


 10740
10740 56
56本期嘉宾,是清华大学的刘知远和肖朝军,他们刚在 11 月的《自然》杂志《机器学习》子刊上发表了封面文章:Densing Law of LLMS,大模型的密度法则。所谓“密度”,就是用更少的算力和数据获得相当乃至更多的智能。
刘知远是清华计算机系副教授和面壁智能首席科学家,肖朝军现在在清华做博士后,也是面壁 MiniCPM 系列的文本模型负责人。
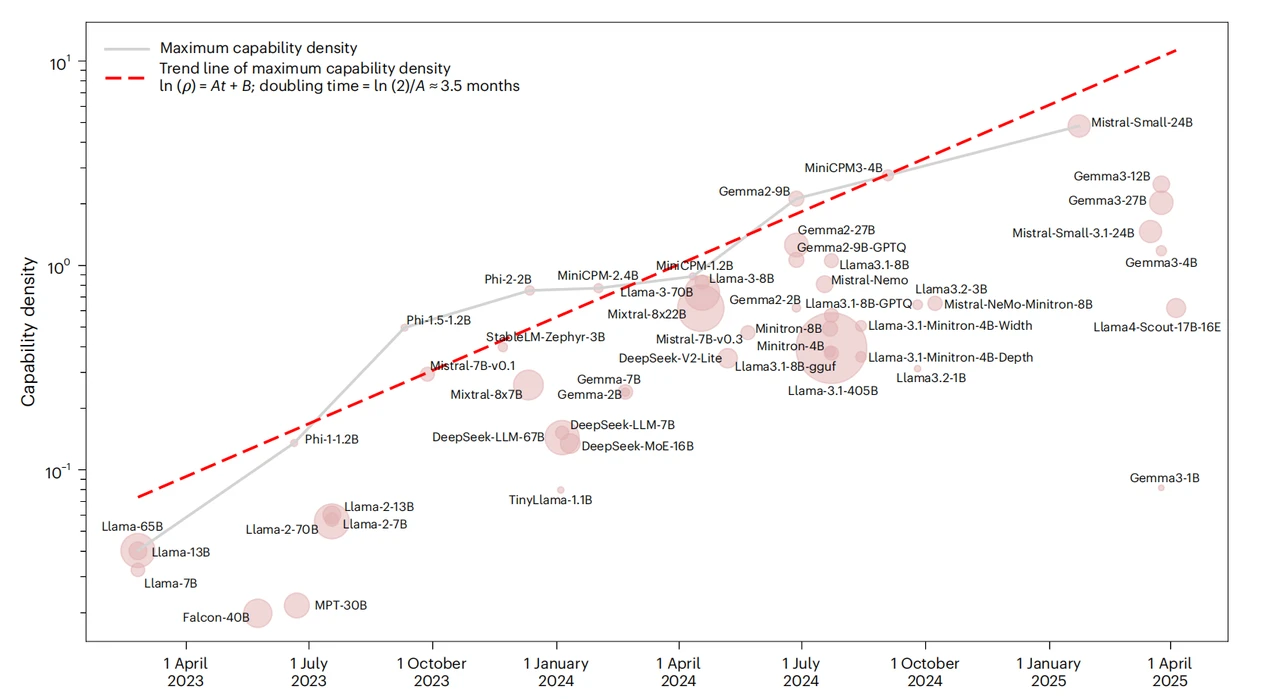
图注:此图描述了 2023 年 4 月之后,主要开源模型的能力密度的变化。能力密度是衡量单位参数/算力下,模型能力的指标。目前版本的密度法则总结了预训练大语言模型的密度变化,o1、R1 等后训练强化学习对能力密度的提升尚未体现在指标里。
我们讨论了密度法则研究的源起,也展开聊了业界提升模型能力密度的具体做法:如何从架构、数据治理、算法和软硬协同优化 4 个环节着手提升模型能力密度。
而再往后,更大的密度提升,可能需要一些全新方法,因为强化学习的 Scaling Law 还未清晰展现,未来可能有两种技术路线:一是继续扩大强化学习的规模,观察其中是否涌现更多泛化能力;二是寻找新的学习方式。
在刘知远的设想中,未来,更高密度的模型,会支持每个人在端侧的专属模型,智能会分布式存在:也许手机都不是最终的入口,而是一个可以随身携带的个人计算设备:“就像一个可以随身携带的 NAS”。
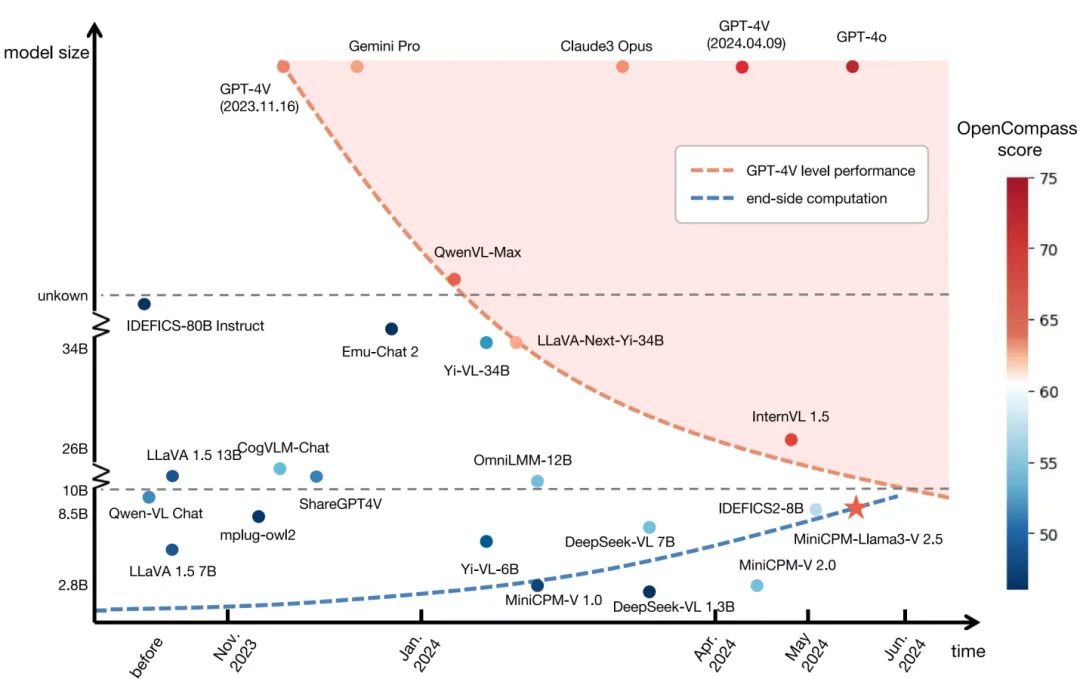
图注:达到 GPT-4V 水平的模型参数规模随时间增长迅速缩减,而端侧算力快速增强,当芯片电路密度(摩尔定律)和模型能力密度(密度法则)两条曲线交汇,端侧设备将能运行以往只能在云端运行的大模型。
性能一直是人们更关注的模型演进的脉络,而这期我们会讨论,在另一条主线“效率”上,我们可以做出什么努力。
本期嘉宾:
刘知远,清华大学计算机系副教授、面壁智能首席科学家
肖朝军,清华大学计算机系博士后、面壁智能 MiniCPM 系列文本模型负责人
本期主播:程曼祺,《晚点 LatePost》科技报道负责人
时间线跳转:
-大模型时代的“摩尔定律”
02:09 Gemini 3 和 Nano Banana Pro 的启发:统一的“自回归式视觉+语言生成”即将突破
04:31 大模型演进的两条主线:能力和效率
10:23 和摩尔定律一样,“密度法则”是行业现实,也是“自我实现”
18:43 每 3.5 个月,大模型的能力密度翻一番
21:01 2023 年下半年的抉择:花几千万再训一个更大的模型,然后呢?
-提升密度的四个环节
27:08 架构、数据、算法、软硬协同优化
30:41 (1) 架构:MoE (混合专家系统) + 注意力机制改进
