

 4
4 0
0Attention Is All You Need 解读与学习
引言与自然语言处理的范式演进
在自然语言处理(NLP)和序列建模的早期发展历程中,循环神经网络(RNN)、长短期记忆网络(LSTM)以及门控循环单元(GRU)构成了处理序列转导(Sequence Transduction)任务的核心基石 。序列转导的核心目标是将一个可变长度的输入符号序列精确地映射为另一个输出符号序列,这一过程在机器翻译、语音识别和文本摘要等领域具有极高的应用价值 。传统的循环模型以及大多数具有竞争力的神经序列转导系统,均采用复杂的编码器-解码器(Encoder-Decoder)宏观架构 。在这种架构下,编码器负责将输入序列压缩为一个连续的上下文隐状态表示,而解码器则基于该隐状态逐步生成输出序列 。

尽管学术界在后续的研究中通过引入因式分解技巧(Factorization Tricks)和条件计算(Conditional Computation)显著提升了循环模型的计算效率和基础性能,但顺序计算的根本性物理约束依然没有被打破 。为了绕开这一限制并捕捉长距离依赖关系,部分研究者曾尝试引入卷积神经网络(CNN)作为基础构建模块,例如Extended Neural GPU、ByteNet和ConvS2S模型 。这些模型通过局部感受野对所有输入和输出位置的隐藏表示进行并行计算,从而大幅提升了处理速度 。然而,在卷积模型中,关联两个任意相距较远的输入或输出位置所需的计算操作数量会随着位置距离的增加而急剧攀升——在ConvS2S中呈线性增长,而在ByteNet中呈对数增长 。这种距离阻抗使得卷积模型在学习文本中跨度极大的远距离依赖关系时面临巨大的理论与实际挑战 。
在这一技术瓶颈期,注意力机制(Attention Mechanisms)作为一种能够无视输入或输出序列中符号距离而直接建立依赖关系的强大工具,逐渐成为序列建模领域的标准配置 。但值得注意的是,在早期的绝大多数应用场景中,注意力机制仅仅是作为传统循环网络的一个辅助组件被引入,负责在解码阶段连接编码器的输出 。
《Attention Is All You Need》这项由Google Brain和Google Research团队主导的研究,彻底颠覆了上述传统范式 。该研究提出了一种名为Transformer的全新简单网络架构,它以前所未有的魄力完全摒弃了循环网络和卷积网络,仅仅依赖于自注意力(Self-Attention)机制来绘制输入和输出之间的全局依赖关系 。这种从“时间序列单向处理”向“空间全局并行处理”的革命性转变,不仅实现了极其高效的硬件并行化,极大地缩短了训练周期,更在机器翻译任务上确立了难以企及的新基准(State-of-the-Art) 。


核心数学引擎:注意力机制的解构与重塑
注意力函数在本质上可以被抽象地描述为一种信息检索与特征加权的过程:它将一个指定的查询(Query)和一组预设的键值对(Key-Value Pairs)共同映射到一个单一的输出空间,其中查询、键、值以及最终生成的输出无一例外均为实数向量 。最终的输出特征被严格计算为所有值(Values)向量的加权求和,而分配给序列中每个独立值的权重参数,则是通过一个特定的兼容性函数,动态地计算当前查询与其对应的键之间的匹配度而得出的 。

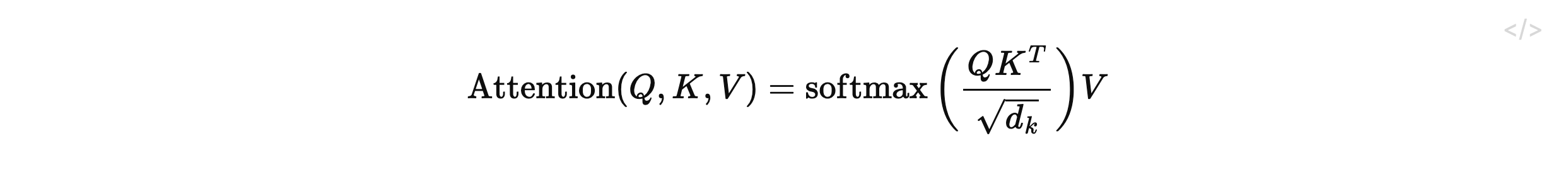



多头机制的语义解析与认知映射: 多头注意力机制为Transformer赋予了在任意位置联合审视和提取来自于不同表示子空间的异构信息的能力 。在自然语言中,同一个词汇往往具有多重语义(例如“She turned on the light”与“The bag was very light”中的“light”含义截然不同) 。单一的注意力机制可能会在加权求和的平均化效应下抵消这些细微差别 。通过开辟多条并行的计算子空间,多头机制允许不同的注意力头分别专注于捕捉不同的语言特征:有的头可能负责追踪长距离的主谓一致性,有的则负责挖掘不同词汇间的情感或指代关联 。
机器翻译中的直觉隐喻:自注意力处理的时空路径
“自注意力”(Self-Attention)是Transformer用于将句子中其他高度关联词汇的语义融入到当前目标词汇表征中的核心手段 。它抛弃了RNN在时间轴上的步进传递模式,转而建立词与词之间的全局放射性连接 。
以一个典型的指代消解场景为例,如句子:“The animal didn't cross the street because it was too tired”(这只动物没有穿过街道,因为它太累了) 。在处理代词“it”时,模型需要精准判定它指代的是“the animal”还是“the street”。在Transformer编码器中,当计算聚焦于“it”时,查询(Query)向量会与上下文中所有单词的键(Key)向量进行匹配打分 。训练良好的模型会赋予“The animal”极高的相关性得分,随后按比例提取该词的值(Value)向量,并将其核心语义特征毫无保留地叠加到“it”的最终输出表征中,从而使模型“理解”了代词的真实指代 。
编码器与解码器的深层拓扑结构剖析
编码器塔楼的设计美学(Encoder Stack)
编码器系统由 N=6 个具有相同拓扑结构的抽象层垂直堆叠组合而成 。每一个孤立的编码层中封装了两个核心子层:
多头自注意力机制阵列:所有的键、值以及查询向量均来源于编码器前一层的输出张量。这使得编码器内的每一个位置都能纵览全局,提取前置序列中所有位置的信息 。
逐位置的前馈神经网络(Position-wise Feed-Forward Network):这是一个带有非线性激活函数(ReLU)的全连接网络,独立且无差别地应用于序列的每一个离散位置上 。

