本是任何业务都无法忍受的。因此,流处理引擎必须具备在不影响业务流转的前提下,定期生成全局一致性状态快照的能力,并以此为锚点在故障发生时提供精确一次(Exactly-once)的处理语义保障 。
突破 Chandy-Lamport 算法的局限
在分布式系统理论领域,用于获取异步分布式进程全局一致性快照的黄金标准是由图灵奖得主 Leslie Lamport 与 K. Mani Chandy 于 1985 年提出的 Chandy-Lamport 算法 。然而,当尝试将这一经典理论强行应用到现代大数据流处理架构时,却面临着巨大的水土不服。
原始的 Chandy-Lamport 算法为了确保即便在强连通图(包含复杂环路的拓扑)中也能捕获到全局一致性,提出了极为严苛的要求:在生成快照的瞬间,不仅需要每一个分布式计算节点冻结并记录其自身的本地状态,更具毁灭性的是,节点还必须详细且持久化地记录下当时正处于各个通信通道(Communication Channels)中传输、尚未被对端接收的全部“飞行数据消息(In-flight Messages / Channel States)” 。在大吞吐量的流计算网络中,通信通道中堆积的数据包动辄达到千兆字节(GB)级别。要求系统在生成快照时将这些海量的缓冲数据一同写入磁盘备份,不仅会疯狂消耗磁盘 I/O 吞吐与内存配额,更会极大拉长快照时间,并引发严重的计算迟滞(Stall),对吞吐量的冲击几乎是灾难性的 。
异步屏障快照(Asynchronous Barrier Snapshotting, ABS)的诞生
为了彻底克服这一理论瓶颈,Flink 的核心设计团队基于数据流引擎本身主要呈有向无环(DAG)拓扑结构的深刻洞察,首创并实现了极其优雅的异步屏障快照(ABS)算法 。
ABS 算法放弃了全局锁与冻结系统,转而通过向持续流动的数据流中巧妙注入被称为“屏障(Barriers)”的控制记录来实现隔离 。其完整的执行周期如下:
触发与屏障注入:JobManager 定期启动快照过程,向数据流图最上游的所有 Source 算子发送指令。Source 算子首先记录并持久化自身当前的数据读取偏移量(例如 Kafka 的 Partition Offset),随后生成一个带有全局单调递增的快照版本号(如 Snapshot N)的屏障,并将其注入到向下的输出数据流中。屏障如同流水线上的挡板,将无界流在逻辑上严丝合缝地劈开:屏障前方的数据记录其效应用以构建当前的 Snapshot N,而屏障后方的记录效用将留给未来的 Snapshot N+1 。
屏障流动与算子对齐(Alignment):当下游的一个算子从其某个输入通道接收到屏障 N 时,奇妙的逻辑介入了。由于该算子可能还有其他的输入通道,为了保证不将未来版本的数据状态混入当前快照,算子会立即停止处理该通道中跟随屏障 N 之后到达的所有常规数据记录。它将这些后续数据滞留在内存缓冲区中,并耐心地继续处理其他尚未送达屏障 N 的通道数据。这一等待其他通道的过程被称为“屏障对齐” 。
