

 12
12 0
0
1. 引言:量化坟墓里的警示录
在曼哈顿下城或伦敦金融城的顶级对冲基金办公室里,研究员的屏幕上常会出现一种令人生畏的“幻象”:那是一个回测曲线近乎完美斜向上、夏普比率(Sharpe Ratio)高达4.5的统计套利模型。然而,当这类模型在实盘中与真实的撮合引擎碰撞时,往往会在前三个月内迅速崩盘。这种从“纸面富贵”到“实盘灾难”的转变,被资深从业者戏称为“量化坟墓里的入场券”。
为什么传统的线性资产定价模型在现代高频且碎片化的市场中如此脆弱?核心矛盾在于:教科书式的“有效市场假说”忽略了市场的粘滞性(Viscosity)。当下的全球金融市场已不再是一个由理性的基本面驱动的简单系统,而是一个由无数高度进化的算法主体构成的复杂自适应系统。在这个系统中,被动指数基金调仓带来的非弹性需求冲击、监管规则漏洞下的微观套利、以及不同执行场所(Venues)之间微秒级的结构性摩擦,才是利润的真正发源地。
“现代量化研究的根本任务,是制定能够系统性提取特异性 Alpha 的动态组合策略,同时通过数学手段严密优化并管理对‘增长贝塔’(Growth Beta)等特定系统性风险因子的暴露。” —— 摘自源码
对于顶尖量化机构而言,市场并非“有效”或“无效”的二元对立,而是一个充满非平稳性(Non-stationarity)的、由非线性摩擦力牵引的物理过程。本文将跨越数学模型、微观结构、执行算法以及最前沿的深度学习架构,深度复盘量化“炼金术”的底层逻辑,并揭示那些隐藏在毫秒级博弈背后的生存法则。
2. 核心突破一:Alpha 的精确手术刀——如何从“增长贝塔”中提取纯净超额收益
在现代量化组合构建的公理体系中,首要任务是对收益流进行如同外科手术般的精确分解。机构必须确保其专有信号(Proprietary Signals)不被未受补偿的系统性风险所污染。
2.1 因子分解与期望收益的数学重构
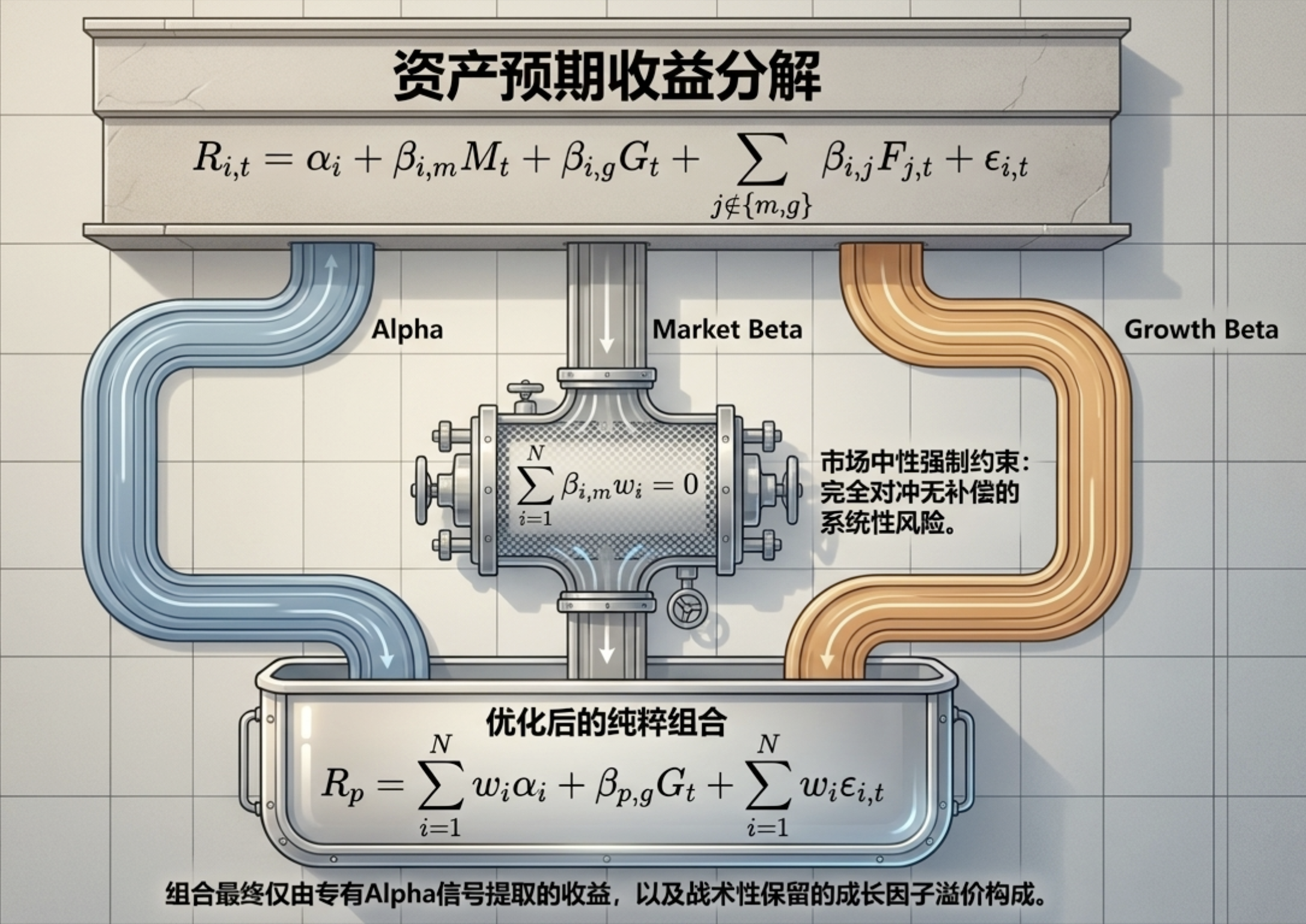
