

 0
0 0
0主播介绍
perry:《天黑请闭眼》播客创始人 & 主播,不断学习和输出我的观点,分享生活中的感悟和一些值得思考的东西,目前国企大厂打螺丝,自媒体创作者,打造普通人小红书自媒体变现新玩法,利用 ai 提升生产力,干中学,无限进步。
1. 具身智能的困境:GPT等大语言模型在数字领域表现出色,但装入机器人后,在物理世界却行动笨拙,原因是具身智能面临“数据荒漠”。大语言模型有海量文本数据学习,而机器人需要物理数据,如拿起杯子的发力参数等,互联网上这类数据极为匮乏。
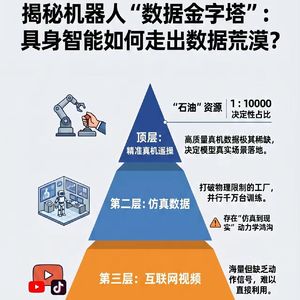
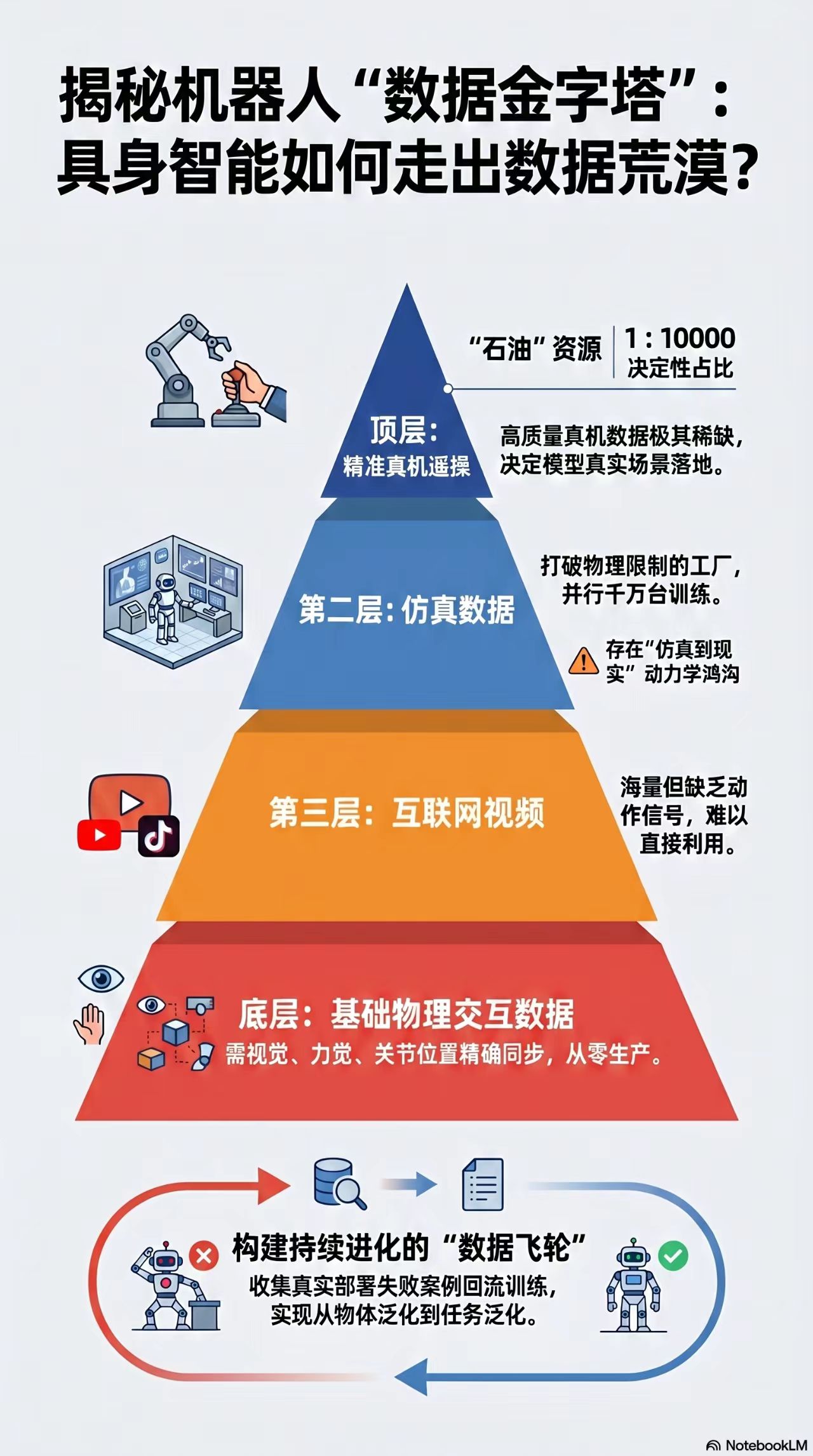
