

 4
4 0
0
当我们在谈论大模型的“智能涌现”时,背后是否隐藏着一条像物理定律一样精确的数学法则?答案是肯定的——缩放定律(Scaling Laws)。
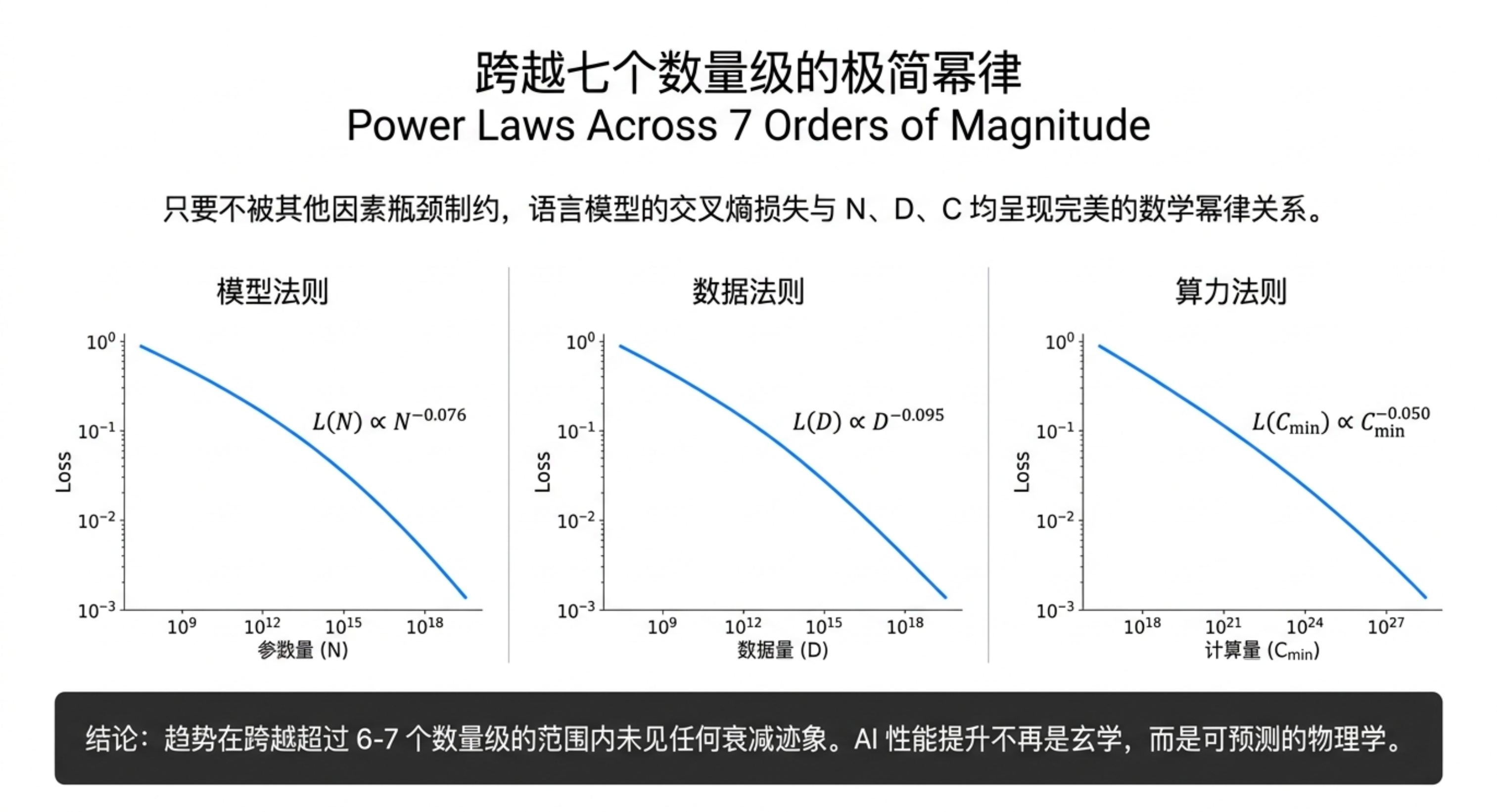
