6
6 0
0
1. 引言:从算力竞赛到物理极限的“诸神黄昏”
步入 2026 年,全球半导体产业正经历一场前所未有的范式转移。如果说过去三年的 AI 热潮是关于“峰值算力(Peak FLOPS)”的粗放扩张,那么 2026 年则是关于“系统级能效”的物理决战。我们正在目睹一场算力工厂的黎明,其背景是人类对万亿参数前沿模型(Frontier Models)的贪婪需求,与物理世界“功耗墙”和“内存墙”之间不可调和的矛盾。
当前的 AI 负载正呈现出极端的“两极分化”:一端是超大规模预训练,动辄消耗数万张卡连续运行数月;另一端则是追求毫秒级延迟、具备复杂思维链(CoT)的 Agentic AI。传统的 GPGPU 架构在处理这两种截然不同的任务时,逐渐显露出疲态。2026 年,巨头们不再满足于在旧架构上修修补补,而是纷纷开启了底层的架构豪赌。这场被称为“诸神黄昏”的竞争,本质上是试图通过重构物理层级的互联、存储与计算逻辑,在硅片的方寸之间重新定义智能的成本。
2. 谷歌的“算力手术刀”:训练与推理的物理大解耦 (TPU v8)
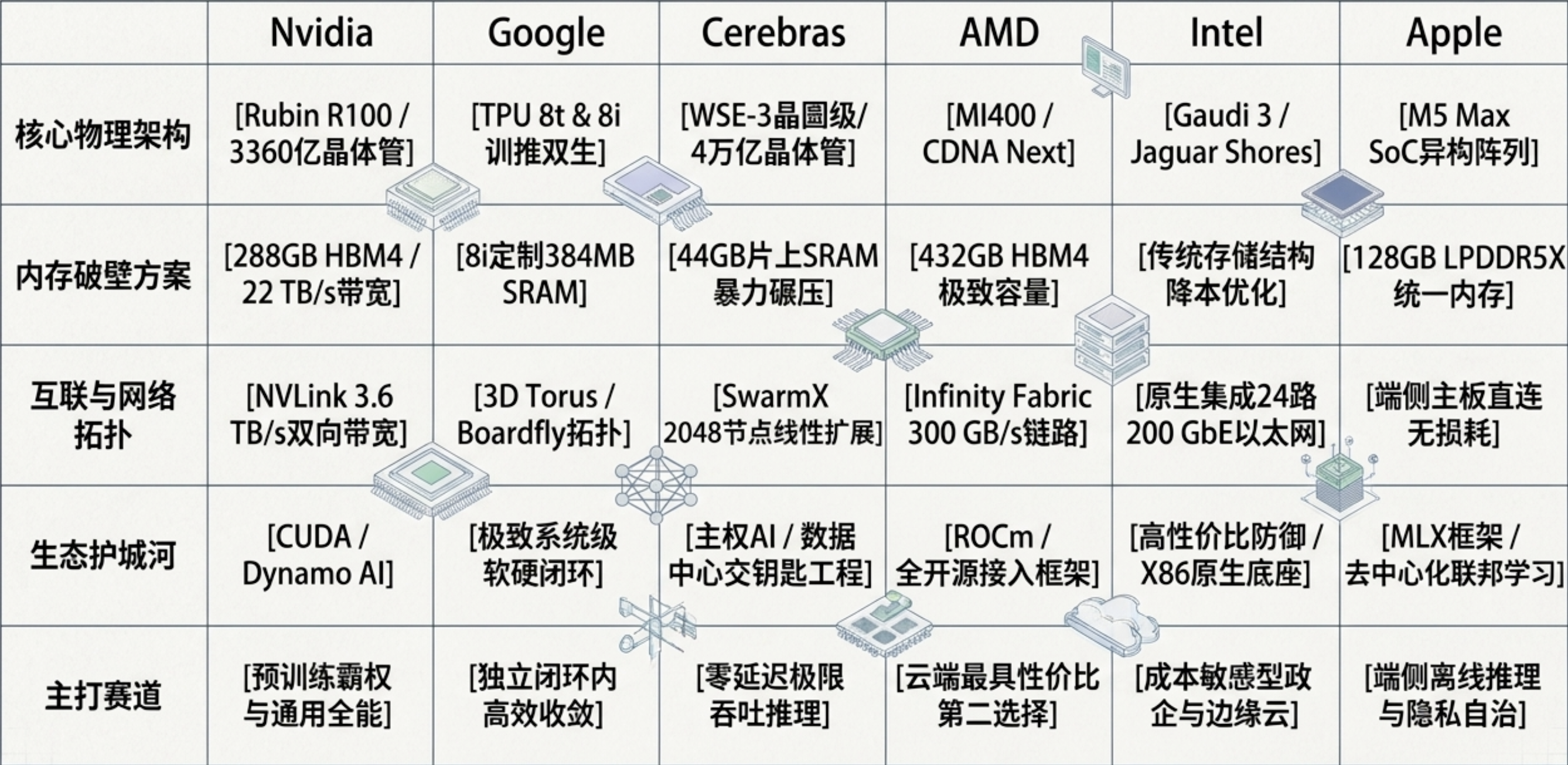
在 2026 年的智算版图中,谷歌(Google)凭借第八代张量处理单元(TPU v8)展现了其极致的系统闭环能力。与 Nvidia 试图用单一架构兼容所有负载的逻辑不同,谷歌首次挥动“算力手术刀”,将 TPU 家族彻底拆分为专属训练的 8t 和专属推理的 8i。这种物理级的解耦,是谷歌对大模型生命周期中“计算密集”与“内存带宽密集”矛盾的终极回应。