状态持久化与广播:当该算子成功接收到所有输入通道传来的屏障 N 时,意味着在这一逻辑时间点上,该算子已经精确无误地消化了构建当前快照所需的所有历史数据,且完全没有接触任何逾矩的未来数据。就在这一绝对静止的微观逻辑瞬间,算子将其当前内存中的内部业务状态(例如窗口聚合的总和数值、自定义数据结构等)通过异步后台线程写入高度可靠的外部持久化存储底座(如 Hadoop HDFS 或是云端的 Amazon S3 之中)。确认写入指令下发后,算子会解除输入通道的封锁,恢复数据的正常处理,同时将屏障 N 立即沿着它自己的输出通道广播给下一级算子 。
当屏障 N 最终流经系统最底层的 Sink 算子,且所有 Sink 算子向 JobManager 汇报其状态持久化成功后,一个无需暂停整个拓扑的全局分布式一致性快照便正式宣告完成 。如果在后续执行中遭遇系统崩溃,Flink 只需将所有算子的状态回滚到该全局快照所记录的绝对值,同时命令所有的 Source 算子将源头的读取游标退回到记录的对应偏移量,并从那里重启数据流注入即可。这一机制严格且毫无瑕疵地保证了 Exactly-once 的故障恢复语义。
ABS 算法在性能数据上展现出了压倒性的统治力。相较于传统需要记录飞行通道数据或是采用阻塞式落盘的系统方案,由于 ABS 算法将需要写入磁盘的冗余数据量降至了理论上的绝对最低极限(即只包含纯粹的算子状态本身),在一项严谨的基准对比测试中,ABS 算法不仅彻底维持了数据摄取的线性扩展性,更一举降低了超过 38% 的检查点消耗时间、缩减了 33% 的系统灾备恢复延迟,甚至在快照生成的高峰期,将系统的 CPU 占用率与内存驻留量分别砍掉了 47% 与 37% 。
解决极端反压难题:非对齐检查点与缓冲去胀
然而,即使是精妙绝伦的 ABS 算法,在复杂的企业级生产环境中也暴露出了一处致命的阿喀琉斯之踵(Achilles Heel):当遇到系统级反压(Backpressure)时,快照过程会陷入极其被动的瘫痪状态 。
如前所述,当某个下游算子因为处理繁重的计算逻辑或是遭遇外部系统的写入节流瓶颈时,网络缓冲区会被数据迅速塞满,进而通过 TCP 反压导致上游算子发送受阻 。在严重的背压场景下,数据在管道中如蜗牛般爬行,这意味着承载着容错使命的检查点屏障(Barriers)将被大量拥塞在网络缓冲区的末端,根本无法按时流通到下游算子以触发“屏障对齐”与状态持久化逻辑 。当屏障因为阻塞而在传输管道中耗尽了预设的超时时间(Timeout)后,会导致检查点频繁宣告失败。更具讽刺意味的是,常规对齐过程中必须暂停消费较快通道数据的设计,在反压发生时不仅无助于缓解拥堵,反而会加剧整个集群的吞吐量雪崩 。
为彻底攻克这一顽疾,Flink 在近年的架构迭代中引入了非对齐检查点(Unaligned Checkpoints)这一极具破局性的高阶功能 。
非对齐检查点在面对复杂反压时采取了截然相反的哲学路径。在这种模式被激活后,当算子从某一个网络通道接收到屏障后,它完全放弃了极其耗时的“等待其他通道对齐”过程。相反,它让屏障像救护车一样在数据队列中获得绝对优先路权,“超车”越过当前堆积在输入和输出缓冲区中的所有未处理数据,并立刻向更下游广播 。由于打破了对齐逻辑导致的时间线混淆,算子必须立刻将自身状态,连同那些在通道中被屏障超越的、尚未处理完毕的所有“飞行中数据缓存(In-flight Buffers)”全部打包抓取,并一并写入到快照存储之中 。