34:28 (2) 数据治理:Ultra-FinWeb 用 1/10 数据量达到更好效果
40:24 (3) 算法:RL 还没有 Scaling Law,接下来可能有两条路
49:21 (4) 软硬协同优化
52:02 InfLLM-V2 的核心更新:把稀疏注意力做到预训练阶段
55:18 注意力改进趋势:长文本不仅是长输入,更多关注“长输出”
-大模型上车、上手机
58:53 5 年内,手机可跑 GPT-4~5 级别的模型
01:06:23 大模型在汽车上已开始量产落地
01:10:34 “别人得到的,不一定是你失去的”,AGI 既会发生在云端,也会发生在终端
01:15:07 未来入口也许不是手机,而是属于每个人的移动计算终端
-AGI 下一步:自主学习 + 分布式的智能
01:17:40 自主学习→AI 协作网络→真正的创新
01:21:04 2023 年初,有巨头说世界上只会拥有几个大模型,就像 1943 年,IBM 董事长曾说全球不需要超过 5 台主机
01:24:46 AI 助手帮成为更好的工作者
01:28:53 不担心生产过剩,未知领域还太多
01:31:39 机器制造机器,AI 制造 AI
01:40:01 ☆连点成线
相关链接:
晚点聊 143 期:《再聊 Attention:阿里、Kimi 都在用的 DeltaNet 和线性注意力新改进》
晚点聊 103 期:《用Attention串起大模型优化史,详解DeepSeek、Kimi最新注意力机制改进》
剪辑制作:Nick
附录,本期提到的一些论文(更多具体名词解释,见本期文字版):
Densing law of LLMss(《大模型的密度法则》)
Efficient GPT-4V level multimodal large language model for deployment on edge devices(本期中提到的,具身行业喜欢引用的图的原始论文。)
InfLLM-V2: Dense-Sparse Switchable Attention for Seamless Short-to-Long Adaptation(InfLLM 稀疏注意力改进的第二版。)

☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆
欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。
这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。
请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。
关注公众号《晚点 LatePost》和《晚点对话》,阅读更多商业、科技文章:



















图文版链接