


 16700
16700 76
76Summary
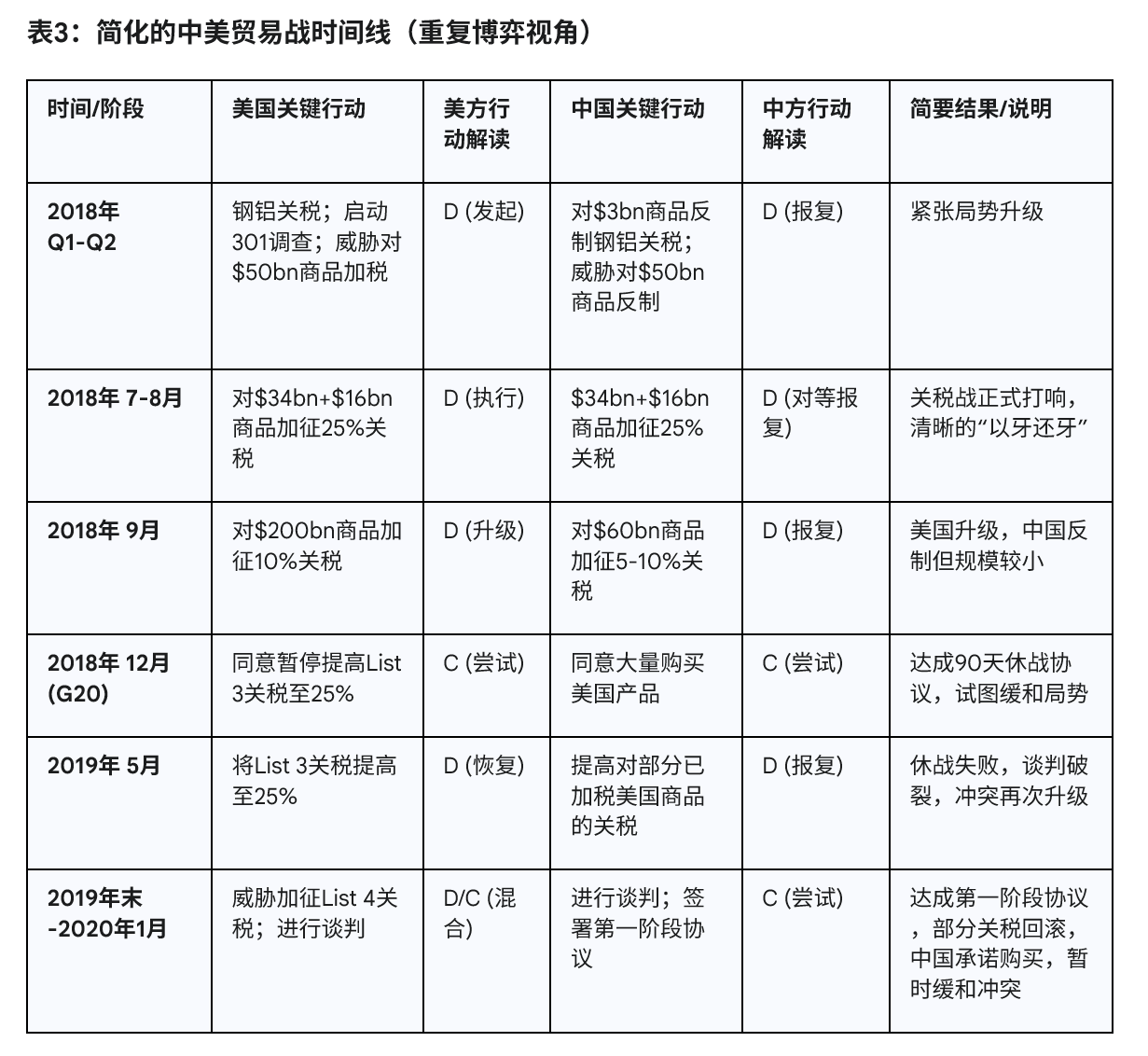
本期节目探讨了中美博弈的背景与框架,分析了多次博弈与以牙还牙策略的有效性,深入解析了囚徒困境的概念及其在中美贸易战中的应用,最后结合具体案例展望未来的策略建议。 本次对话深入探讨了中美贸易战的背景、应对策略及未来可能的发展。讨论了2018年与当前贸易战的不同之处,以及中国在面对美国加征关税时的反制措施和策略。同时,强调了沟通机制在谈判中的重要性,认为双方需要建立有效的沟通渠道,以避免误判和冲突升级。
Keywords
中美博弈, 多次博弈, 以牙还牙, 囚徒困境, 贸易战, 中美贸易战, 反制策略, 经济影响, 谈判机制, 贸易政策
Chapters
00:00 中美博弈的背景与现状
03:07 多次博弈的框架与策略
06:24 囚徒困境与博弈论的应用
09:10 中国的反制策略与国际关系
12:00 未来展望与博弈的可能性
13:50 囚徒困境的深刻理解
14:44 中国的博弈策略与逻辑
16:01 迭代囚徒困境的探讨
19:50 真实竞赛中的策略表现
25:54 中美贸易博弈中的TFT策略
27:44 中国的反制策略与经济准备
30:08 中美贸易战的博弈与沟通
33:21 2018年与现在的贸易战对比
39:21 谈判与合作的尝试
40:44 中美贸易战的背叛与反制
41:42 第一阶段协议的签署与后果
42:39 中美贸易战的反制策略
43:41 中美之间的误判与反应
44:47 对等反制的策略与效果
45:44 维持力量均衡的重要性
46:43 中国的经济应对与选择
47:40 未来贸易战的可能走向
48:50 复合囚徒困境模型的局限性
49:49 博弈策略的复杂性与局限性
52:15 博弈模型的成功与局限性
55:59 中美谈判中的策略与条件
01:00:18 多次博弈的理解与未来展望
Reference and Extended Reading

困境的核心在于:无论对方作何选择,每个囚徒单独来看,选择背叛(D)总是比选择合作(C)能获得更好的个人结果 1。如果囚徒B合作,囚徒A选择背叛可以获得T(5分),优于合作的R(3分)。如果囚徒B背叛,囚徒A选择背叛可以获得P(1分),优于合作的S(0分)。因此,背叛是每个理性囚徒的“优势策略”。然而,当双方都追求个人最优选择(背叛)时,最终结果是(P, P)= (1, 1),这比双方都合作的(R, R)= (3, 3) 的结果要差得多。这就是囚徒困境:个体理性导致了集体非理性。这种结果被称为“纳什均衡”(Nash Equilibrium),即在此状态下,任何一方都无法通过单方面改变策略来改善自己的收益。
从单次博弈到重复互动:迭代囚徒困境 (IPD)