在多因子框架下,资产的收益率不再被视为单一的波动,而是多种驱动力的线性或非线性叠加。为了孤立最纯净的 Alpha 信号,我们将资产 i 在时间 t 的期望收益 R_{i,t} 建模为:
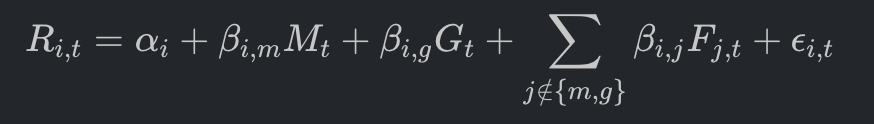
在此模型中:
αi:这是量化员追求的“圣杯”,即与任何已知系统性因子均不相关的特异性超额收益。
βi,mMt:代表资产对广义市场贝塔的敏感度。
βi,gGt:代表对**增长因子溢价(Growth Beta)**的暴露。实证表明,该因子在过去十年中与美国科技股、动量特征及卖方盈利预测的修订表现出极强的正相关性。
顶尖机构的差异化竞争点在于:他们不再单纯追求“绝对市场中性”,而是有目的地保留一部分 Growth Beta,因为这种因子在特定宏观周期下具有极高的收益持久性。
2.2 市场中性的数学实现与动态组合构建
为了获得所谓的“纯净收益流”,组合经理会通过求解一组约束方程,构建一个权重序列 w_i,使得组合对广义市场风险的暴露(Market Beta)精确归零:
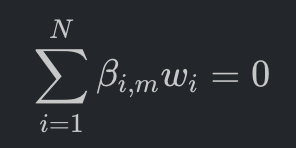
在实现该约束后,组合的期望收益 R_p 转化为:
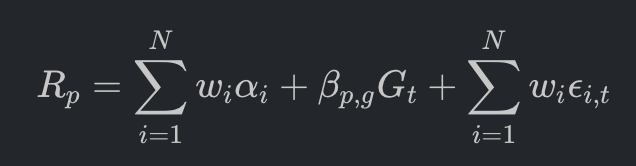
这意味着,当市场大盘剧烈波动时,该组合的净值应表现得如同波澜不惊的湖面,其动能完全来自于 Alpha 信号的捕获和对增长因子的战术性倾斜。
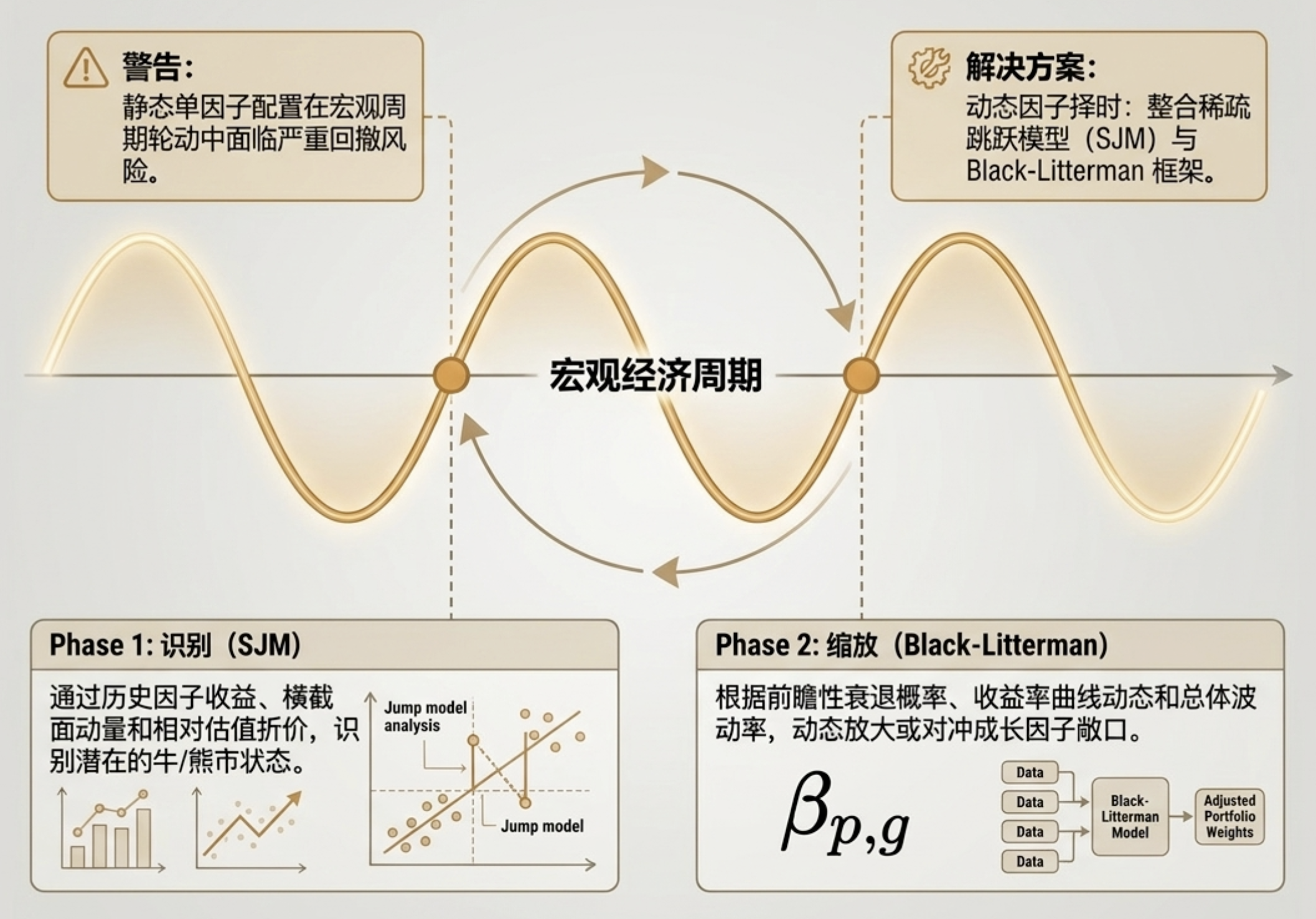
2.3 动态因子择时:Sparse Jump Models (SJM) 与 Black-Litterman 框架
因子溢价并非永恒,它们在不同的宏观状态(Regimes)下呈现出显著的周期性波动。静态的因子配置往往会遭遇“回撤陷阱”。
“实证研究表明,由于行为偏见(如处置效应、锚定效应)与结构性刚性的结合,市场低效性得以长期存在。然而,这种低效性的表现形式会随宏观环境动态切换。” —— 摘自源码