解码器结构的特殊进化与自回归掩码机制
解码器同样由 N=6 个层堆叠而成,但其内部结构更为繁复 。除了自注意力层和前馈网络层外,解码器插入了第三个子层:编码器-解码器跨注意力层(Encoder-Decoder Attention Layer) 。 在这个层中,查询(Queries)来自解码器前一层的输出,而键(Keys)和值(Values)则全部继承自左侧编码器堆叠的最终输出 。这允许解码器在生成每一个目标符号时,都能全局性地向后“凝视”源输入序列中的相关信息 。
屏蔽机制(Masking)的强制介入: 解码器必须维持自回归的单向不可逆属性,即在预测位置 i 的词汇时,绝对不能利用位置 i 之后的“未来”数据 。为了阻绝非法信息渗透,Transformer在解码器的自注意力内部实施了严密的掩码机制(Masking) 。在计算Softmax之前,掩码机制会将所有对应于非法未来连接位置的输入得分强制覆写为一个趋近于负无穷的极小值 。这样,在Softmax激活后,这些未来位置的概率权重将被彻底清零,确保预测推算只能基于已知历史输出进行 。
序列顺序的守恒法则:位置编码(Positional Encoding)
由于Transformer彻底剥离了RNN的序列传递逻辑和CNN的局部空间感知,纯粹的注意力机制本身是不具备位置感知能力的(即具有排列不变性) 。为了让模型理解词序,必须将关于词元位置的显式坐标信息人为地注入模型 。研究人员选择在输入嵌入层之上,通过向量加法融合“位置编码” 。
Transformer采用了基于正弦和余弦周期函数的解析编码方案,公式如下:
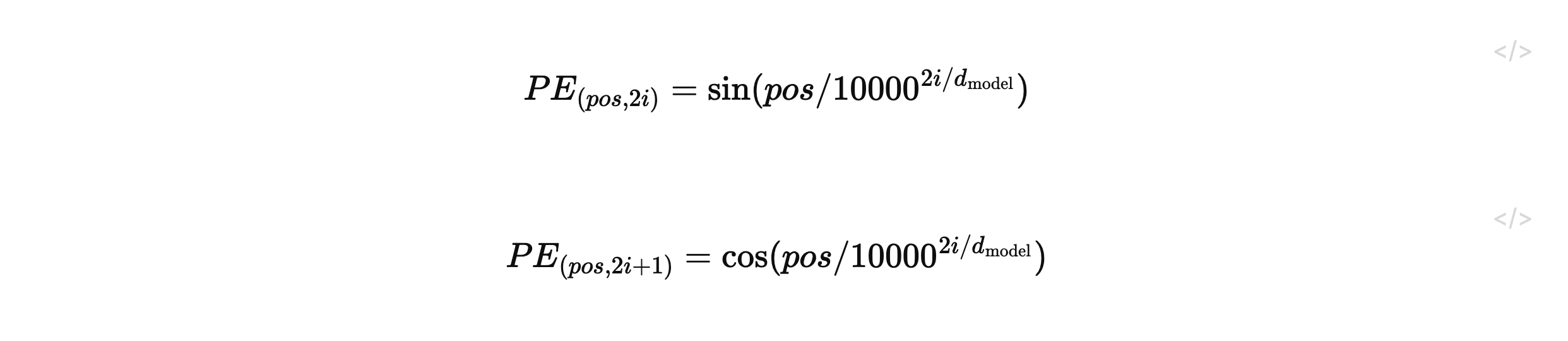

自注意力的理论优势与计算复杂度分析
在理论对比层面,研究团队详细分析了自注意力机制相比于循环网络(RNN)和卷积网络(CNN)的三大核心优势 :

此外,自注意力机制还带来了一个极具价值的副产物——可解释性(Interpretability)。通过可视化注意力分布矩阵,研究人员可以清晰地观察到各个注意力头在处理信息时的分工:有些头精准地捕捉了句法结构,有些头则完美映射了词汇间的语义关联和指代关系 。
极限规模下的模型工程训练与正则化策略
为了在真实工业级场景中验证Transformer的效能,研究团队构建了极其庞大的训练流水线,并在海量数据上进行了严苛的压力测试 。
训练数据与批处理: 模型训练基于业界公认的大规模数据集。对于英语-德语翻译任务,系统使用了包含约450万个句子对的 WMT 2014 英德数据集;对于英语-法语任务,则采用了规模更庞大的包含3600万个句子的 WMT 2014 英法数据集 。在批处理策略上,句子对根据近似序列长度被动态打包,每个训练批次(Batch)包含约25,000个源词元和25,000个目标词元 。
硬件算力与训练周期: 研究团队动用了包含8张 NVIDIA P100 GPU 的计算集群 。即便在如此强悍的硬件支撑下,基础模型(Base Model)仍需训练 100,000 步(耗时约12小时);而参数量更为庞大的大模型(Big Model)则需要训练 300,000 步,耗时达到3.5天 。