这里我延展一下在播客里没有机会说清楚的定义和解释: 囚徒困境模型最初描述的是一次性的互动。然而,现实世界中的许多互动,尤其是在国际关系中,是重复发生的。当囚徒困境游戏被重复进行多次时,就构成了“迭代囚徒困境”(Iterated Prisoner's Dilemma, IPD)。重复互动极大地改变了博弈的性质 。与一次性博弈不同,在IPD中,参与者拥有“记忆”,可以根据对手之前的行为来调整自己的策略。这使得“声誉”和“互惠”(Reciprocity)成为可能 。今天的行为会影响未来的结果,因为对手可能会在下一轮进行“报复”(惩罚背叛)或“回报”(继续合作。这种对未来结果的预期,即所谓的“未来的阴影”(Shadow of the Future),是促进合作的关键因素。参与者越看重未来的收益(用贴现因子 δ 表示,其中 0<δ<1),就越有可能在当前选择合作。
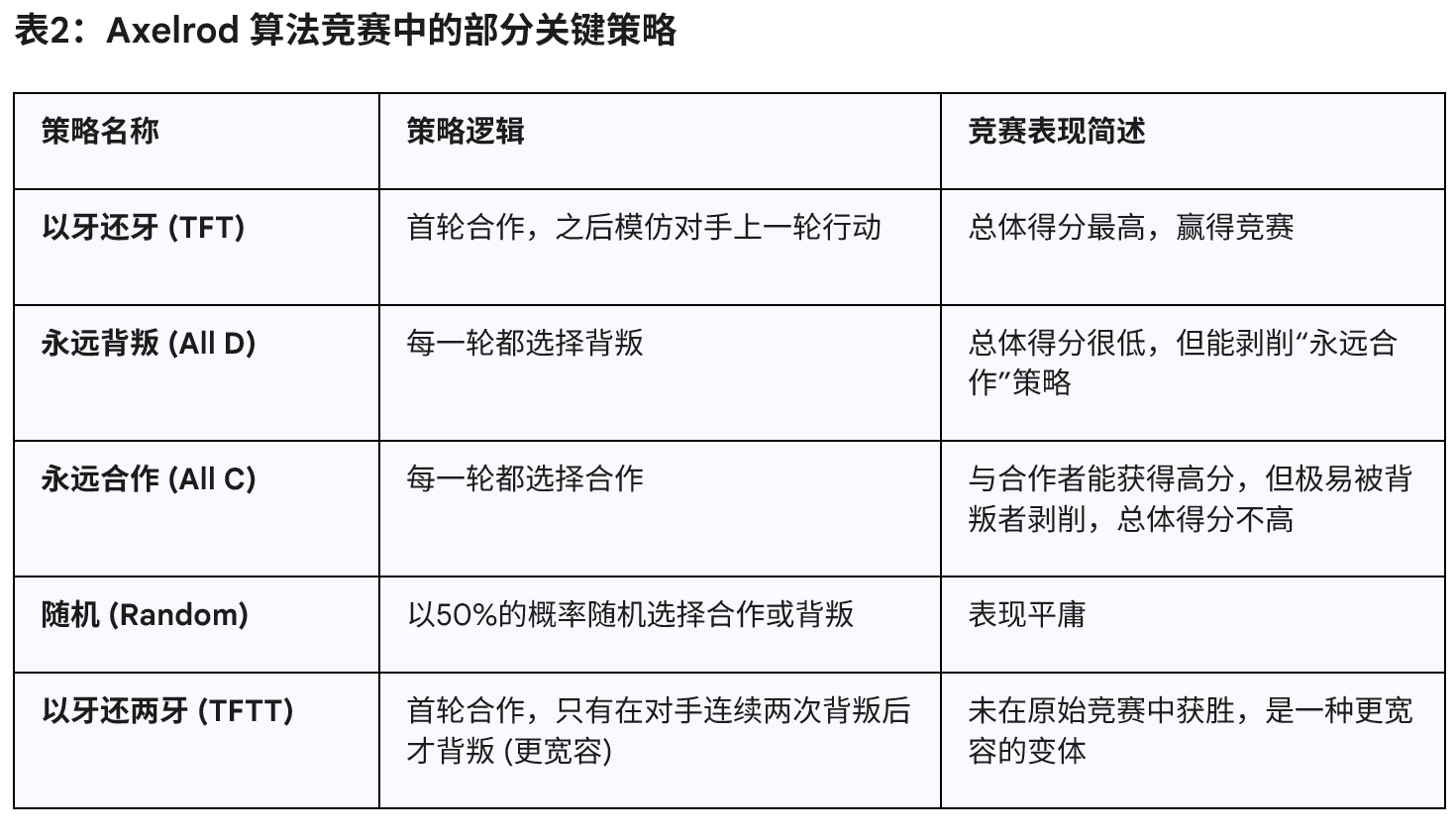
TFT的规则极其简单:第一步选择合作,之后每一轮都模仿对手上一轮的行动 。如果对手上一轮合作,TFT这一轮就合作;如果对手上一轮背叛,TFT这一轮就背叛。
本次播客引用论文 (Axelrod, 1980):
1. 斯坦福对于Axelrod's Tournament的解释- Stanford Computer Science, accessed May 12, 2025, cs.stanford.edu
链接: cs.stanford.edu
2. 原论文链接: esp.mit.edu

