为了应对这种非平稳性,前沿机构引入了稀疏跳转模型(Sparse Jump Models, SJM)。SJM 通过评估因子的历史主动收益、横截面动量以及估值折价,识别潜在的牛熊转换节点。结合 Black-Litterman 模型,研究员能够动态调整预期收益向量。例如,当宏观模型预测经济衰退概率上升、收益率曲线趋平时,系统会自动调低 Growth Beta 的暴露权重,转向防御性更强的风格因子。
3. 核心突破二:Reg NMS 与“抢跑”的艺术——揭秘 1/4 美分的微观博弈
在量化交易的物理边界,利润往往隐藏在交易所的底层规则中。理解微观结构不仅是为了降低成本,更是为了将其转化为一种执行策略。
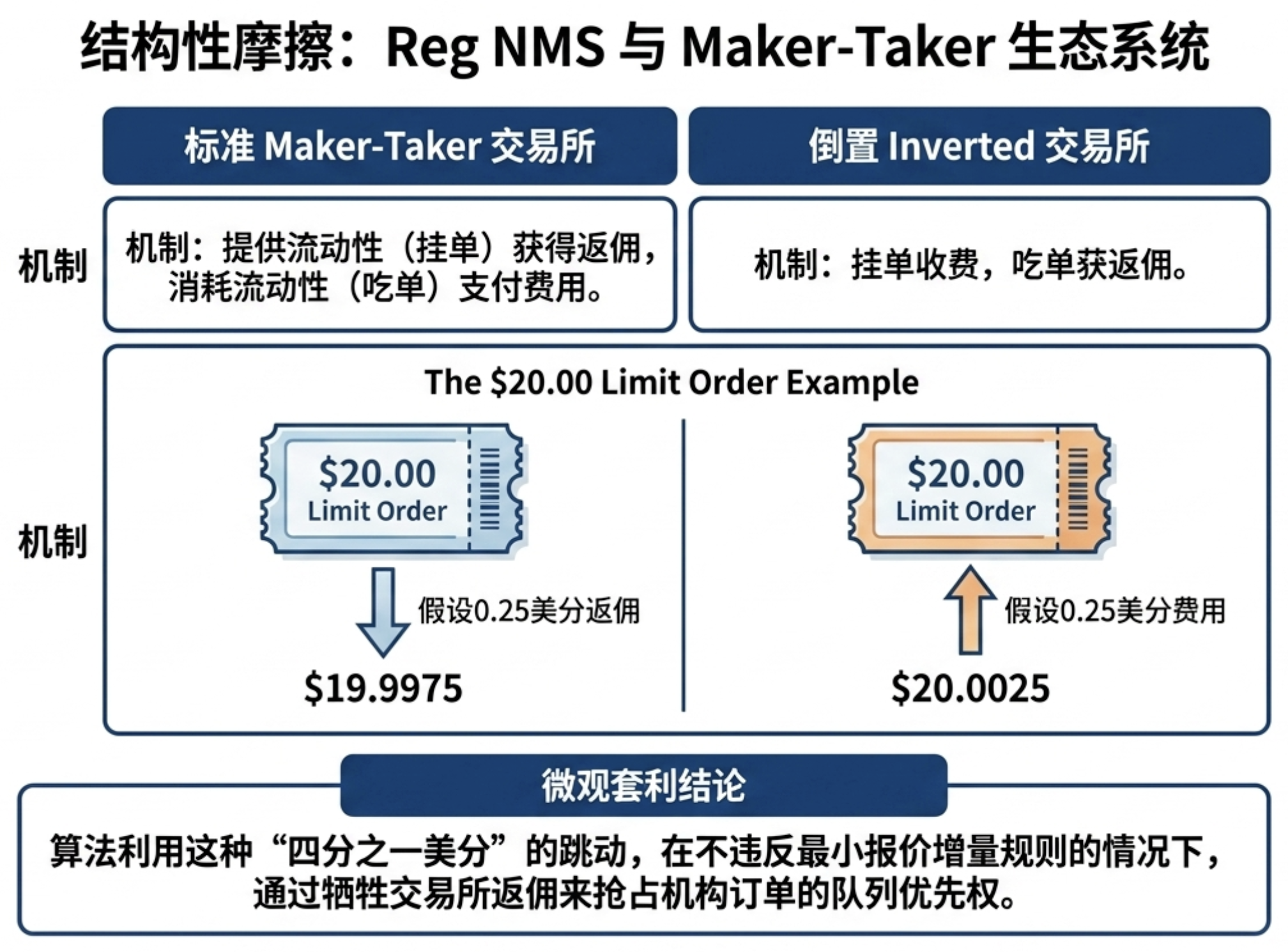
3.1 规则 610 与 Maker-Taker 经济学
美国股票市场受 Regulation NMS(国家市场系统规则)管辖。其中 Rule 610(接入规则) 规定,交易所对每百股的执行接入费不得超过 30 美分。这一红线直接催生了复杂的 Maker-Taker 定价模型。
在这种博弈中,交易所为了争夺订单流,会给予提供流动性的“挂单者”(Maker)财务回扣,而向消耗流动性的“吃单者”(Taker)收取费用。然而,更有趣的现象发生在“反转场馆”(Inverted Venues)中——这里是 Taker-Maker 逻辑:吃单者拿回扣,挂单者交费。
3.2 代理人问题与微观套利的物理实现
这种定价差异导致了严重的“代理人问题”(Agency Problems)。经纪商可能为了赚取回扣,将客户订单路由到成交质量较差的场馆。
“老练的量化路由算法利用这种‘四分之一美分’的价格动态,在不违反最小价格增量规则的前提下,通过支付交易所回扣成本来换取队列优先级(Queue Priority)。” —— 摘自源码
想象一个场景:在标准场馆,由于回扣的存在,队列极长,你的单子可能永远无法成交。此时,算法会选择支付一定的“过路费”进入反转场馆。虽然成本略高,但你获得了队列的绝对优先级,能够在机构大单冲击市场之前的微秒内完成执行。