非对齐检查点深刻体现了分布式工程系统设计中极为经典的权衡(Trade-off)艺术 。它的出现成功且彻底地将检查点完成的速度与当前数据流转的速度解绑,使得 Flink 在面临最极端恶劣的背压阻塞网络中,依然能够迅速、稳定地完成系统快照闭环,避免容错机制的失效停摆。然而,这一收益的代价是昂贵的:系统付出了更高的瞬时外部存储 I/O 写入负担、导致了更加庞大臃肿的快照文件体积、拉长了重启时所需的数据恢复时间,并在具有多输入流的算子中增加了处理潜在重复记录的微小风险 。为了进一步平滑这种代价,Flink 同时配合推出了缓冲区去胀(Buffer Debloating)技术,通过动态监测系统的吞吐指标,自动压缩网络缓冲池的分配规模,从源头上减少飞行数据的堆积量,从而在非对齐模式下亦能控制快照体积的膨胀 。这一系列深度底层重构,赋予了 Flink 在最严苛工业环境中无可匹敌的容错健壮性。
主动内存管理机制与底层二进制操作革命
在利用 JVM 语言(如 Java 与 Scala)构建极高性能数据引擎的过程中,大数据从业者面临着一个长期难以逾越的技术鸿沟。早期的框架(如原始形态的 Hadoop 以及未经过 Tungsten 计划深度改造前的 Spark)习惯于在 JVM 的堆(Heap)内存中直接分配海量的 Java 对象来代表一条条缓冲的在途数据记录 。这种看似天然的做法,却引发了灾难性的系统后果。当堆中驻留着数以十亿计的微小、生命周期差异极大的对象实例时,JVM 的垃圾回收器(Garbage Collector, GC)需要耗费巨量的 CPU 时钟周期去遍历与扫描庞大的对象引用追踪树 。这不仅导致严重的资源浪费,更会频繁触发全堆级别的“Stop-The-World”垃圾回收停顿。在对毫秒级延迟极为敏感的流计算系统中,动辄数秒甚至数十秒的 GC 停顿不仅彻底粉碎了实时预警的承诺,更会导致分布式心跳检测机制误判任务节点已经宕机,进而引发不必要的故障恢复与重调度风暴 。此外,复杂的 Java 对象头部元数据带来了巨大的存储空间膨胀(Storage Overhead),使得可用内存急剧缩水 。
为了在这个底层战场上取得彻底的性能优势,Flink 从架构设计之初便全面吸收了传统关系型数据库管理系统(DBMS)的核心精髓,并在 JVM 环境之上构建了一套极度硬核的主动内存管理(Active Memory Management)体系 。
规避 JVM 缺陷的物理内存分层区隔
在现代 Flink 的 TaskManager 节点内部,系统内存被实施了近乎军事化般严格的分区分层控制策略。系统彻底告别了单一维度的堆内存分配,将其切分为如下几个具有特定使命的物理隔间:
JVM 堆内存(JVM Heap):Flink 仅仅将一小部分的堆内存资源留给用户代码逻辑的执行(如 UDF 函数分配的临时变量)、部分对性能不敏感的框架控制类对象,以及在特定轻量级场景下使用的堆内状态后端(Heap State Backend) 。这部分内存受限于 JVM 原生的垃圾回收约束。
堆外托管内存(Managed Memory / Off-Heap):这是 Flink 主动接管的最核心重镇,直接通过操作系统级别的系统调用申请物理内存页面。所有用于复杂的底层数据排序(Sorting)、哈希关联(Hashing)、大规模批处理缓存,以及支撑庞大的嵌入式 RocksDB 状态后端块缓存(Block Cache)的数据,均被强制迁移至此 。这些完全游离于 JVM 视线之外的内存块,彻底免疫了任何形式的垃圾回收扫描(GC overhead) 。