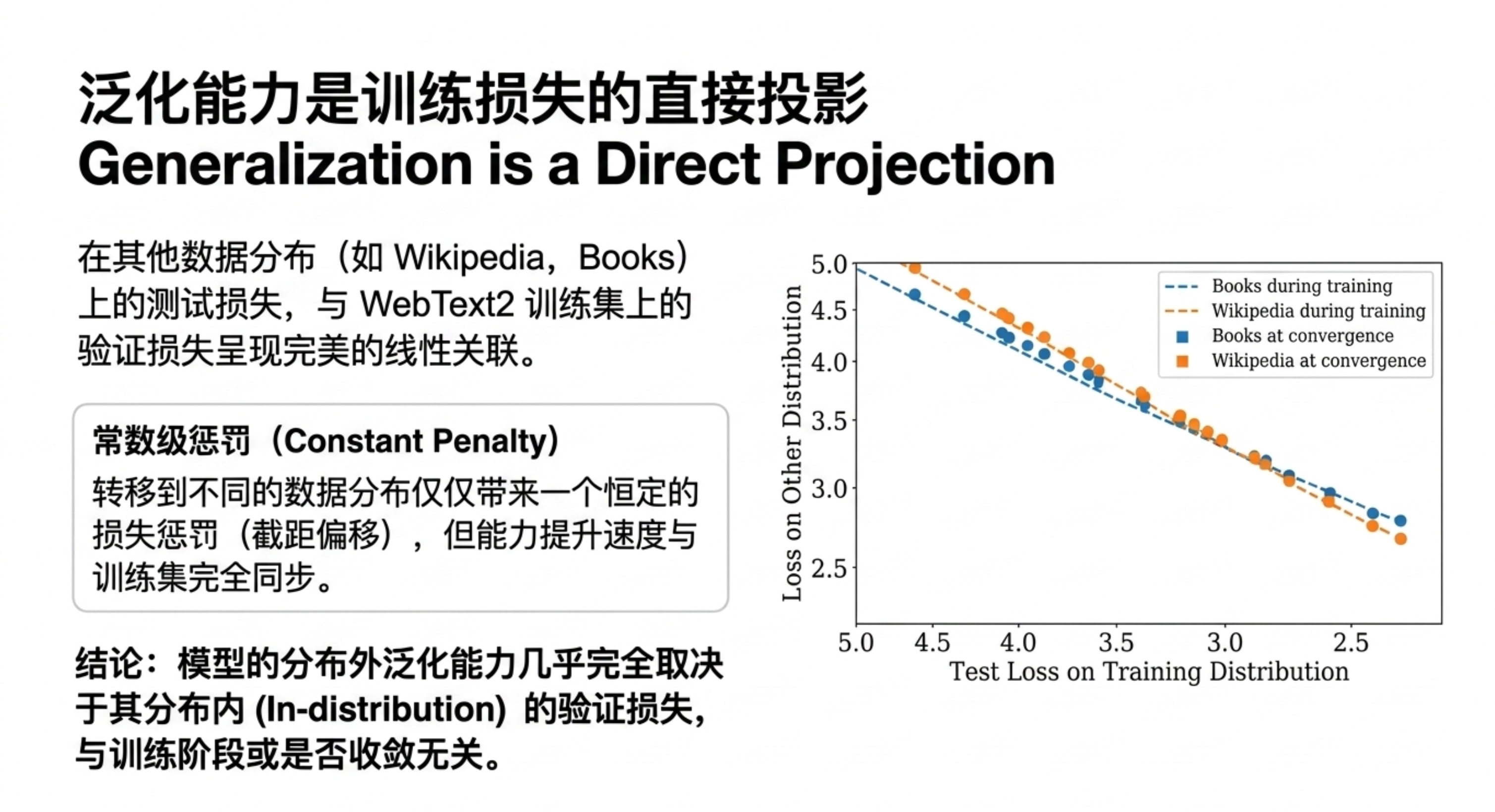
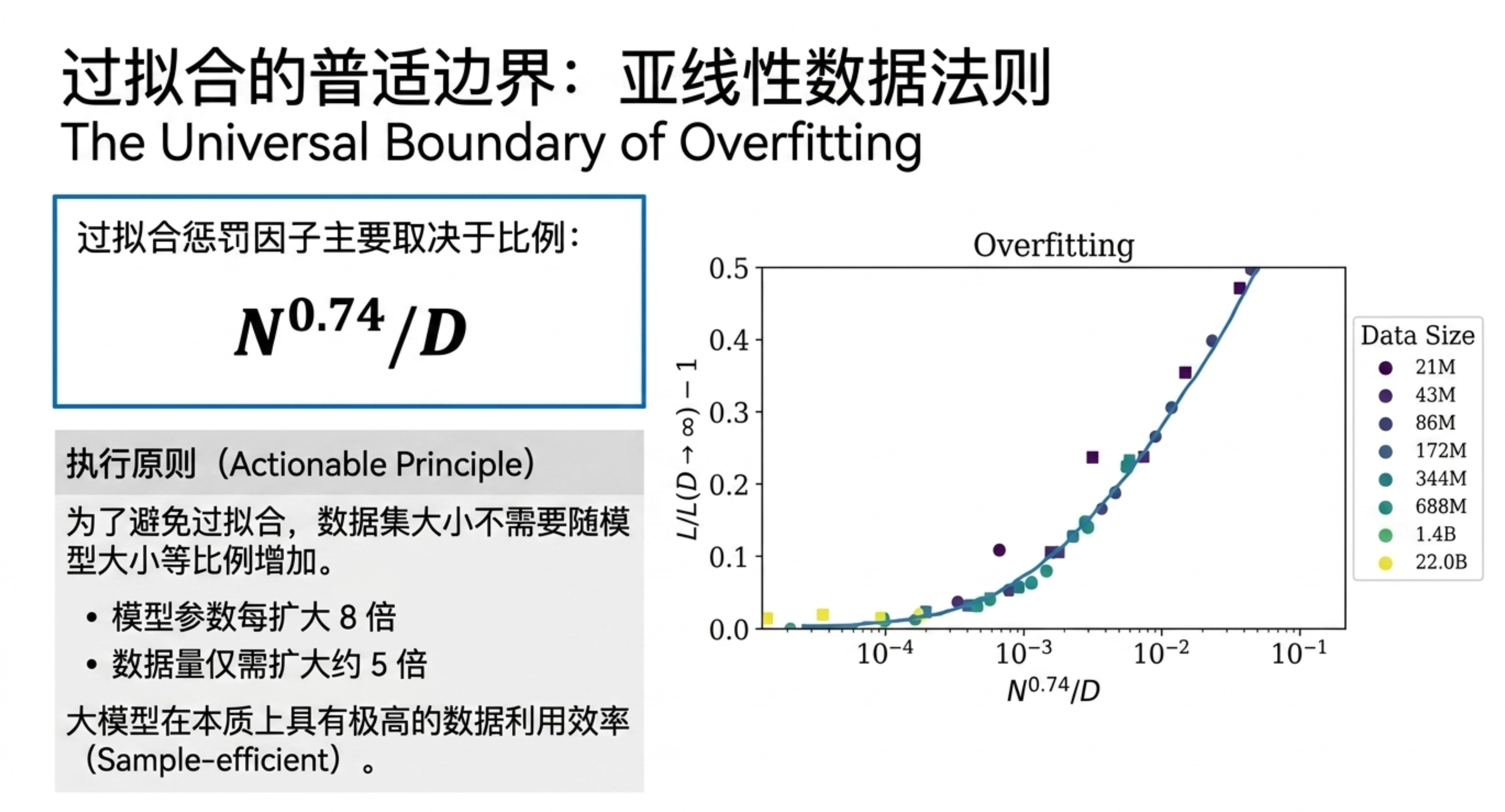