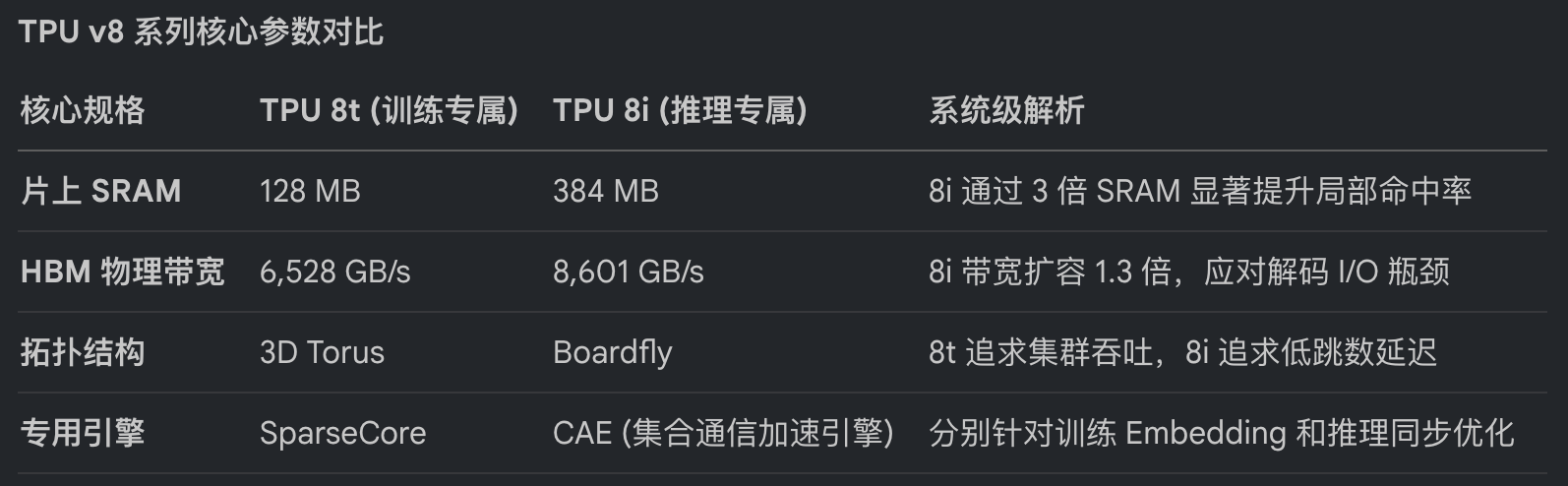
TPU 8i:抹杀延迟的 SRAM 巨兽
谷歌深刻洞察到,Agentic AI 的核心瓶颈在于自回归解码(Decoding)阶段对内存带宽的极度渴求。为此,TPU 8i 将片上高速缓存(SRAM)扩充至惊人的 384MB,这是前代产品的三倍。其核心商业逻辑非常明确:通过巨大的片上空间,让推理阶段庞大的 KV Cache 尽可能完整驻留在芯片内部,从而彻底阻断数据向外部 HBM 搬运产生的微秒级延迟。
这种设计配合名为“集合通信加速引擎(CAE)”的专用模块,成功将推理同步延迟缩减了 5 倍,打破了长期困扰产业的“份额墙(Quota Wall)”。在系统级设计上,谷歌引入了基于 Arm 架构的自研 Axion CPU 处理 Host 端逻辑,实现 2:1 的 TPU 对 CPU 高效配比,确保了系统吞吐上限不受传统 x86 处理器的瓶颈限制。
架构拓扑:3D Torus 与 Boardfly 的博弈
针对不同的任务特征,谷歌设计了截然不同的网络拓扑:
TPU 8t: 采用 3D Torus 结构。这种结构旨在最大化集群吞吐,单个 Pod 能串联 9600 颗芯片,提供 121 ExaFLOPS 的算力,旨在缩短万亿参数模型的收敛周期。
TPU 8i: 转向了 Boardfly 拓扑。这是一种分层全连接结构,通过光路交换机(OCS)将 36 个组链接成 1152 颗芯片的推理 Pod,将网络传输跳数降低了 56%(仅需七跳即可完成任意节点通信)。
TPU v8 系列核心参数对比