网络缓冲内存(Network Buffers):专门划拨的用于跨节点分布式数据交换的独立内存池。Flink 引擎能够根据全局内存配置,自动验证并强制推导出满足吞吐需求的最小与最大缓冲限额,确保网络层通信不会因瞬时阻塞而反噬挤占计算内存 。
JVM 元空间与直接内存开销控制(JVM Metaspace & Overhead):由于 Flink 需要动态生成海量的类文件(如即时编译生成的序列化器与执行代码),因此必须显式控制 Metaspace 的上限,避免元空间耗尽引发的 OutOfMemoryError 崩溃 。
基于字节码序列的二进制运算艺术
在确保了堆外托管内存的安全避风港之后,Flink 引入了另一个技术王牌:DBMS 风格的二进制直接运算 。当任何业务数据流入框架内核准备进行缓冲、聚合或跨节点传输时,立刻会经过 Flink 基于类型推断与代码生成(Type Inference & Code Generation)技术打造的专属高效序列化栈 。这些数据被剥离掉所有沉重的 Java 对象外壳,转化为最为纯粹、紧凑的二进制比特序列,并被连续填充入固定长度的物理内存段(MemorySegments)之中 。
这种颠覆性的设计带来了极其丰厚的技术分红。首先,极大地削减了反序列化开销:诸如对海量记录进行字段排序或多表主键关联操作时,Flink 算法直接在二进制字节层面对键值特征进行扫描对比。只有在确认需要将特定记录抛向用户自定义逻辑时,才会触发昂贵的反序列化操作将其重塑为 Java 对象 。其次,紧凑的二进制序列化表示大幅提升了现代多核 CPU 的高速缓存命中率(Cache Sensitivity),使得底层指令集运行更为流畅 。更为关键的是,由于底层数据块具有确定的物理大小和形态,当系统面临极端的内存耗尽危机时,Flink 能够以极其平滑、优雅的姿态,将这些固定尺寸的内存块直接溢写(Destage/Spill)到本地磁盘上 。这种“外存运算(Out-of-core Algorithms)”能力赋予了 Flink 极为坚韧的系统稳定性,使其能在内存受限的恶劣硬件环境下顽强地处理远远超过内存容量的海量批处理与重型图计算数据集。
状态后端的物理挂载
如前文所述,在处理包含大规模特征维度矩阵或复杂滑动时间窗口的流计算任务时,算子的内部状态数据规模极有可能膨胀至数百 GB 甚至数 TB。Flink 将逻辑上的状态概念与底层的物理存储解耦,引入了可拔插的状态后端(State Backends)体系 。
Heap State Backend(堆内状态后端):对于小规模且对读写延迟极其苛求的任务,状态以 Java 对象的形式常驻堆内,能够实现微秒级以下的极速存取,但容易受到 GC 惩罚,且内存容量面临严峻天花板 。
RocksDB State Backend(RocksDB 状态后端):对于需要存储海量特征数据的巨型流作业,Flink 内嵌了极其强大的 RocksDB 键值对数据库引擎。状态被序列化并持久化至本地磁盘及受控的堆外内存块缓存(Block Cache)之中 。这一机制虽然引入了额外的磁盘与内存交互 I/O 成本,但彻底打破了单机内存天花板对状态规模的限制,是支撑现代金融风控特征计算等重型状态处理的中流砥柱 。
面向有界静态数据集的深度批处理优化引擎
在贯彻了将所有的计算统一于分布式数据流之上,并利用网络缓冲与二进制内存管理夯实了执行引擎的基础后,Apache Flink 面对的核心挑战是如何使其针对有界静态数据(Bounded Data)的批处理任务,在性能上不仅不落后于,甚至要超越那些传统的专为离线计算打造的霸主系统。
诚然,根据 Flink 的理论体系,有界静态数据集仅仅是无界数据流的一个微小特例。只要我们在逻辑上将所有的输入数据硬塞进一个无限大的全局窗口(Global Window)中等待执行,流计算系统在理论上完全能够得出批处理的最终结果。然而,在真实的工业应用中,对于动辄扫描数千亿行表格的复杂 SQL 查询关联,这种简单的流式抽象不仅语法繁冗(需要定义人工全局窗口),而且完全没有利用到“数据完全静态且有界”这一极其珍贵的前提条件 。为了兑现其高性能的承诺,Flink 对传统的批处理链路实施了针对性的降维与特化优化。
首先,在容错机制层面,对于纯粹的批处理 DataSet 作业,极其昂贵且复杂的周期性状态快照机制(ABS)被完全关闭或大幅削弱。因为静态输入源数据始终静静地躺在外部文件系统(如 HDFS 或 S3)中,系统发生任何故障,只需简单地回溯并在最新的物化检查点或源头重新拉起计算分支即可,极大释放了执行期的计算与网络资源 。
其次,更具技术挑战的优化集中于 Flink 的批处理查询层。在传统的关系型并行数据库领域,基于成本的查询优化技术(Cost Modeling and Query Optimization)早已十分成熟。但 Flink 所面对的不仅仅是标准的关系代数,而是一个充斥着各种黑盒式用户自定义函数(UDF-heavy DAGs)的复杂分布式数据流图 。由于 UDF 向优化器屏蔽了内部操作语义,传统的记录数基数估计(Cardinality Estimation)方法彻底失效 。为了突破这一技术壁垒,Flink 的优化器构建了一套新颖的技术路线,它不仅能够接受有经验的程序员主动注入的关于数据量变化的编译提示(Hints)来推导基数变化,更引入了被称为“有趣属性传播(Interesting Property Propagation)”的高阶理论 。
在该理论的驱动下,优化器在解析批流图时,会主动探测数据分区和排序特征(有趣属性)在操作图中的传递路径。系统支持极其多元的物理执行策略矩阵,涵盖了广播数据传输(Broadcast)、哈希重分区传输(Repartitioning)、基于磁盘和内存联合的排序分组(Sort-based Grouping)乃至哈希关联与排序归并关联(Sort- and Hash-based Join)的多重实现版本 。优化器在编译期会对这些物理计划的成千上万种排列组合进行暴力探索和成本评估。其成本核算模型不仅衡量纯粹的 CPU 指令消耗,更深入到底层,全面预估磁盘页交换的 I/O 代价以及集群网络分发的拥堵成本 。经过这番地狱般的深度优化,当同一个 DataSet 程序被递交给 TaskManager 时,它可能已经被彻底改造为了最契合当前硬件拓扑的高效机器级执行指令。这也是 Flink 作为一套基于流内核构建的引擎,却能够在各类权威批处理 TPC-H 压力测试中展现出与 Spark 乃至传统数据库比肩统治力的核心机密。