3.3 衍生品市场的阶梯式收费挑战
在期权和期货市场,成本结构更加错综复杂。例如,CBOE 针对 SPXW 合并了一套基于交易量的阶梯费用。如果量化系统无法实时计算当月的累计成交量,其回测中看到的利润可能只是因为未剔除昂贵的阶梯溢价。
Table 1: Cboe SPXW 复杂策略 Maker-Taker 阶梯表 (2026 估算)
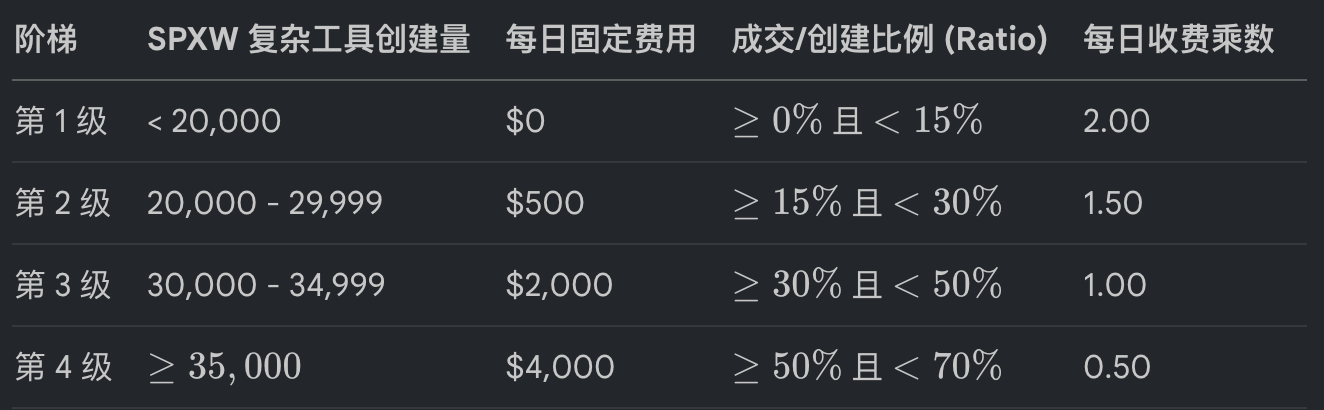
类似地,Nasdaq 衍生品市场对客户的回扣也具有高度的非线性。
Table 2: Nasdaq 期权客户回扣阶梯 (2026 估算)
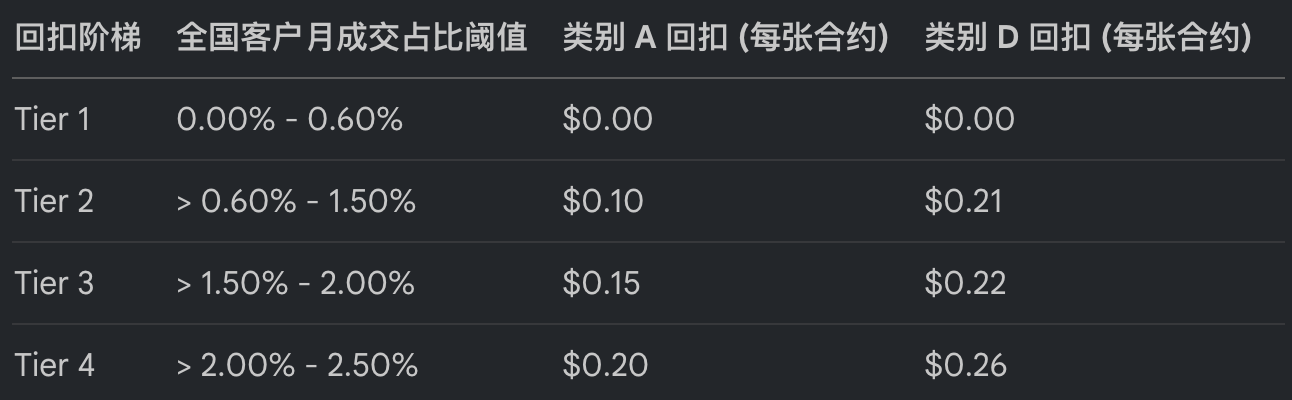
算法系统必须利用高性能的向量化计算(如 Numpy/Pandas 优化逻辑)在毫秒内动态更新这些阈值,确保每一笔微观套利在考虑了复杂的清理成本后依然是正期望的。
4. 核心突破三:被误解的摩擦成本——从“平方根模型”到“3/5 幂律”
很多量化研究员在解释滑点(Slippage)时仍停留在十年前的认知。传统的 Almgren-Chriss (AC) 框架认为市场冲击与交易速度的平方根成正比,但在实战中,这种假设会导致对大额单执行成本的严重低估。
4.1 AC 框架下的价格动力学
在 AC 模型中,观测到的执行价格 S_t 被分解为:
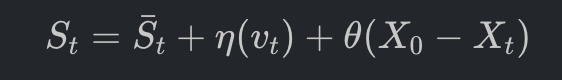
Sˉt:遵循无漂移布朗运动的基础价格 (dSˉt=σdWt)。
η(vt):临时市场冲击。这是由于交易速率 vt 超过了限价簿补充速度而产生的瞬时成本。
θ(X0−Xt):永久市场冲击。由于你的交易行为泄露了信息,导致市场对均衡价格的认知发生了永久位移。
4.2 3/5 幂律:微观结构的物理约束
基于花旗集团(Citigroup)海量机构订单流数据的最新实证分析显示,临时冲击 η(vt) \eta(v_t) 并非遵循平方根律,而是在极广的规模范围内遵循 3/5 幂律。
“由于隐藏机构订单的重尾分布以及订单流的不对称可预测性,临时市场冲击在极广的订单规模范围内遵循 3/5 幂律。忽略这一非线性约束,是量化策略走向毁灭的‘原罪’。” —— 摘自源码
在训练强化学习(RL)交易代理时,如果不在超参数优化(HPO)阶段强制执行 3/5 幂律成本函数,代理程序会表现出一种“自杀式”的乐观:它会为了微小的账面利润而疯狂消耗流动性,最终在实盘交易中因滑点过大而导致策略破产。这种现象揭示了市场的一个深层本质:流动性并非均匀分布,它具有某种类似于物理学中非牛顿流体的性质——你推得越快,它的阻力就呈非线性增加。
5. 核心突破四:深度学习重塑限价订单簿(LOB)——DeepLOB 与万有引力
现代微观 Alpha 的提取已全面转向基于深度卷积网络对 LOB 的实时解析。
5.1 订单流不平衡 (OFI) 的精细建模
OFI 是衡量高频价格压力的核心指标。它不仅关注成交,更关注未成交的挂单变化。对于时间步 t,其公式为:
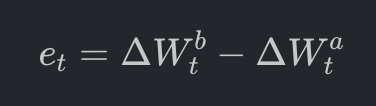
买盘压力 ΔWtb 的逻辑必须严密区分以下三种物理状态:
价格上升:Ptb>Pt−1b,此时买盘压力即为当前的最优买单量 Qtb(建立了新的价格防线)。
价格持平:Ptb=Pt−1b,压力为挂单量的增量 Qtb−Qt−1b。
价格下跌:Ptb<Pt−1b,压力为负的上一时刻挂单量 −Qt−1b(防线崩溃)。
5.2 DeepLOB 模型:从卷积到可迁移性
为了处理高达 40 维(买卖各 10 档的价格与量)的复杂张量,机构部署了 DeepLOB 架构。该模型融合了卷积神经网络(CNN)提取空间深度特征、Inception 模块捕捉多尺度波动、以及 LSTM 处理时间序列的长期依赖。
其输入张量维度通常定义为: N×100×40×1 即 100 个历史事件回溯期下的 40 个 LOB 特征。