3. Nvidia Rubin:硅片堆料的暴力美学与软件护城河的终极演进
尽管谷歌在闭环体系内极其高效,但 Nvidia 依然凭借 Rubin (R100) 架构维持着全球算力标准的霸权。Nvidia 的核心策略是利用极致的物理指标,建立一个让竞争对手难以逾越的“绝对高度”。
暴力美学的物理极限
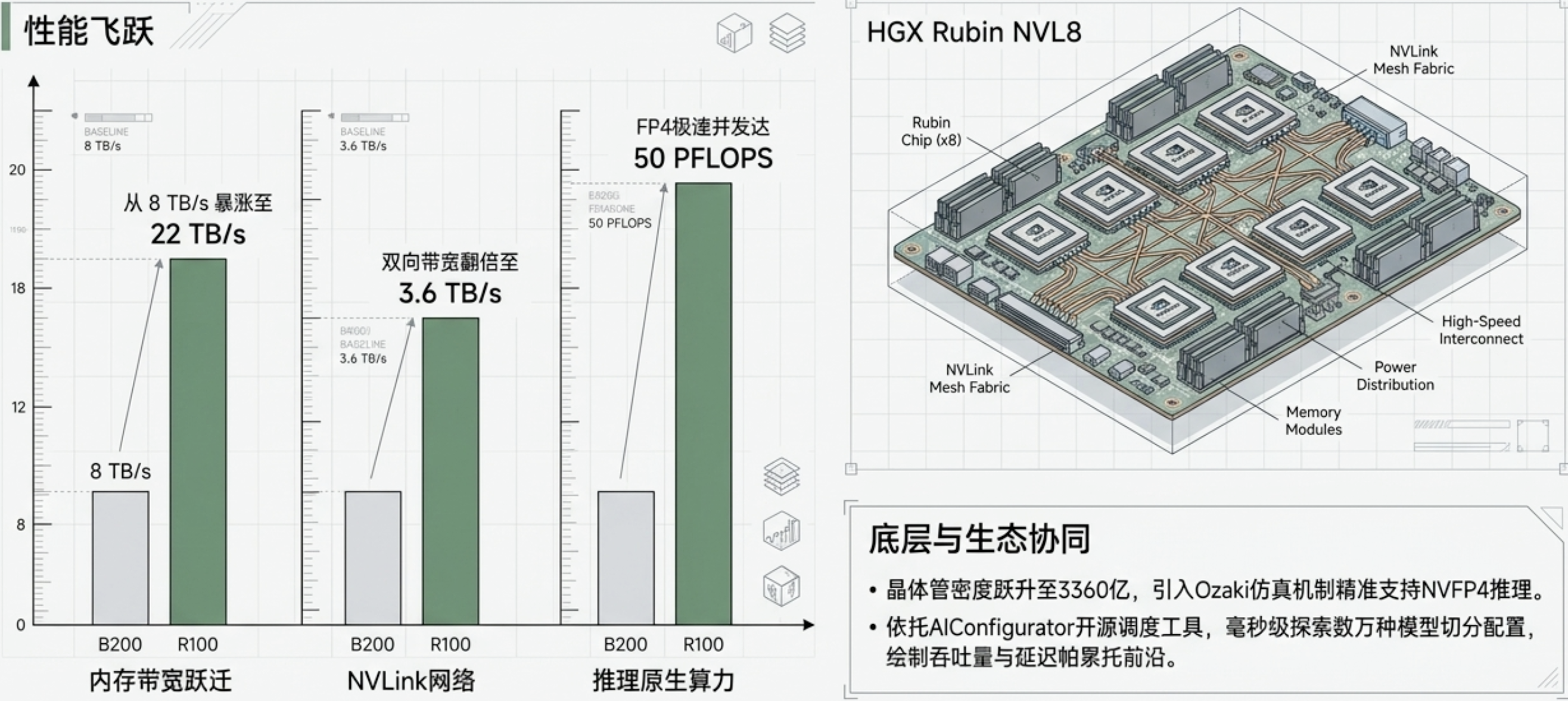
Rubin 架构是硅片堆料的终极体现。其单颗芯片集成了 3360 亿个晶体管,相较于 Blackwell 架构实现了 60% 的巨幅跃升。这种密度增长不仅带来了更多的计算单元,更重要的是提供了更庞大的内部 SRAM。Rubin 引入了 HBM4,虽然单片容量为 288GB,但其内存物理带宽达到了惊人的 22TB/s。更令人震撼的是其 NVLink 双向带宽达到了 3.6TB/s,这使得跨节点张量并行(TP)的通信损耗几乎可以被忽略。
Ozaki 方案:精度的炼金术
在 Rubin 架构中,Nvidia 引入了基于 Ozaki 方案的张量核心仿真机制。这项技术允许硬件在位级别模拟任意精度。在实际应用中,这意味着即便在进行极低精度的 NVFP4 推理时,系统也能通过仿真维持 FP16 级别的数值稳定性。这种“硬件级仿真”让 Nvidia 在低精度量化赛道上爆发出了前所未有的能效比,原生 FP4 推理算力达到了 50 PFLOPS。
软件霸权:从 CUDA 到 AIConfigurator
Nvidia 深刻明白,硬件优势只是暂时的,真正的门槛在于软件。其推出的开源工具 AIConfigurator 能够自动进行帕累托前沿(Pareto frontier)搜索。它能在数秒内模拟数万种配置变量(如批处理策略、硬件并行配置、专家路由倾斜等),确保企业客户能够最快地将硬件算力转化为业务吞吐量。这种“卖最易部署的算力标准”的策略,是其抵御异构架构入侵的终极防线。
4. Cerebras WSE-3:晶圆级巨兽对冯·诺依曼架构的降维打击
当其他厂商还在讨论封装技术时,Cerebras 选择直接使用一整块晶圆。其 WSE-3 处理器拥有 4 万亿个晶体管,是目前人类历史上最大的单体计算引擎,它代表了对冯·诺依曼瓶颈最彻底的物理终结。
物理抹杀“内存墙”
WSE-3 拥有 44GB 的全互联片上 SRAM,内部互联带宽达到恐怖的 214 Pb/s。由于核心间通信仅需一个时钟周期,完全不存在传统 GPU 通过 PCIe 或 NVLink 访问外部 HBM 时的路由损耗。
8B 模型表现: 每秒 1800 个 token。
70B 模型表现: 每秒 450 个 token。
Jais 2 70B 模型: 更是达到了每秒 2000 个 token。
其单并发速度达到了云端 GPU 方案的 20 倍,而成本却极低。
商业版图的侵略性
Cerebras 不再是一家单纯的芯片设计公司。随着其 $70B 的 IPO(股票代码:CS)成功,Cerebras 正在全球范围内布局“主权 AI”。通过 MemoryX(支持 1.5PB 权重存储)和 SwarmX(支持 2048 台节点线性扩展)技术,它为 G42、DARPA、梅奥诊所等机构提供了“交钥匙”式的闭环智算中心。这种跳过 Nvidia 供应链的独立生态,正在主权安全和医疗科研市场构建坚实的堡垒。
5. AMD 的海量显存反击:MI400 成为最强“备选方案”
2026 年,AMD 采取了极其务实的追赶策略:既然无法短期内超越 Nvidia 的软件生态,那就通过“极致堆料”在硬件物理规格上形成错位竞争。
显存容量的绝对碾压
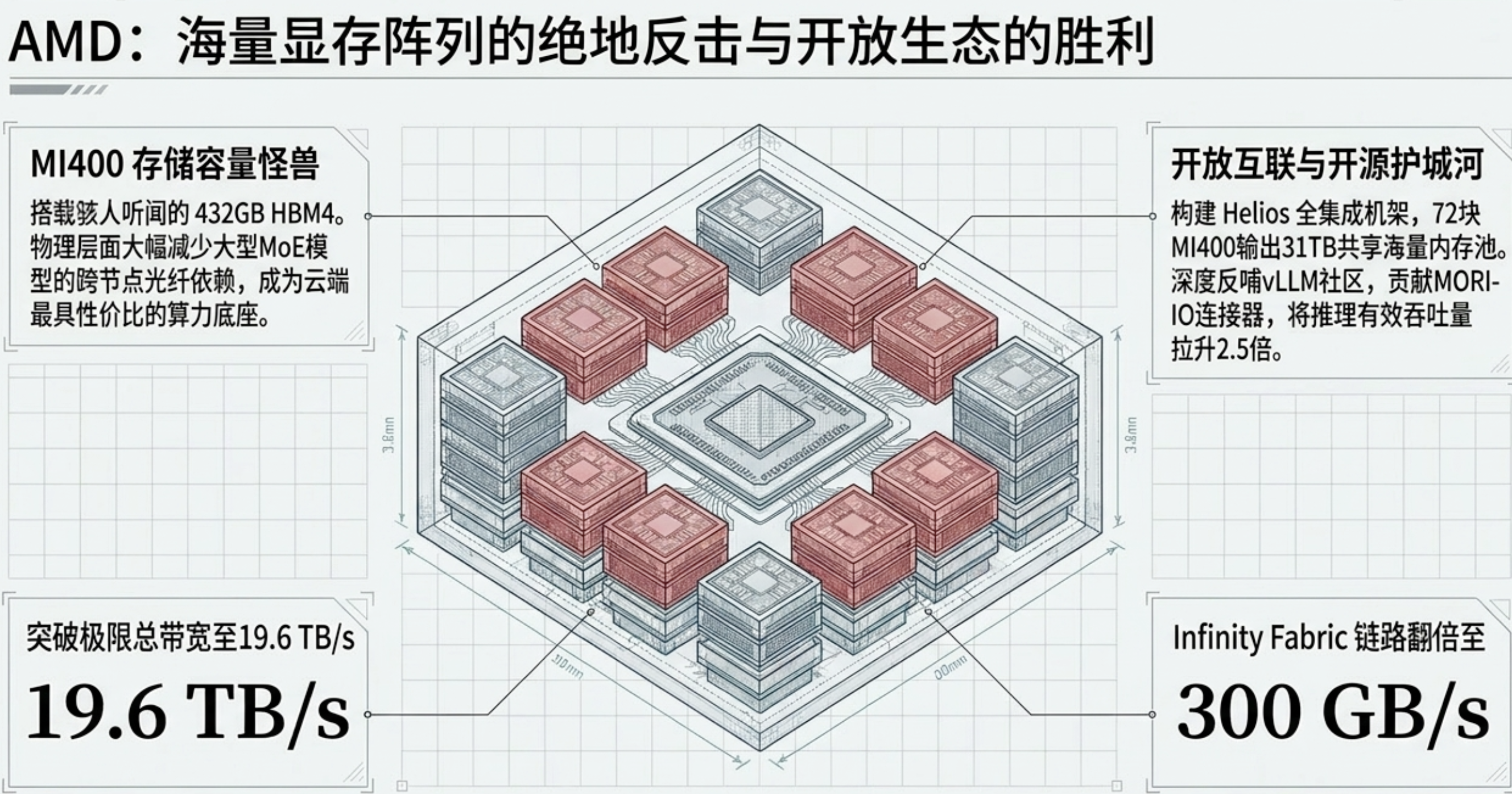
AMD 定于年初部署的 Instinct MI400 系列,最核心的杀手锏是其 432GB HBM4 显存。相比 Nvidia Rubin 的 288GB,AMD 的容量优势高达 50%。在处理万亿参数的混合专家(MoE)模型时,这种海量显存能大幅减少跨节点的张量拆分,从而在物理层面降低了对昂贵光纤网络组件的依赖。其内存带宽也逼近了 19.6TB/s 的极限。
Helios 机架与 Goodput 革命
AMD 不再孤立地卖卡,而是推出了 Helios 机架方案。单个机架包含 72 块 MI400,能够输出 3.1 ExaFLOPS 的算力。为了提升实际应用中的“有效吞吐量(Goodput)”,AMD 贡献了开源的 MORI-IO KV 缓存连接器。在 MI300/400 节点上,该技术通过 Prefill 与 Decoding 的高效分离调度,将系统 Goodput 提升了 2.5 倍。这种以开放互联架构直击推理痛点的做法,确立了其作为智算中心“第二供应源(Second Source)”的领导地位。
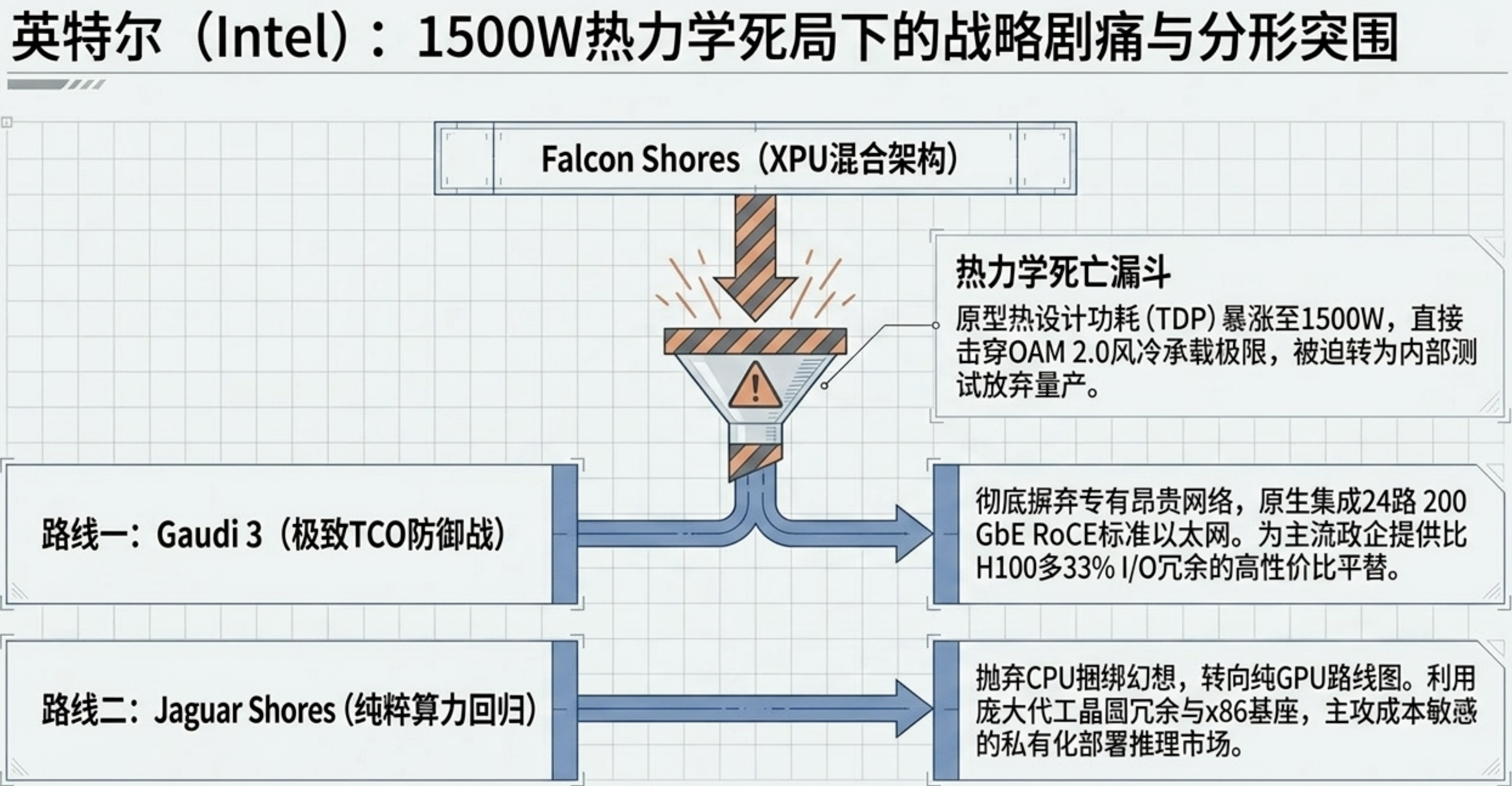
6. Intel 的剧痛与觉醒:从 Falcon Shores 的失败到以太网的防御战
Intel 在 2025-2026 年经历了一场痛苦但必要的战略重构。原本寄予厚望的混合架构芯片 Falcon Shores 因为 TDP 暴涨至 1500W 而被迫取消,这一数值刺破了数据中心 OAM 2.0 规范(1000W)的安全承载极限。
战略大收缩后的突围
Intel 迅速调整了路线图:
Gaudi 3 的以太网防线: Gaudi 3 坚持“原生以太网 (RoCE)”互联,利用 24 路 200 GbE 端口提供极高的性价比。对于不愿支付 InfiniBand 溢价的传统政企客户,它提供了最优的 TCO。
Jaguar Shores 的回归: 彻底抛弃 CPU+GPU 绑定的幻想,Jaguar Shores 是一条纯粹的 GPGPU 路线,基于 Intel 18A/14A 先进制程,旨在通过自有代工的成本优势抢占中端推理市场。
7. Apple M5:端侧智能的“独立王国”与统一内存的胜利
当数据中心在液冷机柜中博弈时,苹果正在端侧构建其“独立王国”。M5 Max 芯片组在 2026 年的发布,将端侧 AI 的护城河挖到了前所未有的深度。
统一内存架构 (UMA) 的统治力
M5 Max 通过 Fusion Architecture 将两颗裸晶粘合,最高支持 128GB LPDDR5X 统一内存,带宽达 614GB/s。这种设计彻底消除了数据在 CPU、GPU 与 NPU 间通过 PCIe 总线搬运产生的性能黑洞。在实测中,M5 基础版的 GPU 推理性能甚至超越了 64 核的 M1 Ultra。
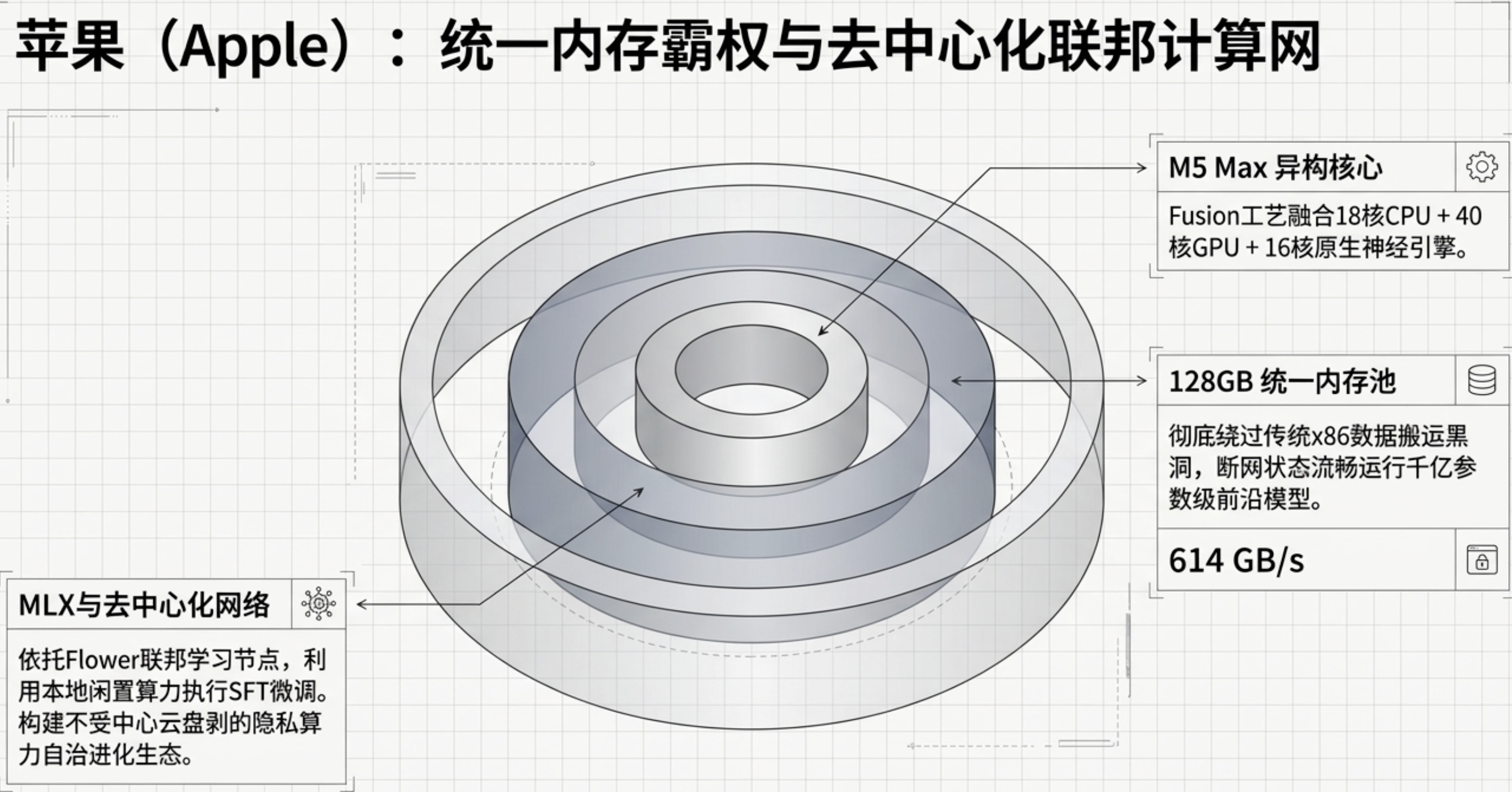
去中心化的进化网络
借助 MLX 框架和 BlossomTuneLLM-MLX 项目,苹果让 Mac 不仅仅是推理工具,更是联邦学习的节点。这种在保护隐私的前提下利用个人本地数据进行 LoRA/DoRA 微调的生态,是苹果抵御中心化云巨头蚕食用户入口的终极武器。
8. 终极胜负手:四大颠覆性底层技术解析
2026 年的终局胜负不仅取决于晶体管数量,更取决于对以下四项底层范式的重构:
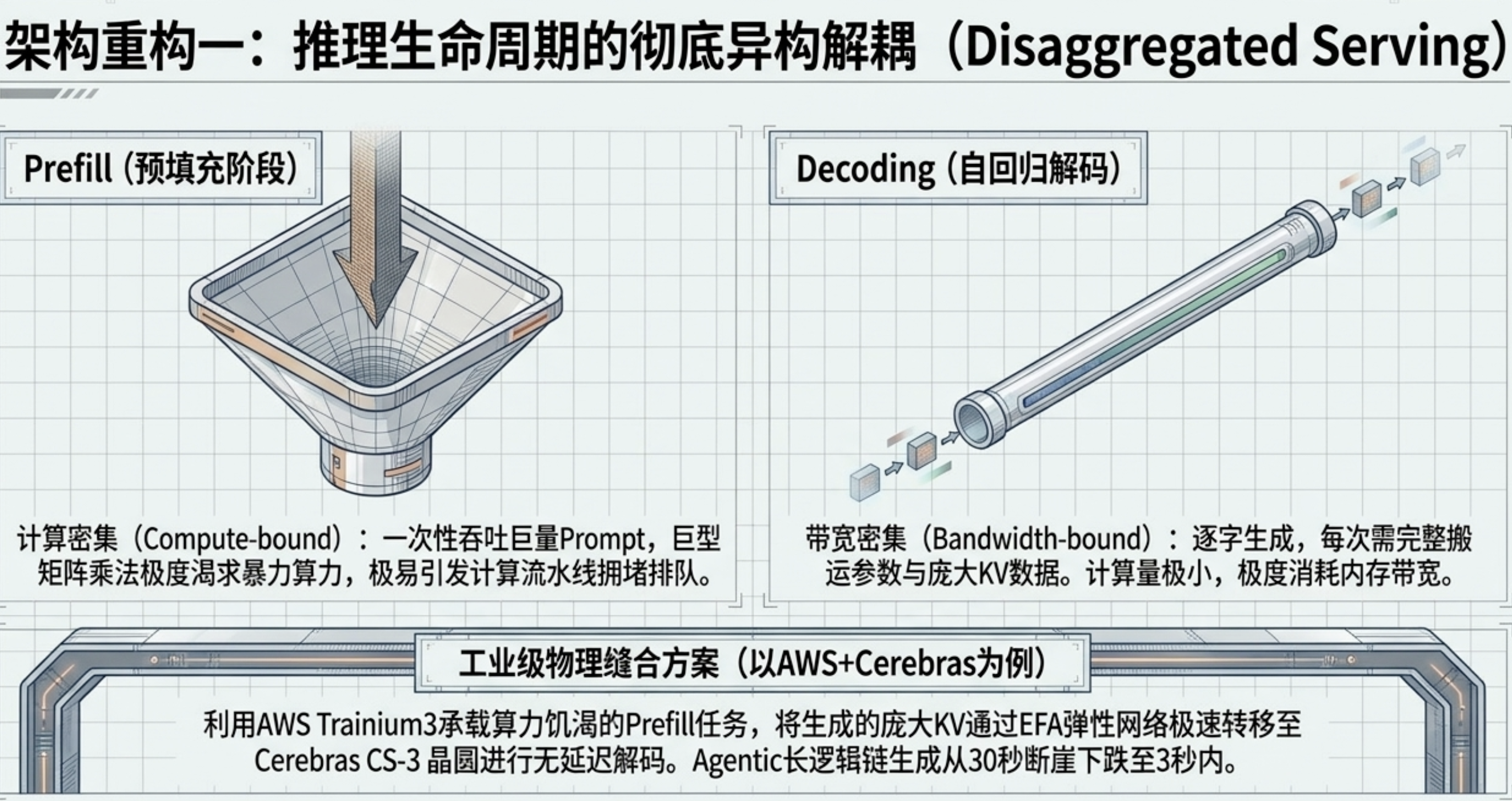
1. Prefill 与 Decoding 的彻底解耦
推理负载被拆分为计算密集型的 Prefill(预填充,GEMM 为主)和内存带宽密集型的 Decoding(解码,自回归为主)。通过分离式调度(Disaggregated Serving),系统能够物理消除长文本输入带来的延迟毛刺,将 Agentic 任务的总生成耗时从 30 秒缩减至 3 秒以内。
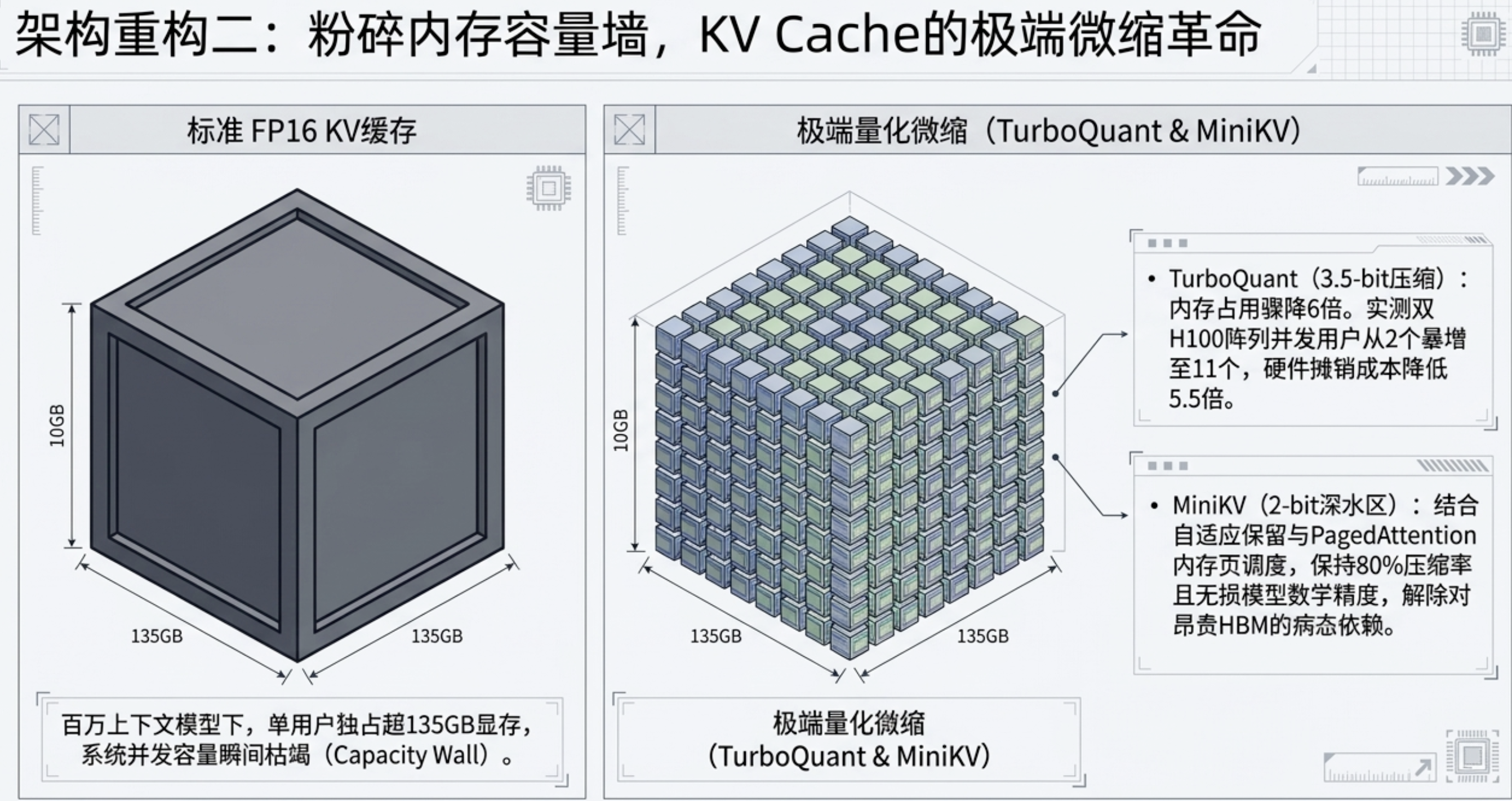
2. KV Cache 的微缩革命
随着百万上下文成为标配,KV Cache 压垮了 HBM。谷歌的 TurboQuant (3.5-bit) 实现了 6 倍的空间缩减,而前沿的 MiniKV 则在 2-bit 极限上通过自适应保留策略维持了模型精度,这直接粉碎了内存容量墙。
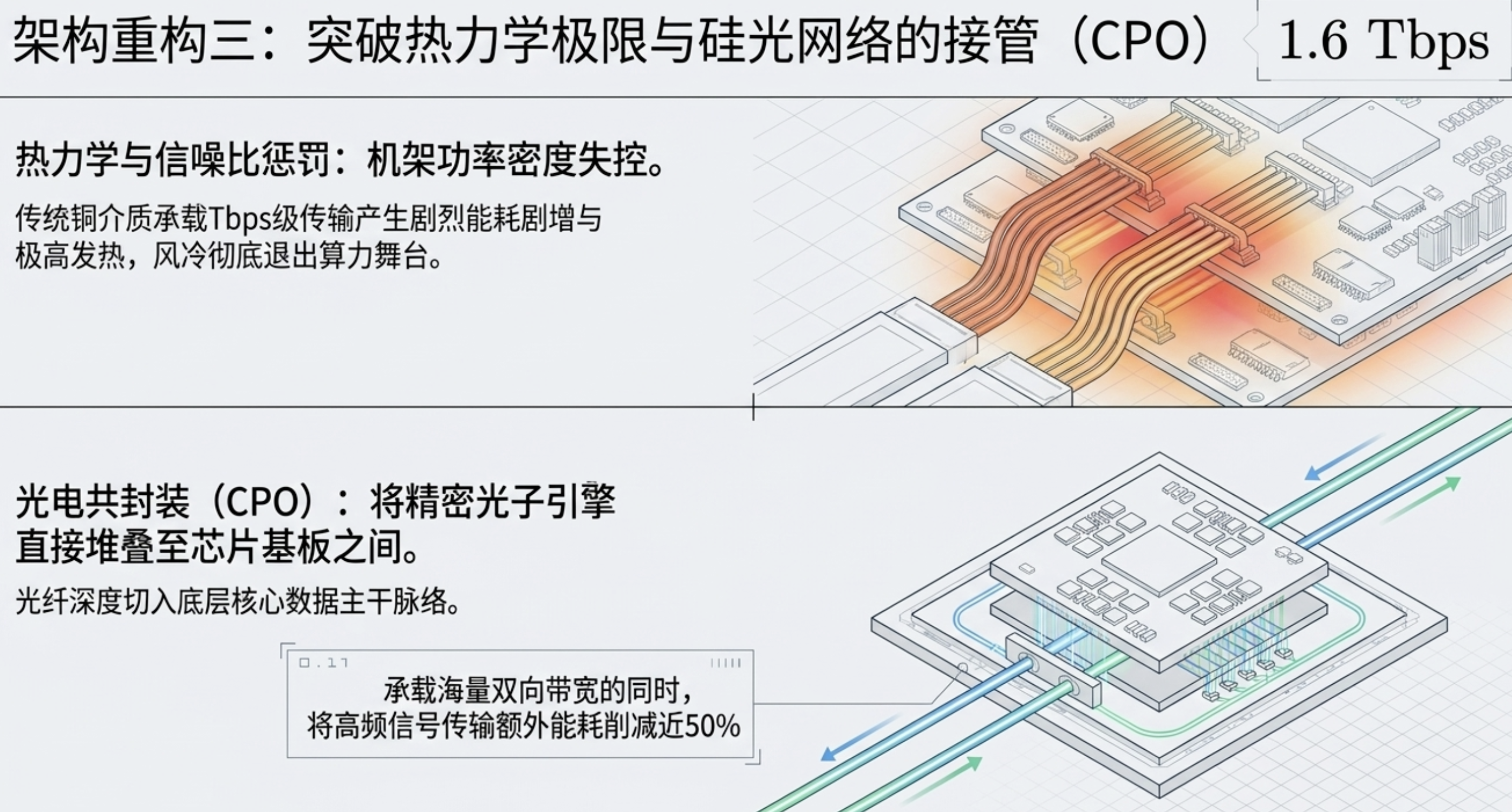
3. 光电共封装 (CPO) 与液冷
铜线互联的功耗惩罚已不可接受。CPO 硅光子技术开始接管数据主干,承载 1.6 Tbps 的海量双向带宽。
物理指标: CPO 技术将传输能耗削减了 50%,配合第四代液冷系统,解决了 1500W 级别的散热危机。
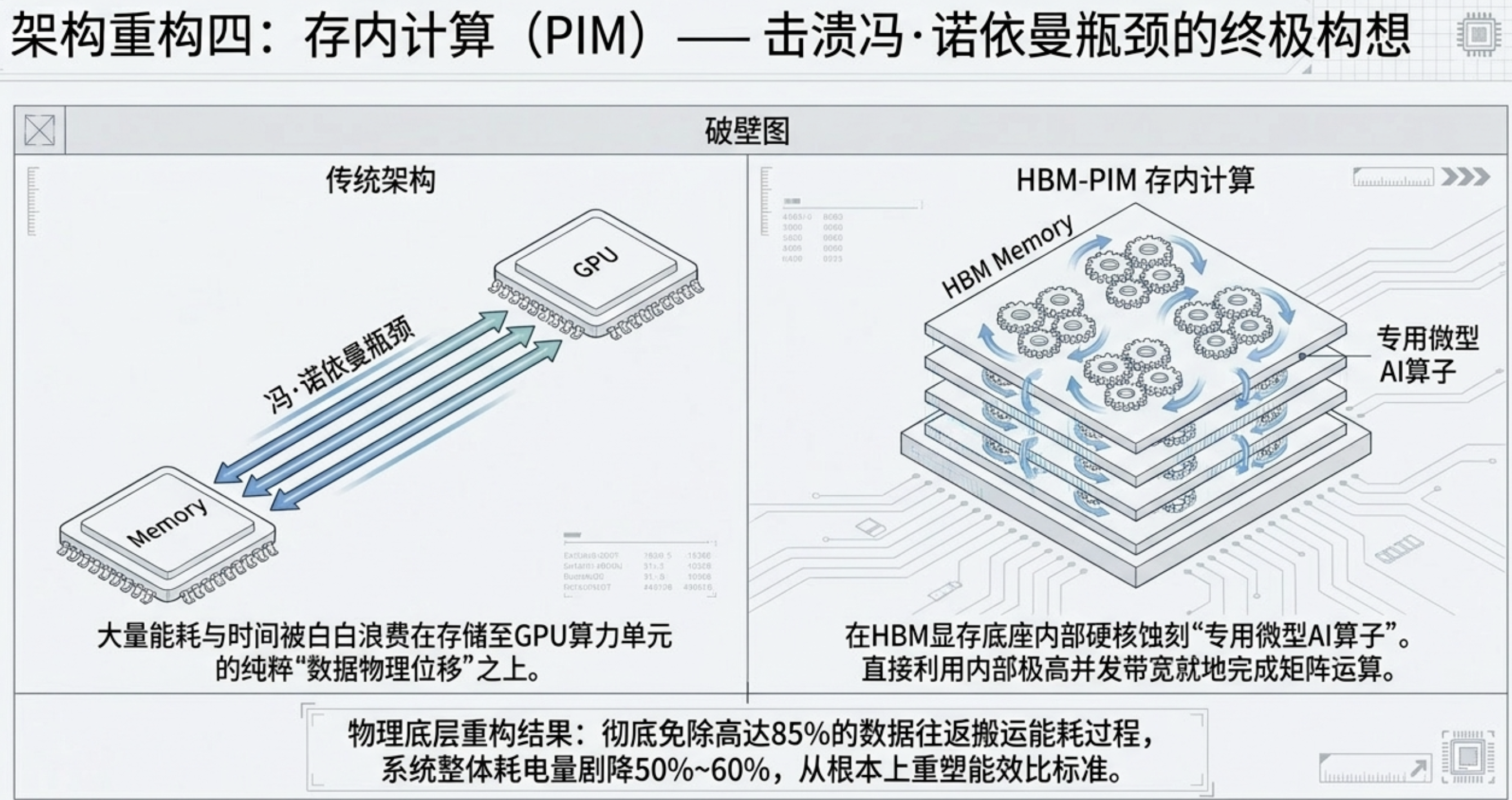
4. 存内计算 (PIM)
三星与海力士主导的 HBM-PIM 架构直接在存储底座内蚀刻计算逻辑。
核心优势: 由于免去了 85% 的数据往返搬运能耗,系统级整体功耗剧降 50%-60%。PIM 让存储不再是计算的旁观者,而是直接参与智能生成的“分布式大脑”。
9. 结语:算力工厂的黎明与进化的暗流
展望 2026 年后的终局,AI 芯片战场已经演变为三位一体的竞争:
训练端: 呈现 Nvidia (开放标准) 与 Google (闭环高效) 的双王共治。
推理端: 走向极端的异构解构,Cerebras 的暴力美学与谷歌的专用 8i 正在分食原本属于 GPU 的蛋糕。
终端: 苹果凭借统一内存架构构筑了无法逾越的铁壁,将个人智能锁定在本地边缘。
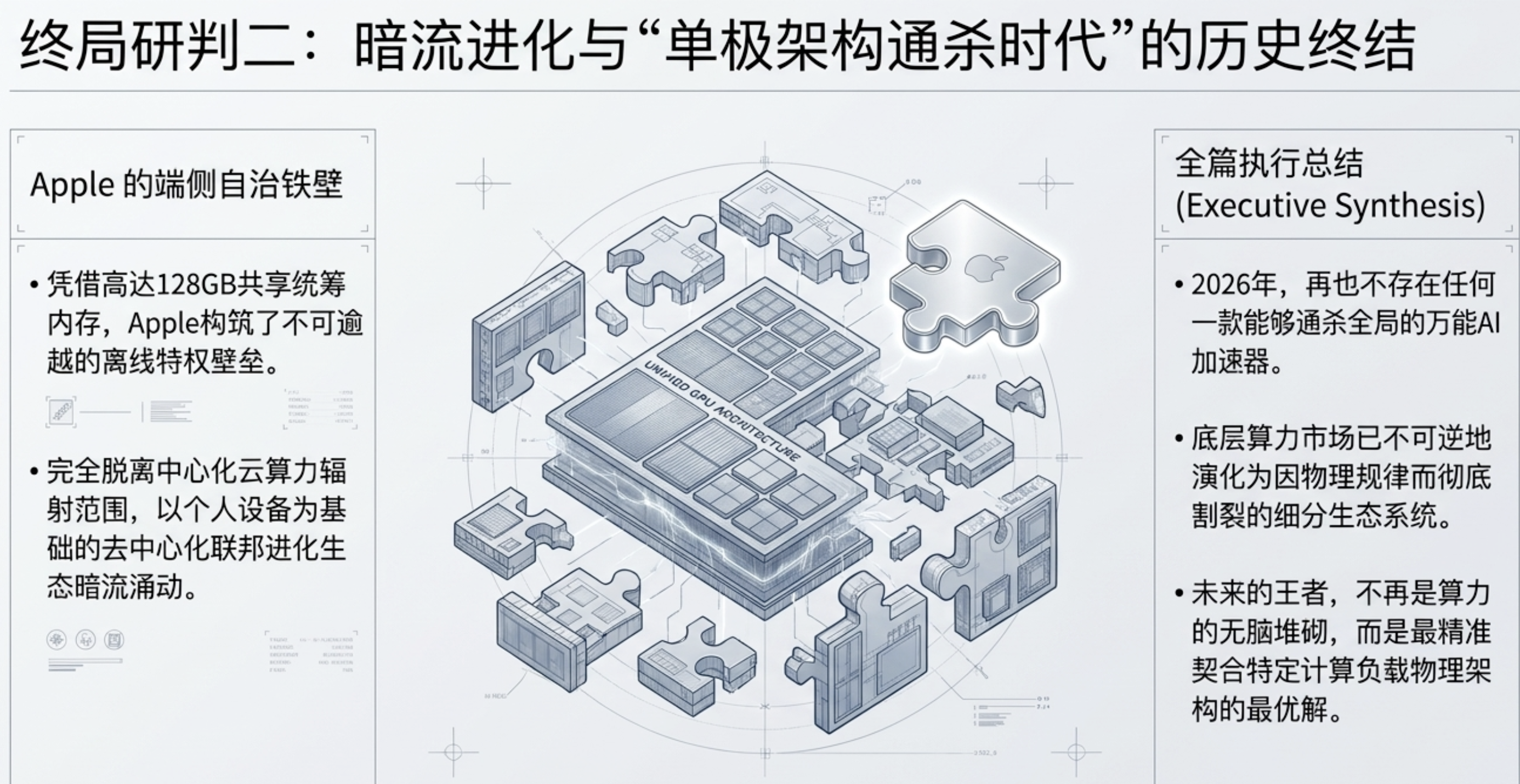
一个关键的悬念依然存在:这种以苹果为代表的、基于个人物理节点的“去中心化分布式 AI 进化网络”,是否会最终因为隐私、成本与个性化的三重优势,反过来瓦解由算力巨头统治的中心化云帝国?无论如何,2026 年的底层技术革命已经彻底改写了通往 AGI 的物理路线图。