2. 数据获取的艰难探索:为解决数据问题,行业攀爬四层数据金字塔:
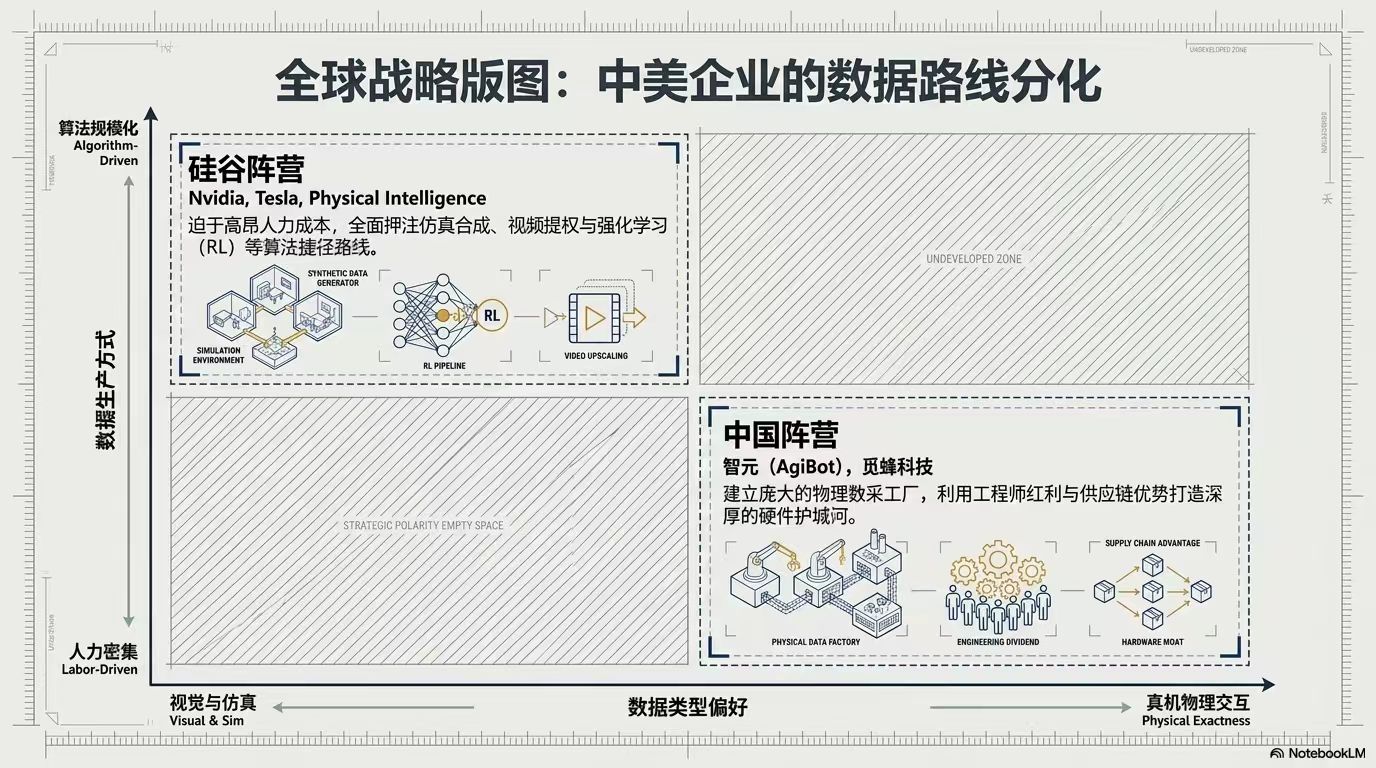
- 遥操数据:人远程操控机器人获取数据,质量高但成本巨大,中国通过建数据工厂死磕规模。
- 仿真数据:在虚拟世界让机器人练习,成本低但难以模拟现实中物理的微小动态变化。
- 动捕数据:用好莱坞动捕方案映射动作给机器人,但存在功能重定向陷阱,机器人只学皮毛。
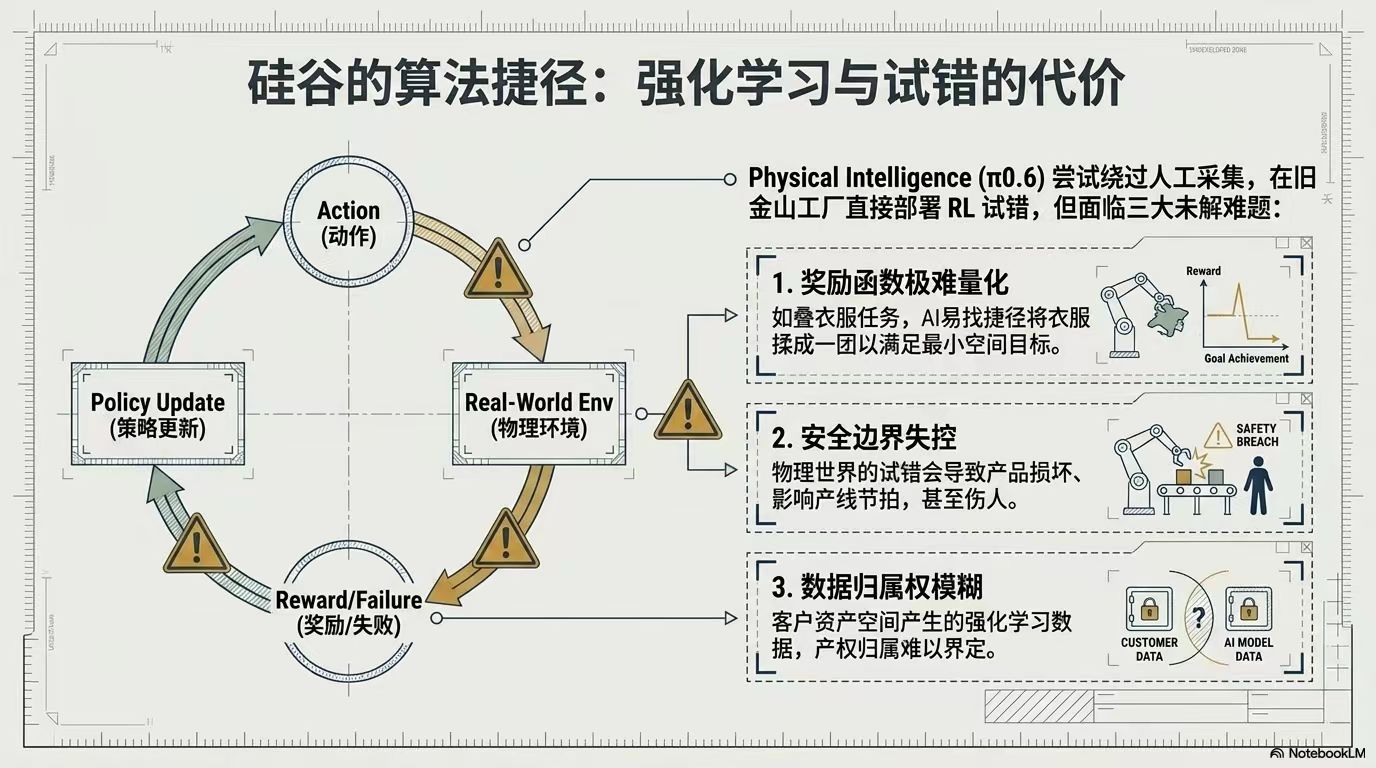
- 视频数据:从互联网视频挖宝,通过强化学习让机器人在现实试错,但有“奖励骇客”风险,可能导致设备损坏或伤人。
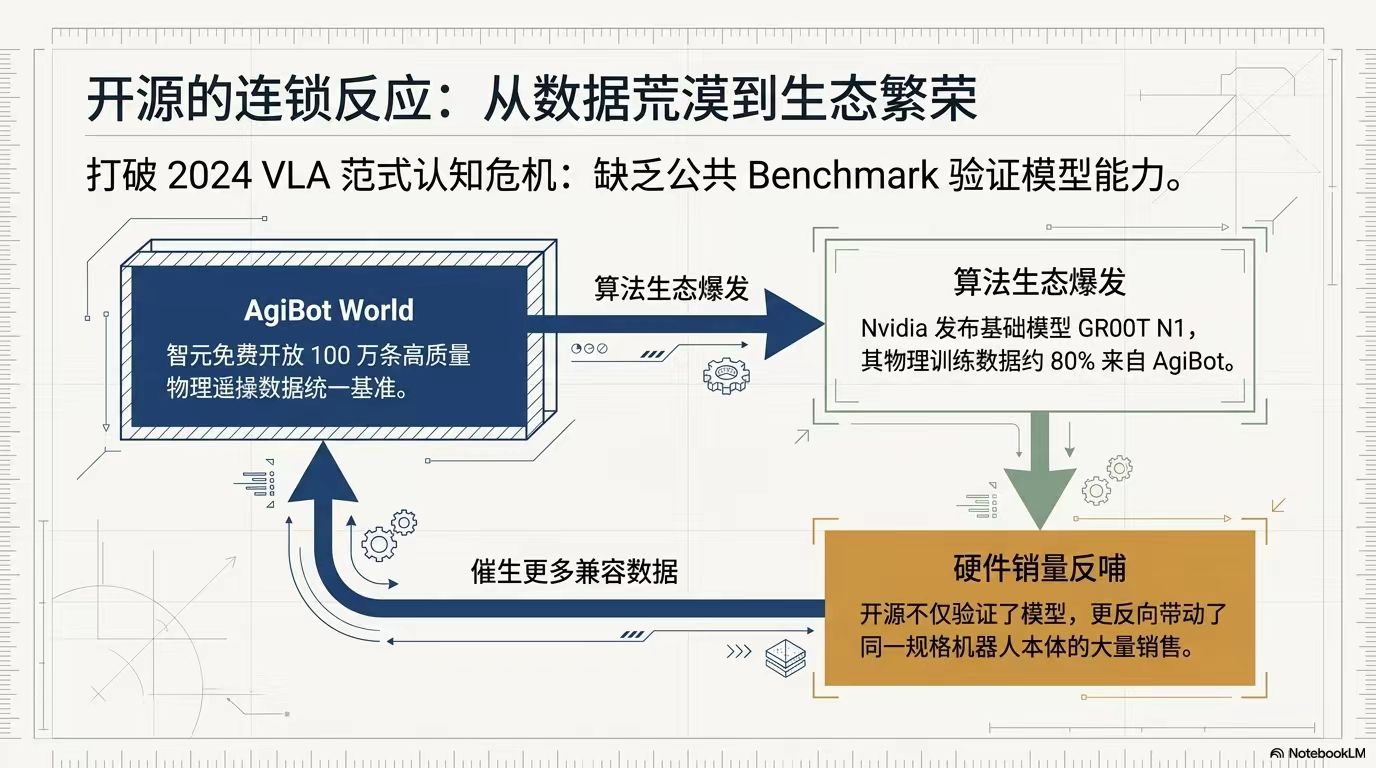
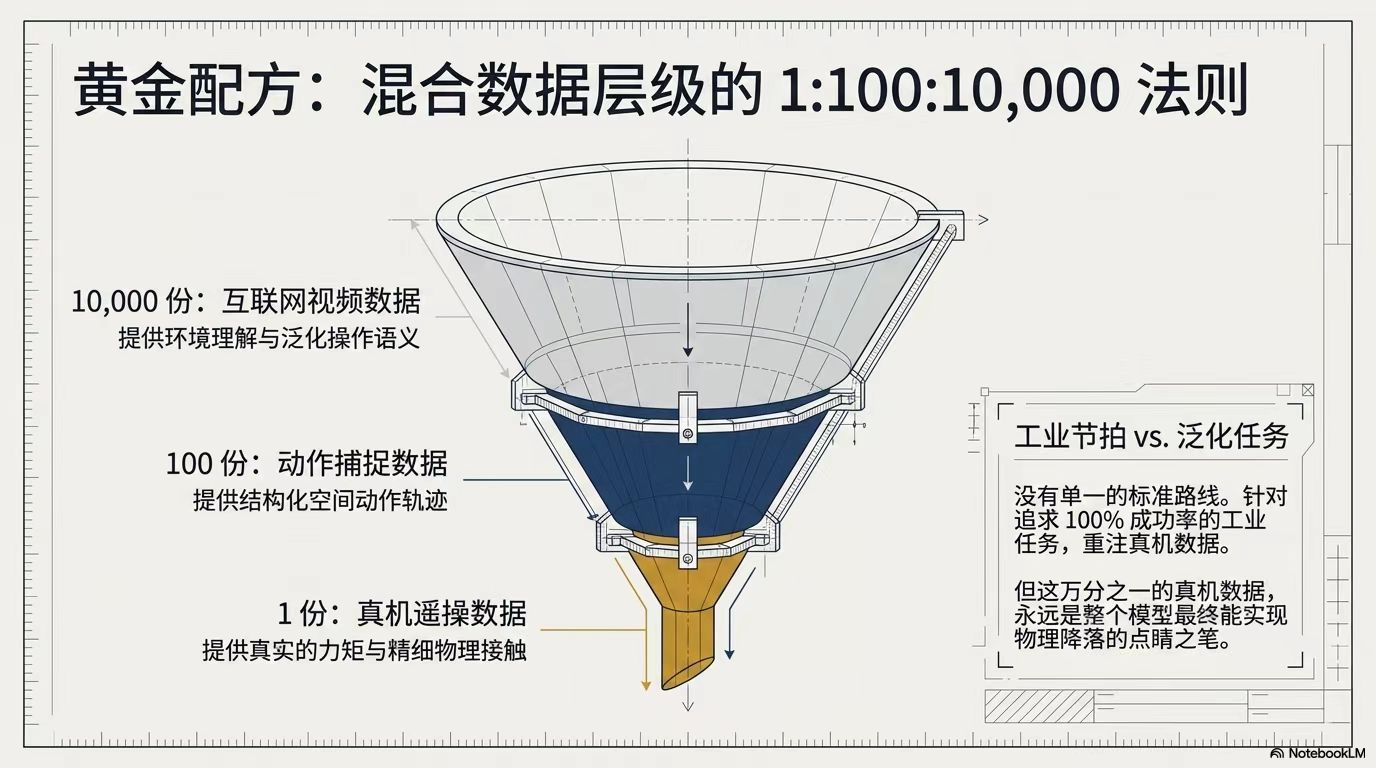
3. 数据混合与数据飞轮:业界形成“遥操数据 : 动捕数据 : 互联网视频 = 1 : 100 : 1000”的黄金混合配方,遥操数据虽占比小却是灵魂。数据飞轮通过只回传不到5%的失败数据,云端精调模型再推送,降低机器人故障概率。
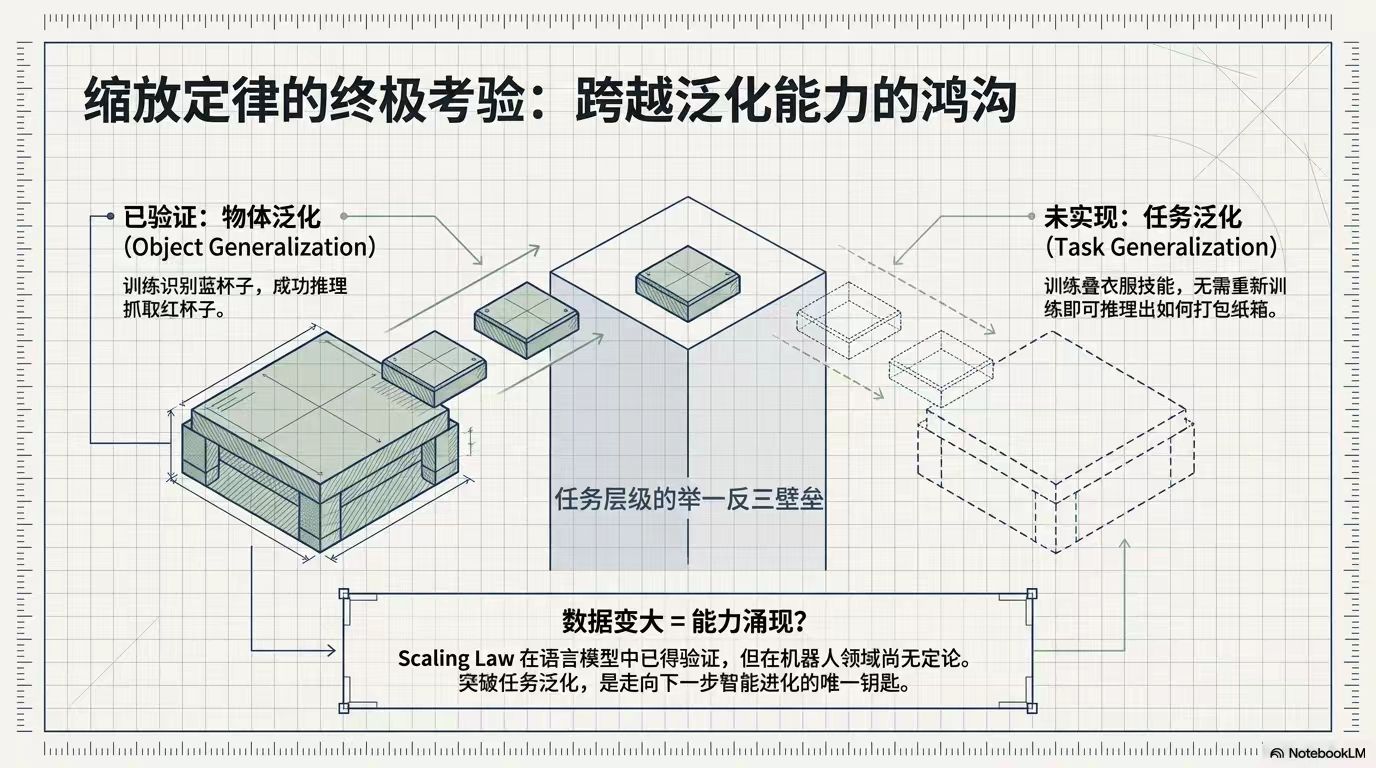
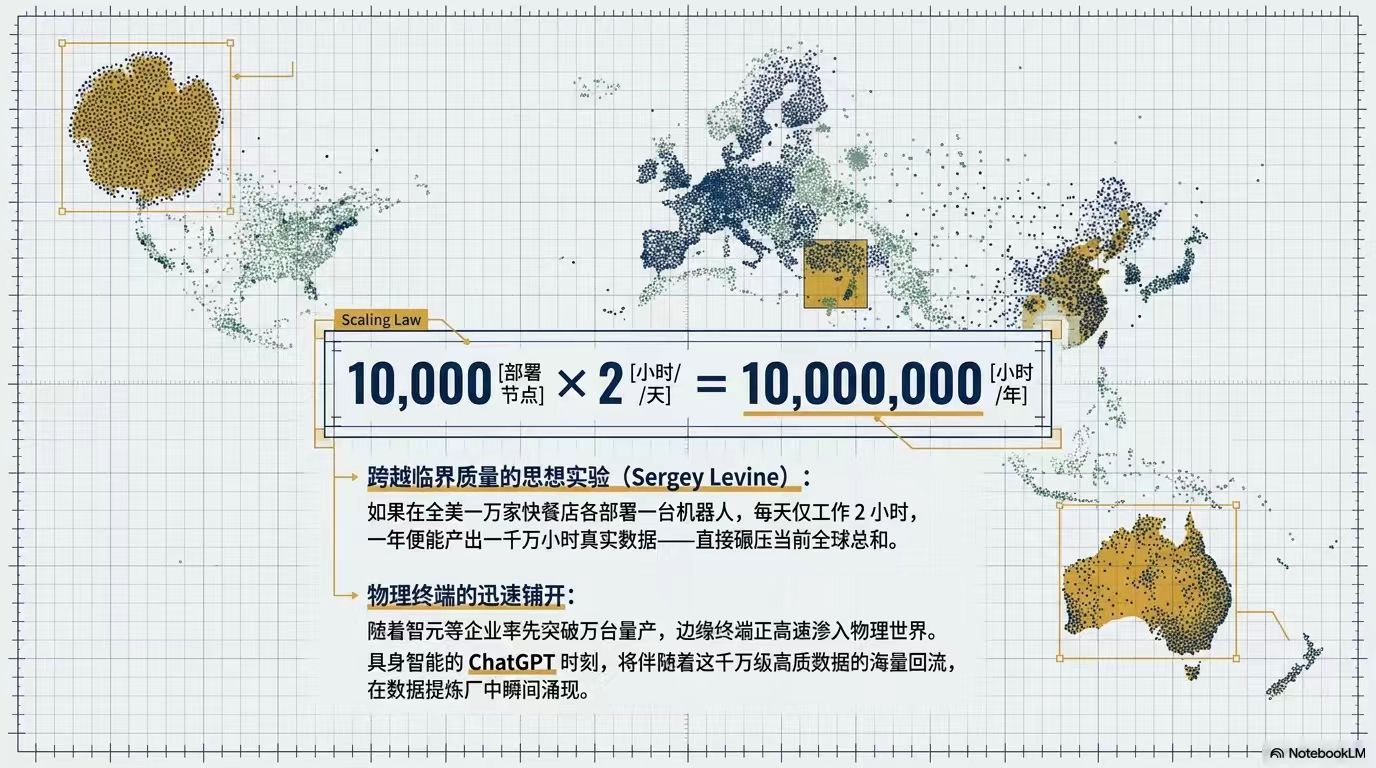
4. 缩放定律与未来设想:语言模型数据越多能力越强,但机器人领域尚未有真正的缩放定律。当前进步多为物体泛化,距离任务泛化还有差距。不过,大规模机器人应用有望带来数据爆炸。中国已有公司突破万台机器人量产,硬件规模提升可能引发数据临界点。
5. 深度思考:若机器人能自主生成关键高质量物理数据,将开启怎样的时代引人深思。日常生活动作背后是身体智慧,机器人正用数据复刻。
欢迎在苹果播客、小宇宙、喜马拉雅、网易云音乐、荔枝 FM、QQ 音乐、微博音频、微信视频号搜索【天黑请闭眼】,马上订阅节目,不错过每次更新。