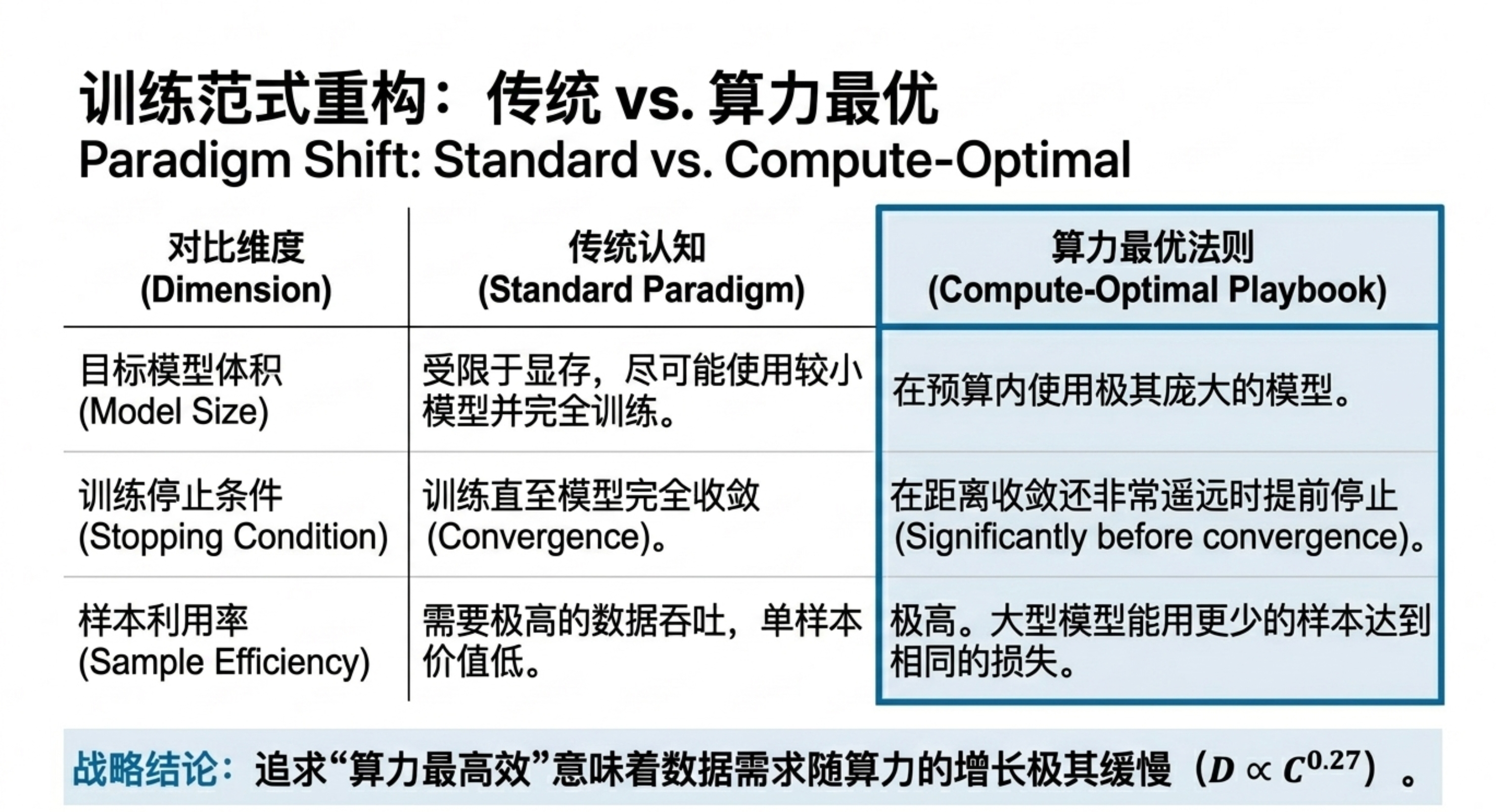
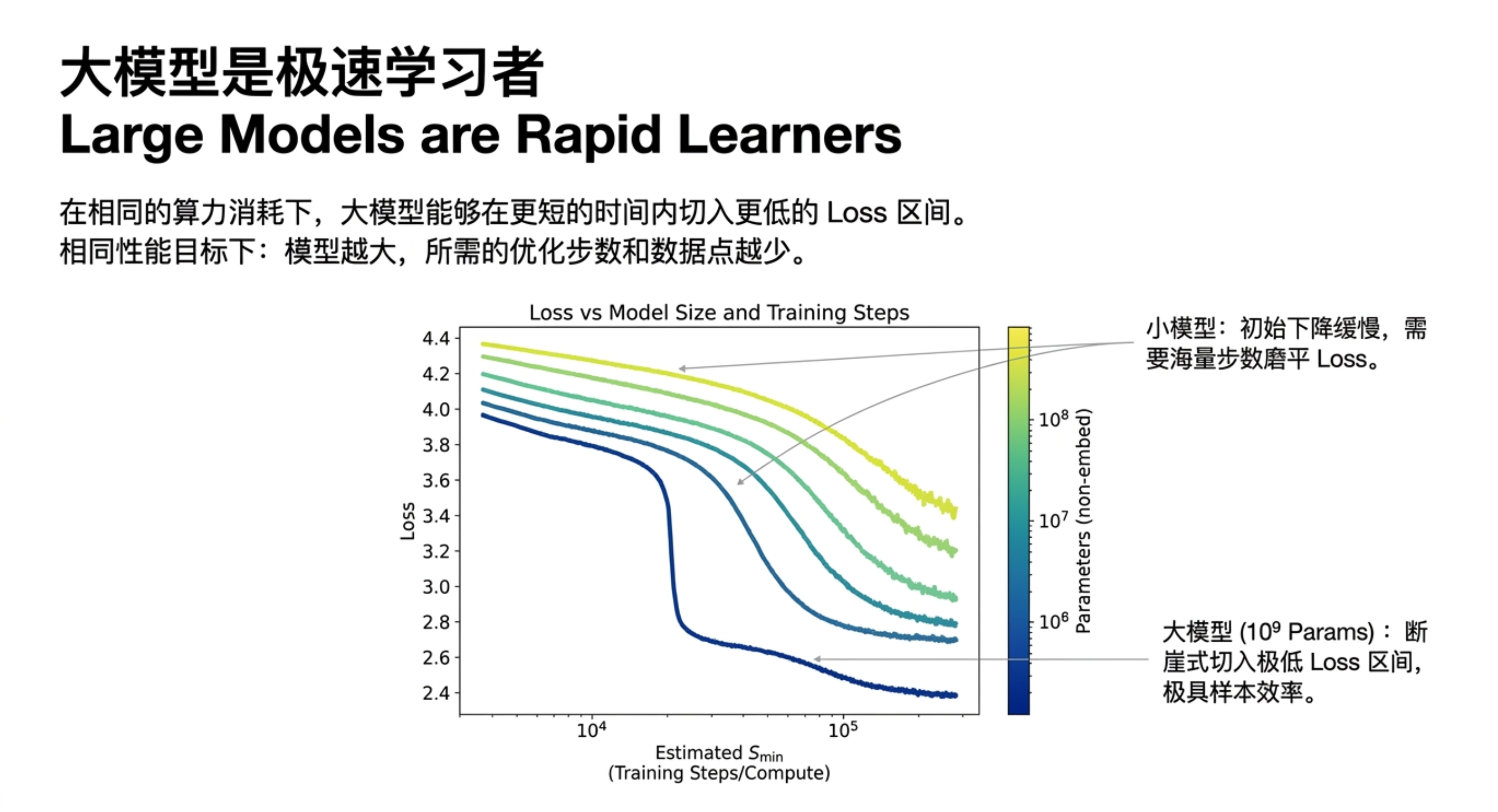
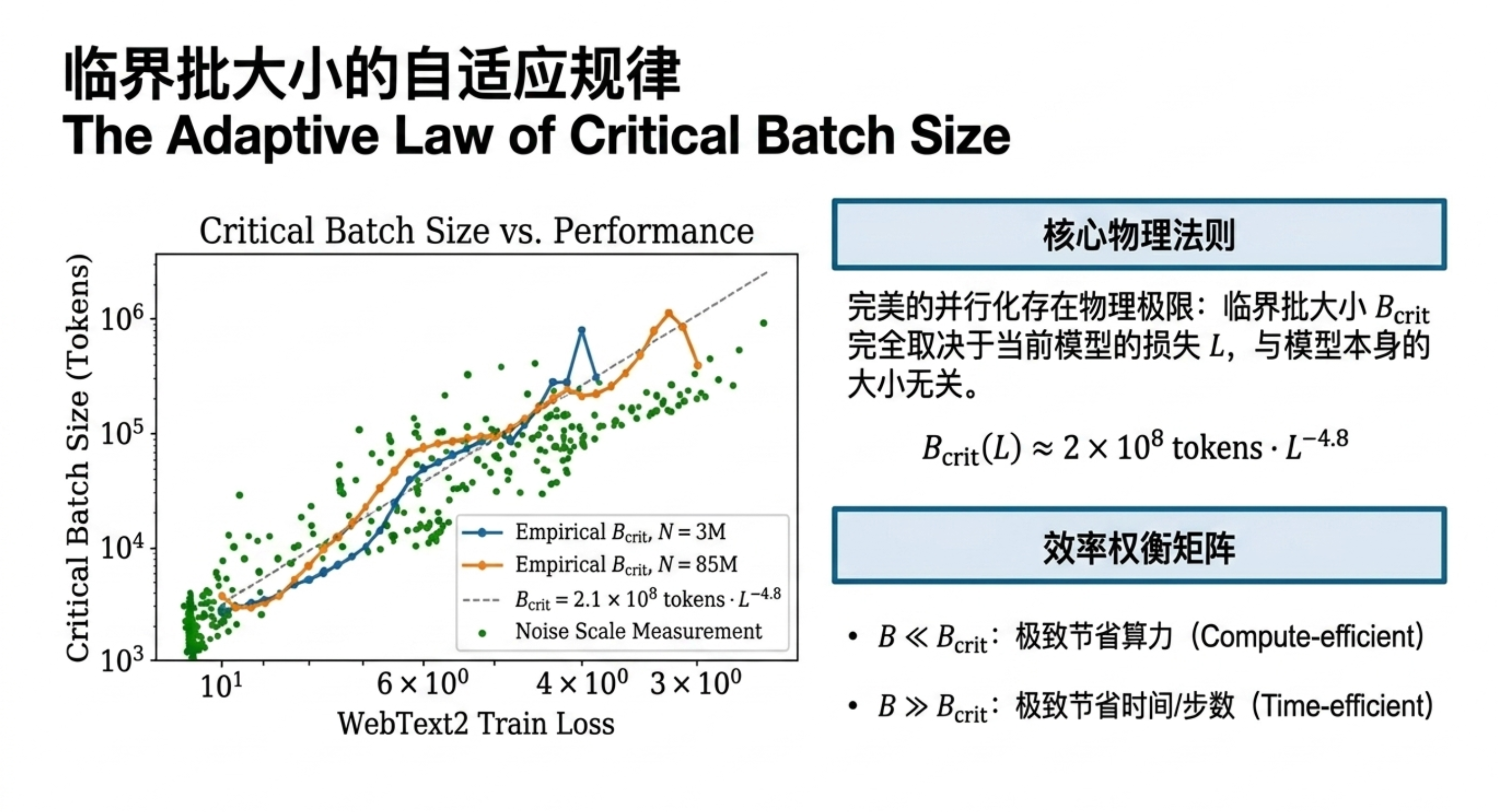