迭代计算的降维打击:从 Bulk BSP 到增量迭代逻辑
在复杂的图分析计算(如 Google 著名的 PageRank 排名算法)和大规模并行机器学习(如梯度下降参数调优)领域,算法需要基于同一套基础拓扑数据,进行成百上千次的反复迭代循环训练 。
在 Flink 诞生之前,Hadoop 的 MapReduce 被证明完全不适合执行此类图计算,因为其在每一次外围循环(Loop)结束时,都必须将庞大的中间状态持久化写入磁盘 HDFS 系统,导致 I/O 开销彻底锁死性能上限。Apache Spark 凭借其弹性分布式数据集(RDD)在内存中的缓存机制,通过在外部 Driver 节点不断触发提交新的子计算图的方式,极大地改善了迭代效率,一战成名 。然而,这种将循环控制逻辑剥离出计算引擎外部、需要不断与调度器进行交互重组的架构,依然存在难以逾越的系统损耗。
Flink 则采用了截然不同的物理架构来征服这一难题。依托于其天生具备流水线和反馈能力的流处理执行图,Flink 抛弃了外部提交机制,直接在内部核心数据流图中原生引入了能够形成闭环数据回路的“迭代头(Iteration Head)”和“迭代尾(Iteration Tail)”任务节点 。当开启迭代时,隐式连接这些节点的反馈边(Feedback Edges)直接在 TaskManager 的内存网络之间构建了物理数据的循环传输通道 。为了同步并控制并行工作节点的演进节奏,Flink 系统会在反馈通道中精确注入迭代同步控制事件(Iteration Control Events),以此严密构建出极其标准的大量同步并行(Bulk Synchronous Parallel, BSP)或陈旧同步并行(Stale Synchronous Parallel, SSP)计算超步模型 。
然而,Flink 对迭代计算的理解并未止步于此。在许多高级图算法如 PageRank 的深层推演中,存在一个极其重要的数学特征:随着迭代次数的不断增加,图中绝大多数节点的权重变化幅度会急速缩小甚至趋近于静止,只有极其微小的一部分热点节点及边缘网络仍需要继续更新状态 。面对这种高度稀疏的依赖网络,如果每一轮依然机械地(Bulk)扫描和计算所有上亿级别节点的完整拓扑,无疑是巨大的算力浪费。为此,Flink 在其批处理 API 中创造性地实现了增量迭代(Delta Iterations)架构 。
在增量迭代体系中,系统将被迭代的数据严格拆分为两部分:只读的静态拓扑结构和需要不断更新变异的增量工作集(Working Set)。在每一轮计算(例如 PageRank 的第 10 次迭代超步)开始时,系统能够精确感知并仅仅处理在上一轮中权重发生实质性改变的顶点子集及其直接邻接边 。通过这种极其精妙的算力收敛技术,随着迭代层数的深入,系统需要调动的计算工作集规模呈指数级衰减 。在一项关于大规模 PageRank 的性能对照实验中,凭借着 Delta Iterations 对无效计算分支的精准修剪功能,Flink 图处理库 Gelly 所展现出的迭代耗时收敛速度与资源利用率,足以将那些只能依赖全量循环的竞品系统彻底抛离数个身位 。
行业生态矩阵与竞品框架的全方位对比评估
将 Flink 放置于 2010 年代中期至当今的大数据引擎图谱中进行多维度的比对,可以极其清晰地刻画出其技术护城河的演进脉络,特别是在与两大历史级框架 Apache Spark 和 Apache Storm 的终极技术博弈中 。
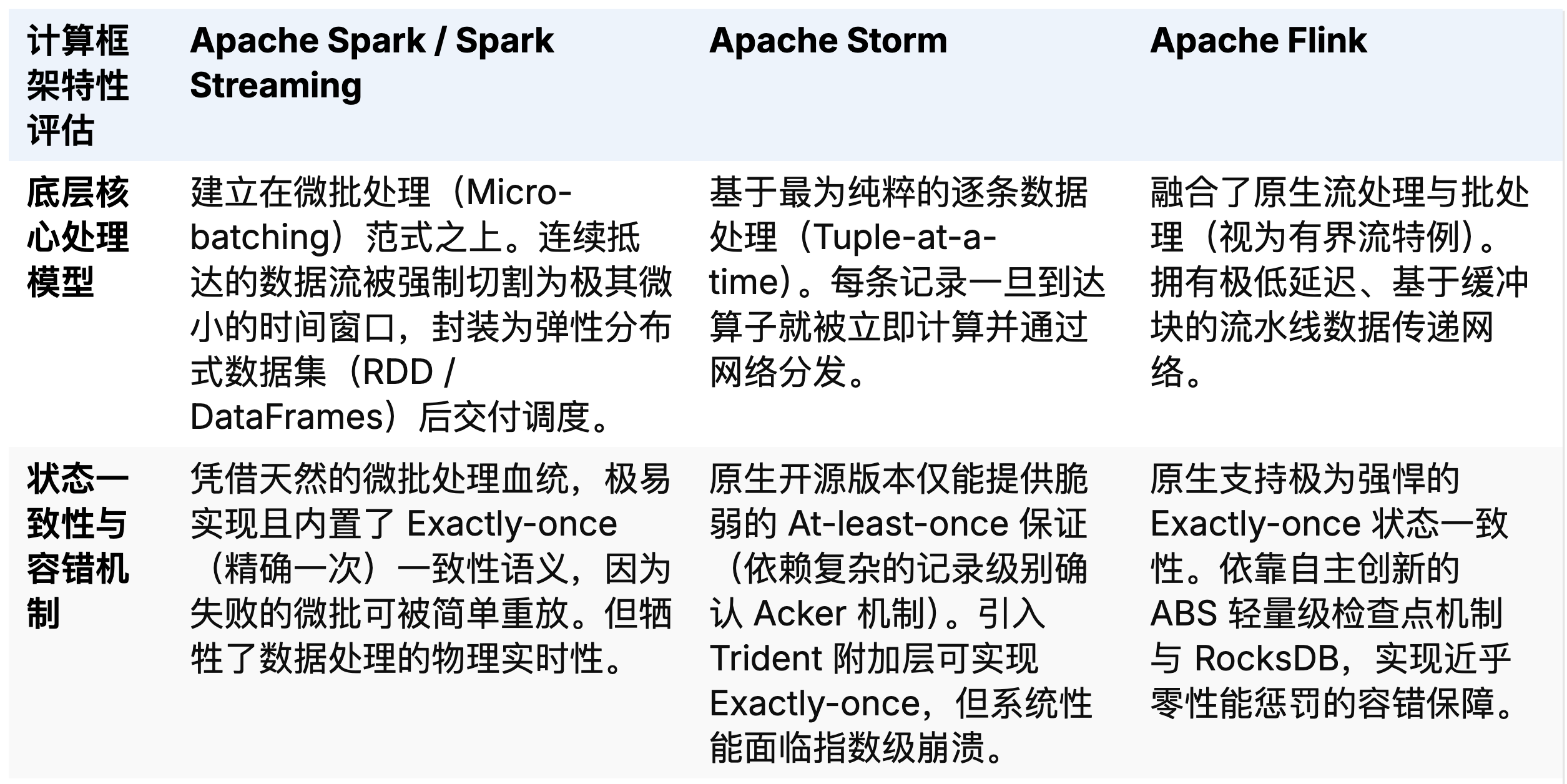

在早中期的大数据架构设计蓝图中,Spark 因为顶着 Hadoop MapReduce 最完美继任者的光环,并在基于内存的批处理上展现出了横扫千军的威力,长期占据着计算市场的绝对统治地位 。当移动互联网红利催生海量实时监控需求时,Spark 社区为了迅速占领市场推出了 Spark Streaming,试图利用微批架构复用其现有强悍的批处理引擎与容错体系。然而,这种治标不治本的架构不仅无法从底层解决事件驱动系统对于绝对毫秒级低延迟的苛求,也难以自然地表达复杂的基于事件时间(Event-time)的窗口聚合逻辑,最终沦为高延迟流处理的代名词 。另一方面,作为流计算先行者的 Storm 提供了毫无保留的纯粹逐条数据处理能力,填补了实时风控响应的空白。但其简单的记录级树状确认机制(Acker)导致了令人绝望的网络开销冗余,且在面临节点级断电故障时无法提供严格的不丢失、不重复计算(Exactly-once)保证,同时自身设计的单一性也将其彻底阻绝于广袤的批处理数据仓库大门之外 。根据学术界的严谨对比基准测试,即便在不开启复杂容错特性的原生吞吐压测中,Storm 和 Flink 这样的原生流处理系统,其执行效能亦能达到 Spark Streaming 这种微批架构的 15 倍以上之巨 。
在这一犬牙交错的行业背景下,Flink 提出的“视流计算为万物基础的统一引擎”理念无疑是石破天惊的破局方案 。它在工程上用铁一样的事实证明了开发者不再需要痛苦地在低延迟响应、高吞吐吞吐量以及结果的严苛一致性之间做出妥协 。通过极为精细内置的操作符状态管理、优雅的缓冲超时(Buffer Debloating)弹压策略,配合 ABS 屏障快照的高效闭环,Flink 不仅全盘接管并超越了 Storm 所承诺的毫秒级时效延迟,更在大量复杂关联压测中达到了甚至隐隐超越 Spark 这一微批霸主的吞吐吞吐量指标 。
更具划时代意义的是,大约在 2015 年之后,业界在历经无数数据对账的挫败后,普遍深刻认识到了由于物理时延和网络跳跃导致的“乱序数据处理(Out-of-Order Processing, OOP)”能力的重要性。受到 Google 闭源系统 MillWheel 与后续 Dataflow 模型极其深刻的学术启迪,Flink 在一众主流开源社区中,以前所未有的决断力率先引入了极度完善的事件时间处理逻辑和基于触发器的灵动窗口机制 。这种深入系统基因、从根本上掌控并扭曲时间维度、彻底抹平由于乱序时钟偏差带来的业务抖动的能力,赋予了系统极其可靠的可信赖度,并最终将 Flink 托举上了支撑现代极速金融交易风控、自动驾驶实时传感器聚合以及超大互联网公司海量点击流推荐模型刷新等核心生命线场景的王座 。
客观视角的系统局限性:批处理主导权与 SQL 生态的现实差距
尽管 Flink 在批流一体理念上取得了理论上的统领地位,但在客观的工程实践中,其并非在所有计算领域都占据绝对主导。在纯粹的离线批处理与传统数据仓库场景中,其生态圈与实际表现仍存在客观的局限性。以 Apache Spark 为例,Spark 凭借其弹性分布式数据集(RDD)及 DataFrames 机制,结合历经多年深耕优化的 Tungsten 物理执行引擎和 Catalyst 逻辑优化器,在处理海量纯离线大批量 ETL 场景中依然占据着难以撼动的优势与行业最高的话语权。虽然 Flink 的底层引擎完全支持将批处理视为特例并进行基于代价的优化,但其批处理能力很大程度上仍是流计算内核的副产品化衍生,而非专门针对静态数据堆叠打造的极致优化引擎。
此外,在 SQL 生态成熟度方面,尽管 Flink 的 Table API 和 SQL 引擎近年来发展迅速,被确立为未来的战略方向,但相较于 Spark SQL 历经十余年积累的丰富工具链、第三方库广泛兼容性以及在复杂多表关联查询中优化器行为的极度可预测性,Flink SQL 在某些极端复杂的即席查询(Ad-hoc Query)场景下,仍可能出现性能瓶颈或需要人工介入调优。在企业真实的技术选型中,如果核心用例是纯离线批处理且高度依赖成熟的分析生态,采用 Spark 往往仍是更加稳妥的优先选择。
生产环境中的重重挑战与运维深水区
尽管 Flink 在理论架构和核心算法上近乎无懈可击,但在将其大规模推向企业级生产环境并深耕多年的过程中,这套极其精密复杂的分布式巨兽也给工程团队带来了诸多严峻且难以规避的运维挑战与工程债。
其中最为令运维工程师头疼的是极其陡峭且复杂的故障排查与调试(Debugging)曲线。由于 Flink 作为一个枢纽管道,其两侧往往连接着极为庞杂的上下游组件,当一个 Flink 实时作业发生崩溃或结果异常时,其根本诱因往往并非引擎本身的逻辑缺陷。源头可能隐藏在上游数据源发出的畸形乱序时间戳中,可能是底层网络基础设施连接超时引发的心跳丢失,抑或是外部数据存储服务因写入过载反向施加的毁灭性反压 。在缺乏足够通透的可观测性支撑下,开发者极难在这层层迷雾中定位到真正的问题根源。因此,构建包含详尽日志追踪、实时细粒度系统指标监控面板以及数据血缘(Lineage tracking)关联的立体化可观测(Observability)体系,成为了驾驭这一引擎不可或缺的重型先决条件 。
更加宏观且致命的挑战往往深埋于长期的系统维护与升级流转之中。作为一个极其庞大的生态系统,现代 Flink 往往部署于 Kubernetes 这样的云原生容器编排环境中,同时紧密捆绑着数量繁多的各类外部连接器(Connectors)。一次看似微小的底层基础设施升级(如 Kubernetes 的底层组件更新),或是外部消息队列(如 Kafka 内部升级引发的关于数据保留期策略或消息语义投递规则的微调),都极有可能如蝴蝶效应般引发一连串的雪崩式级联故障,最终导致数个原本健康运行的核心 Flink 作业陷入瘫痪或数据倾斜 。此外,如何构建一条安全可靠、能够自动化实现从开发环境到生产环境的无缝发布验证,涵盖源码版本控制整合以及 CI/CD 自动化回滚策略在内的工作流,也是企业在试图长期维持 Flink 平台级稳定和规模化扩张时必须跨越的险峻鸿沟 。