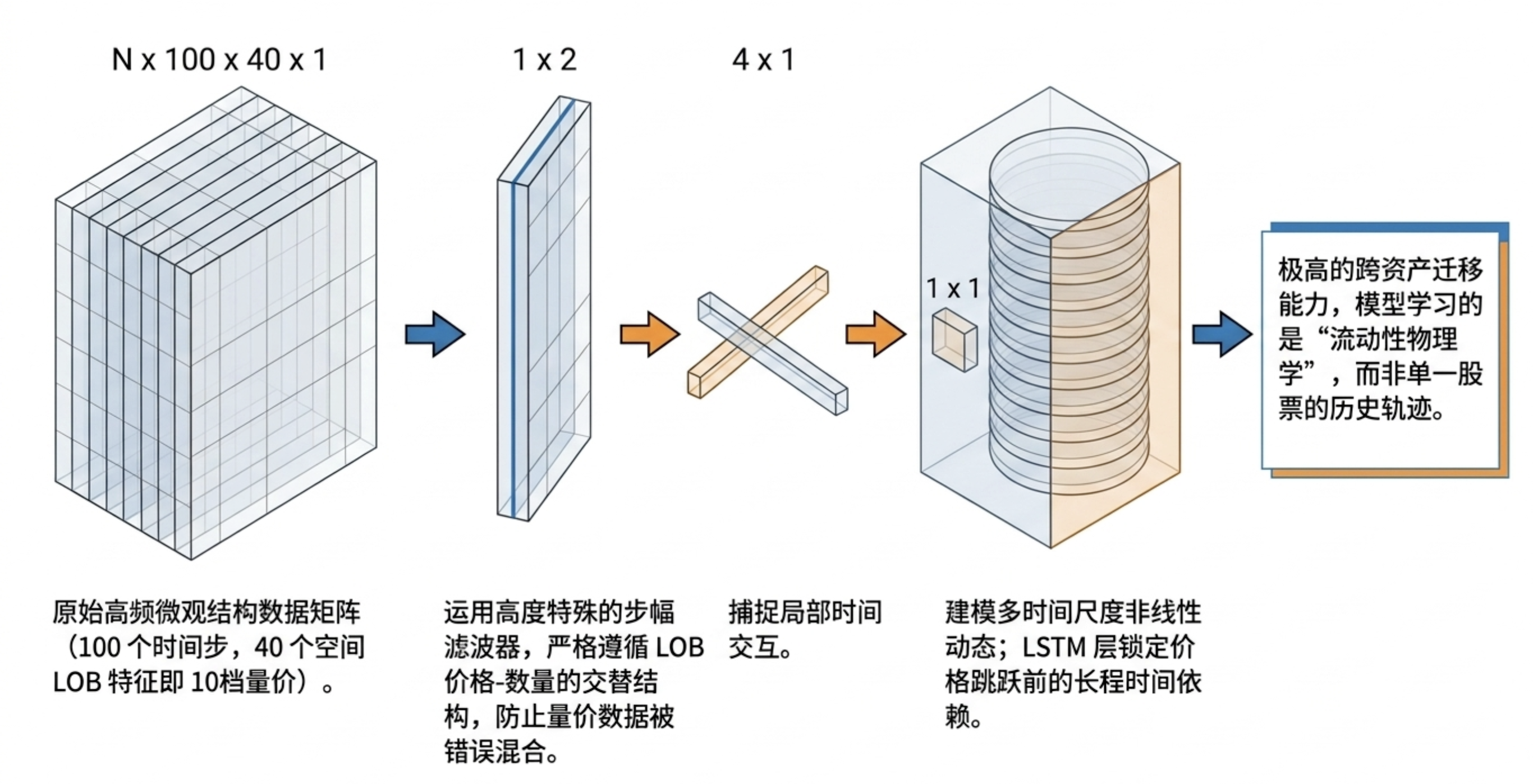
“在伦敦证券交易所(LSE)数据集上的测试证明,DeepLOB 具有极高的‘可迁移性’。它能预测从未见过的股票,这意味着深度学习已经捕捉到了流动性的通用物理规律。” —— 摘自源码
5.3 从 HFT 到多日:Temporal Fusion Transformers (TFT) 与 GNN
当 Alpha 视野从毫秒拉长至数天,传统的模型便会因忽略复杂的供应链关联而失效。为此,顶级团队引入了 TFT-GNN (图神经网络混合架构)。TFT 通过注意力机制捕捉时间依赖,而 GNN 则负责注入资产间的“关系基因”——如上下游供应链联动、行业相关性以及基本面相似度。这种架构能够精准预测一个局部的流动性冲击如何通过复杂的市场网络进行扩散。
6. 核心突破五:统计套利的现代进化——PCA、指数重组与“展期收益神话”
尽管人工智能气势如虹,但在中低频领域,基于统计套利的均值回归依然是机构利润的压舱石。
6.1 PCA 降维与 Ornstein-Uhlenbeck (OU) 过程
为了寻找不依赖于行业定义的套利对,研究员利用主成分分析(PCA)对资产相关性矩阵进行特征值分解,将收益率投影到主成分上,扣除系统性部分后提取残差序列 X_t。
这个代表特异性 Alpha 的残差序列,被建模为一个经典的 OU 过程,其随机微分方程定义为:
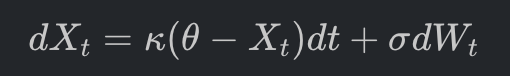
κ:均值回归的速度(Alpha 的半衰期)。
θ:残差的均衡价值水平。
σdWt:市场的噪声扰动。
当偏离值 X_t 超过统计阈值时,算法即刻介入,捕捉那回归均衡点的微弱引力。
6.2 指数重组与 0DTE 的期权锚定
统计套利的另一个肥沃土壤是“非基本面因素带来的非弹性需求”。
指数调仓:大量被动 ETF 在特定日期必须不计成本地完成调仓。量化算法通过建模这些被动载体的执行触发阈值,在它们入场前预先建立头寸,从而收割那些因“被迫交易”产生的溢价。
0DTE 期权锚定 (Options Pinning):末日期权的大规模流行使得期权做市商面临剧烈的 Gamma 对冲压力。在到期时刻,这种对冲行为会将底层标的价格强行“钉在”高持仓量的行权价(Strike Price)附近,形成一种可预测的确定性波动压缩。
6.3 戳破“展期收益神话” (Roll Yield Myth)
在商品期货市场,大众文献常将 Contango 结构下的损失描述为“收益”的流失,但这本质上是期限结构导致的负面拖累。
“所谓的展期收益,本质上完全是期限结构效应导致的。被动商品指数必须连续卖近买远,这种可预测的、非理性的滚动行为,为量化算法提供了完美的‘抢跑’机会。” —— 摘自源码
7. 核心突破六:另类数据的“炼金术”——当卫星图像遇到情绪向量
当传统的价量数据被上千台服务器反复碾压后,超额收益的来源便转向了那些计算成本极高、结构极度混乱的另类数据。
Table 3: 机构另类数据分类与 Alpha 效能分析
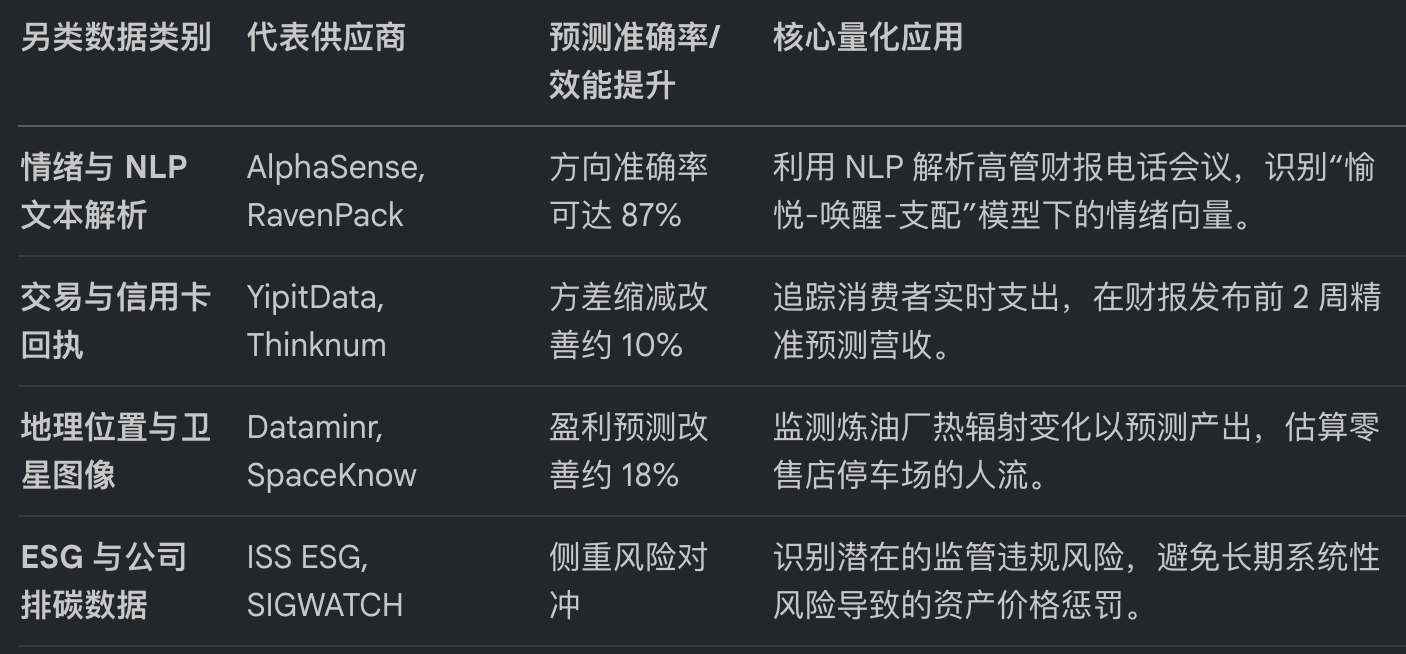
识别潜在的监管违规风险,避免长期系统性风险导致的资产价格惩罚。
在 NLP 领域,最前沿的研究不再关注简单的“利好/利空”词频,而是利用 PAD (Pleasure-Arousal-Dominance) 心理模型。该模型能够捕捉到高管在回答分析师提问时细微的恐惧或惊喜情绪,并将这些瞬时情绪向量化,与高频 LOB 的失衡度进行对齐,从而构建出极具攻击性的微观信号。
8. 终极防御:对抗过拟合的“黄金标准”——CPCV 与组合净化
这是量化炼金术中最关键的“防火墙”。任何未通过严格净化协议的模型,在量化先锋看来都只是昂贵的随机数生成器。
8.1 为什么 K-Fold 验证是“回测自杀行为”?
传统机器学习中的 K-Fold 交叉验证假设样本是独立同分布(IID)的。但在金融市场,时间序列具有强烈的序列相关性。如果训练集和测试集在时间上紧密相连,数据泄露(Data Leakage)将使得模型能够“感知”未来的波动,从而产生极高的虚假夏普比率。
8.2 组合净化交叉验证 (CPCV) 的技术细节
为了根除这种“回测的原罪”,机构采用了由 Marcos Lopez de Prado 倡导的 CPCV 协议:
清除 (Purging):从训练集中彻底删除任何与测试集标签存在时间窗口重叠的观察点。
封锁 (Embargoing):由于市场存在延迟反应,研究员会在测试集结束后的数据流中人为设定一个 1% 到 5% 的“缓冲区”,严禁该区域内的数据进入训练阶段,防止模型捕捉到测试集事件的后续动量反馈。
“这种严密的净化协议允许研究员计算出数学上未经污染的‘回测过拟合概率’(PBO)。这是机构部署策略之前的核心准入指标,其地位甚至高于回测收益率本身。” —— 摘自源码
8.3 抛弃标准夏普比率:Deflated Sharpe Ratio (DSR)
为了修正重复测试带来的选择性偏见(Selection Bias),机构要求所有策略必须通过 降维夏普比率 (Deflated Sharpe Ratio) 的校验。DSR 能够计算在进行了 N 次实验后,观察到的最佳夏普比率是否仅仅是由于随机巧合而产生的虚假繁荣。
9. 结论:在非平稳的海洋中寻找锚点
在这个由光缆、算法和海量数据构成的复杂自适应系统中,唯一不变的真相就是“变迁”。当每一个交易所的回扣规则都被算尽,当每一张地球同步卫星拍摄的油罐照片都被卷积神经网络解析完毕,人类量化交易员的终极领地在哪里?
答案深藏于对概率、纪律与数学严谨性的极度虔诚中。正如本文所述,量化炼金术并非寻找某种永恒的致富公式,而是在非平稳的时间序列海洋里,通过对微观物理结构、行为偏见以及制度僵化的深邃理解,捕捉那些转瞬即逝的确定性。
真正的赢家,不是那个拥有最强计算资源的人,而是那个始终对“数据泄露”保持警惕、能够识别出“这笔利润本质上是制度摩擦”的人。在这个算法竞争进入微秒级的时代,唯有那些将执行视为策略、将数学视为信仰的炼金术士,方能在量化坟墓的警示中,找到那枚通往真实利润的钥匙。