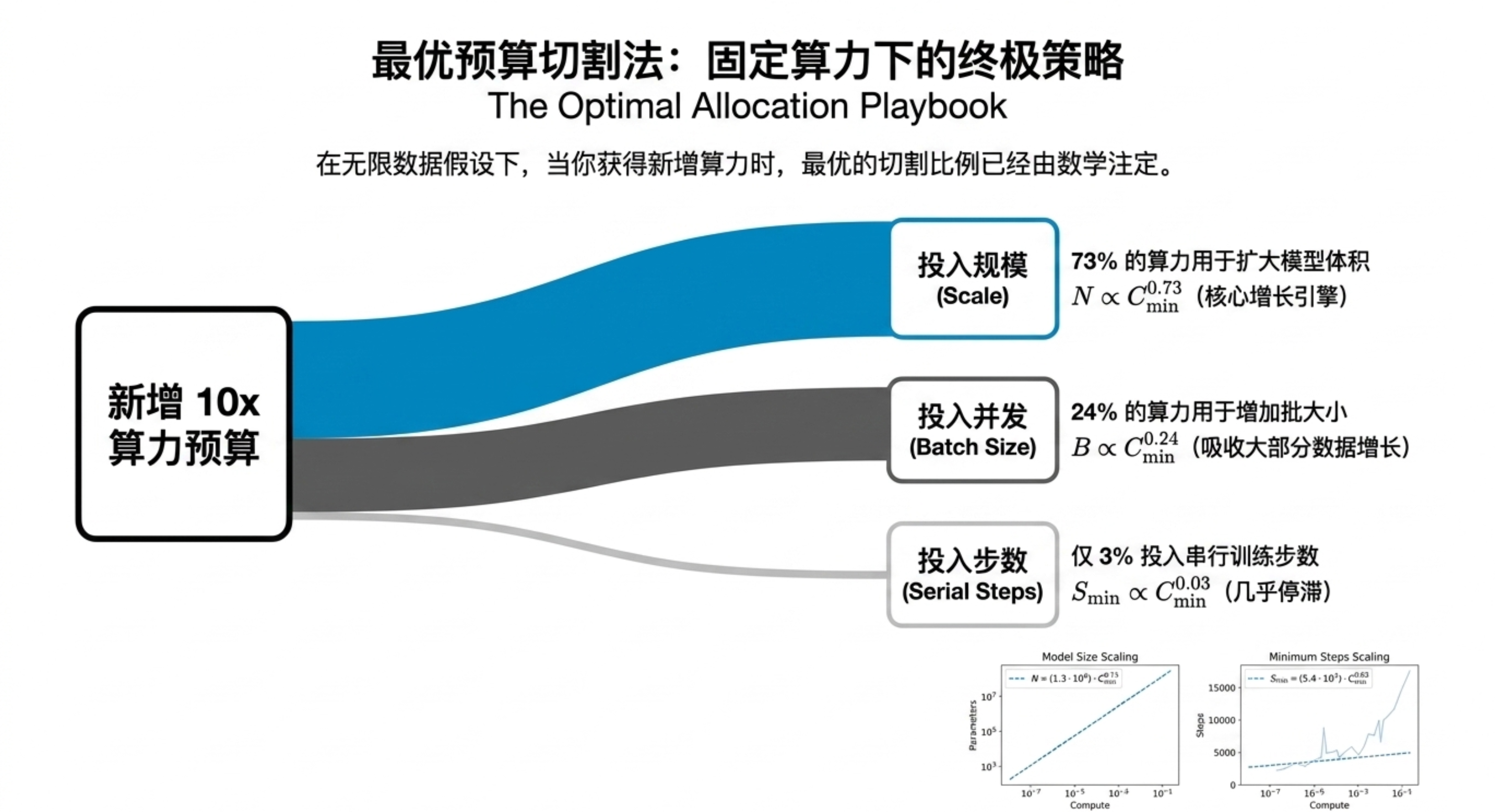
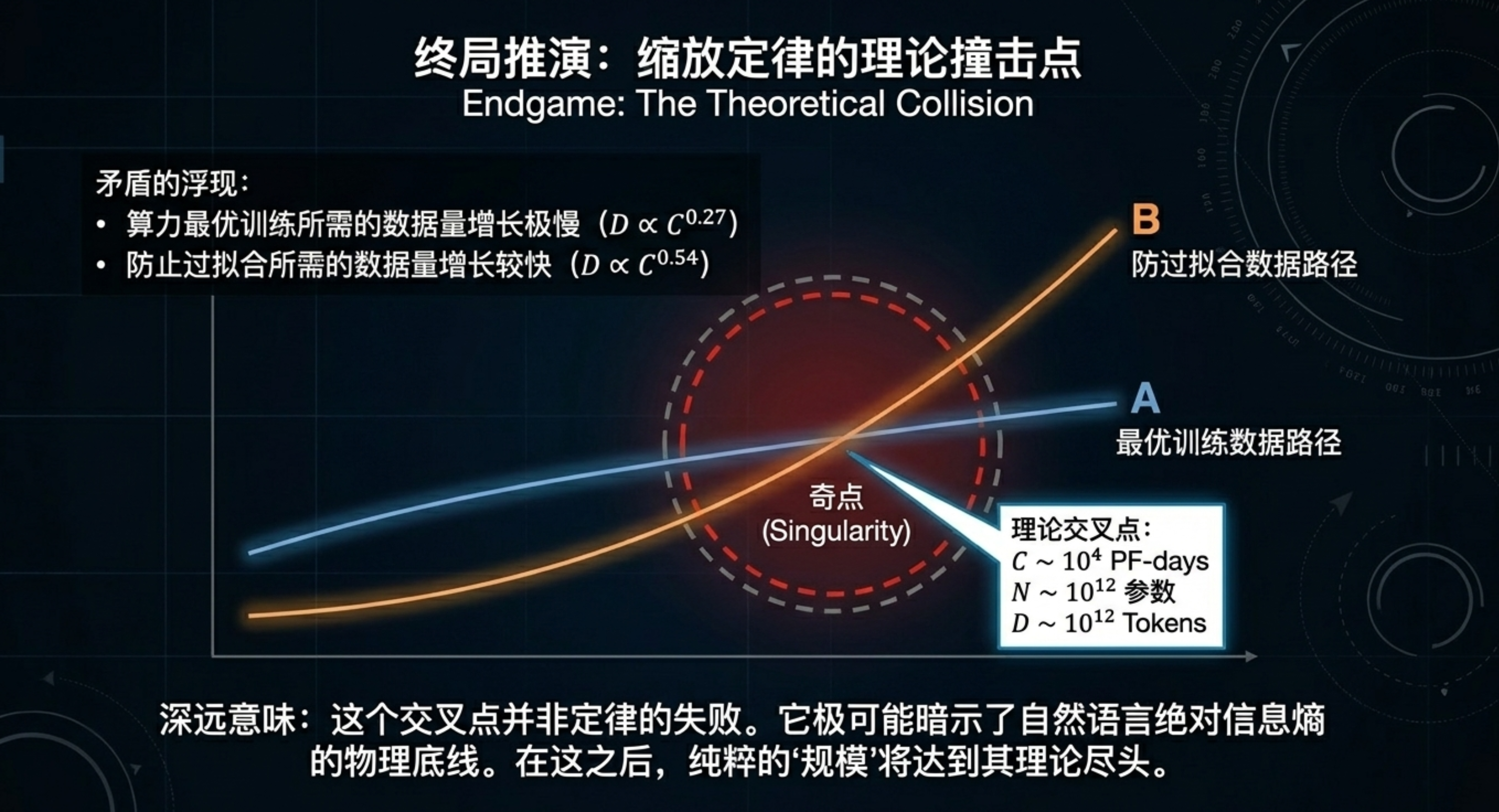
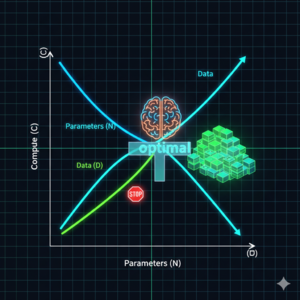
本期内容将带你深入一份关于神经网络语言模型规模定律的研究。你会发现,模型的性能(交叉熵损失)与参数量、数据集大小和计算资源之间,存在着跨越多个数量级的幂律关系,且几乎不受架构细节(深度、宽度)的影响。更关键的是,研究揭示了计算预算的最佳分配策略:优先扩大模型规模,而非无限增加数据或训练步数;大模型比小模型更具样本效率,且不应训练到收敛。这些规律为预测下一代模型性能提供了类似“理想气体定律”的理论框架,也解释了为何“大力出奇迹”在目前阶段依然有效。
缩放定律证明了语言模型的性能高度依赖于规模,且遵循精确的幂律。它告诉我们:扩大模型规模比增加数据更划算,训练大模型并提前停止是最优策略。这对于指导未来大模型的研发投入具有重要的定量意义。
参考:Scaling Laws for Neural Language Models

以下为主要内容的图文介绍: